Dynamic Proxy-Mixing: Transferring Replay Controllers from Small to Large Models for Continual Instruction Tuning
Pith reviewed 2026-06-28 22:56 UTC · model grok-4.3
The pith
A dynamic replay controller learned on a small proxy model transfers directly to larger models for continual instruction tuning by relying on consistent task vulnerability rankings across scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
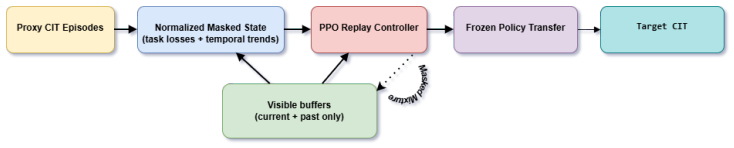
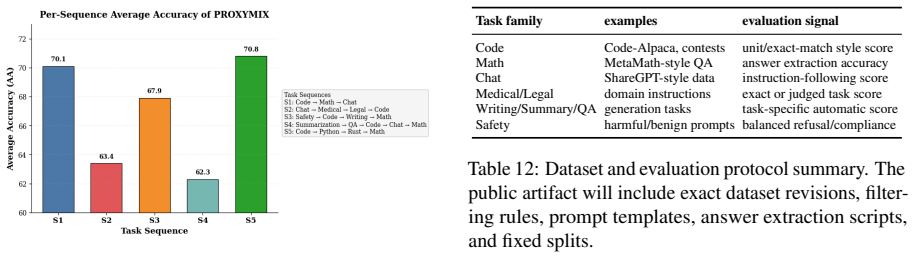
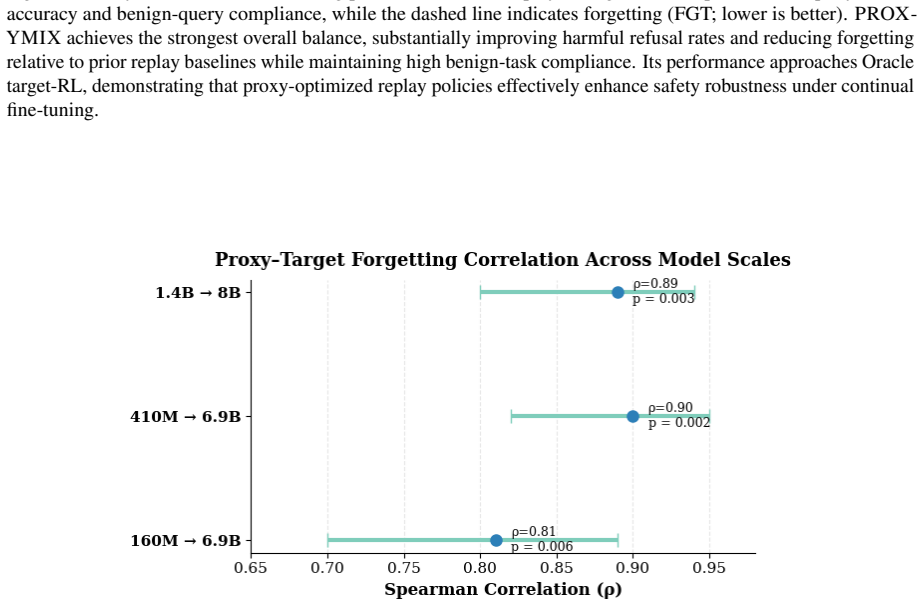
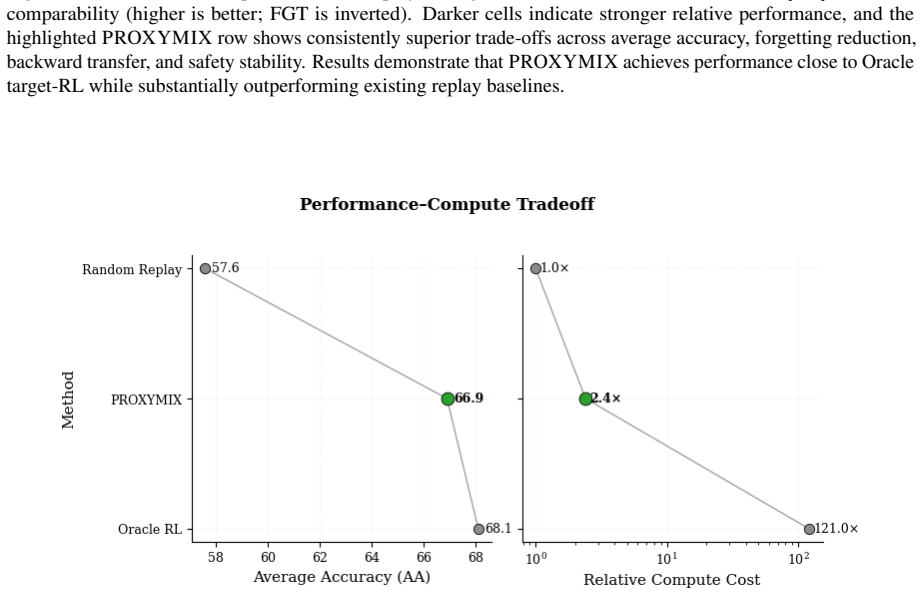
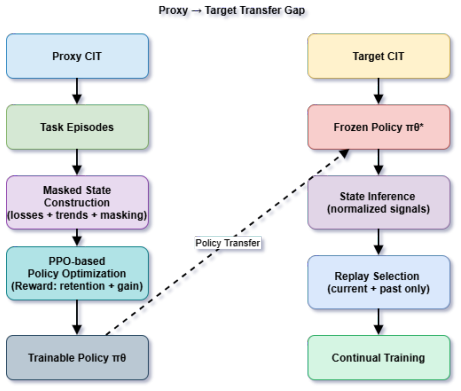
PROXYMIX learns a dynamic replay controller on a small proxy model from normalized validation losses and temporal dynamics, then transfers the frozen controller to a larger target model. The controller produces a masked mixture of the current task and replay buffers. The transfer succeeds because task vulnerability rankings remain largely consistent across scales, an assumption validated empirically on the proxy before any transfer occurs. On LLaMA-3-8B across five sequences this yields 3.4-point accuracy gains, 3.5-point forgetting reduction, and 5.8-point safety improvement over the strongest non-oracle baseline at roughly 50x lower policy-learning cost.
What carries the argument
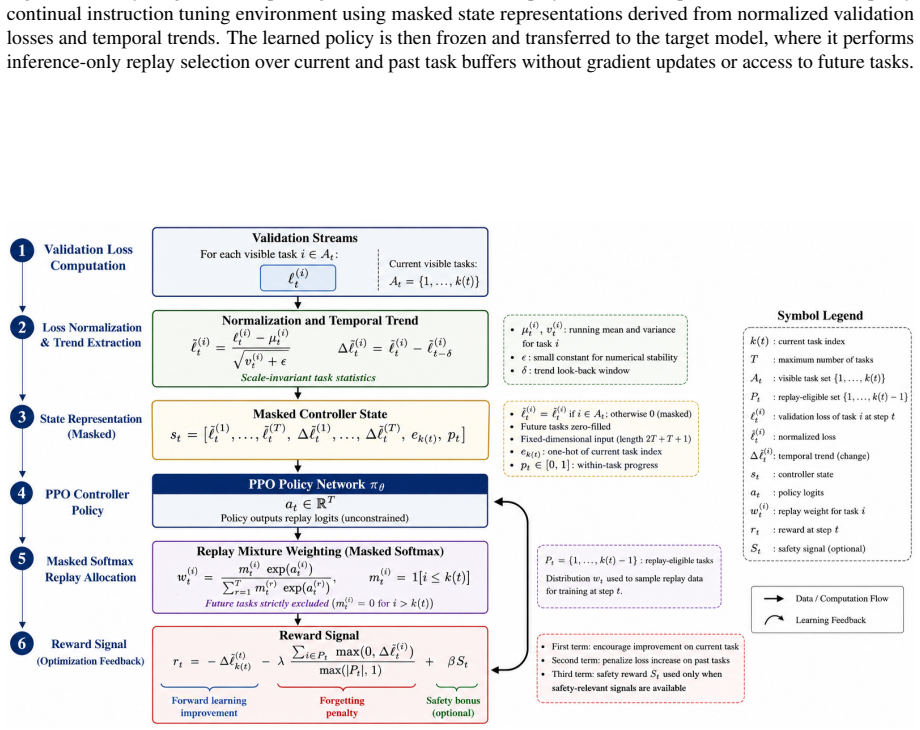
The dynamic replay controller, which builds its state solely from normalized validation losses and their temporal dynamics on accessible buffers to output a masked mixture; it is trained once on the proxy and transferred without retraining.
If this is right
- Average accuracy rises by 3.4 points on LLaMA-3-8B across five sequences.
- Final forgetting drops by 3.5 points relative to the strongest non-oracle baseline.
- Safety scores increase by 5.8 points.
- Policy learning cost falls by a factor of roughly 50 compared with training the controller directly on the target.
- The interface remains leakage-free and works across architectures without modification.
Where Pith is reading between the lines
- If vulnerability rankings prove stable for additional scales, the same proxy-trained controller could be reused across an entire family of models without per-scale relearning.
- The method implies that validation-loss trajectories on a small model can serve as a cheap surrogate for deciding replay priorities on larger models in production continual-learning pipelines.
- Settings where the mirroring assumption fails, as the paper already flags, indicate the need for lightweight on-target recalibration triggers rather than full retraining.
- The approach could extend to other continual-learning regimes such as vision or multimodal models if similar ranking consistency is observed.
Load-bearing premise
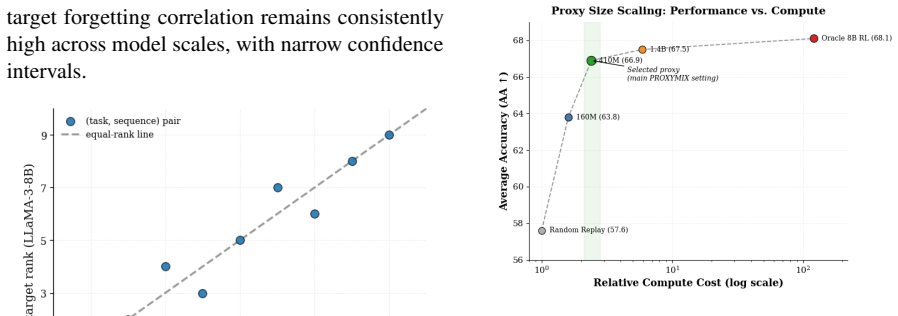
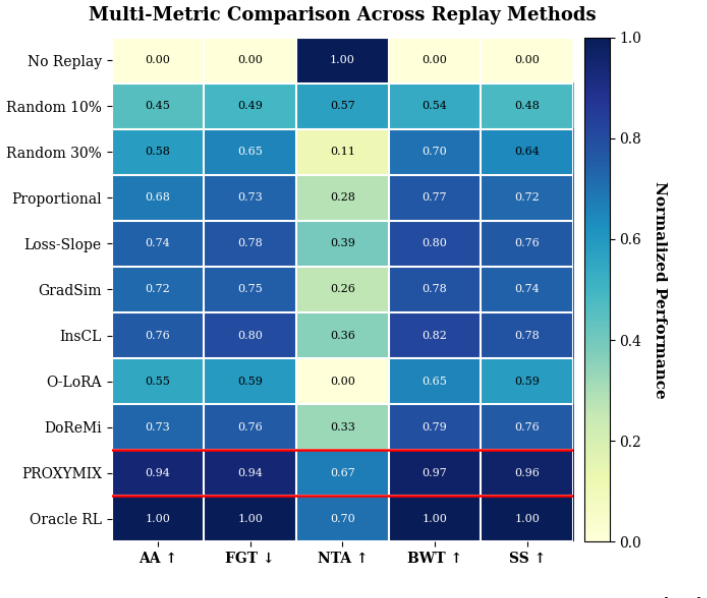
Relative rankings of how quickly different prior tasks are forgotten stay consistent when the same sequence is run on a small proxy versus a large target model.
What would settle it
A continual tuning sequence in which the ranked order of final forgetting rates on the proxy model differs markedly from the order observed on the target model after identical task ordering.
Figures
read the original abstract
Continual instruction tuning updates a language model through a sequence of new domains, yet each update can progressively erode previously learned capabilities and alignment behavior. Replay is the standard mitigation, but fixed replay ratios are inherently limited because the optimal mixture varies with the current domain, the training stage, and the evolving vulnerability of prior behaviors. We propose PROX-YMIX, a framework that learns a dynamic replay controller on a small proxy model and transfers the frozen controller to a larger target. The controller never observes future tasks and constructs its state from normalized validation losses and their temporal dynamics, producing a masked mixture over the current task and accessible replay buffers. Our core empirical hypothesis is forgetting mirroring: task vulnerability rankings remain largely consistent across model scales even when absolute loss magnitudes differ. We validate this assumption empirically before transferring controllers across scales. On LLaMA-3-8B across five continual instruction tuning sequences, PROXYMIX improves average accuracy by 3.4 points, reduces final forgetting by 3.5 points, and raises safety score by 5.8 points over the strongest non-oracle baseline, at roughly 50x lower policy learning cost than Oracle Target RL. The framework is leakage free and architecture independent at the interface level, and we also identify settings where the proxy assumption breaks down, highlighting limitations for robust deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PROXYMIX, a framework that trains a dynamic replay controller on a small proxy model using normalized validation losses and their temporal dynamics (without observing future tasks), then transfers the frozen controller to a larger target model for continual instruction tuning. The central hypothesis is 'forgetting mirroring,' i.e., that relative task vulnerability rankings remain consistent across scales despite differing absolute losses; this is validated empirically on the proxy before transfer. On LLaMA-3-8B across five sequences, it reports +3.4 average accuracy, -3.5 final forgetting, and +5.8 safety over the strongest non-oracle baseline, at ~50x lower policy-learning cost than Oracle Target RL. The method is described as leakage-free and architecture-independent at the interface, with some settings where the proxy assumption breaks down.
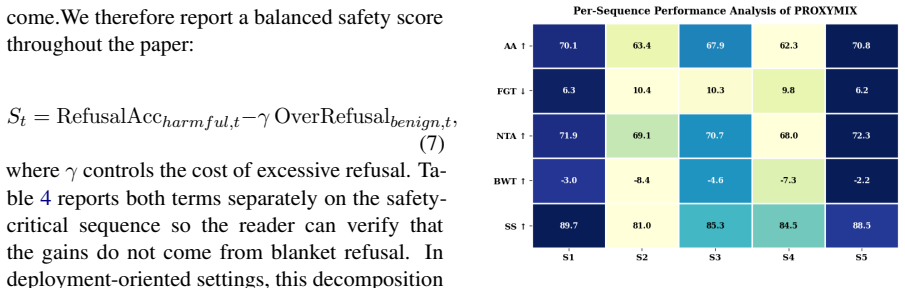
Significance. If the mirroring hypothesis is robust, the approach would enable substantial cost savings in continual instruction tuning by avoiding full-scale policy optimization while preserving replay effectiveness. The explicit identification of breakdown cases and the leakage-free design are positive features. However, the transfer claim rests on indirect evidence, as the required invariance is tested only at proxy scale.
major comments (2)
- [Abstract / hypothesis validation section] Abstract and the section describing the forgetting-mirroring validation: the hypothesis that task vulnerability rankings are preserved across scales is validated exclusively via proxy-scale runs; no direct ranking comparison (e.g., Spearman correlation of per-task forgetting or loss trajectories) is reported on the target-scale model, leaving open the possibility that orderings diverge only at the target scale and thereby undermining the controlled test of transferability.
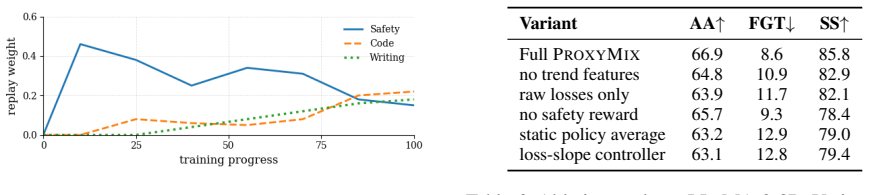
- [Experimental results] Experimental results section (the LLaMA-3-8B tables): the reported gains of 3.4 accuracy / 3.5 forgetting / 5.8 safety are presented without error bars, number of random seeds, or full ablation tables isolating the contribution of the transferred controller versus the proxy training itself; this makes it impossible to judge whether the improvements are statistically reliable or driven by the mirroring assumption.
minor comments (2)
- [Methods] Notation for the controller state (normalized losses and temporal dynamics) should be defined with explicit equations in the methods section to clarify how masking is applied to the mixture.
- [Framework description] The claim of 'architecture independent at the interface level' would benefit from a brief statement of the exact interface contract (input features to the controller) rather than leaving it implicit.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and detailed comments on our submission. These suggestions will help strengthen the presentation of our method and results. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract / hypothesis validation section] Abstract and the section describing the forgetting-mirroring validation: the hypothesis that task vulnerability rankings are preserved across scales is validated exclusively via proxy-scale runs; no direct ranking comparison (e.g., Spearman correlation of per-task forgetting or loss trajectories) is reported on the target-scale model, leaving open the possibility that orderings diverge only at the target scale and thereby undermining the controlled test of transferability.
Authors: The observation is accurate: our empirical validation of the forgetting-mirroring hypothesis, including consistency of task vulnerability rankings, is conducted on the proxy model. We do not report direct comparisons such as Spearman correlations on the target model. This is because obtaining such rankings on the target would necessitate extensive sequential training runs on the large model, which the proxy-based approach is designed to circumvent. The transfer success and reported improvements on LLaMA-3-8B provide supporting evidence for the hypothesis holding at target scale. We will revise the relevant sections to explicitly note the proxy-scale validation and discuss the practical challenges of target-scale verification. revision: partial
-
Referee: [Experimental results] Experimental results section (the LLaMA-3-8B tables): the reported gains of 3.4 accuracy / 3.5 forgetting / 5.8 safety are presented without error bars, number of random seeds, or full ablation tables isolating the contribution of the transferred controller versus the proxy training itself; this makes it impossible to judge whether the improvements are statistically reliable or driven by the mirroring assumption.
Authors: We acknowledge the absence of error bars, specification of random seeds, and detailed ablations in the presented tables. The gains are averaged across the five sequences, but variance and seed details were not included. We will incorporate error bars based on available runs, specify the number of seeds, and provide additional ablation tables to isolate the contributions of the transferred controller and the proxy training process in the revised manuscript. revision: yes
- Providing a direct ranking comparison (e.g., Spearman correlation) of task vulnerability on the target-scale model, as this would require the high computational resources the method aims to reduce.
Circularity Check
No circularity; empirical proxy-to-target transfer with stated proxy validation
full rationale
The paper describes learning a replay controller on a small proxy model from normalized validation losses and temporal dynamics, then transferring the frozen controller to a larger target under the forgetting-mirroring hypothesis. This hypothesis is described as validated empirically on the proxy before transfer. No equations, definitions, or self-citations are shown that reduce the transferred controller outputs, the target-scale results, or the reported accuracy/forgetting/safety gains to a quantity fitted on the target or defined in terms of itself. The central empirical claims on LLaMA-3-8B remain independent measurements rather than tautological restatements of proxy inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Task vulnerability rankings remain largely consistent across model scales even when absolute loss magnitudes differ
Reference graph
Works this paper leans on
-
[1]
The Twelfth International Conference on Learning Representations , year =
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! , author =. The Twelfth International Conference on Learning Representations , year =
-
[2]
Removing
Zhan, Qiusi and Fang, Richard and Bindu, Rohan and Gupta, Akul and Hashimoto, Tatsunori and Kang, Daniel , booktitle =. Removing. 2024 , doi =
2024
-
[4]
, booktitle =
Rebuffi, Sylvestre-Alvise and Kolesnikov, Alexander and Sperl, Georg and Lampert, Christoph H. , booktitle =. 2017 , url =
2017
-
[5]
Proceedings of the National Academy of Sciences , volume =
Overcoming Catastrophic Forgetting in Neural Networks , author =. Proceedings of the National Academy of Sciences , volume =. 2017 , doi =
2017
-
[6]
Proceedings of the 34th International Conference on Machine Learning , pages =
Continual Learning Through Synaptic Intelligence , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , url =
2017
-
[8]
Advances in Neural Information Processing Systems , volume =
Gradient Episodic Memory for Continual Learning , author =. Advances in Neural Information Processing Systems , volume =. 2017 , url =
2017
-
[9]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =
Orthogonal Subspace Learning for Language Model Continual Learning , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =. 2023 , doi =
2023
-
[10]
2024 , doi =
Wang, Yifan and Liu, Yafei and Shi, Chufan and Li, Haoling and Chen, Chen and Lu, Haonan and Yang, Yujiu , booktitle =. 2024 , doi =
2024
-
[11]
2023 , url =
Wang, Xiao and Zhang, Yuansen and Chen, Tianze and Gao, Songyang and Jin, Senjie and Yang, Xianjun and Xi, Zhiheng and Zheng, Rui and Zou, Yicheng and Gui, Tao and Zhang, Qi and Huang, Xuanjing , journal =. 2023 , url =
2023
-
[12]
Advances in Neural Information Processing Systems , volume =
Data Selection for Language Models via Importance Resampling , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[13]
2023 , url =
Du, Qianlong and Zong, Chengqing and Zhang, Jiajun , journal =. 2023 , url =
2023
-
[14]
2024 , url =
Chen, Lichang and Li, Shiyang and Yan, Jun and Wang, Hai and Gunaratna, Kalpa and Yadav, Vikas and Tang, Zheng and Srinivasan, Vijay and Zhou, Tianyi and Huang, Heng and Jin, Hongxia , booktitle =. 2024 , url =
2024
-
[15]
and Ma, Tengyu and Yu, Adams Wei , booktitle =
Xie, Sang Michael and Pham, Hieu and Dong, Xuanyi and Du, Nan and Liu, Hanxiao and Lu, Yifeng and Liang, Percy and Le, Quoc V. and Ma, Tengyu and Yu, Adams Wei , booktitle =. 2023 , url =
2023
-
[17]
and Babuschkin, Igor and Sidor, Szymon and Liu, Xiaodong and Farhi, David and Ryder, Nick and Pachocki, Jakub and Chen, Weizhu and Gao, Jianfeng , booktitle =
Yang, Greg and Hu, Edward J. and Babuschkin, Igor and Sidor, Szymon and Liu, Xiaodong and Farhi, David and Ryder, Nick and Pachocki, Jakub and Chen, Weizhu and Gao, Jianfeng , booktitle =. Tensor Programs. 2021 , url =
2021
-
[18]
The Twelfth International Conference on Learning Representations , year =
Small-scale Proxies for Large-scale Transformer Training Instabilities , author =. The Twelfth International Conference on Learning Representations , year =
-
[20]
2023 , doi =
Zhang, Zihan and Fang, Meng and Chen, Ling and Namazi-Rad, Mohammad-Reza , booktitle =. 2023 , doi =
2023
-
[23]
Proceedings of the 40th International Conference on Machine Learning , series =
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling , author =. Proceedings of the 40th International Conference on Machine Learning , series =. 2023 , url =
2023
-
[25]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=. 2022 , url=
2022
-
[26]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[27]
Istabrak Abbes, Gopeshh Subbaraj, Matthew Riemer, Nizar Islah, Benjamin Therien, Tsuguchika Tabaru, Hiroaki Kingetsu, Sarath Chandar, and Irina Rish. 2025. https://arxiv.org/abs/2508.01908 Revisiting replay and gradient alignment for continual pre-training of large language models . arXiv preprint arXiv:2508.01908
-
[28]
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. 2023. https://proceedings.mlr.press/v202/biderman23a.html Pythia: A suite for analyzing large language models across training and...
2023
-
[29]
On Tiny Episodic Memories in Continual Learning
Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajanthan, Puneet K. Dokania, Philip H. S. Torr, and Marc'Aurelio Ranzato. 2019. https://arxiv.org/abs/1902.10486 On tiny episodic memories in continual learning . arXiv preprint arXiv:1902.10486
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[30]
Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, and Hongxia Jin. 2024. https://openreview.net/forum?id=FdVXgSJhvz AlpaGasus : Training a better alpaca with fewer data . In The Twelfth International Conference on Learning Representations
2024
- [31]
-
[32]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L \'e lio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth \'e e Lacroix, and William El Sayed. 2023. https://arxiv.org/ab...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. 2017. https://doi.org/10.1073/pnas.1611835114 Overcoming catastrophic forgetting in neural networks . Proceedings of...
-
[35]
David Lopez-Paz and Marc'Aurelio Ranzato. 2017. https://proceedings.neurips.cc/paper/2017/hash/f87522788a2be2d171666752f97ddebb-Abstract.html Gradient episodic memory for continual learning . In Advances in Neural Information Processing Systems, volume 30
2017
-
[36]
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. 2024. https://openreview.net/forum?id=hTEGyKf0dZ Fine-tuning aligned language models compromises safety, even when users do not intend to! In The Twelfth International Conference on Learning Representations
2024
-
[37]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H. Lampert. 2017. https://openaccess.thecvf.com/content_cvpr_2017/html/Rebuffi_iCaRL_Incremental_Classifier_CVPR_2017_paper.html iCaRL : Incremental classifier and representation learning . In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2001--2010
2017
-
[38]
Andrei A. Rusu, Neil C. Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. 2016. https://arxiv.org/abs/1606.04671 Progressive neural networks . arXiv preprint arXiv:1606.04671
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[39]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. https://arxiv.org/abs/1707.06347 Proximal policy optimization algorithms . arXiv preprint arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang. 2025. https://doi.org/10.1145/3735633 Continual learning of large language models . ACM Computing Surveys
-
[41]
Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuanjing Huang. 2023 a . https://doi.org/10.18653/v1/2023.findings-emnlp.715 Orthogonal subspace learning for language model continual learning . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 10658--10671, Singapore. Association for Co...
-
[42]
Xiao Wang, Yuansen Zhang, Tianze Chen, Songyang Gao, Senjie Jin, Xianjun Yang, Zhiheng Xi, Rui Zheng, Yicheng Zou, Tao Gui, Qi Zhang, and Xuanjing Huang. 2023 b . https://arxiv.org/abs/2310.06762 TRACE : A comprehensive benchmark for continual learning in large language models . arXiv preprint arXiv:2310.06762
-
[43]
Yifan Wang, Yafei Liu, Chufan Shi, Haoling Li, Chen Chen, Haonan Lu, and Yujiu Yang. 2024. https://doi.org/10.18653/v1/2024.naacl-long.37 InsCL : A data-efficient continual learning paradigm for fine-tuning large language models with instructions . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Lin...
-
[44]
Liu, Lechao Xiao, Katie E
Mitchell Wortsman, Peter J. Liu, Lechao Xiao, Katie E. Everett, Alexander A. Alemi, Ben Adlam, John D. Co-Reyes, Izzeddin Gur, Abhishek Kumar, Roman Novak, Jeffrey Pennington, Jascha Sohl-Dickstein, Kelvin Xu, Jaehoon Lee, Justin Gilmer, and Simon Kornblith. 2024. https://openreview.net/forum?id=d8w0pmvXbZ Small-scale proxies for large-scale transformer t...
2024
-
[45]
Le, Tengyu Ma, and Adams Wei Yu
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy Liang, Quoc V. Le, Tengyu Ma, and Adams Wei Yu. 2023 a . https://proceedings.neurips.cc/paper_files/paper/2023/hash/dcba6be91359358c2355cd920da3fcbd-Abstract-Conference.html DoReMi : Optimizing data mixtures speeds up language model pretraining . In Advances in Neural Informat...
2023
-
[46]
Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang. 2023 b . https://proceedings.neurips.cc/paper_files/paper/2023/hash/6b9aa8f418bde2840d5f4ab7a02f663b-Abstract-Conference.html Data selection for language models via importance resampling . In Advances in Neural Information Processing Systems, volume 36
2023
-
[47]
Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao
Greg Yang, Edward J. Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. 2021. https://proceedings.neurips.cc/paper/2021/hash/8df7c2e3c3c3be098ef7b382bd2c37ba-Abstract.html Tensor programs V : Tuning large neural networks via zero-shot hyperparameter transfer . In Advances in Neural Info...
2021
-
[48]
Kailai Yang, Xiao Liu, Lei Ji, Hao Li, Xiao Liang, Zhiwei Liu, Yeyun Gong, Peng Cheng, and Mao Yang. 2025. https://arxiv.org/abs/2507.15640 Data mixing agent: Learning to re-weight domains for continual pre-training . arXiv preprint arXiv:2507.15640
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Friedemann Zenke, Ben Poole, and Surya Ganguli. 2017. https://proceedings.mlr.press/v70/zenke17a.html Continual learning through synaptic intelligence . In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 3987--3995. PMLR
2017
-
[50]
Qiusi Zhan, Richard Fang, Rohan Bindu, Akul Gupta, Tatsunori Hashimoto, and Daniel Kang. 2024. https://doi.org/10.18653/v1/2024.naacl-short.59 Removing RLHF protections in GPT-4 via fine-tuning . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Shor...
-
[51]
Zihan Zhang, Meng Fang, Ling Chen, and Mohammad-Reza Namazi-Rad. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.633 CITB : A benchmark for continual instruction tuning . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9443--9455, Singapore. Association for Computational Linguistics
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.