Sample-Efficient Optimisation over the Outputs of Generative Models
Pith reviewed 2026-05-18 12:55 UTC · model grok-4.3
The pith
Surrogate latent spaces let standard optimizers find higher-scoring outputs from generative models than direct latent-space search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that low-dimensional surrogate latent spaces, which are Euclidean embeddings extracted from a generative model without additional training, preserve enough task-relevant structure to let standard black-box optimisers locate substantially higher-scoring samples than optimisation performed directly in the model's native latent space, as shown on image and protein design tasks.
What carries the argument
Surrogate latent spaces: low-dimensional Euclidean embeddings extracted from a generative model without additional training; these spaces provide controllable dimensionality and allow direct application of standard optimisation algorithms.
If this is right
- Surrogate-space optimisation finds substantially higher-scoring samples than standard sampling or optimisation in the original latent space on image and protein design tasks.
- The method applies to both diffusion and flow-matching models without modification.
- It remains agnostic to the particular generative model and to the choice of black-box optimiser.
- It adds negligible extra computation beyond ordinary generation and requires no retraining.
- The dimensionality of the surrogate space can be chosen by the user to suit the optimisation problem.
Where Pith is reading between the lines
- The same embedding extraction step could be tested on other generative architectures to see whether controllable low-dimensional surrogates improve optimisation in additional domains.
- If the embeddings keep task structure, the approach offers a route to optimisation in high-dimensional scientific design settings where direct search is expensive.
- Controllable dimensionality provides a practical knob for trading representation fidelity against optimisation speed that future work could tune systematically.
Load-bearing premise
Low-dimensional Euclidean embeddings extracted from a generative model without additional training preserve enough task-relevant structure to support effective application of standard black-box optimizers.
What would settle it
An experiment on the image or protein design tasks in which optimisation performed inside the surrogate space does not return higher-scoring samples than optimisation inside the original latent space or than standard sampling.
Figures






read the original abstract
Modern generative AI models, such as diffusion and flow matching models, can sample from rich data distributions. However, many applications, especially in science and engineering, require more than drawing samples from the model distribution: they require searching within this distribution for samples that optimise task-specific criteria. In this work, we propose O3 (Optimisation Over the Outputs of Generative Models), a method for sample-efficient black-box optimisation over continuous-variable diffusion and flow-matching models. O3 is built around surrogate latent spaces: low-dimensional Euclidean embeddings that can be extracted from a generative model without additional training. The resulting representations have controllable dimensionality and support the direct application of standard optimisation algorithms. We show, on image and protein design tasks, that surrogate-space optimisation finds substantially higher-scoring samples than standard sampling or optimisation in the original latent space. Our method is model- and optimiser-agnostic, incurs negligible additional cost over standard generation, and requires no retraining or fine-tuning of the generative model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes O3, a method for sample-efficient black-box optimisation over the outputs of continuous-variable generative models such as diffusion and flow-matching models. It introduces surrogate latent spaces consisting of low-dimensional Euclidean embeddings extracted from the generative model without additional training or fine-tuning. These embeddings support the direct application of standard optimisation algorithms. Experiments on image and protein design tasks are reported to show that optimisation in the surrogate space yields substantially higher-scoring samples than standard sampling or optimisation performed in the original latent space. The method is presented as model- and optimiser-agnostic with negligible additional computational cost.
Significance. If the central empirical claims hold after validation, the work offers a practical, low-overhead approach to task-driven search within generative model distributions that avoids retraining. The model-agnostic design and emphasis on controllable dimensionality without extra training are clear strengths that could benefit scientific applications such as protein design. The significance is tempered by the need to confirm that observed gains arise from preserved task-relevant structure rather than incidental effects of dimensionality reduction.
major comments (2)
- [Experiments / Results] The central claim that surrogate-space optimisation finds substantially higher-scoring samples rests on the assumption that low-dimensional embeddings extracted without retraining preserve sufficient task-relevant structure for standard black-box optimisers. The manuscript reports only end-to-end performance gains versus latent-space baselines and does not provide direct supporting evidence such as correlations between surrogate coordinates and task scores or ablations on embedding extraction and dimensionality (see Experiments and Results sections).
- [Method] The description of surrogate latent spaces as independent of the downstream objective is load-bearing for the claim of broad applicability, yet no quantitative checks are supplied to verify alignment between Euclidean geometry in the surrogate space and the true task objective (see Method section on surrogate construction).
minor comments (1)
- [Abstract] The abstract states performance gains on two task families but supplies no quantitative details, baselines, error bars, or exclusion criteria; adding these would improve clarity and verifiability.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment below, providing clarifications and indicating where we will strengthen the manuscript with additional analyses in the revision.
read point-by-point responses
-
Referee: The central claim that surrogate-space optimisation finds substantially higher-scoring samples rests on the assumption that low-dimensional embeddings extracted without retraining preserve sufficient task-relevant structure for standard black-box optimisers. The manuscript reports only end-to-end performance gains versus latent-space baselines and does not provide direct supporting evidence such as correlations between surrogate coordinates and task scores or ablations on embedding extraction and dimensionality (see Experiments and Results sections).
Authors: We agree that direct supporting analyses would improve interpretability of the results. While the primary contribution is the demonstrated end-to-end performance improvement on concrete tasks, we acknowledge that ablations on dimensionality and correlations between surrogate coordinates and task scores would help distinguish preserved structure from incidental effects of reduction. In the revised manuscript we will add these analyses to the Experiments section, including dimensionality sweeps and selected correlation metrics on the image and protein tasks. revision: yes
-
Referee: The description of surrogate latent spaces as independent of the downstream objective is load-bearing for the claim of broad applicability, yet no quantitative checks are supplied to verify alignment between Euclidean geometry in the surrogate space and the true task objective (see Method section on surrogate construction).
Authors: The construction of the surrogate spaces is deliberately independent of any downstream objective, which is essential for the claimed generality. We recognise that explicit quantitative verification of geometric alignment would strengthen this claim. In the revision we will augment the Method section with checks that quantify how well Euclidean distances or local geometry in the surrogate space relate to task-score differences, for example via rank correlations on sampled pairs or proxy alignment metrics computed on held-out data. revision: yes
Circularity Check
No circularity: method and claims are self-contained empirical proposal
full rationale
The paper introduces O3 as a new surrogate-space optimization procedure whose core construction (low-dimensional embeddings extracted from a frozen generative model) is described as independent of the downstream task objective. The central claims rest on end-to-end empirical comparisons against latent-space baselines on image and protein tasks rather than on any fitted parameter being relabeled as a prediction or on a self-citation chain that supplies the uniqueness or correctness of the approach. No equations or steps in the provided description reduce the reported gains to a definitional identity or to a prior result whose only support is the authors' own unverified work. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- surrogate dimensionality
axioms (1)
- domain assumption Generative models produce samples from rich continuous data distributions that contain high-value regions according to external task criteria.
invented entities (1)
-
surrogate latent space
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
surrogate latent spaces: non-parametric, low-dimensional Euclidean embeddings … ϕw:U→SK−1+ … l:SK−1+→Z … Knothe–Rosenblatt chart … cosine similarity simz(zi,zj)=(ξwi)⊺(ξwj)/…
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three key principles … P3 Stationarity: relationship between objects’ similarity as a function of their Euclidean distance … approximately maintained
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Erik Bodin, Alexandru Stere, Dragos D Margineantu, Carl Henrik Ek, and Henry Moss. Linear com- binations of latents in generative models: subspaces and beyond.arXiv preprint arXiv:2408.08558,
-
[2]
Inversion-based latent bayesian optimization.arXiv preprint arXiv:2411.05330,
Jaewon Chu, Jinyoung Park, Seunghun Lee, and Hyunwoo J Kim. Inversion-based latent bayesian optimization.arXiv preprint arXiv:2411.05330,
-
[3]
Iterative importance fine-tuning of diffusion models.arXiv preprint arXiv:2502.04468,
Alexander Denker, Shreyas Padhy, Francisco Vargas, and Johannes Hertrich. Iterative importance fine-tuning of diffusion models.arXiv preprint arXiv:2502.04468,
-
[4]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
work page 2019
-
[5]
Carles Domingo-Enrich, Michal Drozdzal, Brian Karrer, and Ricky TQ Chen. Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control. arXiv preprint arXiv:2409.08861,
-
[6]
Zach Evans, Julian D Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons. Stable audio open. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE,
work page 2025
-
[7]
Antoine Grosnit, Rasul Tutunov, Alexandre Max Maraval, Ryan-Rhys Griffiths, Alexander I Cowen- Rivers, Lin Yang, Lin Zhu, Wenlong Lyu, Zhitang Chen, Jun Wang, et al. High-dimensional bayesian optimisation with variational autoencoders and deep metric learning.arXiv preprint arXiv:2106.03609,
-
[8]
The CMA Evolution Strategy: A Tutorial
Nikolaus Hansen. The cma evolution strategy: A tutorial.arXiv preprint arXiv:1604.00772,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
James Kennedy and Russell Eberhart. Particle swarm optimization. InProceedings of ICNN’95- international conference on neural networks, volume 4, pp. 1942–1948. ieee,
work page 1942
-
[10]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Grammar variational autoencoder
Matt J Kusner, Brooks Paige, and José Miguel Hernández-Lobato. Grammar variational autoencoder. InInternational conference on machine learning, pp. 1945–1954. PMLR,
work page 1945
-
[13]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representa- tions in vector space.arXiv preprint arXiv:1301.3781,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
cmaes: A Simple yet Practical Python Library for CMA-ES.arXiv preprint arXiv:2402.01373, 2026
Masahiro Nomura and Masashi Shibata. cmaes: A simple yet practical python library for cma-es. arXiv preprint arXiv:2402.01373,
-
[16]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020a. Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020b. 12 Harald Steck, Chai...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[17]
Watson, David Juergens, Nathaniel R
ISSN 1476-4687. doi: 10.1038/s41586-023-06415-8. URL http://dx.doi.org/10.1038/s41586-023-06415-8. Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935,
-
[18]
Lemma 1.Let {zk}K k=1 ⊂Z be seeds, and define their inner latents ϵk =T →(zk). Let ξ= [ϵ1, . . . ,ϵK]∈RD×K. Assume: (A1)ξhas full column rank, so thatξ +ξ=I K; (A2) For allϵ∈R D, T→(T←(ϵ)) =α(ϵ)ϵ, α(ϵ)>0. Define thelmap l(w,{z k})=T ←(ξw),w∈S K−1 + . Thenlis invertible with l−1(z,{z k})= ξ+ T→(z) ∥ξ+ T→(z)∥. Proof.Letz=l(w,{z k})=T ←(ξw). ApplyingT → and ...
work page 2024
-
[19]
and θk =arccos (wk/ ∏k−1 i=1 sinθ i) for k≥2 , then ui = 2 π θi.Notes: smooth,notequal-area. Knothe–Rosenblatt (KR) chart.LetU∈(0,1) K−1and define independent stick-breaks vk =I −1 uk( 1 2 , K−k 2 ), k=1, . . . , K−1, whereI −1 ⋅(a, b)is the inverse regularised incomplete beta. Set (Dirichlet stick-breaking) z1 =v 1, z k =v k k−1 ∏ i=1 (1−vi) (k=2, . . . ...
work page 2022
-
[20]
(2024) has a dimensionality of severalmillion
have aD oftens of thousandstohundreds of thousands, and Kong et al. (2024) has a dimensionality of severalmillion. E GOOD EXAMPLES DEFINE SPACES WITH BETTER SOLUTIONS:DETAILS For our surrogate spaces to be useful they need to contain varied objects that share characteristics with the seed latents; especially those attributes that impact targeted objective...
work page 2024
-
[21]
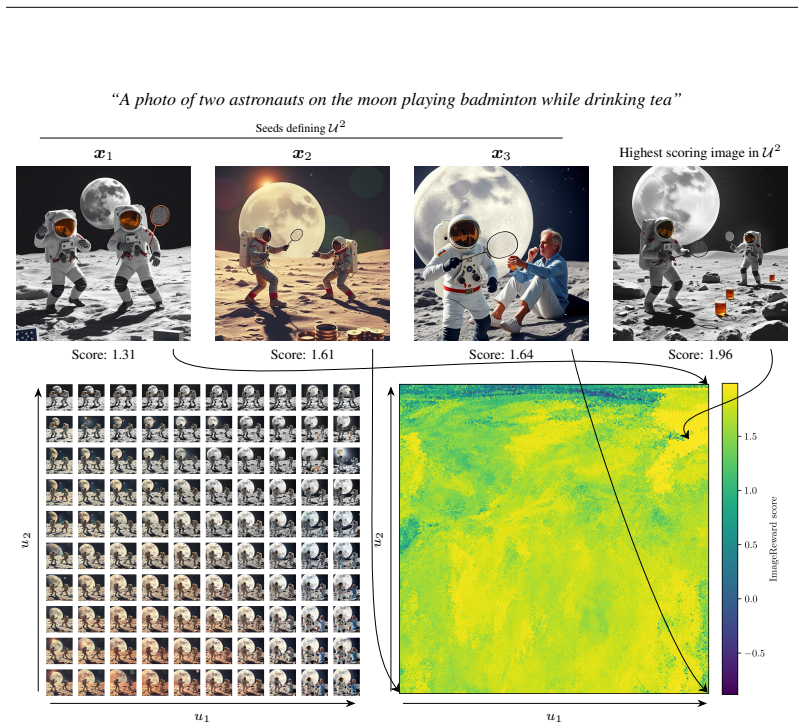
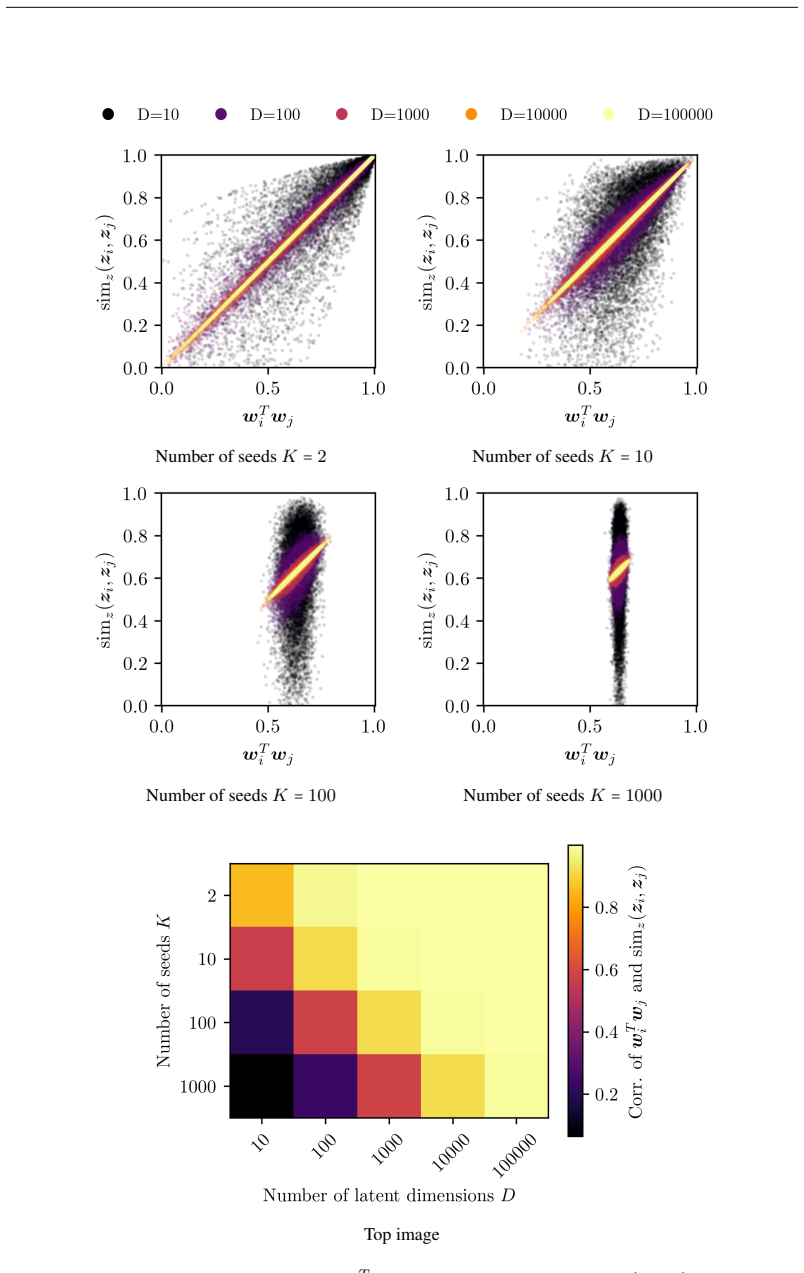
that score highly according to ImageReward (Xu et al., 2023), a 15 Number of seedsK=2 Number of seedsK=10 Number of seedsK=100 Number of seedsK=1000 Top image Figure 6: (top) Dot products of the weightswT i wj and the cosine similaritysimϵ(ϵi,ϵ j) for uniformly drawn samples in U for K=2,10,100,1000 , respectively for various dimensions D, where ϵ∈RD. The...
work page 2023
-
[22]
embeddings of the images. Results: We test our surrogate spaces by seeing if we can form 100 generations (gridded over the surrogate space) that are both good (well-aligned with the target prompt) and diverse. To generate the seed latents that define our surrogate space, we use a budget of S random generations and pick the top K (a stand-in for having a-p...
work page 2025
-
[23]
model. Specifically, the model is given a general prompt (‘A vehicle’) and the objective is obtain high Pick-scores for a prompt sampled randomly from a grammar composed of three parts as ‘A <attribute> <vehicle type> <environment>’, forming a million possible combinations. The grammar is given in Section K. The sampled target prompts are hidden from the ...
work page 2024
-
[24]
and the author’s official implementation. •Random search inU. Uniform, independent sampling inU. • Random search in Z. Standard random (and independent) sampling from the latent distribution. • CMA-ES in Z. CMA-ES deployed on [0,1]D, where evaluations are mapped to latent distribution samples via the inverse Gaussian CDF. H WEIGHT CHART OPTIMISATION COMPA...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.