Escaping the Variance Trap: Jacobian-Free Dynamics for Root-Finding Bilevel Optimization
Pith reviewed 2026-06-26 10:54 UTC · model grok-4.3
The pith
Root-finding bilevel problems are solved by updating directly along the root error with Jacobian-free two-time-scale stochastic approximation, avoiding variance amplification from implicit Jacobians.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Root-finding bilevel optimization is formalized as a problem class separate from minimization; the proposed TTSA method updates parameters along the root error without computing or inverting Jacobians, thereby structurally preventing the noise amplification that occurs when hypergradients are estimated from stochastic residuals, and the analysis supplies non-asymptotic convergence rates for this dynamics under Markovian noise.
What carries the argument
Two-Time-Scale Stochastic Approximation (TTSA) that updates directly along the root error instead of via hypergradients.
If this is right
- The method achieves a 2.6% top-1 accuracy gain on SimCLR relative to squared-residual and implicit-gradient baselines.
- It produces 17 times faster convergence on non-linear ODE control tasks where the baselines fail to converge.
- Entropy stability improves in reinforcement learning tasks compared with minimization-based approaches.
- Generative modeling quality rises by 11.1% when the root-finding formulation replaces squared-residual training.
Where Pith is reading between the lines
- The same root-error framing may simplify training loops for other equilibrium-seeking models that currently rely on implicit differentiation.
- Because the guarantees hold under Markovian noise, the approach could extend to online settings where data arrive sequentially rather than in i.i.d. batches.
- Implementation cost may drop in large models since no Jacobian or Hessian-vector products are required at each step.
Load-bearing premise
That hypergradient estimates involving implicit Jacobians necessarily amplify variance in stochastic bilevel settings while direct root-error updates avoid this amplification.
What would settle it
A controlled stochastic root-finding task in which the TTSA method shows no improvement in convergence speed or stability over squared-residual baselines when both are run with identical Markovian noise and step-size schedules.
Figures


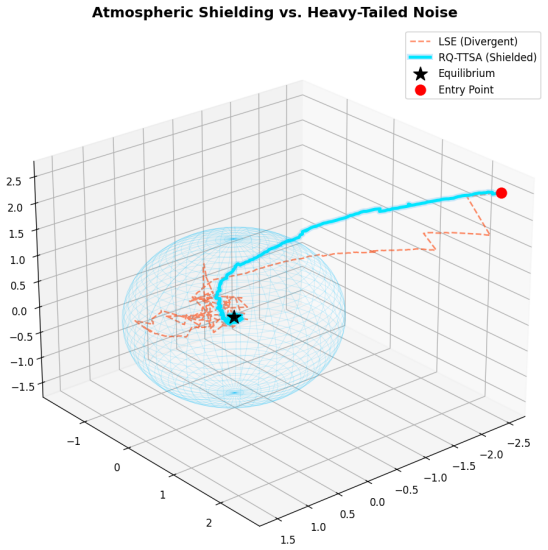
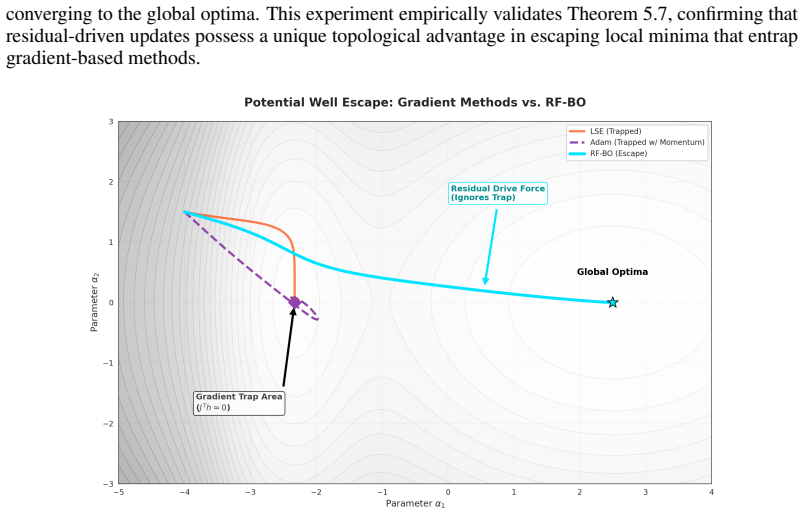
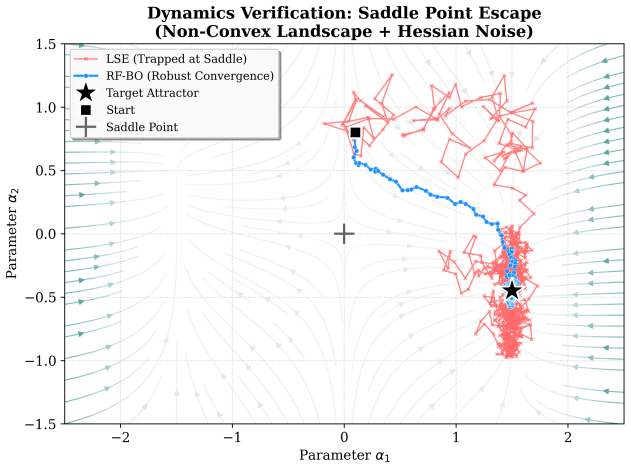
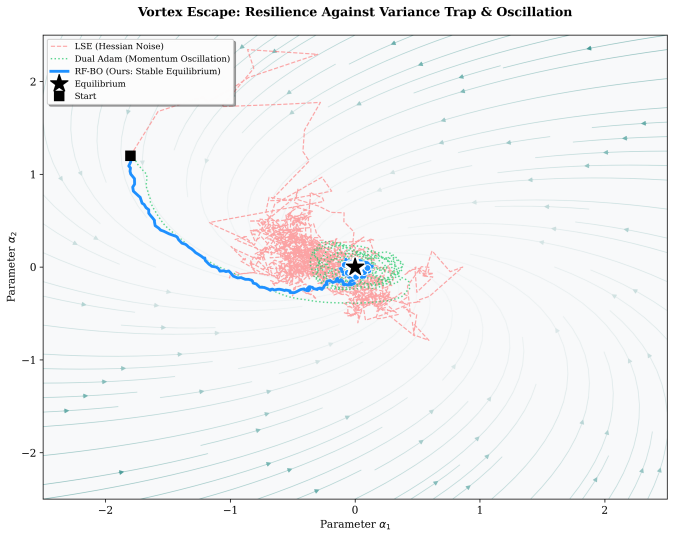
read the original abstract
Many central machine learning tasks, from entropy tuning in reinforcement learning to equilibrating generative adversarial networks, are fundamentally stochastic root-finding problems rather than loss minimization. Yet, they are frequently forced into a minimization framework via squared residuals, introducing a critical flaw we identify as the Variance Trap. Standard bilevel minimization algorithms require estimating hypergradients involving implicit Jacobians; in stochastic settings, these terms act as noise amplifiers, destabilizing convergence. We formalize Root-Finding Bilevel Optimization (RF-BO) as a distinct problem class that bypasses this pathology. We propose a Jacobian-free solution using Two-Time-Scale Stochastic Approximation (TTSA) that updates directly along the root error, structurally avoiding variance amplification. We provide the first non-asymptotic convergence guarantees for TTSA in this setting under Markovian noise. Extensive experiments demonstrate the decisive advantage of this paradigm: compared to squared-residual and implicit-gradient baselines, our framework achieves a 2.6\% top-1 accuracy gain in SimCLR, 17$\times$ faster convergence in non-linear ODE control where baselines fail, significantly improved entropy stability in reinforcement learning, and an 11.1\% quality improvement in generative modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard stochastic bilevel minimization suffers from a 'Variance Trap' due to implicit Jacobians acting as noise amplifiers; it formalizes Root-Finding Bilevel Optimization (RF-BO) as an alternative, proposes Jacobian-free TTSA updates directly on the root error, supplies the first non-asymptotic convergence guarantees for TTSA under Markovian noise, and reports empirical gains (2.6% SimCLR accuracy, 17× faster ODE control convergence, improved RL entropy stability, 11.1% generative modeling quality) over squared-residual and implicit-gradient baselines.
Significance. If the non-asymptotic TTSA guarantees hold under reasonable Markovian assumptions and the experiments are reproducible, the reframing offers a structurally cleaner approach to stochastic bilevel problems common in RL, GANs, and hyperparameter optimization; the explicit provision of the first such guarantees is a concrete strength that could influence algorithm design in the area.
major comments (2)
- [Abstract] Abstract: the central claim of 'first non-asymptotic convergence guarantees for TTSA in this setting under Markovian noise' is load-bearing, yet the text supplies neither a proof sketch nor an explicit list of assumptions on the Markov chain (mixing time, ergodicity, step-size conditions), preventing verification of the result from the provided material.
- [Abstract] Abstract (experimental claims): the reported gains (2.6% top-1 accuracy, 17× faster convergence, 11.1% quality improvement) are presented without any statement of experimental protocol, statistical testing, or baseline implementation details, which are required to substantiate the 'decisive advantage' assertion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'first non-asymptotic convergence guarantees for TTSA in this setting under Markovian noise' is load-bearing, yet the text supplies neither a proof sketch nor an explicit list of assumptions on the Markov chain (mixing time, ergodicity, step-size conditions), preventing verification of the result from the provided material.
Authors: We agree that the abstract does not contain a proof sketch or explicit assumptions, which limits immediate verification. The full manuscript provides the complete non-asymptotic analysis in Appendix A (including the proof) and states the Markov chain assumptions (mixing time, ergodicity, and step-size conditions) explicitly in Section 3.2 and Theorem 4.1. To address the concern, we will revise the abstract to briefly reference these sections and list the key assumptions. This change will make the claim verifiable without altering the technical content. revision: yes
-
Referee: [Abstract] Abstract (experimental claims): the reported gains (2.6% top-1 accuracy, 17× faster convergence, 11.1% quality improvement) are presented without any statement of experimental protocol, statistical testing, or baseline implementation details, which are required to substantiate the 'decisive advantage' assertion.
Authors: The detailed experimental protocols, statistical testing (multiple independent runs with reported means and standard deviations), and baseline implementation specifics are provided in Section 5 and the associated appendices. We acknowledge that the abstract would be strengthened by a concise reference to the evaluation setup. We will add one sentence to the abstract summarizing the protocol and directing readers to Section 5 for full details. This revision will better substantiate the empirical claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and claims introduce RF-BO as a reframing of bilevel problems and apply standard TTSA to root-error updates, with no equations, fitted parameters, or self-citations appearing that would reduce any convergence guarantee or prediction to a self-definitional input or prior author result by construction. The distinction between hypergradient estimation and direct root-finding is presented as a modeling choice rather than a derived equality, and the non-asymptotic guarantees are asserted without visible reduction to fitted quantities or load-bearing self-citations in the given text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International conference on machine learning , pages=
Bilevel programming for hyperparameter optimization and meta-learning , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[2]
Advances in neural information processing systems , volume=
Meta-learning with implicit gradients , author=. Advances in neural information processing systems , volume=
-
[3]
DARTS: Differentiable Architecture Search
Darts: Differentiable architecture search , author=. arXiv preprint arXiv:1806.09055 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
International conference on artificial intelligence and statistics , pages=
Optimizing millions of hyperparameters by implicit differentiation , author=. International conference on artificial intelligence and statistics , pages=. 2020 , organization=
2020
-
[5]
International conference on machine learning , pages=
Bilevel optimization: Convergence analysis and enhanced design , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[6]
Statistica Sinica , volume=
A new principle for tuning-free Huber regression , author=. Statistica Sinica , volume=. 2021 , publisher=
2021
-
[7]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[8]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[9]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[10]
2008 , publisher=
Stochastic approximation: a dynamical systems viewpoint , author=. 2008 , publisher=
2008
-
[11]
Advances in neural information processing systems , volume=
Actor-critic algorithms , author=. Advances in neural information processing systems , volume=
-
[12]
IEEE Transactions on Automatic Control , volume=
Nonlinear two-time-scale stochastic approximation: Convergence and finite-time performance , author=. IEEE Transactions on Automatic Control , volume=. 2022 , publisher=
2022
-
[13]
International Conference on Artificial Intelligence and Statistics , pages=
Central limit theorem for two-timescale stochastic approximation with markovian noise: Theory and applications , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[14]
SIAM journal on control and optimization , volume=
Acceleration of stochastic approximation by averaging , author=. SIAM journal on control and optimization , volume=. 1992 , publisher=
1992
-
[15]
2020 , publisher=
First-order and stochastic optimization methods for machine learning , author=. 2020 , publisher=
2020
-
[16]
International conference on machine learning , pages=
Hyperparameter optimization with approximate gradient , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[17]
International Conference on Machine Learning , pages=
On the iteration complexity of hypergradient computation , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[18]
International conference on machine learning , pages=
Forward and reverse gradient-based hyperparameter optimization , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[19]
Advances in Neural Information Processing Systems , volume=
Provably faster algorithms for bilevel optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
arXiv preprint arXiv:2111.14580 , year=
Amortized implicit differentiation for stochastic bilevel optimization , author=. arXiv preprint arXiv:2111.14580 , year=
-
[21]
International Conference on Machine Learning , pages=
Implicit differentiation of lasso-type models for hyperparameter optimization , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[22]
Advances in Neural Information Processing Systems , volume=
A framework for bilevel optimization that enables stochastic and global variance reduction algorithms , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A fully single loop algorithm for bilevel optimization without hessian inverse , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[24]
Approximation Methods for Bilevel Programming
Approximation methods for bilevel programming , author=. arXiv preprint arXiv:1802.02246 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Mathematical Programming , volume=
Lower bounds for non-convex stochastic optimization , author=. Mathematical Programming , volume=. 2023 , publisher=
2023
-
[26]
International Conference on Learning and Intelligent Optimization , pages=
A stochastic alternating balance k-means algorithm for fair clustering , author=. International Conference on Learning and Intelligent Optimization , pages=. 2022 , organization=
2022
-
[27]
arXiv preprint arXiv:2106.13781 , year=
Tighter analysis of alternating stochastic gradient method for stochastic nested problems , author=. arXiv preprint arXiv:2106.13781 , year=
-
[28]
Advances in Neural Information Processing Systems , volume=
Stochastic optimization with heavy-tailed noise via accelerated gradient clipping , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Optimizing methods in statistics , pages=
A convergence theorem for non negative almost supermartingales and some applications , author=. Optimizing methods in statistics , pages=. 1971 , publisher=
1971
-
[30]
arXiv preprint arXiv:2007.01932 , year=
Meta-sac: Auto-tune the entropy temperature of soft actor-critic via metagradient , author=. arXiv preprint arXiv:2007.01932 , year=
-
[31]
Fine-Tuning Language Models from Human Preferences
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[32]
Journal of the American Statistical Association , volume=
Adaptive huber regression , author=. Journal of the American Statistical Association , volume=. 2020 , publisher=
2020
-
[33]
Reward Constrained Policy Optimization
Reward constrained policy optimization , author=. arXiv preprint arXiv:1805.11074 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Artificial intelligence and statistics , pages=
Fairness constraints: Mechanisms for fair classification , author=. Artificial intelligence and statistics , pages=. 2017 , organization=
2017
-
[35]
International Conference on Machine Learning , pages=
Revisiting and advancing fast adversarial training through the lens of bi-level optimization , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[36]
Conference On Learning Theory , pages=
Finite sample analysis of two-timescale stochastic approximation with applications to reinforcement learning , author=. Conference On Learning Theory , pages=. 2018 , organization=
2018
-
[37]
SIAM Journal on Optimization , volume=
A two-timescale stochastic algorithm framework for bilevel optimization: Complexity analysis and application to actor-critic , author=. SIAM Journal on Optimization , volume=. 2023 , publisher=
2023
-
[38]
International conference on machine learning , pages=
Understanding contrastive representation learning through alignment and uniformity on the hypersphere , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[39]
Advances in neural information processing systems , volume=
Improved training of wasserstein gans , author=. Advances in neural information processing systems , volume=
-
[40]
The Thirty Seventh Annual Conference on Learning Theory , pages=
On finding small hyper-gradients in bilevel optimization: Hardness results and improved analysis , author=. The Thirty Seventh Annual Conference on Learning Theory , pages=. 2024 , organization=
2024
-
[41]
Journal of Global Optimization , pages=
Inexact bilevel stochastic gradient methods for constrained and unconstrained lower-level problems , author=. Journal of Global Optimization , pages=. 2025 , publisher=
2025
-
[42]
Linear convergence of gradient and proximal-gradient methods under the polyak-
Karimi, Hamed and Nutini, Julie and Schmidt, Mark , booktitle=. Linear convergence of gradient and proximal-gradient methods under the polyak-. 2016 , organization=
2016
-
[43]
arXiv preprint arXiv:2309.01753 , year=
On penalty methods for nonconvex bilevel optimization and first-order stochastic approximation , author=. arXiv preprint arXiv:2309.01753 , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
Contextual stochastic bilevel optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Conference on Learning Theory , pages=
Finite time analysis of linear two-timescale stochastic approximation with Markovian noise , author=. Conference on Learning Theory , pages=. 2020 , organization=
2020
-
[46]
2025 , eprint=
Multi Timescale Stochastic Approximation: Stability and Convergence , author=. 2025 , eprint=
2025
-
[47]
Distribution-Aware Robust Bilevel Optimization: Quantile-Guided Huber Updates in Two-Timescale Stochastic Approximation
Anonymous Authors. Distribution-Aware Robust Bilevel Optimization: Quantile-Guided Huber Updates in Two-Timescale Stochastic Approximation
-
[48]
International Conference on Machine Learning , pages=
Optimal stochastic non-smooth non-convex optimization through online-to-non-convex conversion , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[49]
Advances in Neural Information Processing Systems , volume=
Improved convergence in high probability of clipped gradient methods with heavy tailed noise , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
physica , volume=
Brownian motion in a field of force and the diffusion model of chemical reactions , author=. physica , volume=. 1940 , publisher=
1940
-
[51]
Reviews of modern physics , volume=
Reaction-rate theory: fifty years after Kramers , author=. Reviews of modern physics , volume=. 1990 , publisher=
1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.