Citation-Closure Retrieval and Per-Rule Attribution for Real-World Regulatory Compliance Question Answering
Pith reviewed 2026-06-29 07:44 UTC · model grok-4.3
The pith
RefWalk traverses citations and attributes claims to rules to improve retrieval in regulatory compliance QA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RefWalk traverses cross-document citations, fuses multi-view candidates via max-based aggregation, and enforces per-rule attribution to explicitly map claims to sources. On RegOps-Bench derived from complex national R&D regulations, this establishes a strong baseline with substantial improvements in retrieval recall and citation accuracy. Contrastive evaluation on a U.S. health compliance dataset (HIPAA) reveals that existing systems exhibit saturation on flat-structure rules.
What carries the argument
RefWalk, a unified framework driven by a shared topic anchor that traverses cross-document citations, fuses multi-view candidates via max-based aggregation, and enforces per-rule attribution.
If this is right
- RefWalk provides explicit per-rule attribution that maps claims directly to source rules in multi-tiered structures.
- Retrieval recall improves substantially on the RegOps-Bench compared to prior RAG systems.
- Citation accuracy increases due to the citation-closure and attribution mechanisms.
- Existing RAG systems saturate on flat-structure rules as shown in the HIPAA contrast.
- The need for benchmarks like RegOps-Bench is underscored for complex regulatory domains.
Where Pith is reading between the lines
- Similar citation traversal methods could apply to other domains with hierarchical document structures, such as legal case law or technical standards.
- Per-rule attribution may help reduce the risk of incorrect compliance advice from LLMs by grounding outputs in specific sources.
- Testing RefWalk on additional regulatory datasets could confirm if the gains generalize beyond R&D regulations.
- The Operational Knowledge Graph approach might inspire similar graphs for other compliance areas.
Load-bearing premise
The Operational Knowledge Graph and RegOps-Bench from national R&D regulations represent real-world multi-tiered regulatory compliance tasks so that the observed improvements generalize.
What would settle it
Applying RefWalk to another multi-tiered regulatory domain and finding no gains in retrieval recall or citation accuracy compared to standard RAG methods.
Figures









read the original abstract
Deploying Large Language Models (LLMs) for regulatory compliance demands rigorous traceability via comprehensive citations across multi-tiered authority structures. Unlike traditional multi-hop or legal QA, this task requires structured procedural lookups and evidence-set closure rather than entity resolution or case-law reasoning. Existing RAG systems struggle here due to flattened citation edges, fragmented retrieval expansions, and fragile post-hoc attribution. We formalize Regulatory Compliance QA with RegOps-Bench, a novel benchmark featuring an Operational Knowledge Graph derived from complex national R\&D regulations. To address these bottlenecks, we propose RefWalk, a unified framework driven by a shared topic anchor. RefWalk traverses cross-document citations, fuses multi-view candidates via max-based aggregation, and enforces per-rule attribution to explicitly map claims to sources. We establish a strong baseline with substantial improvements in retrieval recall and citation accuracy. Finally, a contrastive evaluation on a U.S. health compliance dataset (HIPAA) reveals that existing systems exhibit saturation on flat-structure rules, underscoring the need for RegOps-Bench. Our code is available at https://github.com/yeongjoonJu/RefWalk.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RegOps-Bench, a new benchmark for regulatory compliance QA built on an Operational Knowledge Graph extracted from complex national R&D regulations. It proposes RefWalk, a citation-closure retrieval framework that traverses cross-document citations from a shared topic anchor, fuses multi-view candidates via max-based aggregation, and enforces per-rule attribution to map claims to sources. The central claim is that RefWalk delivers substantial gains in retrieval recall and citation accuracy over existing RAG systems on RegOps-Bench while highlighting saturation of prior methods on the flat-structure HIPAA dataset.
Significance. If the quantitative gains and attribution properties hold under full evaluation, the work would supply a useful benchmark and baseline for citation-aware retrieval in multi-tiered regulatory domains where standard RAG pipelines lose traceability. The public release of code at the cited GitHub repository is a clear strength that supports reproducibility and future comparisons.
major comments (3)
- [Abstract] Abstract: the claim of 'substantial improvements in retrieval recall and citation accuracy' is presented without any numerical results, ablation tables, error bars, or dataset statistics, rendering the central empirical claim unverifiable from the manuscript text.
- [Abstract] Abstract (final sentence): the contrastive HIPAA evaluation reports only that existing systems saturate on flat-structure rules but supplies no RefWalk numbers on the same dataset, leaving open whether the citation-traversal and max-aggregation advantages are tied to the dense hierarchy of RegOps-Bench rather than constituting a general solution.
- [Method description (inferred from abstract)] No section or equation is supplied that defines the 'shared topic anchor' selection procedure or the precise max-based aggregation formula; without these, it is impossible to assess whether the method is parameter-free or how it differs from standard multi-hop retrieval.
minor comments (2)
- The GitHub link is provided, which aids reproducibility; consider adding a brief reproducibility statement with commit hash or environment details.
- Dataset statistics (number of rules, citation edges, query count) and example queries from RegOps-Bench would improve clarity of the benchmark contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and method presentation. We agree that the abstract requires strengthening for verifiability and will revise it to include key results and clarifications. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'substantial improvements in retrieval recall and citation accuracy' is presented without any numerical results, ablation tables, error bars, or dataset statistics, rendering the central empirical claim unverifiable from the manuscript text.
Authors: We agree that the abstract should make the central claims verifiable. In the revision we will insert the primary quantitative results (e.g., recall@10 and citation accuracy deltas on RegOps-Bench) and basic dataset statistics directly into the abstract while preserving length constraints. revision: yes
-
Referee: [Abstract] Abstract (final sentence): the contrastive HIPAA evaluation reports only that existing systems saturate on flat-structure rules but supplies no RefWalk numbers on the same dataset, leaving open whether the citation-traversal and max-aggregation advantages are tied to the dense hierarchy of RegOps-Bench rather than constituting a general solution.
Authors: The HIPAA contrast was intended only to illustrate saturation of prior methods on flat rules. To address the open question we will either add RefWalk numbers on HIPAA (if space and compute allow) or revise the sentence to explicitly state the scope limitation of the contrastive experiment. revision: partial
-
Referee: [Method description (inferred from abstract)] No section or equation is supplied that defines the 'shared topic anchor' selection procedure or the precise max-based aggregation formula; without these, it is impossible to assess whether the method is parameter-free or how it differs from standard multi-hop retrieval.
Authors: The full manuscript contains the formal definitions and the max-aggregation formula in Section 3. The abstract is intentionally high-level. We will add a one-sentence pointer to the relevant equation and selection procedure within the abstract to improve traceability. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces RefWalk as a new framework using citation traversal, max aggregation, and per-rule attribution on a novel Operational Knowledge Graph and RegOps-Bench benchmark. No equations, fitted parameters, or predictions are described that reduce to inputs by construction. No self-citations appear as load-bearing premises, and the method is presented as independent of prior author work. The central claims rest on empirical improvements on the introduced benchmark without self-referential reductions or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Douglas W Arner, Jànos Barberis, and Ross P Buckley
Natural language processing for the legal do- main: A survey of tasks, datasets, models, and chal- lenges.ACM Computing Surveys, 58:1–37. Douglas W Arner, Jànos Barberis, and Ross P Buckley
-
[2]
arXiv preprint arXiv:2212.08037 , year=
Regtech: Building a better financial system. In Handbook of blockchain, digital finance, and inclu- sion, volume 1, pages 359–373. Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to retrieve, generate, and critique through self-reflection. InThe International Conference on Learning Repre- sentations (ICLR)...
-
[3]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
LEGAL-BERT: The muppets straight out of law school. InFindings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2898–2904. Gordon V Cormack, Charles LA Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the International ACM SIGIR Conf...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[4]
arXiv preprint arXiv:2402.03367 , year=
Think-on-graph 2.0: Deep and faithful large language model reasoning with knowledge-guided retrieval augmented generation. InThe International Conference on Learning Representations (ICLR). Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettle- moyer, and Hannaneh Hajishirzi. 2023. FActScore: Fine-grained atomi...
-
[5]
John B Ruhl and Daniel Martin Katz
Measuring attribution in natural language gen- eration models.Computational Linguistics, 49:777– 840. John B Ruhl and Daniel Martin Katz. 2015. Measuring, monitoring, and managing legal complexity.Iowa L. Rev., 101:191. Yash Saxena, Raviteja Bommireddy, Ankur Padia, and Manas Gaur. 2025. Generation-time vs. post-hoc citation: A holistic evaluation of LLM ...
-
[6]
Do- main anchor
Judging LLM-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems (NeurIPS), 36:46595–46623. A Appendix A.1 Implementation Details All open-source models were served using vLLM (Kwon et al., 2023) on RTX A6000 (48 GB) GPUs in bfloat16 precision with a maxi- mum sequence length of 32,768 tokens. We em- ployed Qwen3....
2023
-
[7]
Do not fabricate any content not present in the provided document or introduce external knowledge
Context Dependency: All answers and grounds must be extracted strictly from within the provided ’Context’. Do not fabricate any content not present in the provided document or introduce external knowledge
-
[8]
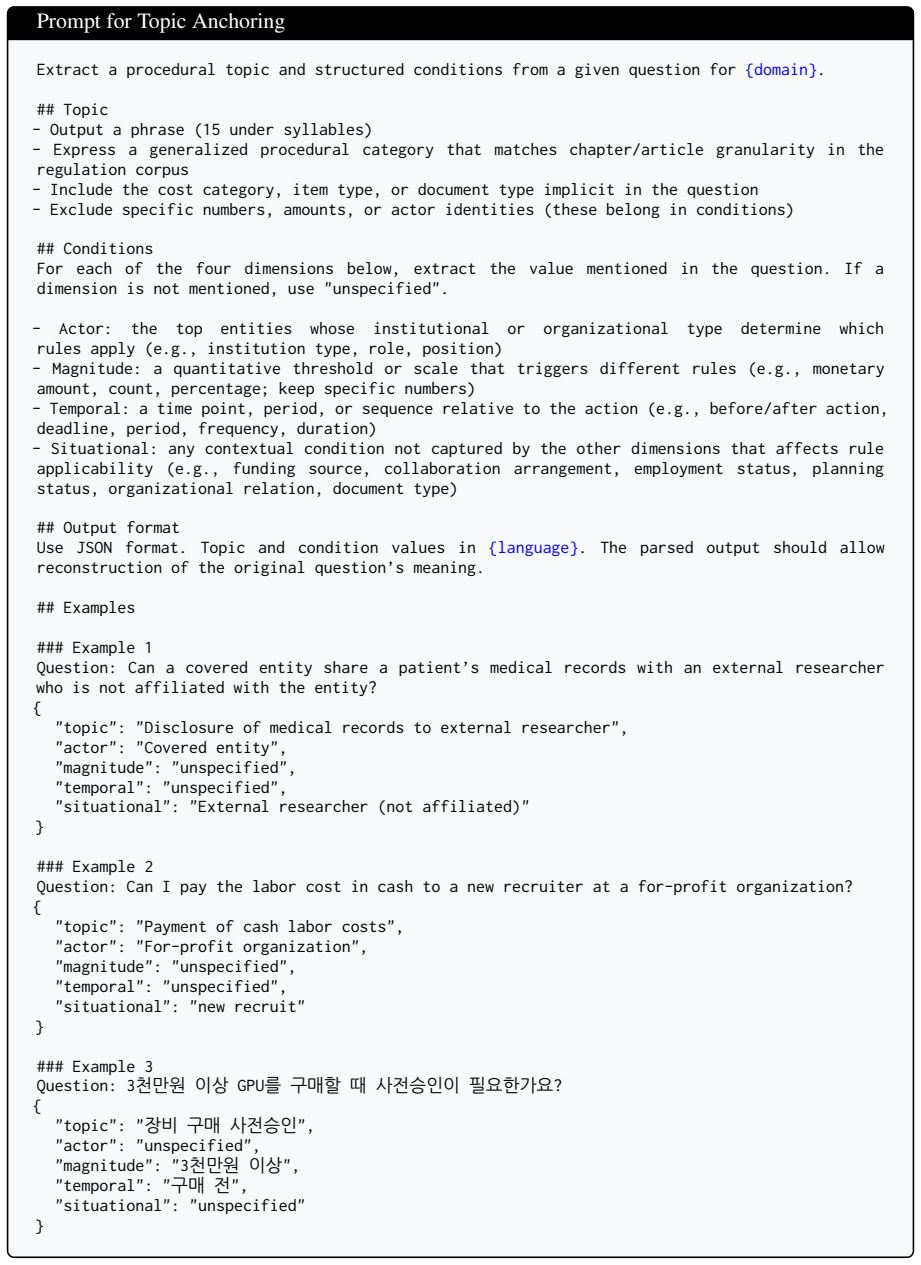
국가연구개발사업_연구개발비_ 사용기준_제22조
Uniformity of Reference Unit (Article level): The key values of the JSON must be written in the exact same format as the node_id specified in the Context (e.g., “국가연구개발사업_연구개발비_ 사용기준_제22조”). Never arbitrarily invent or modify the names of the keys
-
[9]
If a detailed unit (Paragraph, Subparagraph) that serves as the actual ground exists, indicate it with square brackets (e.g., [제O항]) before the content
Ground (Claim) Extraction and Detailed Unit Notation: Extract the specific facts or regulatory content required to answer the question from each referenced clause, and list them in an array format. If a detailed unit (Paragraph, Subparagraph) that serves as the actual ground exists, indicate it with square brackets (e.g., [제O항]) before the content
-
[10]
다만,∼” [provided that,∼], “∼의경우 예외로한다
Mandatory Reflection of Exceptions and Provisos: If the value of the provided conditions (subject, timing, scale, situation) is ’all’ (unspecified) or comprehensive, you must search for existing exceptional conditions or provisos (e.g., “다만,∼” [provided that,∼], “∼의경우 예외로한다” [except in the case of∼], “중앙행정기관의 장이 인정하는경우” [cases recognized by the head of th...
-
[11]
다만, [예외조건]의경우[예외결과]가 가능합니다/제한됩니다
Drafting the Final Answer (Answer): - Synthesize the extracted grounds (Claim) and exceptions to write a clear answer that aligns with the question. - If there is an exceptional condition, explicitly notify it in the answer in the form of “다만, [예외조건]의경우[예외결과]가 가능합니다/제한됩니다.” [Provided that, in the case of [Exceptional Condition], [Exceptional Outcome] is p...
-
[12]
OOO_Article O
Output Format: You must respond strictly in the JSON format below, and never include any other greetings or additional explanations outside of the JSON. # Output format (JSON) { “OOO_Article O”: [ “[Paragraph 1] Original text and details of the principle-based ground derived from the relevant clause”, “[Paragraph 2] Another original text content in cases ...
-
[13]
Do not invoke outside knowledge or fabricate content
Context dependency: Every claim and the final answer MUST be drawn from the provided ’Context’ only. Do not invoke outside knowledge or fabricate content
-
[14]
spans-passthrough-candidates/sent_0012-0ec05553
Reference-key format: Each JSON key MUST be the ‘node_id‘ exactly as it appears between the [ and ] of a Context passage header — without the surrounding brackets. Do not invent, modify, or concatenate identifiers. (Example: header [spans-passthrough-candidates/sent_0012-0ec05553]→ key “spans-passthrough-candidates/sent_0012-0ec05553”.)
-
[15]
The default is one rule per question; cite a second only when the answer genuinely depends on a distinct second rule
Cite minimally: include only the rule(s) that materially support the answer. The default is one rule per question; cite a second only when the answer genuinely depends on a distinct second rule. Do not echo every passage in the Context
-
[16]
except”, “provided that
Claim extraction: Under each cited node_id, list the specific facts the rule contributes toward the answer (JSON array of one-sentence English strings). Surface an exception or proviso (“except”, “provided that”, “unless”) only when the cited rule itself explicitly contains one — do NOT search for exceptions when none are present in the cited text
-
[17]
§164.502(a)(1)
Final ’answer’ field: - Concise English synthesis grounded in the cited claims. - Reference the regulation in-line by its CFR section (e.g., "§164.502(a)(1)") so the reasoning is traceable. - State any explicit exception when it applies
-
[18]
<node_id>
Output format: Respond with ONLY the JSON object below. No greetings, no preface, no trailing prose. # Output format (JSON) { “<node_id>”: [ “Primary normative content derived from this rule”, “Exception or proviso, only when the cited rule explicitly contains one”, ], “answer”: “Final answer text. Reference the regulation in-line (e.g., §164.502(a)) and ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.