Characterizing Optimizer-Dependent Training Dynamics Through Hessian Eigenvector Displacement and Localization
Pith reviewed 2026-06-30 07:51 UTC · model grok-4.3
The pith
SGD stabilizes leading Hessian eigenvectors over training while Adam drives ongoing reorganization and localization to a small parameter subset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
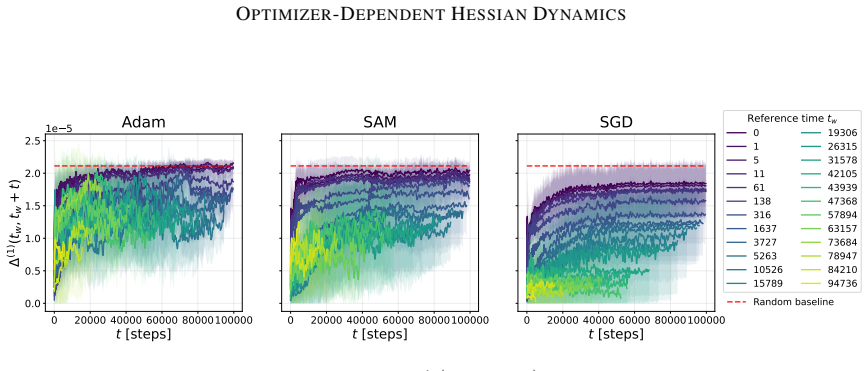
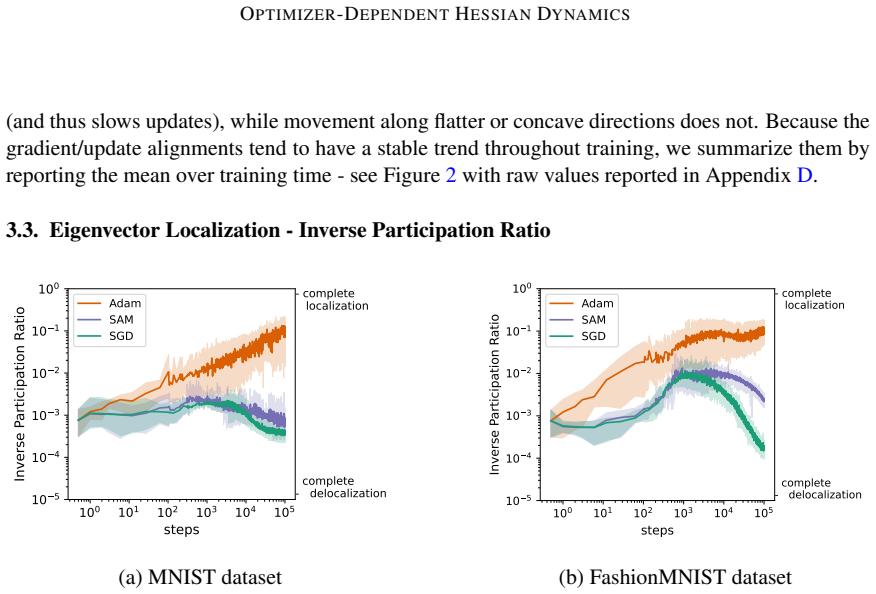
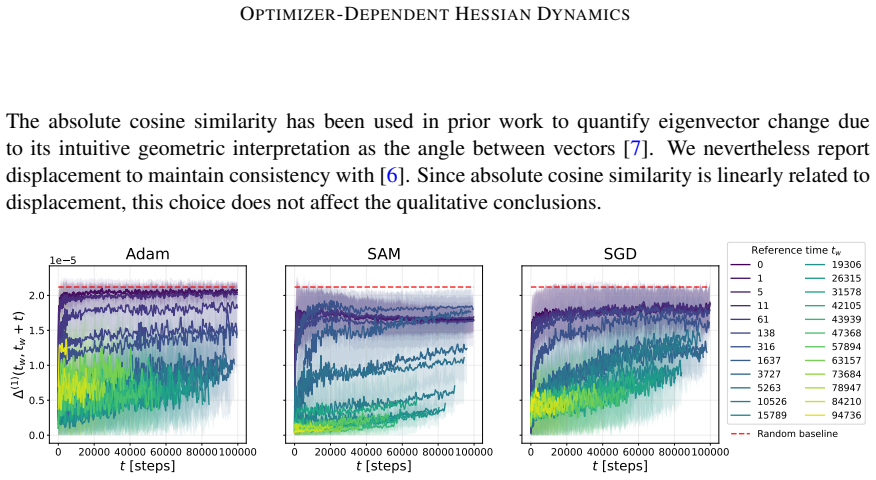
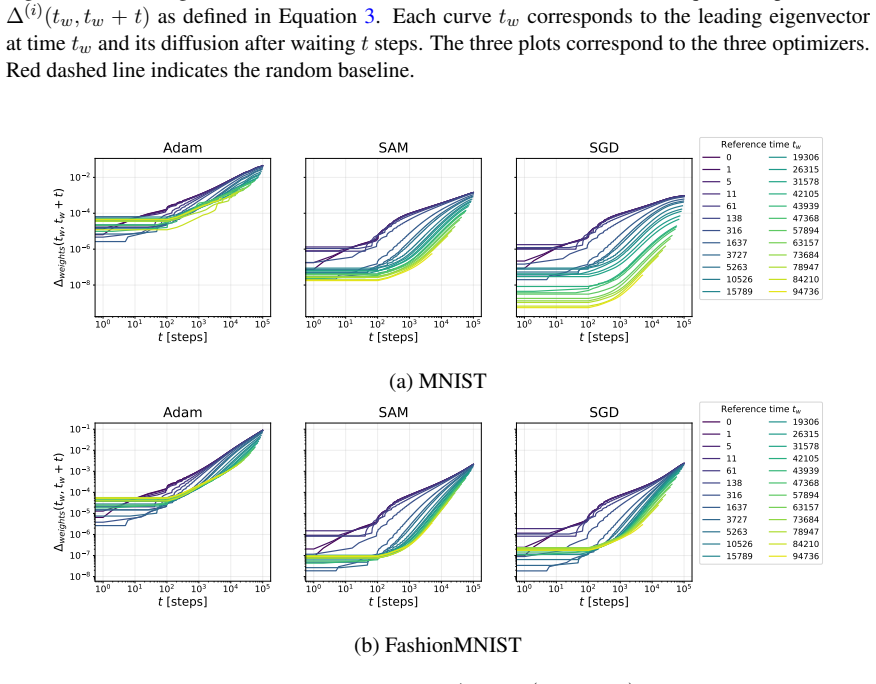
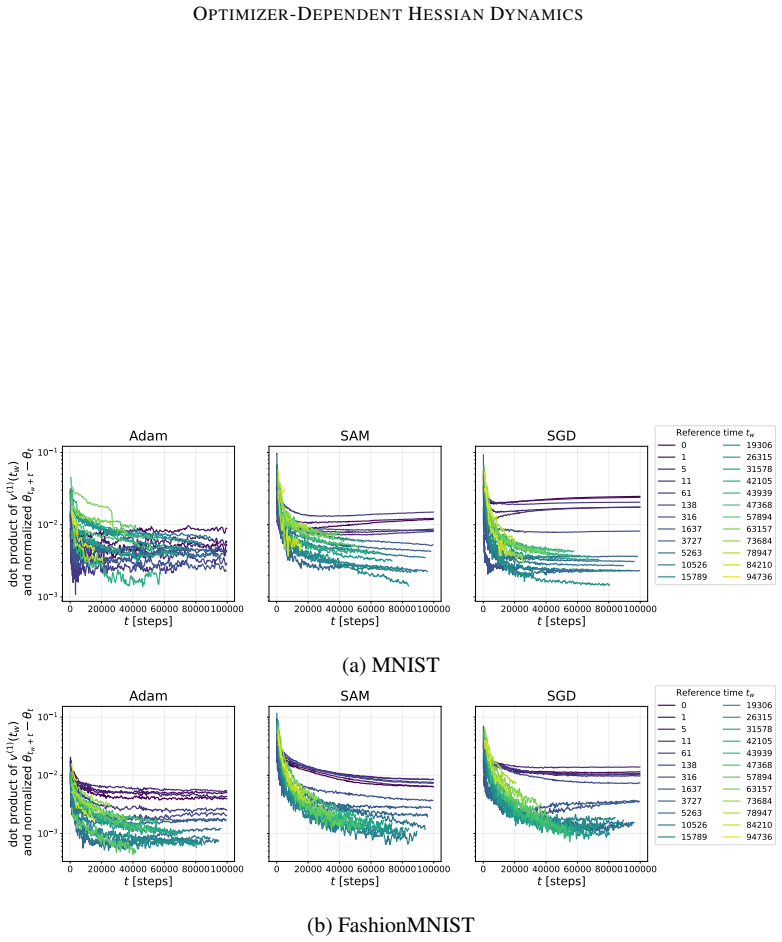
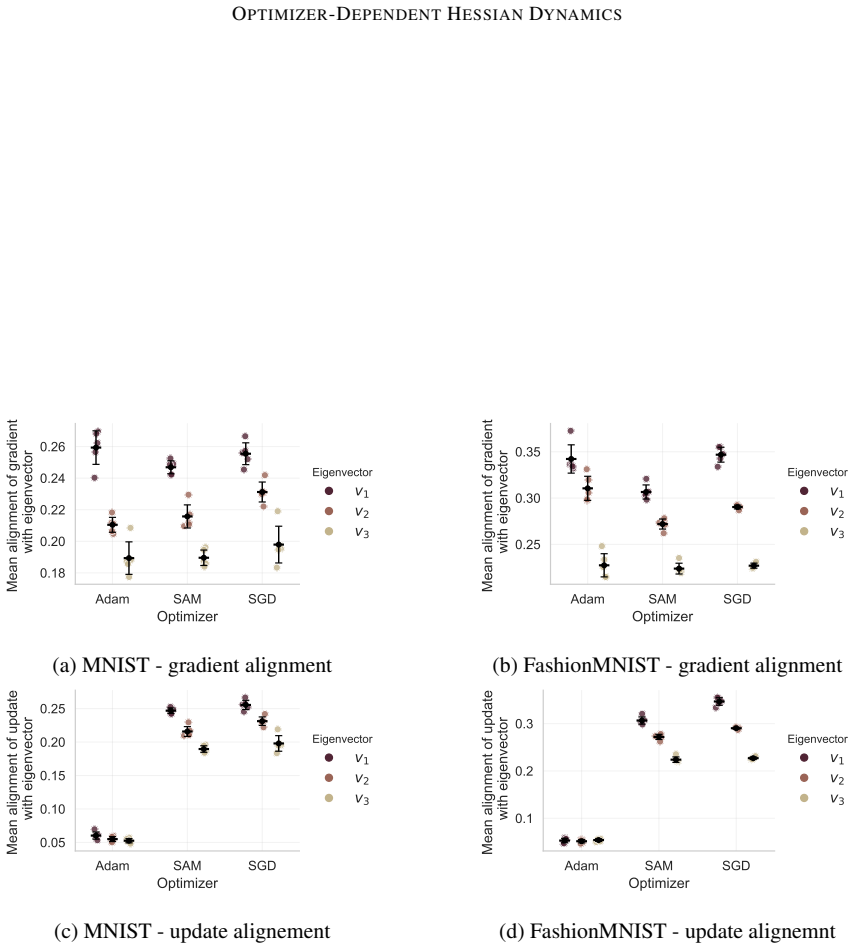
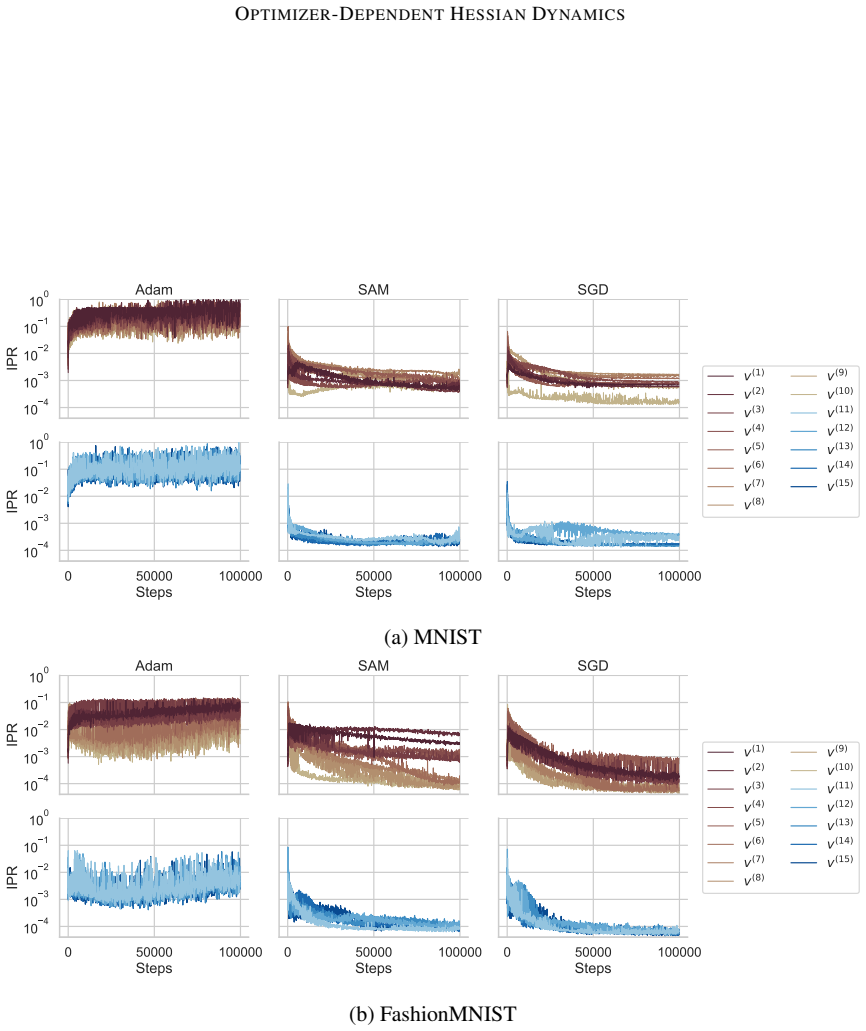
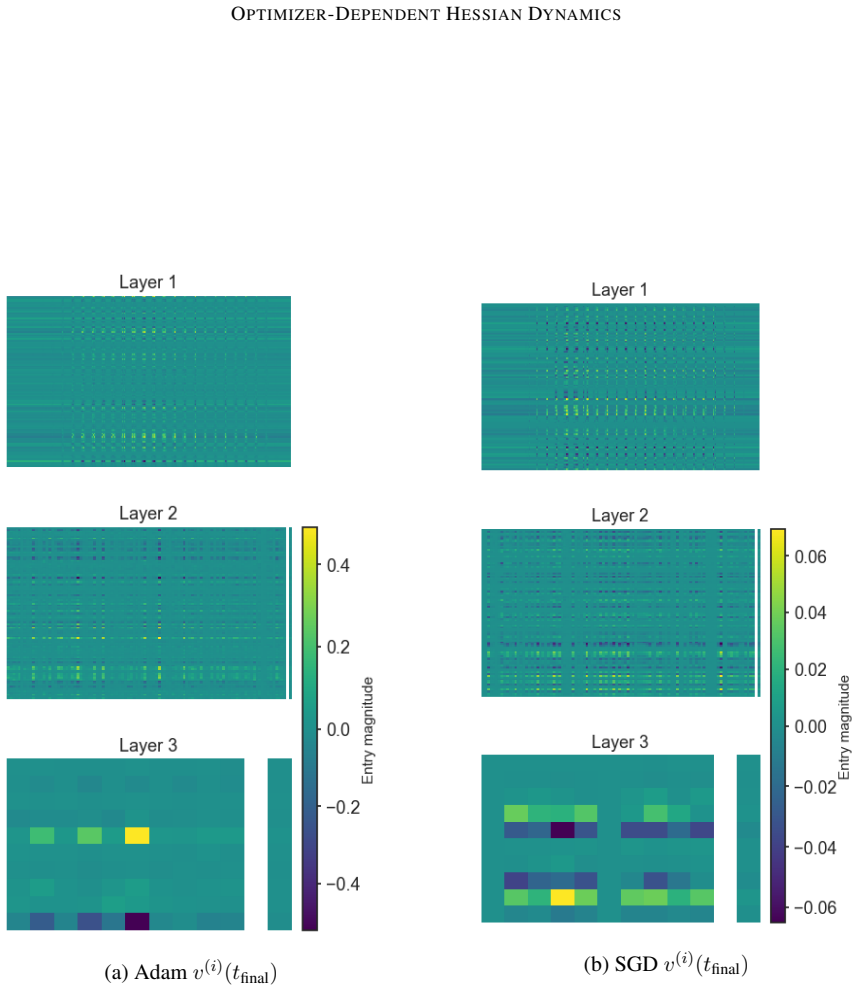
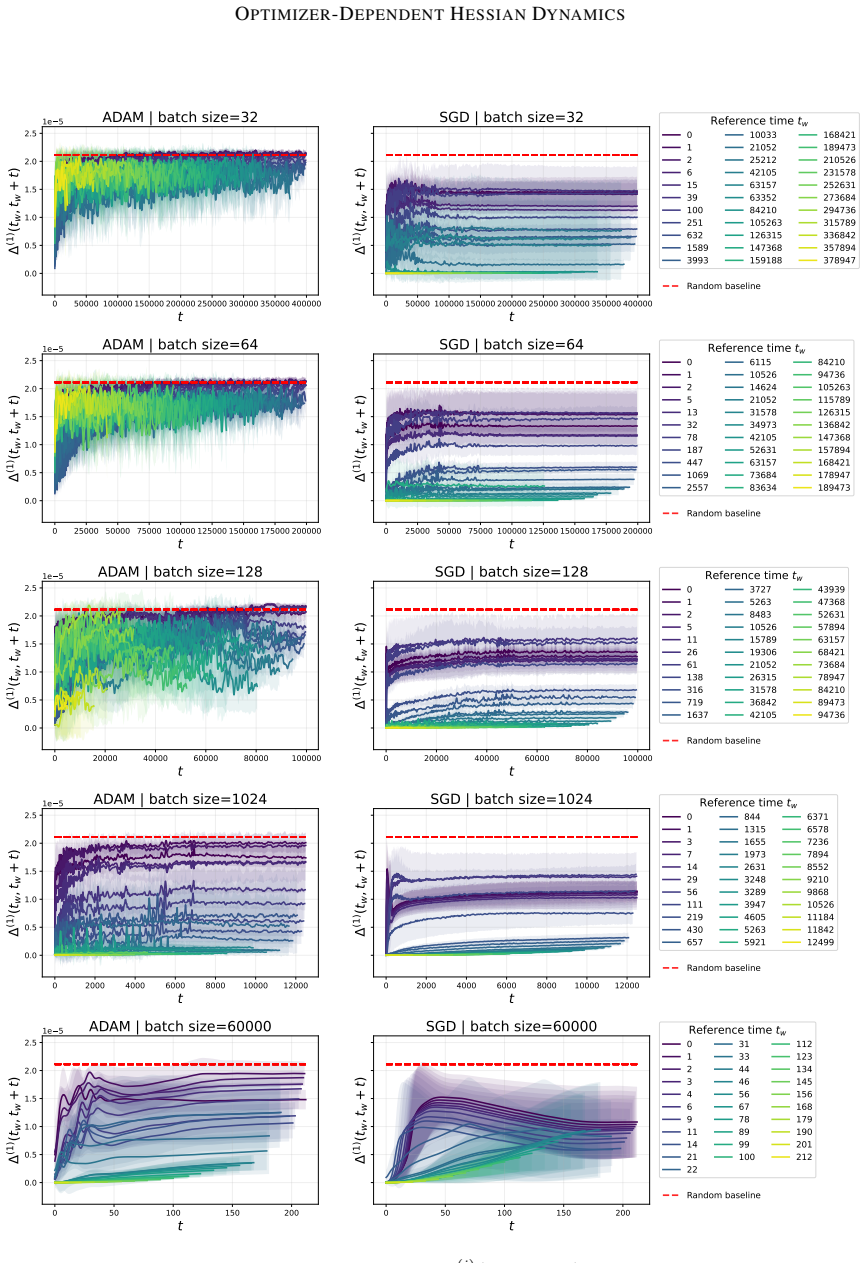
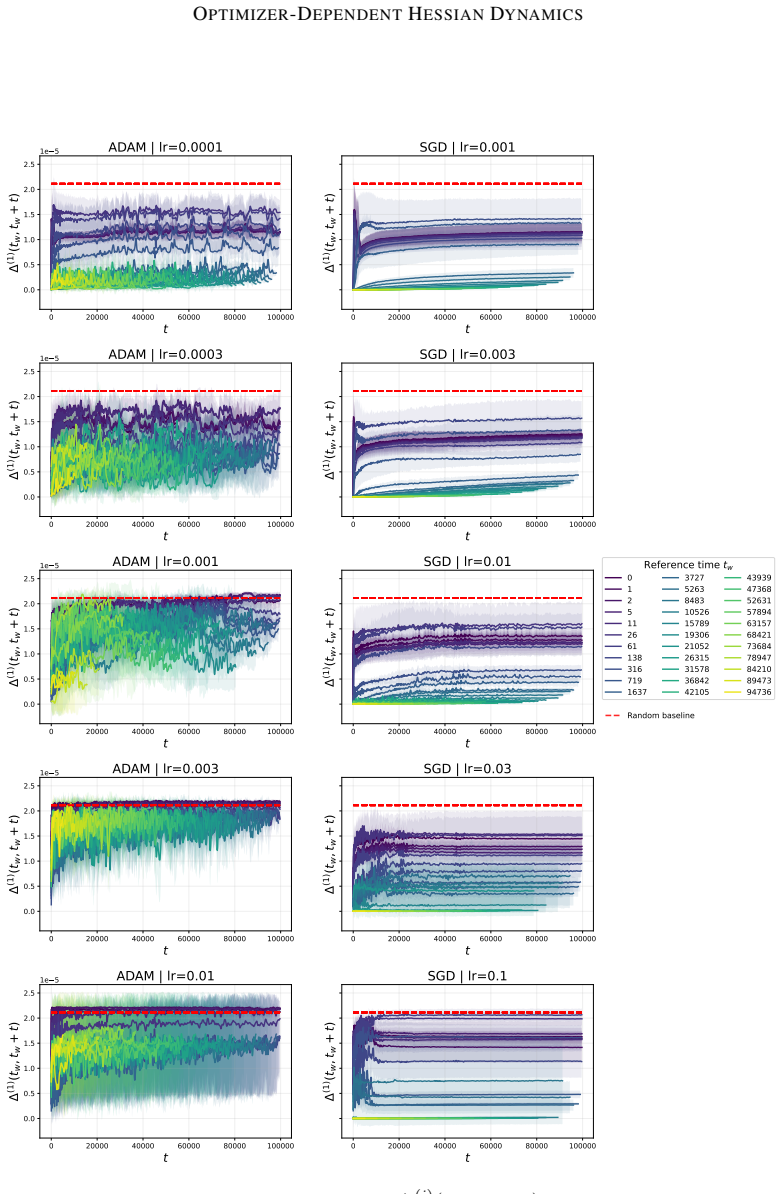
By tracking the displacement of leading Hessian eigenvectors and their localization via the inverse participation ratio against an architecture-induced random null model, the work establishes that SGD leads to progressively more stable leading curvature directions during training of multilayer perceptrons on classification, while Adam exhibits substantially stronger reorganization of eigenvectors throughout training together with a localization phenomenon in which a small subset of parameters contributes disproportionately to the leading curvature directions.
What carries the argument
Displacement of leading Hessian eigenvectors over training steps and their localization measured by the inverse participation ratio, benchmarked against a random null model of the Hessian induced by the architecture.
If this is right
- Optimizer selection affects not only loss decrease rate but also the temporal stability and spatial concentration of the dominant curvature directions.
- Adam's continued eigenvector reorganization implies that its adaptive per-parameter steps keep altering which directions dominate curvature even late in training.
- Localization under Adam indicates that curvature becomes concentrated on fewer effective parameters, potentially changing the effective dimensionality of the optimization problem.
- Eigenvector dynamics supply a diagnostic that distinguishes training trajectories beyond what loss curves or eigenvalue spectra alone reveal.
Where Pith is reading between the lines
- If stable eigenvectors correlate with flatter regions, the SGD pattern could help explain its often-reported generalization advantage over Adam.
- The same displacement and localization statistics could be applied to other architectures to test whether the optimizer contrast persists beyond MLPs.
- If the null model under-corrects for architecture effects, the reported optimizer-specific signals would shrink and the localization claim would need re-examination on matched architectures.
Load-bearing premise
The random null model of the Hessian induced by the architecture supplies a baseline that lets observed displacement and localization be attributed to the optimizer rather than to the network architecture itself.
What would settle it
Re-running the same MLP training experiments and finding that the time series of eigenvector displacement and inverse-participation-ratio values under SGD and Adam are statistically indistinguishable from each other and from the architecture null model.
Figures
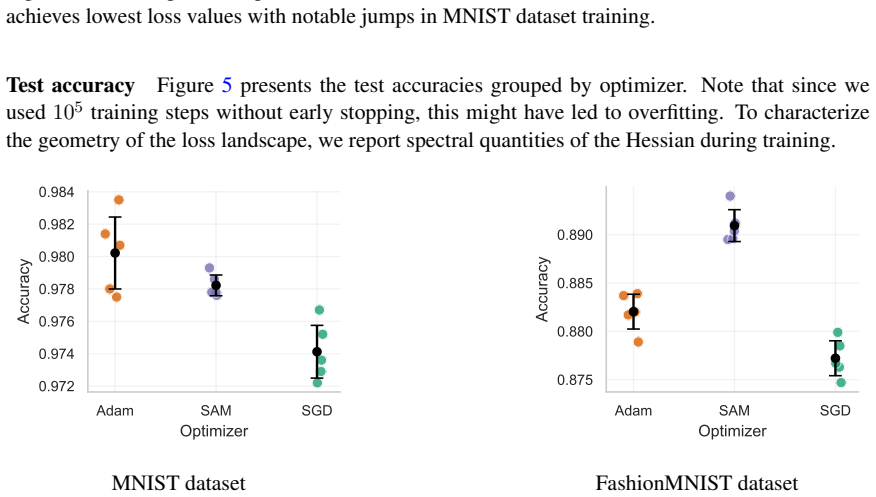
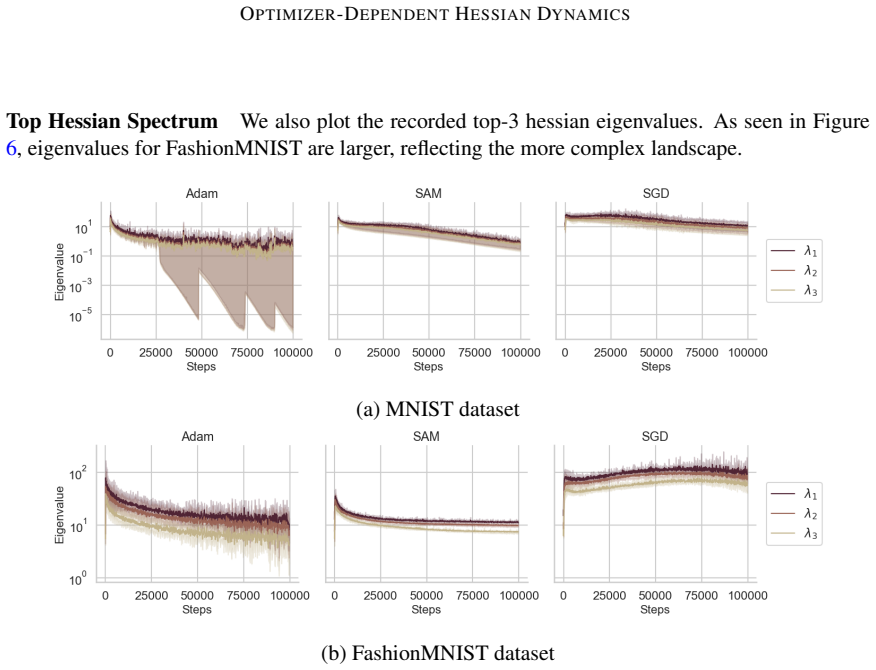
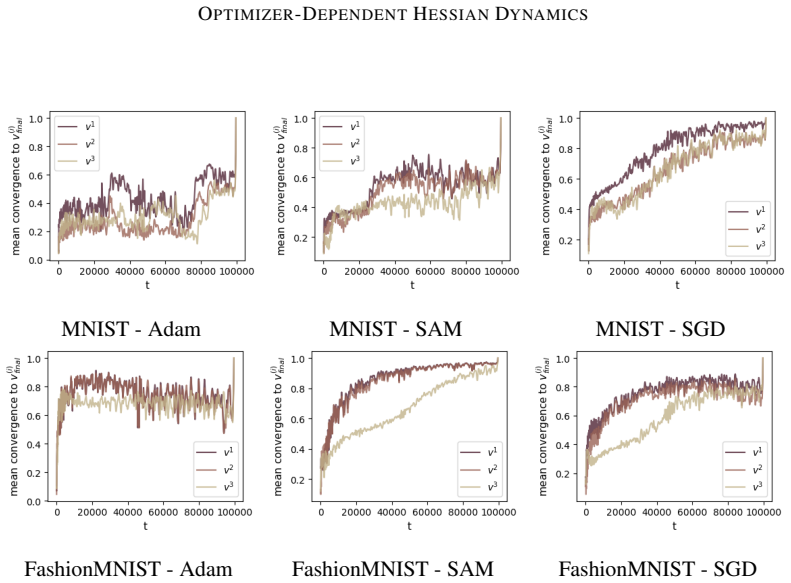
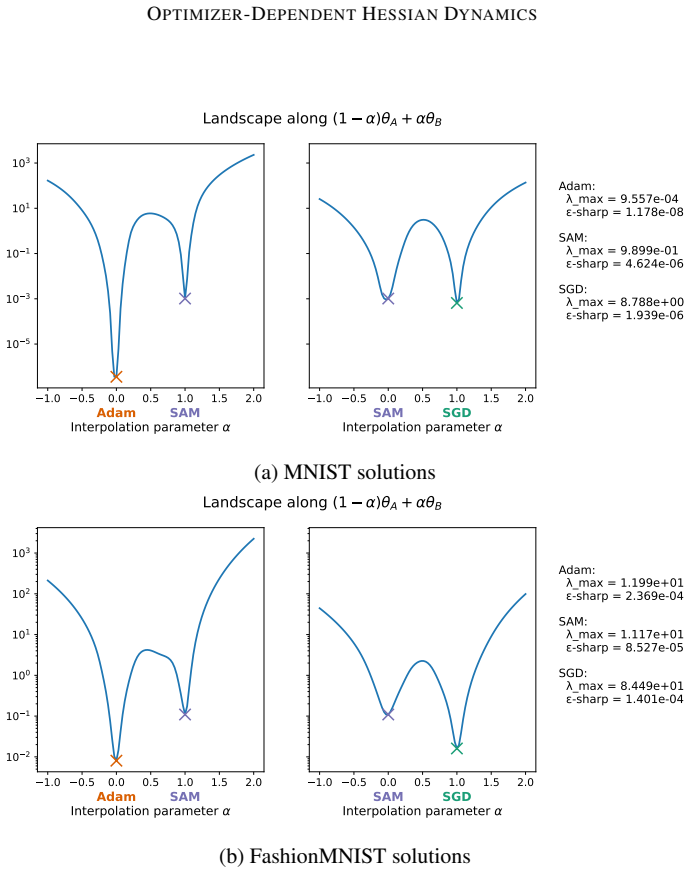



read the original abstract
Hessian spectral properties are a standard tool in analysing neural-network training, with eigenvalues linked to sharpness, generalization, and optimization dynamics. Eigenvalues quantify curvature magnitude, while eigenvectors identify which parameters generate that curvature. In this work, we study how the leading Hessian eigenvectors evolve during training and how they affect the learning trajectories. We track the training dynamics of multilayer perceptrons on a classification problem and measure eigenvector dynamics through two complementary statistics: (i) displacement over time, inspired by analyses of glassy systems, and (ii) localization via the inverse participation ratio. The metrics are compared against a random null model of the Hessian induced by the architecture. Our results reveal clear optimizer-dependent behaviour. SGD leads to progressively more stable leading curvature directions, while Adam exhibits substantially stronger reorganization of eigenvectors throughout training. We also observe a localization phenomenon under Adam, where a small subset of parameters contributes disproportionately to the leading curvature directions. These results suggest that Hessian eigenvector dynamics capture key differences in optimizer behaviour and the resulting training trajectories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes the evolution of leading Hessian eigenvectors during training of multilayer perceptrons on classification tasks, using displacement (inspired by glassy systems) and inverse participation ratio to quantify dynamics. It reports optimizer-dependent patterns when compared to a random null model of the Hessian induced by the architecture: SGD produces progressively more stable leading curvature directions, while Adam exhibits stronger eigenvector reorganization throughout training and a localization effect in which a small subset of parameters dominates the leading curvature directions.
Significance. If the central attribution to optimizers holds after proper validation of the baseline, the work would provide a useful spectral characterization of how SGD versus Adam shape loss-landscape geometry, extending beyond eigenvalue magnitudes to eigenvector stability and localization. The complementary metrics and explicit null-model comparison constitute a concrete, falsifiable approach that could inform optimizer analysis and training-trajectory studies.
major comments (1)
- [Null model (abstract and results)] Null-model construction and validation (abstract and results sections describing the random null model): The claim that observed displacement and localization differences are optimizer-specific rather than architecture- or initialization-driven rests on comparison to the random null model. No explicit description is given of how the null model is generated (e.g., weight randomization procedure, preservation or destruction of layer-wise correlations and activation-induced structure), nor is any validation reported (moment matching, tests on untrained or frozen networks). This is load-bearing for the central claim; without it the optimizer attribution cannot be isolated.
minor comments (2)
- [Abstract] Abstract and results: quantitative details such as number of independent runs, error bars on displacement and IPR statistics, dataset sizes, and architecture controls are not reported, making it difficult to assess the robustness of the qualitative differences described.
- [Methods] The manuscript would benefit from an explicit statement of how many leading eigenvectors are tracked and whether results are sensitive to this choice.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of the null-model details. We agree this is essential for isolating optimizer effects and will revise the manuscript accordingly.
read point-by-point responses
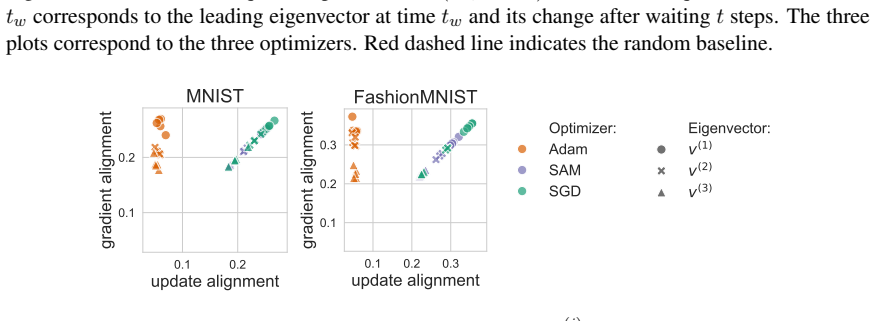
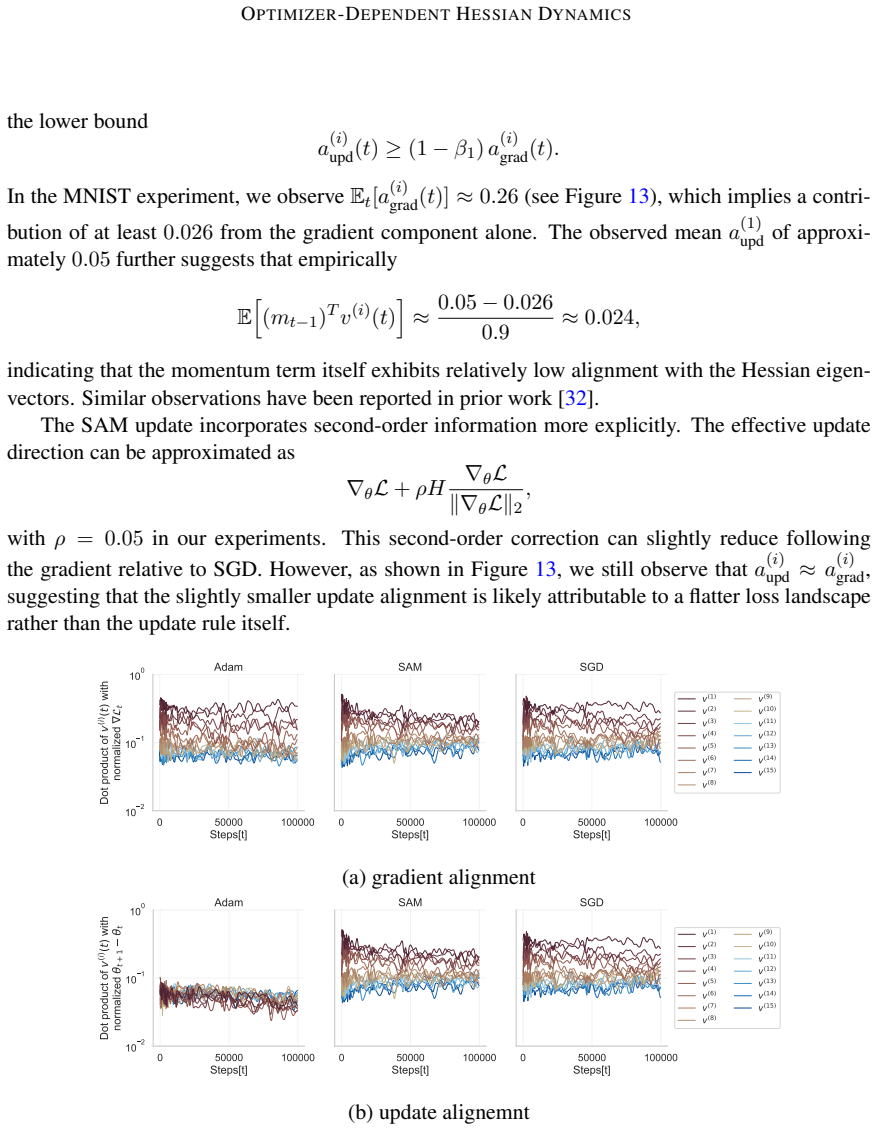
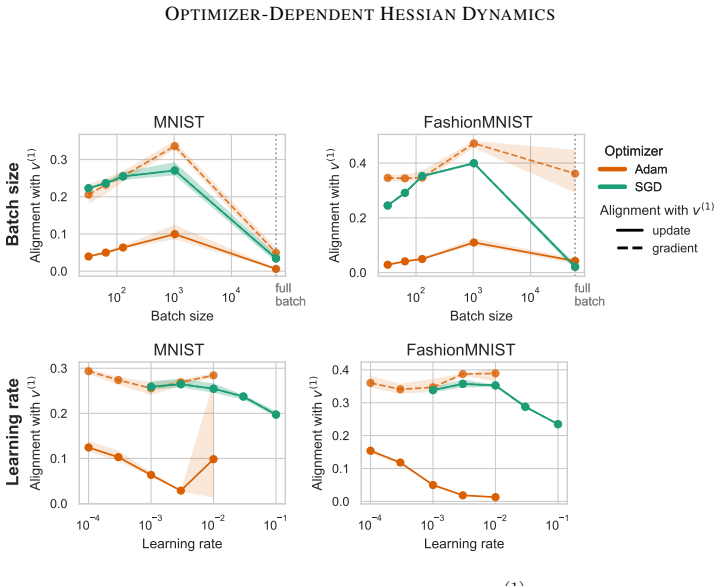
-
Referee: Null-model construction and validation (abstract and results sections describing the random null model): The claim that observed displacement and localization differences are optimizer-specific rather than architecture- or initialization-driven rests on comparison to the random null model. No explicit description is given of how the null model is generated (e.g., weight randomization procedure, preservation or destruction of layer-wise correlations and activation-induced structure), nor is any validation reported (moment matching, tests on untrained or frozen networks). This is load-bearing for the central claim; without it the optimizer attribution cannot be isolated.
Authors: We agree the current manuscript provides insufficient detail on the null model. In the revised version we will add a dedicated Methods subsection specifying that the null model is generated by independently randomly permuting weights within each layer (preserving per-layer marginal distributions and architecture but destroying learned correlations and activation-induced structure). We will also report validation: (i) moment matching of the leading eigenvalues between the empirical Hessian and null model on untrained networks, and (ii) explicit checks that displacement and IPR statistics coincide between real and null Hessians before training begins. These additions will make the optimizer attribution explicit and falsifiable. revision: yes
Circularity Check
No circularity: empirical measurements of Hessian eigenvector statistics against architecture null model
full rationale
The paper reports direct empirical measurements of eigenvector displacement (inspired by glassy systems) and inverse participation ratio on MLPs trained with SGD vs Adam, compared against a random null model induced by the architecture. No equations, fitted parameters, or self-citations are shown to reduce the reported statistics to inputs by construction; the central claims rest on observed differences in these quantities rather than any self-referential derivation or renamed known result. The analysis is self-contained as observational data against an external baseline.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Hessian matrix of the loss captures the local curvature relevant to optimization dynamics.
- standard math The inverse participation ratio is a valid scalar measure of eigenvector localization.
Reference graph
Works this paper leans on
-
[1]
SAM operates far from home: eigenvalue regularization as a dynamical phenomenon
Atish Agarwala and Yann Dauphin. SAM operates far from home: eigenvalue regularization as a dynamical phenomenon. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023. URLhttps://dl.acm.org/doi/10.5555/ 3618408.3618416
-
[2]
Negative eigenvalues of the Hessian in deep neural networks
Guillaume Alain, Nicolas Le Roux, and Pierre-Antoine Manzagol. Negative eigenvalues of the Hessian in deep neural networks, February 2019. URLhttp://arxiv.org/abs/ 1902.02366
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
Romain Allez and Jean-Philippe Bouchaud. Eigenvector dynamics: General theory and some applications.Physical Review E, 86(4):046202, October 2012. ISSN 1539-3755, 1550-2376. URLhttps://link.aps.org/doi/10.1103/PhysRevE.86.046202
-
[4]
Edge of Stochastic Stability: Revisiting the Edge of Stability for SGD, December 2025
Arseniy Andreyev and Pierfrancesco Beneventano. Edge of Stochastic Stability: Revisiting the Edge of Stability for SGD, December 2025. URLhttp://arxiv.org/abs/2412. 20553
2025
-
[5]
High- dimensional SGD aligns with emerging outlier eigenspaces
Gerard Ben Arous, Reza Gheissari, Jiaoyang Huang, and Aukosh Jagannath. High- dimensional SGD aligns with emerging outlier eigenspaces. InThe Twelfth International Con- ference on Learning Representations, 2024. URLhttps://openreview.net/forum? id=MHjigVnI04
2024
-
[6]
Comparing Dynamics: Deep Neural Networks versus Glassy Systems
Marco Baity-Jesi, Levent Sagun, Mario Geiger, Stefano Spigler, Gerard Ben Arous, Chiara Cammarota, Yann LeCun, Matthieu Wyart, and Giulio Biroli. Comparing Dynamics: Deep Neural Networks versus Glassy Systems. InProceedings of the 35th International Conference on Machine Learning, pages 314–323. PMLR, July 2018. URLhttps://proceedings. mlr.press/v80/baity...
2018
-
[7]
Hessian inertia in neu- ral networks
Xuchan Bao, Alberto Bietti, Aaron Defazio, and Vivien Cabannes. Hessian inertia in neu- ral networks. InProceedings of the 1st Workshop on High-dimensional Learning Dynamics (HiLD), International Conference on Machine Learning (ICML), 2023. Poster presentation. 6 OPTIMIZER-DEPENDENTHESSIANDYNAMICS
2023
-
[8]
Nicholas P Baskerville, Jonathan P Keating, Francesco Mezzadri, Joseph Najnudel, and Diego Granziol. Universal characteristics of deep neural network loss surfaces from ran- dom matrix theory.Journal of Physics A: Mathematical and Theoretical, 55(49):494002, December 2022. ISSN 1751-8113, 1751-8121. doi: 10.1088/1751-8121/aca7f5. URL https://iopscience.io...
-
[9]
Tony Bonnaire, Giulio Biroli, and Chiara Cammarota. The Role of the time-Dependent Hes- sian in High-Dimensional Optimization.Journal of Statistical Mechanics: Theory and Exper- iment, 2025(8):083401, 2025. URLhttps://arxiv.org/abs/2403.02418
-
[10]
Sharp Minima Can Generalize For Deep Nets
Laurent Dinh, Razvan Pascanu, Samy Bengio, and Yoshua Bengio. Sharp Minima Can Gen- eralize for Deep Nets. InInternational Conference on Machine Learning, pages 1019–1028. PMLR, 2017. URLhttps://arxiv.org/abs/1703.04933
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
HAWQ: Hessian AWare Quantization of neural networks with mixed-precision
Zhen Dong, Zhewei Yao, Amir Gholami, Michael W Mahoney, and Kurt Keutzer. HAWQ: Hessian AWare Quantization of neural networks with mixed-precision. InProceedings of the IEEE/CVF international conference on computer vision, pages 293–302, 2019. URLhttps: //arxiv.org/abs/1905.03696
-
[12]
Sharpness-Aware Minimization for Efficiently Improving Generalization
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-Aware Mini- mization for Efficiently Improving Generalization, April 2021. URLhttp://arxiv.org/ abs/2010.01412
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Emergent properties of the local geometry of neural loss landscapes, October 2019
Stanislav Fort and Surya Ganguli. Emergent properties of the local geometry of neural loss landscapes, October 2019. URLhttp://arxiv.org/abs/1910.05929
-
[14]
An investigation into neural net opti- mization via hessian eigenvalue density, 2019
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. An investigation into neural net opti- mization via hessian eigenvalue density, 2019. URLhttps://arxiv.org/abs/1901. 10159
2019
-
[15]
An investigation into Neural Net Opti- mization via Hessian Eigenvalue Density
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. An investigation into Neural Net Opti- mization via Hessian Eigenvalue Density. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2232–2241. PMLR, 09–15 Jun 2019. URL ht...
2019
-
[16]
Understanding the difficulty of training deep feedforward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. InProceedings of the Thirteenth International Conference on Artificial Intel- ligence and Statistics, pages 249–256. JMLR Workshop and Conference Proceedings, March
-
[17]
URLhttps://proceedings.mlr.press/v9/glorot10a.html
-
[18]
Beyond Random Matrix Theory for Deep Networks, November 2021
Diego Granziol. Beyond Random Matrix Theory for Deep Networks, November 2021. URL http://arxiv.org/abs/2006.07721
-
[19]
Gradient Descent Happens in a Tiny Subspace
Guy Gur-Ari, Daniel A. Roberts, and Ethan Dyer. Gradient Descent Happens in a Tiny Sub- space, December 2018. URLhttp://arxiv.org/abs/1812.04754
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Dirk Husmeier. The bayesian evidence scheme for regularizing probability-density estimating neural networks.Neural computation, 12(11):2685–2717, 2000. URLhttps://pubmed. ncbi.nlm.nih.gov/11110132/. 7 OPTIMIZER-DEPENDENTHESSIANDYNAMICS
-
[21]
On the relation between the sharpest directions of DNN loss and the SGD step length
Stanislaw Jastrzebski, Zachary Kenton, Nicolas Ballas, Asja Fischer, Yoshua Bengio, and Amos Storkey. On the relation between the Sharpest Directions of DNN loss and the SGD Step Length, 2019. URLhttps://arxiv.org/abs/1807.05031
-
[22]
arXiv preprint arXiv:1912.02178 , year=
Yiding Jiang, Behnam Neyshabur, Hossein Mobahi, Dilip Krishnan, and Samy Bengio. Fan- tastic generalization measures and where to find them. InInternational Conference on Learn- ing Representations (ICLR), 2020. URLhttps://arxiv.org/abs/1912.02178
-
[23]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: Generalization gap and sharp minima, 2017. URLhttps://arxiv.org/abs/1609.04836
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017. URL https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Cornelius Lanczos. An iteration method for the solution of the eigenvalue problem of linear differential and integral operators.Journal of research of the National Bureau of Standards, 45(4):255–282, 1950
1950
-
[26]
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998. doi: 10.1109/5.726791
-
[27]
N. C. Murphy, R. Wortis, and W. A. Atkinson. Generalized inverse participation ratio as a possible measure of localization for interacting systems.Phys. Rev. B, 83:184206, May 2011. doi: 10.1103/PhysRevB.83.184206. URLhttps://link.aps.org/doi/10.1103/ PhysRevB.83.184206
-
[28]
Quang Nguyen and Ngoc-Kim-Khanh Nguyen. Spectral signatures of learning: Uncovering the localization phase transition in deep neural networks via random matrix theory.Physica A: Statistical Mechanics and its Applications, 692:131474, 2026. ISSN 0378-4371. doi: https: //doi.org/10.1016/j.physa.2026.131474. URLhttps://www.sciencedirect.com/ science/article/...
-
[29]
Eigenvectors of random matrices: A survey
Sean O’Rourke, Van Vu, and Ke Wang. Eigenvectors of random matrices: A survey. Journal of Combinatorial Theory, Series A, 144:361–442, 2016. ISSN 0097-3165. doi: https://doi.org/10.1016/j.jcta.2016.06.008. URLhttps://www.sciencedirect.com/ science/article/pii/S0097316516300383. Fifty Years of the Journal of Combi- natorial Theory
-
[30]
Barak A. Pearlmutter. Fast exact multiplication by the hessian.Neural Computation, 6(1): 147–160, 01 1994. ISSN 0899-7667. doi: 10.1162/neco.1994.6.1.147. URLhttps:// doi.org/10.1162/neco.1994.6.1.147
-
[31]
Mark Rudelson and Roman Vershynin. Delocalization of eigenvectors of random matri- ces with independent entries.Duke Mathematical Journal, 164(13), October 2015. ISSN 0012-7094. doi: 10.1215/00127094-3129809. URLhttp://dx.doi.org/10.1215/ 00127094-3129809
-
[32]
Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond
Levent Sagun, Leon Bottou, and Yann LeCun. Eigenvalues of the hessian in deep learning: Singularity and beyond, 2017. URLhttps://arxiv.org/abs/1611.07476. 8 OPTIMIZER-DEPENDENTHESSIANDYNAMICS
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
arXiv preprint arXiv:2405.16002 , year=
Minhak Song, Kwangjun Ahn, and Chulhee Yun. Does SGD really happen in tiny subspaces?, March 2025. URLhttp://arxiv.org/abs/2405.16002
-
[34]
EigenDamage: Struc- tured Pruning in the Kronecker-Factored Eigenbasis
Chaoqi Wang, Roger Grosse, Sanja Fidler, and Guodong Zhang. EigenDamage: Struc- tured Pruning in the Kronecker-Factored Eigenbasis. InProceedings of the 36th Inter- national Conference on Machine Learning, pages 6566–6575. PMLR, May 2019. URL https://proceedings.mlr.press/v97/wang19g.html
2019
-
[35]
Lawrence Wang and Stephen J. Roberts. Training instabilities favor flatter solutions in gradient descent.Neural Networks, 201:108874, 2026. ISSN 0893-6080. URLhttps://www. sciencedirect.com/science/article/pii/S0893608026003357
2026
-
[36]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms, 2017. URLhttps://arxiv.org/abs/ 1708.07747
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Zhewei Yao, Amir Gholami, Qi Lei, Kurt Keutzer, and Michael W Mahoney. Hessian-based analysis of large batch training and robustness to adversaries.Advances in Neural Information Processing Systems, 31, 2018. URLhttps://arxiv.org/abs/1802.08241. 9 OPTIMIZER-DEPENDENTHESSIANDYNAMICS Appendix A. Related work Gradient alignment with the top Hessian subspace....
-
[38]
Gradient and update alignment naturally overlaps for SGD
Points in the plot correspond to mean alignment values over different experiment initializations, shaded areas to min-max over 3 runs. Gradient and update alignment naturally overlaps for SGD. There is a sharp difference with the full-batch training. F.3. Learning rate impact results • Figure 17 presents thealignment across varying learning rates. We obse...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.