ViASNet: A Video Ad Saliency Network for Predicting Dynamic Saliency and Viewer Engagement
Pith reviewed 2026-06-29 08:48 UTC · model grok-4.3
The pith
ViASNet extends 3D U-Net with audio and semantic inputs to predict where viewers look in short video ads and flags low-engagement scenes via saliency-map entropy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
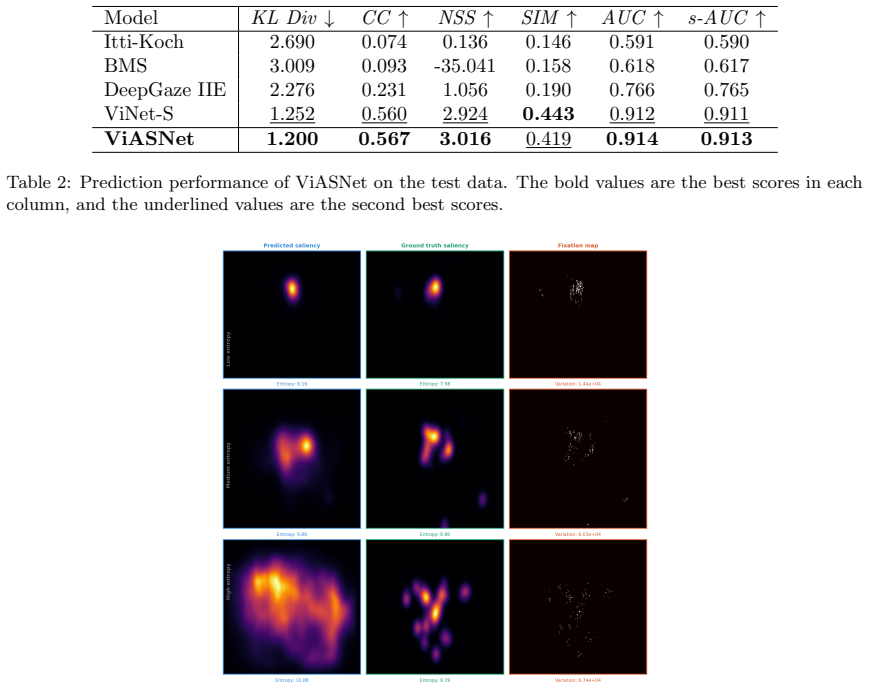
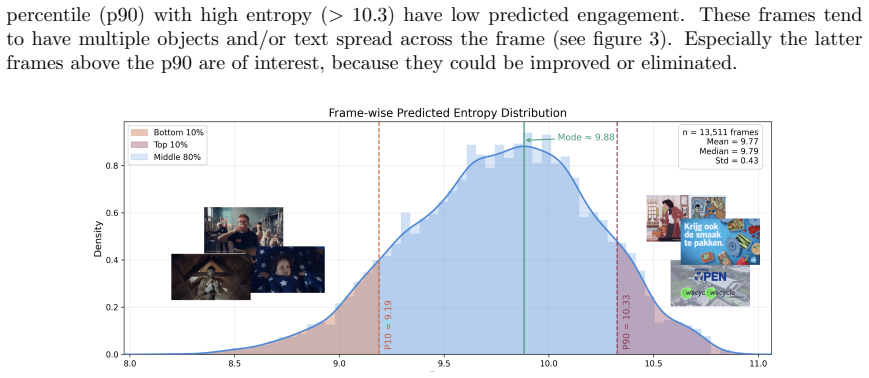
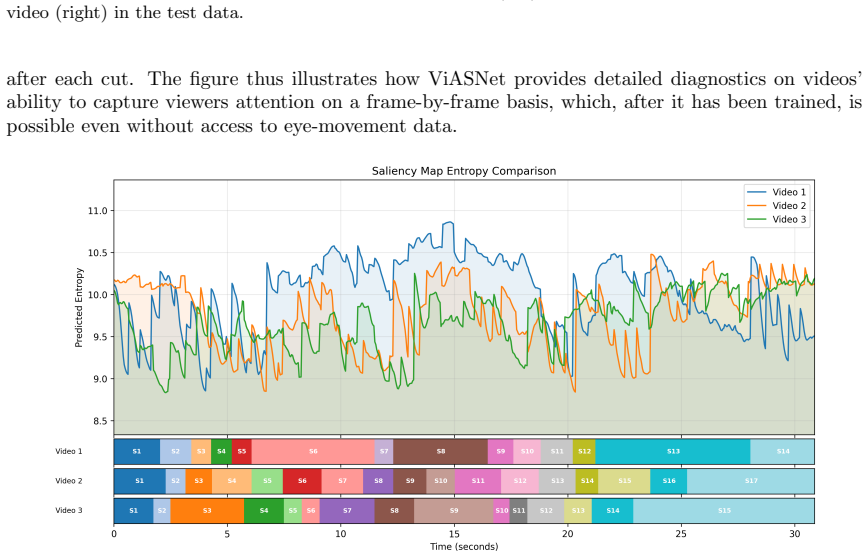
We develop and test ViASNet, a 3D U-Net architecture augmented to process audio and semantic scene information, that generates dynamic saliency maps for video ads. On a corpus of 151 ads each viewed by about 20 eye-tracked participants, the model produces saliency predictions whose frame-wise entropy identifies content that fails to engage viewers, with the same procedure illustrated on 15 unseen test ads.
What carries the argument
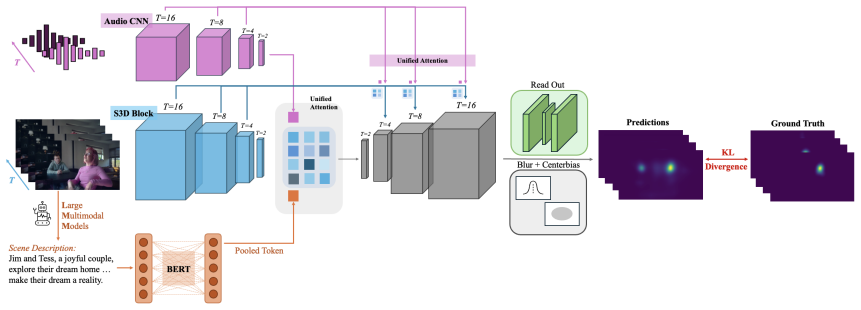
ViASNet, a 3D U-Net backbone extended to accept audio channels and semantic scene features for predicting dynamic saliency maps.
If this is right
- Saliency maps can be produced for new video ads without collecting fresh eye-tracking data.
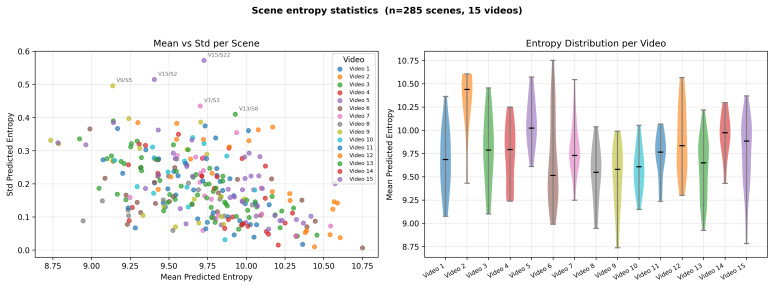
- Frame-by-frame entropy of the maps supplies an automated signal for scenes that lose viewer attention.
- Ablation results indicate that both audio and semantic inputs measurably improve prediction accuracy.
- Ad optimization loops can substitute model runs for repeated human eye-tracking sessions.
- The same entropy diagnostic can be applied at scale to large libraries of short-form video content.
Where Pith is reading between the lines
- The entropy diagnostic could be inserted into early-stage ad-creation software to give designers immediate feedback on attention-holding power.
- If the model generalizes beyond advertising, similar pipelines might evaluate engagement for user-generated short videos on social platforms.
- Combining the saliency output with existing click or completion-rate data could produce richer engagement forecasts than either signal alone.
Load-bearing premise
Eye-tracking data from about 20 viewers per ad on 151 ads supplies a representative sample that lets the trained model generalize to new ads and correctly diagnose engagement failures through saliency entropy.
What would settle it
Collect eye movements from a fresh set of 20+ video ads never seen by the model; if the predicted saliency maps match actual fixations no better than prior video saliency models, or if entropy values do not separate high- versus low-engagement scenes according to independent viewer ratings, the central claim fails.
Figures
read the original abstract
The digital media landscape has seen a pervasive shift toward short-form video advertising on TV, social media and e-commerce platforms. The present study focuses on deep saliency prediction for short-form video advertising. Deep saliency models have been used to generate predictions of human eye fixation patterns with the purpose of enhancing user interaction with digital technology and optimizing its design. For video ads, dynamic saliency maps capture where and when viewers are looking, revealing why video ads are effective, and how their content should be optimized. We develop and test a new deep dynamic saliency prediction model called ViASNet (Video Ad Saliency Network), which has an architecture founded on the 3D U-Net, and accommodates the influence of audio and the semantic meaning of scenes. We assess the model's performance on 151 video ads, each seen by about 20 viewers wile their eye movements were tracked, and explore the critical factors influencing model performance through ablation experiments. We calculate the entropy of the predicted saliency maps frame-by-frame as a diagnostic tool to identify ads and scenes that fail to engage viewers, and illustrate its use on test data of 15 unseen ads. Our study reveals that ad design and testing can be sped up considerably through automated systems built on deep saliency models such as ViASNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ViASNet, a 3D U-Net-based model for dynamic saliency prediction in short-form video ads that incorporates audio and semantic scene information. It evaluates the approach on eye-tracking data collected from 151 video ads (approximately 20 viewers each), reports ablation experiments exploring critical factors, and proposes frame-by-frame entropy of predicted saliency maps as a diagnostic for identifying low-engagement ads and scenes, with illustration on 15 unseen test ads.
Significance. If quantitative results establish reliable performance and the entropy diagnostic proves robust, the work could supply a practical automated tool for video ad optimization and testing in digital media.
major comments (2)
- [Abstract] Abstract: the description of model assessment on 151 video ads and the entropy diagnostic on 15 unseen ads provides no quantitative performance metrics (e.g., AUC, NSS, CC), baseline comparisons, error bars, training/validation split details, or inter-observer consistency checks, so the degree of empirical support for the central claims cannot be assessed.
- [Dataset/Evaluation] Dataset description: eye-tracking data from only ~20 viewers per ad is the load-bearing sample for both saliency prediction and the entropy-based engagement diagnosis; given known high inter-observer variance in eye tracking, this cohort size risks the model capturing viewer-specific patterns rather than population-level attention, with no referenced external validation set or consistency metric to mitigate the risk.
minor comments (1)
- [Abstract] Abstract: typo 'wile' should read 'while'.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments on our manuscript. We address each major comment point by point below, indicating the revisions we will make to improve clarity and empirical support.
read point-by-point responses
-
Referee: [Abstract] Abstract: the description of model assessment on 151 video ads and the entropy diagnostic on 15 unseen ads provides no quantitative performance metrics (e.g., AUC, NSS, CC), baseline comparisons, error bars, training/validation split details, or inter-observer consistency checks, so the degree of empirical support for the central claims cannot be assessed.
Authors: We agree that the abstract should include key quantitative results to allow assessment of the claims. The full manuscript reports AUC, NSS, CC, baseline comparisons, ablation results, and split details, but these are not summarized in the abstract. We will revise the abstract to incorporate representative performance metrics, baseline comparisons, error information where available, and evaluation setup details. revision: yes
-
Referee: [Dataset/Evaluation] Dataset description: eye-tracking data from only ~20 viewers per ad is the load-bearing sample for both saliency prediction and the entropy-based engagement diagnosis; given known high inter-observer variance in eye tracking, this cohort size risks the model capturing viewer-specific patterns rather than population-level attention, with no referenced external validation set or consistency metric to mitigate the risk.
Authors: We acknowledge the concern about sample size and inter-observer variance. While ~20 viewers per ad aligns with common practice in video saliency studies, we will add an explicit discussion of this limitation in the revised manuscript. We will also compute and report inter-observer consistency metrics (e.g., AUC or NSS across observers) to quantify data reliability. The 15 unseen ads function as a held-out test set, and we will clarify the train/validation/test splits; however, no fully independent external dataset beyond our collection is available. revision: partial
Circularity Check
No significant circularity; empirical training and held-out evaluation
full rationale
The paper trains a 3D U-Net variant (ViASNet) on eye-tracking fixation data from 151 video ads (~20 viewers each) and evaluates saliency predictions plus frame-wise entropy on 15 held-out ads. No derivation reduces to a fitted parameter renamed as prediction, no self-citation chain bears the central claim, and no ansatz or uniqueness theorem is imported from prior author work. The entropy diagnostic is computed directly from model outputs on unseen data rather than being defined in terms of the training targets. This is standard supervised learning with external ground truth, making the approach self-contained against the collected eye-tracking benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Network weights and training hyperparameters
axioms (1)
- domain assumption Dynamic visual attention in video ads can be predicted from combined visual, audio, and semantic features using a 3D convolutional architecture
Reference graph
Works this paper leans on
-
[1]
Abdel-Hamid, O., Mohamed, A.-r., Jiang, H., Deng, L., Penn, G., & Yu, D. (2014). Convolutional neural networks for speech recognition.IEEE/ACM Transactions on audio, speech, and language processing,22(10), 1533–1545. Agrawal, R., Jyoti, S., Girmaji, R., Sivaprasad, S., & Gandhi, V. (2022). Does audio help in deep audio-visual saliency prediction models?Pr...
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[2]
Bazzani, L., Larochelle, H., & Torresani, L. (2016). Recurrent mixture density network for spa- tiotemporal visual attention.arXiv preprint arXiv:1603.08199. Boksem, M. A., & Smidts, A. (2015). Brain responses to movie trailers predict individual preferences for movies and their population-wide commercial success.Journal of Marketing Research, 52(4), 482–...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Chaabouni, S., Benois-Pineau, J., & Amar, C. B. (2016). Transfer learning with deep networks for saliency prediction in natural video.2016 IEEE International Conference on Image Processing (ICIP), 1604–1608. Chang, Q., & Zhu, S. (2021). Temporal-spatial feature pyramid for video saliency detection.arXiv preprint arXiv:2105.04213. Chen, X., Jiang, M., & Zh...
-
[4]
Cornia, M., Baraldi, L., Serra, G., & Cucchiara, R. (2016). Multi-level net: A visual saliency pre- diction model.European Conference on Computer Vision, 302–315. Deco, G., & Sch¨ urmann, B. (2000). A hierarchical neural system with attentional top–down en- hancement of the spatial resolution for object recognition.Vision research,40(20), 2845–
2016
-
[5]
Djilali, Y. A. D., Sayah, M., McGuinness, K., & O’Connor, N. E. (2020). 3dsal: An efficient 3d-cnn architecture for video saliency prediction. Dong, X., Liu, H., Xi, N., Liao, J., & Yang, Z. (2024). Short video marketing: What, when and how short-branded videos facilitate consumer engagement.Internet Research,34(3), 1104–1128. Donk, M., & Van Zoest, W. (2...
2020
-
[6]
Hakim, A., Klorfeld, S., Sela, T., Friedman, D., Shabat-Simon, M., & Levy, D. J. (2021). Machines learn neuromarketing: Improving preference prediction from self-reports using multiple eeg measures and machine learning.International Journal of Research in marketing,38(3), 770–791. He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for im...
2021
-
[7]
18 Jain, S., Yarlagadda, P., Jyoti, S., Karthik, S., Subramanian, R., & Gandhi, V. (2021). Vinet: Pushing the limits of visual modality for audio-visual saliency prediction.2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 3520–3527. Janiszewski, C., & Warlop, L. (1993). The influence of classical conditioning procedures on ...
2021
-
[8]
Jiang, L., Xu, M., & Wang, Z. (2017). Predicting video saliency with object-to-motion cnn and two-layer convolutional lstm.arXiv preprint arXiv:1709.06316. Jiang, Y., Leiva, L. A., Rezazadegan Tavakoli, H., RB Houssel, P., Kylm¨ al¨ a, J., & Oulasvirta, A. (2023). Ueyes: Understanding visual saliency across user interface types.Proceedings of the 2023 CHI...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/2504730.2504748 2017
-
[9]
K¨ ummerer, M., Bethge, M., & Wallis, T. S. (2022). Deepgaze iii: Modeling free-viewing human scanpaths with deep learning.Journal of Vision,22(5), 7–7. K¨ ummerer, M., Theis, L., & Bethge, M. (2014). Deep gaze i: Boosting saliency prediction with feature maps trained on imagenet.arXiv preprint arXiv:1411.1045. K¨ ummerer, M., Wallis, T. S. A., & Bethge, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/tpami.2014.2366154 2022
-
[10]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Peters, R. J., & Itti, L. (2007). Beyond bottom-up: Incorporating task-dependent influences into a computational model of spatial attention.2007 IEEE conference on computer vision and pattern recognition, 1–8. Pieters, R., Rosbergen, E., & Wedel, M. (1999). Visual attention to repeated print advertising: A test of scanpath theory.Journal of marketing rese...
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[11]
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556. Staufenbiel, S. M., Van der Lubbe, R. H., & Talsma, D. (2011). Spatially uninformative sounds increase sensitivity for visual motion change.Experimental brain research,213(4), 457–
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[12]
E., Jiang, W., & Stanford, T
Stein, B. E., Jiang, W., & Stanford, T. R. (2004). Multisensory integration in single neurons of the midbrain. In G. Calvert, C. Spence, & B. Stein (Eds.),The handbook of multisensory processes. MIT press. Stein, B. E., London, N., Wilkinson, L. K., & Price, D. D. (1996). Enhancement of perceived visual intensity by auditory stimuli: A psychophysical anal...
2004
-
[13]
22 Theeuwes, J., & Chen, C. Y. D. (2005). Attentional capture and inhibition (of return): The effect on perceptual sensitivity.Perception & psychophysics,67(8), 1305–1312. Thompson, K. G., & Bichot, N. P. (2005). A visual salience map in the primate frontal eye field. Progress in brain research,147, 249–262. Tong, L. C., Acikalin, M. Y., Genevsky, A., Shi...
2005
-
[14]
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention.Cognitive psychol- ogy,12(1), 97–136. Unger, M., Wedel, M., & Tuzhilin, A. (2024). Predicting consumer choice from raw eye-movement data using the retina deep learning architecture.Data Mining and Knowledge Discovery, 38(3), 1069–1100. Van der Lans, R., Pieters, R., & Wedel, M...
-
[15]
H., & Cottrell, G
Zhang, L., Tong, M. H., & Cottrell, G. W. (2009). Sunday: Saliency using natural statistics for dynamic analysis of scenes.Proceedings of the 31st annual cognitive science conference, 2944–2949. 24 Zhou, X., Wu, S., Shi, R., Zheng, B., Wang, S., Yin, H., Zhang, J., & Yan, C. (2023). Transformer- based multi-scale feature integration network for video sali...
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.