PrivFusion: A Privacy-preserving Multi-Agent Framework for Harmonizing Distributed Datasets
Pith reviewed 2026-06-30 16:06 UTC · model grok-4.3
The pith
PrivFusion uses multi-agent collaboration to harmonize heterogeneous datasets privately for federated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
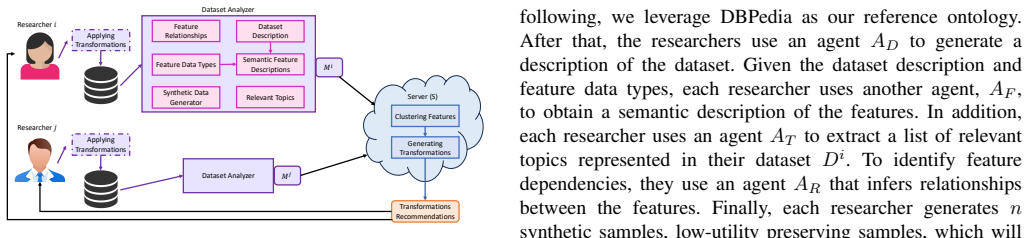
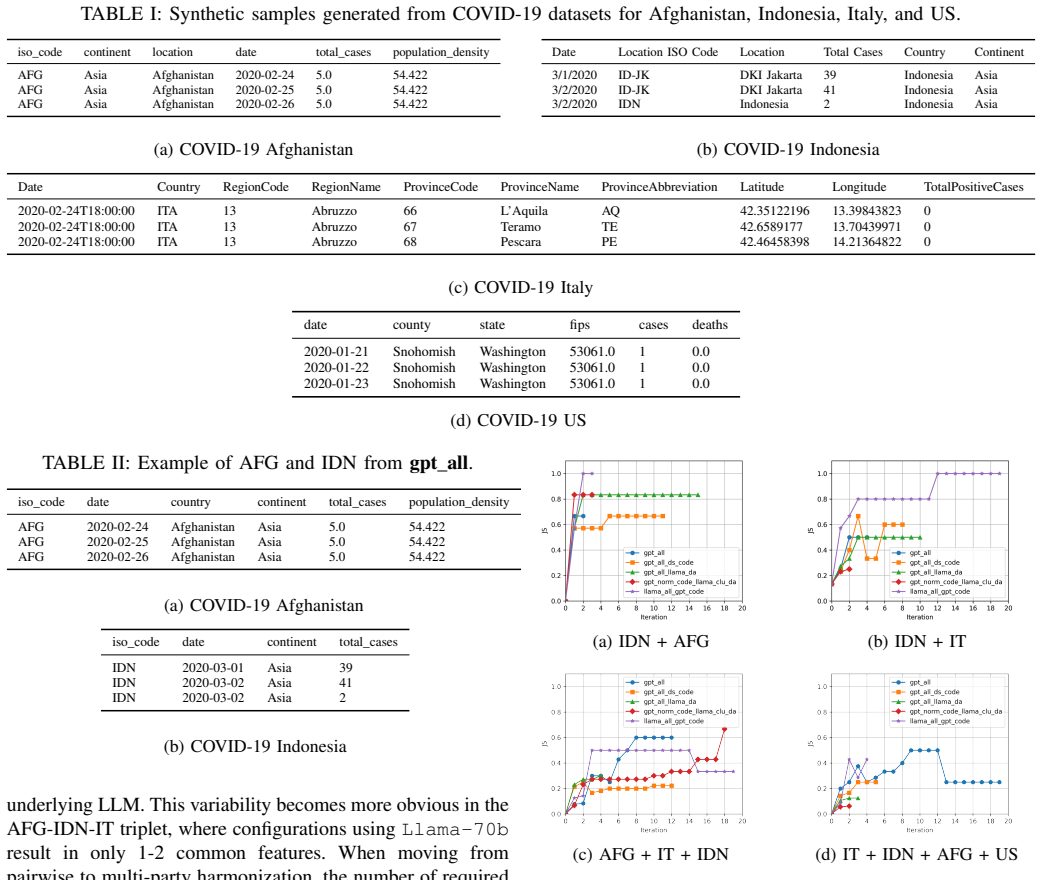
PrivFusion uses agents to analyze local data, cluster semantically similar features across sites, and provide iterative transformation recommendations until alignment is achieved. Evaluation across four heterogeneous COVID-19 datasets demonstrates that PrivFusion effectively and efficiently harmonizes multi-site data while substantially reducing manual effort.
What carries the argument
The multi-agent system performing local analysis, semantic clustering of features across sites, and iterative transformation recommendations without raw data sharing.
Load-bearing premise
That local agents can correctly identify semantically similar features across sites and that their iterative transformation recommendations will produce usable alignment, all without any raw data leaving its original location.
What would settle it
If the recommended transformations fail to produce datasets where federated learning achieves performance close to what centralized training would, or if feature clusters do not align semantically on new data.
Figures
read the original abstract
The growing availability of clinical data has increased the use of machine learning, yet centralized data aggregation is often infeasible for sensitive health information. Federated Learning (FL) offers a distributed alternative, but its adoption is limited by substantial heterogeneity across institutional datasets, making harmonization a critical but frequently overlooked prerequisite for multi-site analytics. We introduce PrivFusion, a privacy-preserving multi-agent framework that automates the harmonization of structured datasets prior to federated training. PrivFusion uses agents to analyze local data, cluster semantically similar features across sites, and provide iterative transformation recommendations until alignment is achieved. Evaluation across four heterogeneous COVID-19 datasets demonstrates that PrivFusion effectively and efficiently harmonizes multi-site data while substantially reducing manual effort.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PrivFusion, a privacy-preserving multi-agent framework for automating harmonization of heterogeneous structured clinical datasets prior to federated learning. Local agents analyze site data to cluster semantically similar features across institutions and iteratively recommend transformations until alignment is reached, all without raw data leaving its original location. The central claim is that evaluation across four heterogeneous COVID-19 datasets shows PrivFusion effectively and efficiently harmonizes multi-site data while substantially reducing manual effort.
Significance. If the empirical results and underlying mechanism hold, the work could address a key practical obstacle to federated learning in healthcare by automating data harmonization without centralization or extensive manual intervention, thereby improving the feasibility of multi-site analytics on sensitive data.
major comments (2)
- [Abstract] Abstract: the evaluation is described solely as demonstrating that PrivFusion 'effectively and efficiently harmonizes multi-site data while substantially reducing manual effort,' with no quantitative metrics, baselines, ablation studies, statistical tests, or performance numbers supplied. This leaves the central empirical claim without evidentiary support.
- The core assumption that local agents can reliably detect semantic equivalence between features (e.g., 'age' vs. 'patient_age' or 'lab_value_X' vs. 'result_Y') across sites using only local data is load-bearing for both the automation and privacy claims, yet no mechanism (embedding similarity, string matching, ontology, or otherwise), algorithm, or validation on heterogeneous COVID-19 naming conventions is provided.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of our empirical results and technical details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the evaluation is described solely as demonstrating that PrivFusion 'effectively and efficiently harmonizes multi-site data while substantially reducing manual effort,' with no quantitative metrics, baselines, ablation studies, statistical tests, or performance numbers supplied. This leaves the central empirical claim without evidentiary support.
Authors: We agree that the abstract would be strengthened by including quantitative support for the claims. The body of the manuscript (Section 4) reports specific metrics including feature alignment rates across the four COVID-19 datasets, reduction in manual harmonization effort relative to a manual baseline, runtime comparisons, and ablation results on the agent components. We will revise the abstract to concisely incorporate key quantitative findings (e.g., alignment percentages, effort reduction, and statistical significance where applicable) while preserving its high-level nature. revision: yes
-
Referee: The core assumption that local agents can reliably detect semantic equivalence between features (e.g., 'age' vs. 'patient_age' or 'lab_value_X' vs. 'result_Y') across sites using only local data is load-bearing for both the automation and privacy claims, yet no mechanism (embedding similarity, string matching, ontology, or otherwise), algorithm, or validation on heterogeneous COVID-19 naming conventions is provided.
Authors: The manuscript states that agents cluster semantically similar features using local analysis, but we acknowledge that the specific detection mechanism, algorithm details, and targeted validation on COVID-19 feature naming variations require clearer exposition. We will add an expanded methods subsection with the precise approach (local embedding similarity with iterative refinement), pseudocode, and empirical validation results demonstrating performance on the heterogeneous naming conventions present in the four datasets. revision: yes
Circularity Check
No circularity; empirical framework evaluation is self-contained
full rationale
The paper describes a multi-agent framework for privacy-preserving dataset harmonization and reports empirical results on four COVID-19 datasets. No equations, parameter-fitting steps, predictions derived from fitted inputs, or load-bearing self-citations appear in the abstract or described content. The central claim is an observed outcome of the method rather than a quantity that reduces to its own inputs by construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Disease prediction by machine learning over big data from healthcare communities,
M. Chen, Y . Hao, K. Hwang, L. Wang, and L. Wang, “Disease prediction by machine learning over big data from healthcare communities,”IEEE access, vol. 5, pp. 8869–8879, 2017
2017
-
[2]
Federated learning for healthcare: Systematic review and architecture proposal,
R. S. Antunes, C. André da Costa, A. Küderle, I. A. Yari, and B. Eskofier, “Federated learning for healthcare: Systematic review and architecture proposal,”ACM Transactions on Intelligent Systems and Technology, vol. 13, no. 4, pp. 1–23, 2022
2022
-
[3]
Data harmonization for heterogeneous datasets: a systematic literature review,
G. Kumar, S. Basri, A. A. Imam, S. A. Khowaja, L. F. Capretz, and A. O. Balogun, “Data harmonization for heterogeneous datasets: a systematic literature review,”Applied Sciences, vol. 11, no. 17, p. 8275, 2021
2021
-
[4]
Cohort harmonization and integrative analysis from a biomedical engi- neering perspective,
K. D. Kourou, V . C. Pezoulas, E. I. Georga, T. P. Exarchos, P. Tsanakas, M. Tsiknakis, T. Varvarigou, S. De Vita, A. Tzioufas, and D. I. Fotiadis, “Cohort harmonization and integrative analysis from a biomedical engi- neering perspective,”IEEE Reviews in Biomedical Engineering, 2018
2018
-
[5]
Generation of open biomedical datasets through ontology-driven transformation and integration pro- cesses,
M. d. Carmen Legaz-García, J. A. Miñarro-Giménez, M. Menárguez- Tortosa, and J. T. Fernández-Breis, “Generation of open biomedical datasets through ontology-driven transformation and integration pro- cesses,”Journal of Biomedical Semantics, vol. 7, no. 1, p. 32, 2016
2016
-
[6]
A novel approach for clinical data harmonization,
E. Chondrogiannis, V . Andronikou, E. Karanastasis, and T. Varvarigou, “A novel approach for clinical data harmonization,” inIEEE Interna- tional Conference on Big Data and Smart Computing (BigComp), 2019
2019
-
[7]
Synthetic data–anonymisation groundhog day,
T. Stadler, B. Oprisanu, and C. Troncoso, “Synthetic data–anonymisation groundhog day,” in31st USENIX Security Symposium, 2022
2022
-
[8]
"what do you want from theory alone?
M. S. M. S. Annamalai, G. Ganev, and E. De Cristofaro, “"what do you want from theory alone?" experimenting with tight auditing of differentially private synthetic data generation,” in33rd USENIX Security Symposium (USENIX Security), pp. 4855–4871, 2024
2024
-
[9]
The inadequacy of similarity-based privacy metrics: Privacy attacks against “truly anonymous
G. Ganev and E. De Cristofaro, “The inadequacy of similarity-based privacy metrics: Privacy attacks against “truly anonymous” synthetic datasets,” inIEEE Symposium on Security and Privacy (SP), 2025
2025
-
[10]
Pragmatic de-identification of cross-domain unstructured documents: A utility-preserving approach with relation extraction filtering,
L. Nedoshivina, A. Halimi, J. Bettencourt-Silva, and S. Braghin, “Pragmatic de-identification of cross-domain unstructured documents: A utility-preserving approach with relation extraction filtering,”AMIA Summits on Translational Science Proceedings, vol. 2024, p. 85, 2024
2024
-
[11]
An extensible de-identification framework for privacy protection of unstruc- tured health information: creating sustainable privacy infrastructures,
S. Braghin, J. H. Bettencourt-Silva, K. Levacher, and S. Antonatos, “An extensible de-identification framework for privacy protection of unstruc- tured health information: creating sustainable privacy infrastructures,” in MEDINFO: Health and Wellbeing E-networks for All, 2019
2019
-
[12]
gpt-oss-120b & gpt-oss-20b Model Card
S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y . Bai, B. Baker, H. Bao,et al., “gpt-oss-120b & gpt-oss-20b model card,”arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
The llama 3 herd of models,
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan,et al., “The llama 3 herd of models,”arXiv e-prints, pp. arXiv–2407, 2024
2024
-
[14]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y . Wu, Y . Li,et al., “Deepseek-coder: When the large language model meets programming–the rise of code intelligence,”arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Étude comparative de la distribution florale dans une portion des alpes et des jura,
P. Jaccard, “Étude comparative de la distribution florale dans une portion des alpes et des jura,”Bulletin de la Société Vaudoise des Sciences Naturelles, vol. 37, pp. 547–579, 1901
1901
-
[16]
Challenges and opportunities in dmri data harmonization,
A. H. Zhu, D. C. Moyer, T. M. Nir, P. M. Thompson, and N. Jahanshad, “Challenges and opportunities in dmri data harmonization,” inInterna- tional Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 157–172, Springer, 2019
2019
-
[17]
An ontology- based spatial data harmonisation for urban analytics,
Y . Chen, S. Sabri, A. Rajabifard, and M. E. Agunbiade, “An ontology- based spatial data harmonisation for urban analytics,”Computers, Envi- ronment and Urban Systems, vol. 72, pp. 177–190, 2018
2018
-
[18]
multiomics: A user- friendly multi-omics data harmonisation r pipeline,
T. Chen, A. J. Abadi, K.-A. Lê Cao, and S. Tyagi, “multiomics: A user- friendly multi-omics data harmonisation r pipeline,”F1000Research, vol. 10, no. 538, p. 538, 2023
2023
-
[19]
A general primer for data harmonization,
C. Cheng, L. Messerschmidt, I. Bravo, M. Waldbauer, R. Bhavikatti, C. Schenk, V . Grujic, T. Model, R. Kubinec, and J. Barceló, “A general primer for data harmonization,”Scientific data, vol. 11, p. 152, 2024
2024
-
[20]
Harmonization of land-use scenarios for the period 1500–2100: 600 years of global gridded annual land-use transitions, wood harvest, and resulting secondary lands,
G. C. Hurtt, L. P. Chini, S. Frolking, R. Betts, J. Feddema, G. Fischer, J. Fisk, K. Hibbard, R. Houghton, A. Janetos,et al., “Harmonization of land-use scenarios for the period 1500–2100: 600 years of global gridded annual land-use transitions, wood harvest, and resulting secondary lands,”Climatic Change, vol. 109, no. 1, p. 117, 2011
2011
-
[21]
Harmonisation of national influenza surveillance morbidity data from eiss: a simple index.,
H. Uphoff, J.-M. Cohen, D. Fleming, and A. Noone, “Harmonisation of national influenza surveillance morbidity data from eiss: a simple index.,”Euro Surveillance: Bulletin Europeen sur les Maladies Trans- missibles= European Communicable Disease Bulletin, 2003
2003
-
[22]
Harmonization-information trade- offs for sharing individual participant data in biomedicine,
A. Torres-Espín and A. R. Ferguson, “Harmonization-information trade- offs for sharing individual participant data in biomedicine,”Harvard Data Science Review, vol. 4, no. 3, pp. 10–1162, 2022
2022
-
[23]
Datashield: taking the analysis to the data, not the data to the analysis,
A. Gaye, Y . Marcon, J. Isaeva, P. LaFlamme, A. Turner, E. M. Jones, J. Minion, A. W. Boyd, C. J. Newby, M.-L. Nuotio,et al., “Datashield: taking the analysis to the data, not the data to the analysis,”International Journal of Epidemiology, vol. 43, no. 6, pp. 1929–1944, 2014
1929
-
[24]
Distributed learning on 20000+ lung cancer patients – the personal health train,
T. M. Deist, F. J. Dankers, P. Ojha, M. Scott Marshall, T. Janssen, C. Faivre-Finn, P. Lambin, and A. Dekker, “Distributed learning on 20000+ lung cancer patients – the personal health train,”Radiotherapy and Oncology, vol. 144, pp. 189–200, 2020
2020
-
[25]
Towards personalized federated learning,
A. Z. Tan, H. Yu, L. Cui, and Q. Yang, “Towards personalized federated learning,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 12, pp. 9587–9603, 2022
2022
-
[26]
Personalized federated learning: A meta-learning approach,
A. Fallah, A. Mokhtari, and A. Ozdaglar, “Personalized federated learning: A meta-learning approach,”arXiv preprint arXiv:2002.07948, 2020
-
[27]
Sample- level data selection for federated learning,
A. Li, L. Zhang, J. Tan, Y . Qin, J. Wang, and X.-Y . Li, “Sample- level data selection for federated learning,” inIEEE INFOCOM-IEEE Conference on Computer Communications, pp. 1–10, IEEE, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.