Computer-Aided Data Mining: Automating a Novel Knowledge Discovery and Data Mining Process Model for Metabolomics
Pith reviewed 2026-05-25 00:17 UTC · model grok-4.3
The pith
MeKDDaM-SAGA software automates a custom process model to make metabolomics data analysis justifiable, traceable and reproducible.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
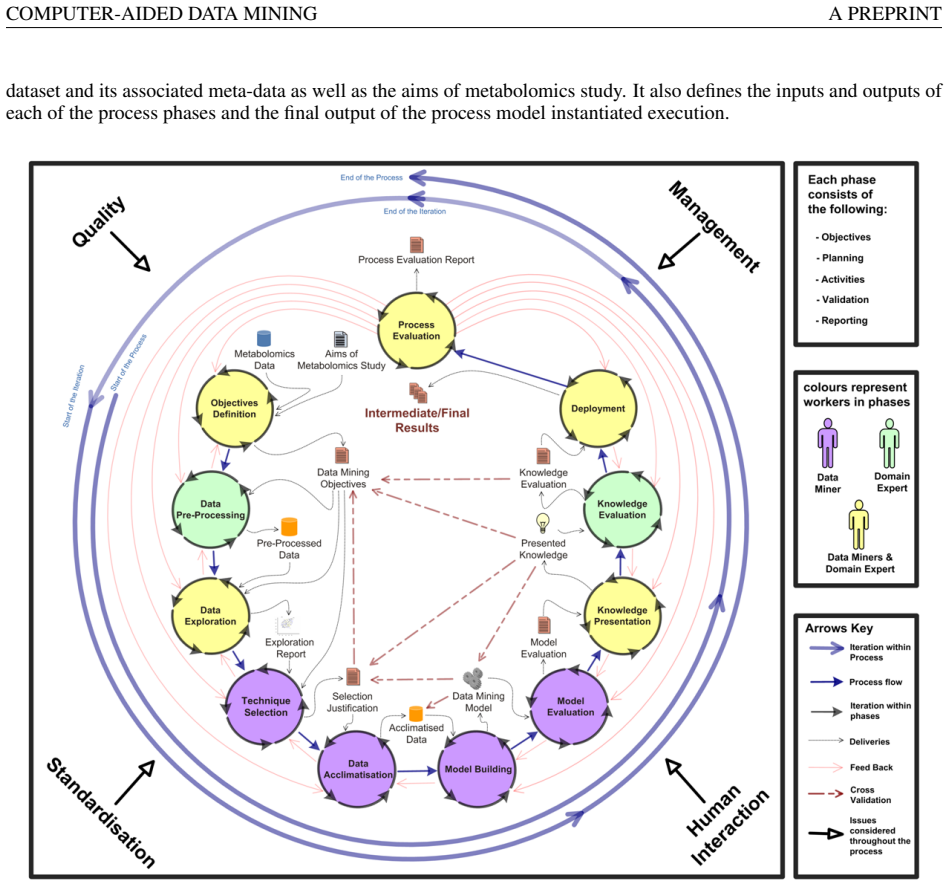
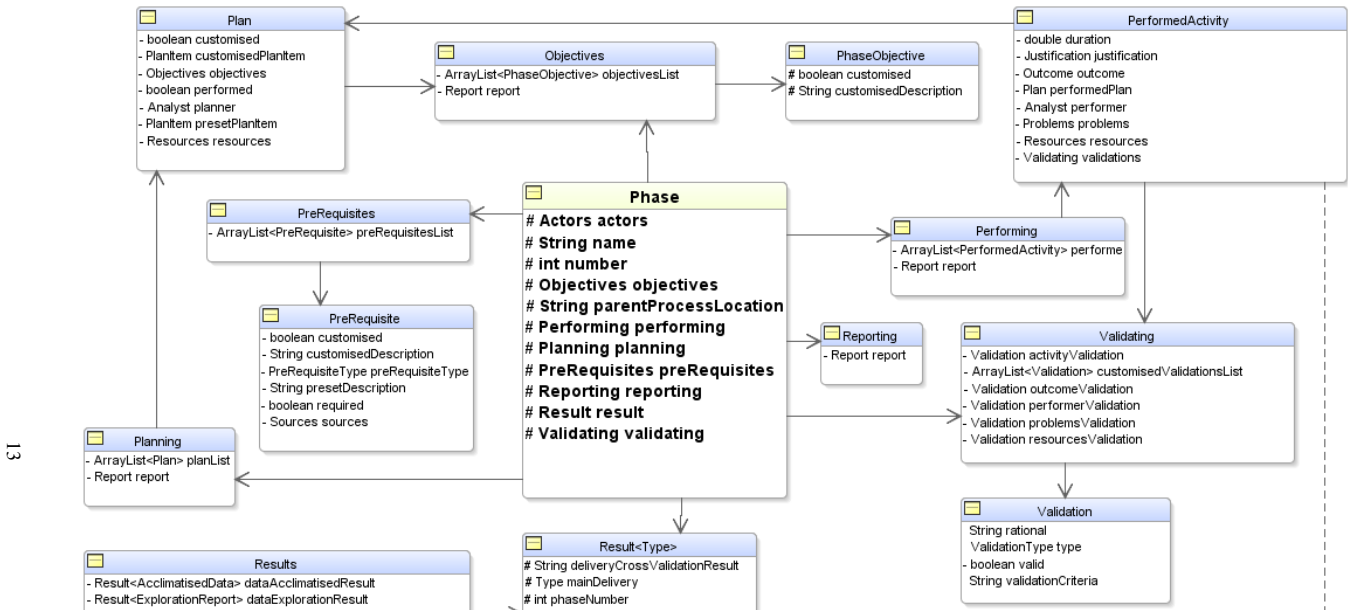
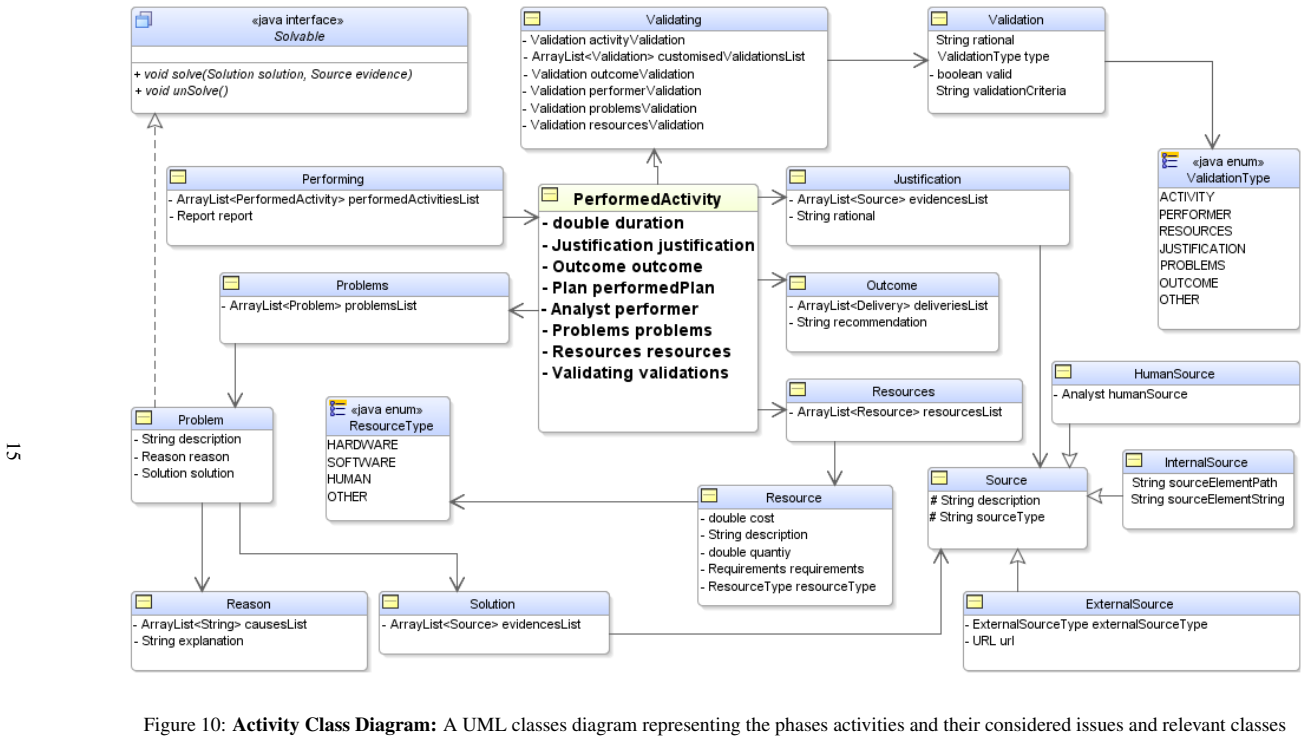
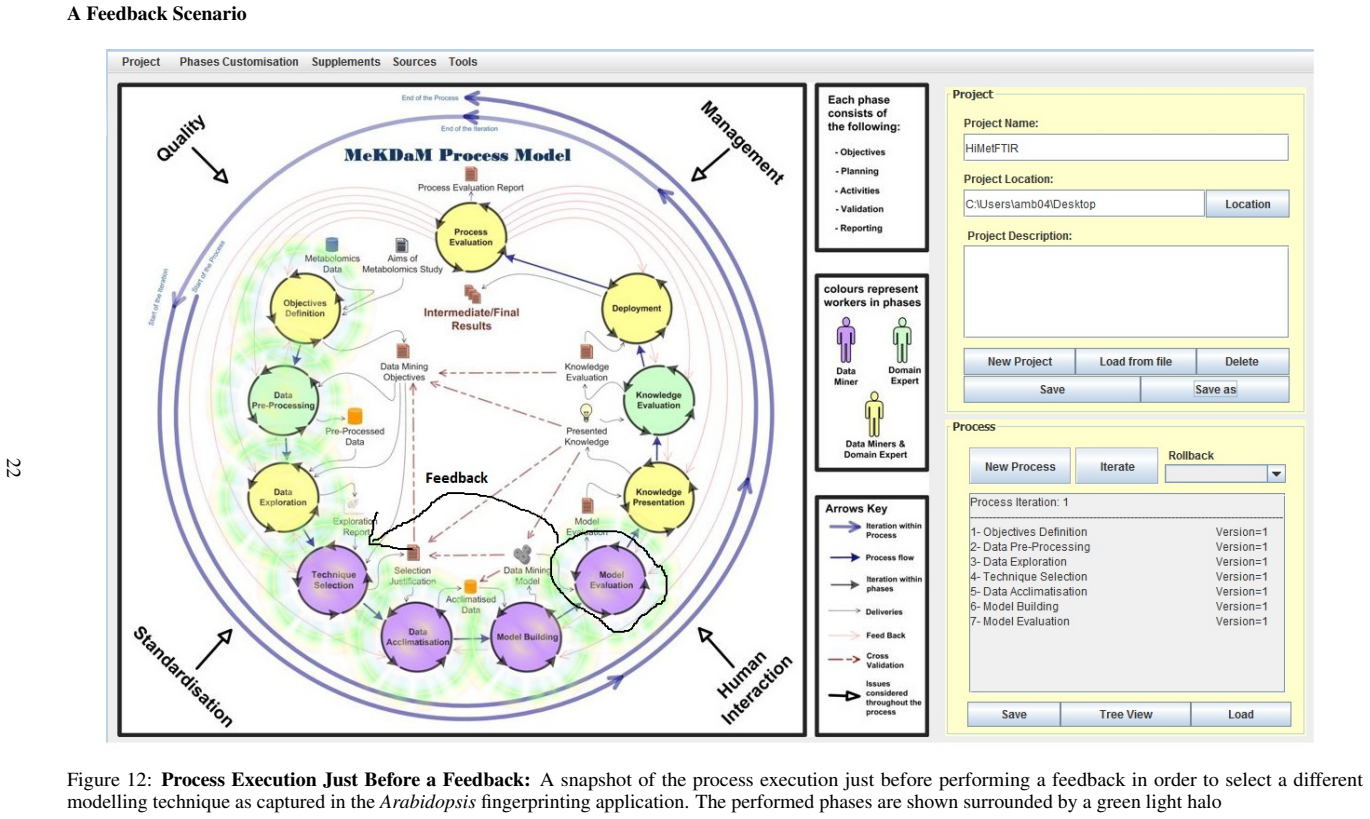
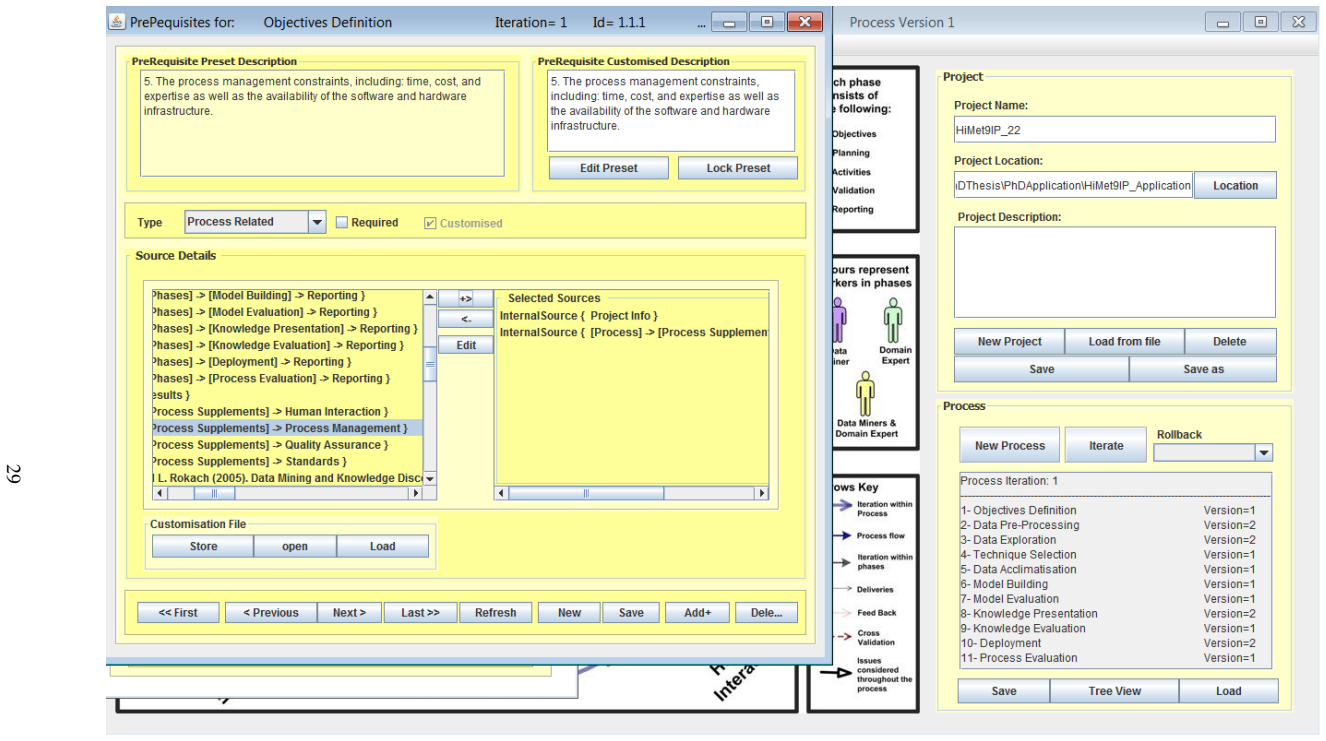
MeKDDaM-SAGA realises the layout, structure and flow of the proposed process model through 241 design classes implementing 27 use-cases, enabling external or internal execution of the model phases while guaranteeing portability, user-friendliness and management of iterations via its embedded version control.
What carries the argument
MeKDDaM-SAGA, the object-oriented Java software consisting of 241 classes that implements the novel KDD process model for metabolomics either externally or via its built-in activities.
If this is right
- Analyses guided by the model can use either external data mining tools or the software's internal preprocessing, modeling and visualization facilities.
- Process flow, feedback loops and iterations are managed automatically by the embedded version control system, allowing undo and redo of phases and tasks.
- Portability is ensured by the XML database while the GUI supports direct user interaction with the process.
- The software satisfies the design and execution requirements of the proposed metabolomics process model in the applications tested.
Where Pith is reading between the lines
- Widespread use of such automation could reduce differences in analysis pipelines between different metabolomics laboratories.
- The same software architecture might be adapted to create similar guided process models for other data-intensive fields such as proteomics or environmental chemistry.
- Without published head-to-head comparisons against standard KDD frameworks, it remains open whether the claimed traceability gains exceed those from existing tools.
Load-bearing premise
The authors' custom process model is both novel and required for metabolomics, and the software implements it correctly without adding new errors or limitations.
What would settle it
An independent test that applies the same metabolomics datasets with and without MeKDDaM-SAGA and finds no measurable gain in traceability or reproducibility of results would falsify the effectiveness claim.
Figures





























read the original abstract
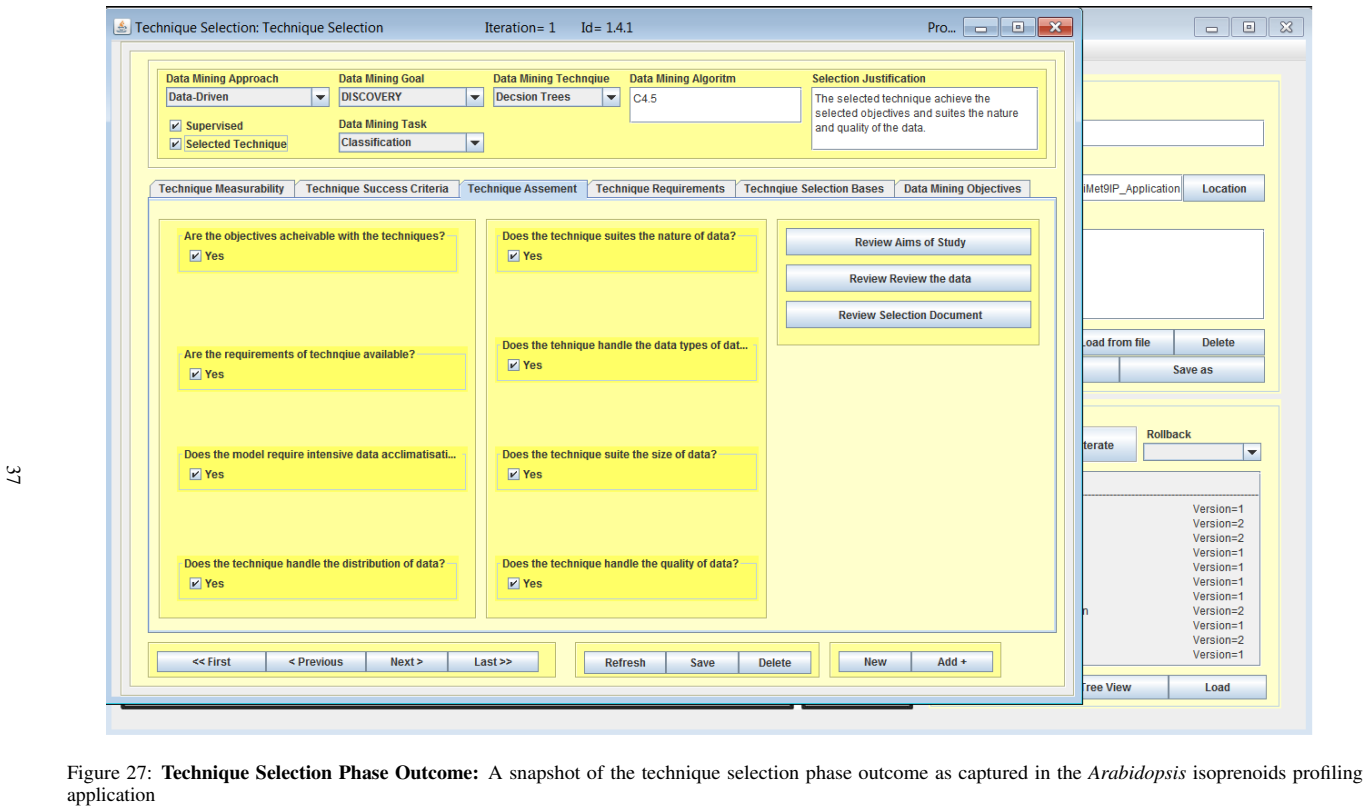
This work presents MeKDDaM-SAGA, computer-aided automation software for implementing a novel knowledge discovery and data mining process model that was designed for performing justifiable, traceable and reproducible metabolomics data analysis. The process model focuses on achieving metabolomics analytical objectives and on considering the nature of its involved data. MeKDDaM-SAGA was successfully used for guiding the process model execution in a number of metabolomics applications. It satisfies the requirements of the proposed process model design and execution. The software realises the process model layout, structure and flow and it enables its execution externally using various data mining and machine learning tools or internally using a number of embedded facilities that were built for performing a number of automated activities such as data preprocessing, data exploration, data acclimatization, modelling, evaluation and visualization. MeKDDaM-SAGA was developed using object-oriented software engineering methodology and was constructed in Java. It consists of 241 design classes that were designed to implement 27 use-cases. The software uses an XML database to guarantee portability and uses a GUI interface to ensure its user-friendliness. It implements an internal embedded version control system that is used to realise and manage the process flow, feedback and iterations and to enable undoing and redoing the execution of the process phases, activities, and the internal tasks within its phases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MeKDDaM-SAGA, a Java-based software system with 241 design classes implementing 27 use-cases, that automates a novel KDD process model for metabolomics. The model emphasizes justifiable, traceable, and reproducible analysis by focusing on analytical objectives and data characteristics. The software supports external DM/ML tools or internal facilities for preprocessing, exploration, acclimatization, modeling, evaluation, and visualization; it uses an XML database for portability and an embedded VCS to manage process flow, feedback, iterations, and undo/redo operations. The central claims are that the software was successfully used to guide the process model in multiple metabolomics applications and that it satisfies the model's design and execution requirements.
Significance. If the claims of successful use and requirement satisfaction were supported by evidence, the work would provide a specialized, traceable automation framework for metabolomics KDD that could improve reproducibility. The object-oriented design, embedded VCS for iteration management, and dual internal/external execution options represent concrete engineering strengths. However, the current absence of any reported applications, metrics, or validation data prevents assessment of actual impact or adoption potential.
major comments (2)
- [Abstract] Abstract: The assertion that 'MeKDDaM-SAGA was successfully used for guiding the process model execution in a number of metabolomics applications' and 'satisfies the requirements of the proposed process model design and execution' is presented without any case-study details, datasets, quantitative success criteria, error analysis, reproducibility measures, or comparisons to prior KDD models/tools. This directly undermines evaluation of the central claim.
- [The manuscript] The manuscript (architecture and implementation sections): The description of 241 classes, 27 use-cases, internal facilities, and embedded VCS is given at a high level, but no validation is supplied that the implementation correctly realizes the process model phases/activities without introducing errors or limitations, which is load-bearing for the claim of requirement satisfaction.
minor comments (2)
- [Abstract] Abstract: The term 'data acclimatization' is introduced without definition or linkage to specific activities in the process model.
- [The manuscript] The manuscript: No diagram or table is referenced that maps the 27 use-cases or 241 classes to the process model phases, which would improve clarity of the implementation claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point-by-point to the major comments below, acknowledging the manuscript's limitations where evidence is absent.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'MeKDDaM-SAGA was successfully used for guiding the process model execution in a number of metabolomics applications' and 'satisfies the requirements of the proposed process model design and execution' is presented without any case-study details, datasets, quantitative success criteria, error analysis, reproducibility measures, or comparisons to prior KDD models/tools. This directly undermines evaluation of the central claim.
Authors: We agree that the abstract asserts successful use in applications and satisfaction of requirements without any supporting case studies, datasets, metrics, or comparisons in the manuscript. The provided text describes the software's design (241 classes, 27 use-cases, XML database, embedded VCS) but supplies no empirical evidence for these claims. This is a substantive weakness. We will revise the abstract to remove the unsubstantiated assertions of 'successful use' and instead describe the software as implementing the process model, with any application references qualified or removed. Detailed validation belongs in companion papers. revision: yes
-
Referee: [The manuscript] The manuscript (architecture and implementation sections): The description of 241 classes, 27 use-cases, internal facilities, and embedded VCS is given at a high level, but no validation is supplied that the implementation correctly realizes the process model phases/activities without introducing errors or limitations, which is load-bearing for the claim of requirement satisfaction.
Authors: The referee correctly identifies that the architecture and implementation sections offer only a high-level description without any validation (e.g., testing, verification of phase fidelity, or error analysis) that the 241 classes correctly realize the process model. No such evidence appears in the manuscript. We will revise by adding an explicit statement acknowledging the lack of formal validation as a limitation and describing the object-oriented methodology used during construction. Comprehensive validation data are not available for inclusion at this stage. revision: partial
- Providing the missing case-study details, datasets, quantitative success criteria, error analysis, reproducibility measures, or implementation validation results, as none of these are documented in the current manuscript.
Circularity Check
No circularity; software description with no derivations or self-referential logic
full rationale
The paper is a description of custom software (MeKDDaM-SAGA) implementing a claimed novel KDD process model for metabolomics. No equations, fitted parameters, predictions, or derivation chains exist. Claims of successful use and requirement satisfaction are direct assertions without reduction to prior self-citations or internal definitions. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear. The central claims rest on implementation statements rather than any self-referential construction, making the paper self-contained against the circularity criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vicki Maloney. Plant metabolomics. BioTeach Journal, 2:92–99, 2004
work page 2004
-
[2]
K. Dettmer and D. Hammock. Metabolomics: a new exciting field within the "omics" sciences. Evironmental Health Perspectives, 112(7):A396–A397, 2004
work page 2004
-
[3]
W. B. Dunn and D. I. Ellis. Metabolomics: Current analytical platforms and methodologies. Trends in Analytical Chemistry, 24(4):285–294, 2005
work page 2005
-
[4]
Jianguo Xia, Nick Psychogios, Nelson Young, and David S. Wishart. MetaboAnalyst- a web server for metabolomic data analysis and interpretation. Nucleic Acids Research, 37(suppl2):W652–660, 2009
work page 2009
-
[5]
Royston Goodacre, David Broadhurst, Age Smilde, Bruce Kristal, J. Baker, Richard Beger, Conrad Bessant, Susan Connor, Giorgio Capuani, Andrew Craig, Tim Ebbels, Douglas Kell, Cesare Manetti, Jack Newton, Giovanni Paternostro, Ray Somorjai, Michael Sjostrom, Johan Trygg, and Florian Wulfert. Proposed minimum reporting standards for data analysis in metabol...
work page 2007
-
[6]
MeMo: A hybrid SQL/XML approach to metabolomic data management for functional genomics
Irena Spasic, Warwick Dunn, Giles Velarde, Andy Tseng, Helen Jenkins, Nigel Hardy, Stephen Oliver, and Douglas Kell. MeMo: A hybrid SQL/XML approach to metabolomic data management for functional genomics. BMC Bioinformatics, 7(1):281, 2006
work page 2006
-
[7]
L. W. Sumner, A. Amberg, D. Barrett, M. H. Beale, R. Beger, C. A. Daykin, T. W. M. Fan, O. Fiehn, R. Goodacre, J. L. Griffin, T. Hankemeier, N. Hardy, J. Harnly, R. Higashi, J. Kopka, A. N. Lane, J. C. Lindon, P. Marriott, A. W. Nicholls, M. D. Reily, J. J. Thaden, and M. R. Viant. Proposed minimum reporting standards for chemical analysis. Metabolomics, 3...
work page 2007
-
[8]
H. Jenkins, H. Johnson, B. Kular, T. Wang, and N. Hardy. Toward supportive data collection tools for plant metabolomics. Plant Physiology, 138(1):67–77, 2005
work page 2005
-
[9]
Frawley, Gregory Piatetsky-Shapiro, and Christopher J
William J. Frawley, Gregory Piatetsky-Shapiro, and Christopher J. Matheus. Knowledge discovery in databases: an overview. AI Magazine, 13(3):57–70, 1992
work page 1992
-
[10]
The KDD process for extracting useful knowledge from volumes of data
Usama Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth. The KDD process for extracting useful knowledge from volumes of data. COMMUNICATIONS OF THE ACM, 39(11):27–34, 1996
work page 1996
-
[11]
Ahmed BaniMustafa. Enhancing learning from imbalanced classes via data preprocessing: A data-driven application in metabolomics data mining. The ISC International Journal of Information Security, 11:–, 2019
work page 2019
-
[12]
David S. Wishart. Metabolomics- applications to food science and nutrition research. Trends in Food Science and Technology, 19(9):482–493, 2008
work page 2008
-
[13]
Aurélie Roux, Dominique Lison, Christophe Junot, and Jean-François Heilier. Applications of liquid chromatog- raphy coupled to mass spectrometry-based metabolomics in clinical chemistry and toxicology - a review. Clinical Biochemistry, 44(1):119–135, 2010
work page 2010
- [14]
-
[15]
David S. Wishart. Applications of metabolomics in drug discovery and development. Drugs Discovery Plus International, 9:307–322, 2008. [1]
work page 2008
-
[16]
The Rational Unified Process: An Introduction
Philippe Kruchten. The Rational Unified Process: An Introduction. The Addison-Wesley object technology series. Addison-Wesley, 2004. COMPUTER-AIDED DATA MINING A PREPRINT
work page 2004
-
[17]
Ronald J. Brachman and Tej Anand. The process of knowledge discovery in databases: A first sketch. Technical report, AAAI, 1994
work page 1994
-
[18]
A Knowledge Discovery and Data Mining Process Model for Metabolomics
Ahmed BaniMustafa. A Knowledge Discovery and Data Mining Process Model for Metabolomics. PhD thesis, Computer Science Department, 2012
work page 2012
-
[19]
Ahmed BaniMustafa. Mekddam-saga: A software for automating and guiding a knowledge discovery and data mining process model for metabolomics. https://doi.org/10.5281/zenodo.3263394, June 2019
-
[20]
Ahmed BaniMustafa and Nigel Hardy. A Strategy for Selecting Data Mining Techniques in Metabolomics, volume 860 of Methods in Molecular Biology, chapter 18, pages 317–333. Springer Science, 2012
work page 2012
-
[21]
Applications of a novel data mining process model for metabolomics
Ahmed BaniMustafa and Nigel Hardy. Applications of a novel data mining process model for metabolomics. arXiv preprint, 2019
work page 2019
-
[22]
Lukasz A. Kurgan and Petr Musilek. A survey of knowledge discovery and data mining process models. Knowl. Eng. Rev., 21(1):1–24, 2006. COMPUTER-AIDED DATA MINING A PREPRINT 7 Appendix 7.1 Appendix: Snapshots of the Process Application This appendix provides some snapshots for MeKDDaM-SAGA software environment that was used for process realization and impl...
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.