Operationalizing Property-Based Testing for Data-Intensive Scalable Computing Systems
Pith reviewed 2026-06-27 12:11 UTC · model grok-4.3
The pith
DiscPBT operationalizes eight meta-properties to catch semantic drifts and corner cases in Spark that crash-based fuzzing misses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
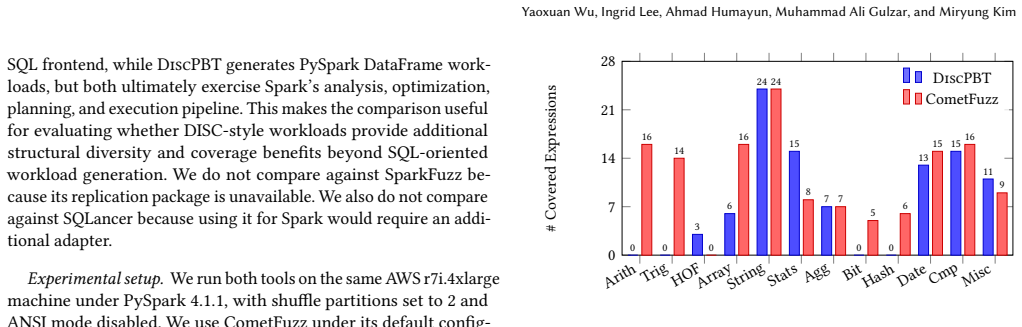
DiscPBT supplies eight reusable meta-properties for DISC semantic testing together with generators and an instantiation framework that realize each property in valid, schema-compatible Spark workloads; this yields 1.2 times higher branch coverage, 1153 times greater plan diversity, and detection of semantic drifts plus NaN and empty-input corner cases not reached by crash-based fuzzing alone.
What carries the argument
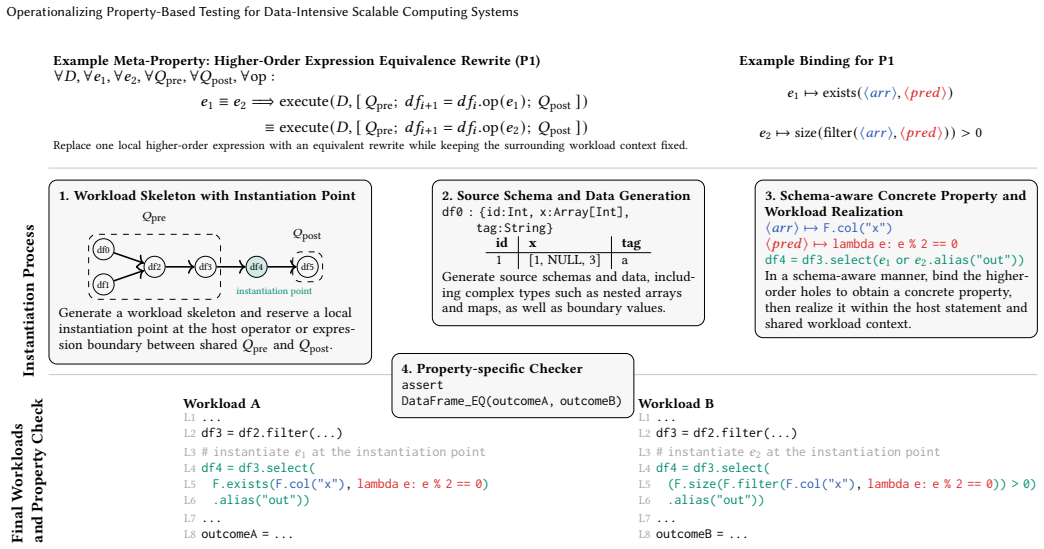
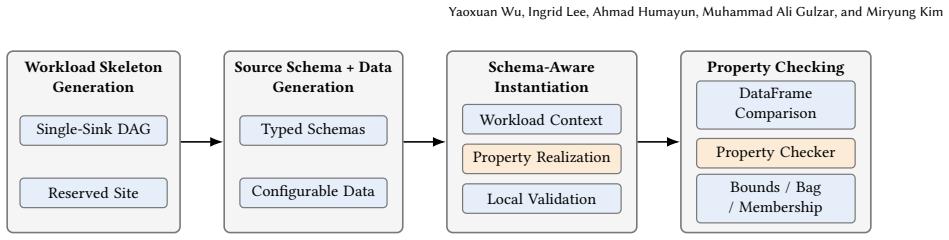
Eight meta-properties for equivalence rewriting, data decomposition, computation decomposition, and operator-local semantic relations, realized through reusable generators for workloads and data plus an instantiation framework that selects compatible operators, expressions, and UDFs.
If this is right
- Semantic invariants can be checked across many inputs and plans without writing expected outputs for each case.
- Cross-version drift becomes detectable by comparing results of equivalent rewritten workloads.
- Corner cases involving NaN values and empty collections can be systematically exercised rather than left to chance.
- Optimization-related errors become visible through plan diversity that exceeds what random fuzzing reaches.
- Property-based testing can be layered on top of existing crash oracles to improve semantic coverage in DISC systems.
Where Pith is reading between the lines
- The same meta-property structure could be ported to other DISC engines that expose similar operator sets and execution plans.
- Teams maintaining large Spark pipelines could embed these properties into continuous integration to guard against regression in UDF behavior.
- Plan diversity metrics might also serve as a proxy for testing performance-sensitive rewrites, not just correctness.
- Extending the generators to include user-defined data distributions could increase the chance of hitting rare but costly semantic failures in production data.
Load-bearing premise
The eight meta-properties together with the generators and instantiation framework can be realized through compatible operators, expressions, and UDFs in schema-compatible contexts to produce representative workloads that expose real semantic issues.
What would settle it
A controlled run on known Spark version pairs that contains a documented semantic drift yet none of the 66 instantiated properties flags any difference, or a workload where DiscPBT generates fewer distinct plans than CometFuzz.
Figures

read the original abstract
While fuzzing effectively catches crashes, its shallow oracles often miss semantic drifts and optimization-related errors in data-intensive scalable computing (DISC) frameworks. Property-based testing (PBT) addresses this limitation by checking general semantic invariants across diverse workloads and inputs, rather than relying on specific expected outputs. However, systematically operationalizing PBT for DISC systems remains difficult because it requires both reusable property definitions and effective instantiation into valid workloads and data. We present DiscPBT, a property-based testing engine for Apache Spark. DiscPBT introduces eight reusable meta-properties for DISC semantic testing, spanning equivalence rewriting, data decomposition, computation decomposition, and operator-local semantic relations. To operationalize these meta-properties, DiscPBT provides reusable generators for synthesizing valid workload skeletons and input data, together with an instantiation framework that realizes each meta-property in schema-compatible contexts through compatible operators, expressions, and UDFs. Our evaluation on PySpark shows that DiscPBT achieves 1.2$\times$ higher branch coverage and 1153$\times$ greater plan diversity than CometFuzz. Across 66 concrete properties, DiscPBT reveals cross-version semantic drift as well as subtle corner-case pitfalls involving NaN and empty inputs, that are not captured by crash-based fuzzing alone. These results demonstrate the value of systematic PBT for uncovering semantic issues in DISC frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DiscPBT, a property-based testing engine for Apache Spark. It defines eight reusable meta-properties for DISC semantic testing (covering equivalence rewriting, data decomposition, computation decomposition, and operator-local semantic relations), along with reusable generators for workload skeletons and input data and an instantiation framework that realizes the meta-properties via schema-compatible operators, expressions, and UDFs. Evaluation on PySpark reports 1.2× higher branch coverage and 1153× greater plan diversity than CometFuzz; across 66 concrete properties, it identifies cross-version semantic drift and corner-case pitfalls with NaN and empty inputs not captured by crash-based fuzzing.
Significance. If the evaluation methodology is strengthened, the work would be significant for moving DISC system testing beyond shallow crash oracles toward reusable semantic invariants. The eight meta-properties and associated generators provide a concrete operationalization of PBT that could improve detection of optimization errors and semantic drifts in frameworks such as Spark.
major comments (2)
- [Evaluation section] Evaluation section: The abstract and evaluation report quantitative gains (1.2× branch coverage, 1153× plan diversity) and findings from 66 properties, but supply no details on experimental methodology, statistical controls, derivation of the 66 properties, or validation that the generators avoid bias. This leaves the central claims of superiority over CometFuzz and discovery of semantic issues only partially supported.
- [Section on meta-properties and instantiation framework] Section on meta-properties and instantiation framework: The weakest assumption—that the eight meta-properties together with the generators and instantiation framework can be realized in schema-compatible contexts through compatible operators, expressions, and UDFs to produce representative workloads capable of exposing real semantic issues—is asserted but lacks sufficient concrete validation or additional case studies beyond the reported findings.
minor comments (1)
- [Evaluation section] Clarify the exact Spark/PySpark versions used for cross-version drift detection and list the specific meta-properties instantiated for each of the 66 concrete properties.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting opportunities to strengthen the evaluation methodology and the concrete validation of the meta-properties. We address each major comment below and will revise the manuscript to incorporate additional details and examples.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: The abstract and evaluation report quantitative gains (1.2× branch coverage, 1153× plan diversity) and findings from 66 properties, but supply no details on experimental methodology, statistical controls, derivation of the 66 properties, or validation that the generators avoid bias. This leaves the central claims of superiority over CometFuzz and discovery of semantic issues only partially supported.
Authors: We agree that the Evaluation section would benefit from expanded methodological details to better support the reported gains and findings. In the revised manuscript we will add: (1) the derivation process for the 66 concrete properties, obtained by systematically instantiating each of the eight meta-properties with combinations of Spark operators, expressions, and data types drawn from the API; (2) the experimental setup, including PySpark versions tested, hardware configuration, and measurement procedures (branch coverage via standard coverage tooling and plan diversity via enumeration of distinct logical plans); (3) the number of independent runs performed and any observed variance; and (4) the design rationale of the generators, which enforce schema compatibility and explicitly target edge cases such as empty collections and NaN values to reduce the risk of bias toward common inputs. These additions will make the comparison with CometFuzz and the semantic-issue discoveries more rigorously documented. revision: yes
-
Referee: [Section on meta-properties and instantiation framework] Section on meta-properties and instantiation framework: The weakest assumption—that the eight meta-properties together with the generators and instantiation framework can be realized in schema-compatible contexts through compatible operators, expressions, and UDFs to produce representative workloads capable of exposing real semantic issues—is asserted but lacks sufficient concrete validation or additional case studies beyond the reported findings.
Authors: The 66 instantiated properties and the semantic drifts and corner-case bugs they uncovered already constitute empirical evidence that the meta-properties can be realized and can expose real issues. We nevertheless accept that additional concrete illustrations would strengthen the presentation. In the revision we will include one or more detailed case studies (placed in the main text or an appendix) that walk through the full instantiation pipeline for at least two meta-properties, showing the generated workload skeleton, the schema-compatible operators/expressions/UDFs chosen, and the specific test cases that revealed the reported semantic problems. This will provide the requested concrete validation of the framework's ability to produce representative workloads. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central contribution is the definition of eight new meta-properties for DISC semantic testing plus generators and an instantiation framework; these are presented as novel operationalizations rather than derived quantities. No equations, fitted parameters, or 'predictions' appear that reduce to inputs by construction. All reported results (branch coverage, plan diversity, 66 concrete properties) are empirical comparisons against the external baseline CometFuzz. No self-citation is load-bearing for the core claims, and the meta-properties are not justified via prior author work. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Fuzzing's shallow oracles miss semantic drifts and optimization-related errors in DISC frameworks.
- domain assumption Reusable meta-properties plus generators can systematically instantiate valid semantic tests for Spark.
invented entities (2)
-
Eight reusable meta-properties for DISC semantic testing
no independent evidence
-
Reusable generators for workload skeletons and input data
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sqlsmith,
“Sqlsmith, ” 2022. [Online]. Available: https://github.com/anse1/sqlsmith
2022
-
[2]
Finding bugs in database systems via query partitioning,
M. Rigger and Z. Su, “Finding bugs in database systems via query partitioning, ” Proceedings of the ACM on Programming Languages, vol. 4, no. OOPSLA, pp. 1–30, 2020
2020
-
[3]
Detecting optimization bugs in database engines via non-optimizing ref- erence engine construction,
——, “Detecting optimization bugs in database engines via non-optimizing ref- erence engine construction, ” inProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2020, pp. 1140–1152
2020
-
[4]
Testing database engines via pivoted query synthesis,
——, “Testing database engines via pivoted query synthesis, ” in14th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2020, pp. 667–682. Yaoxuan Wu, Ingrid Lee, Ahmad Humayun, Muhammad Ali Gulzar, and Miryung Kim
2020
-
[5]
Finding cross-rule optimization bugs in datalog engines,
C. Zhang, L. Wang, and M. Rigger, “Finding cross-rule optimization bugs in datalog engines, ”Proceedings of the ACM on Programming Languages, vol. 8, no. OOPSLA1, pp. 110–136, 2024
2024
-
[6]
Sparkfuzz: searching correctness regressions in modern query engines,
B. Ghit, N. Poggi, J. Rosen, R. Xin, and P. Boncz, “Sparkfuzz: searching correctness regressions in modern query engines, ” inProceedings of the workshop on Testing Database Systems, 2020, pp. 1–6
2020
-
[7]
Achilles’ spear: Using metamorphic testing to find bugs in stream processing engines,
M. E. Kroner, “Achilles’ spear: Using metamorphic testing to find bugs in stream processing engines, ” inDatenbanksysteme für Business, Technologie und Web (BTW 2025). Gesellschaft für Informatik, Bonn, 2025, pp. 1031–1042
2025
-
[8]
Spark: Cluster computing with working sets,
M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica, “Spark: Cluster computing with working sets, ” in2nd USENIX workshop on hot topics in cloud computing (HotCloud 10), 2010
2010
-
[9]
SPARK-33726: Limit and offset ordering behaves differently between dataframe and sql,
“SPARK-33726: Limit and offset ordering behaves differently between dataframe and sql, ” https://issues.apache.org/jira/browse/SPARK-33726, accessed 2026-01- 28
2026
-
[10]
SPARK-49000: Aggregation distinct returning wrong results with literal value,
“SPARK-49000: Aggregation distinct returning wrong results with literal value, ” https://issues.apache.org/jira/browse/SPARK-49000, accessed 2026-01-28
2026
-
[11]
Quickcheck: a lightweight tool for random testing of haskell programs,
K. Claessen and J. Hughes, “Quickcheck: a lightweight tool for random testing of haskell programs, ” inProceedings of the fifth ACM SIGPLAN international conference on Functional programming, 2000, pp. 268–279
2000
-
[12]
Apache DataFusion Comet: Fuzz Testing,
Apache DataFusion Comet Developers, “Apache DataFusion Comet: Fuzz Testing, ” https://github.com/apache/datafusion-comet/tree/ 03e833b955d369f994d9652026ca3c1eb641acac/fuzz-testing
-
[13]
JaCoCo,
“JaCoCo, ” https://www.eclemma.org/jacoco/
-
[14]
Scalacheck: Property-based testing for scala,
“Scalacheck: Property-based testing for scala, ” https://scalacheck.org/
-
[15]
Fscheck: Random testing for .net
“Fscheck: Random testing for .net. ” [Online]. Available: https://fscheck.github.io/ FsCheck/
-
[16]
test.check: A property-based testing library for clojure
“test.check: A property-based testing library for clojure. ” [Online]. Available: https://clojure.org/guides/test_check_beginner
-
[17]
Hypothesis: Property-based testing for python
“Hypothesis: Property-based testing for python. ” [Online]. Available: https: //hypothesis.readthedocs.io/en/latest/
-
[18]
jqwik: Property-based testing in java
“jqwik: Property-based testing in java. ” [Online]. Available: https://jqwik.net/
-
[19]
hedgehog: Release with confidence
“hedgehog: Release with confidence. ” [Online]. Available: https://hackage. haskell.org/package/hedgehog
-
[20]
Quickcheck
“Quickcheck. ” [Online]. Available: https://www.quviq.com/documentation/eqc/ overview-summary.html
-
[21]
Quickstrom: property-based acceptance testing with ltl specifications,
L. O’Connor and O. Wickström, “Quickstrom: property-based acceptance testing with ltl specifications, ” inProceedings of the 43rd ACM SIGPLAN International Conference on Programming Language Design and Implementation, 2022, pp. 1025– 1038
2022
-
[22]
Experiences with quickcheck: testing the hard stuff and staying sane,
J. Hughes, “Experiences with quickcheck: testing the hard stuff and staying sane, ” inA List of Successes That Can Change the World: Essays Dedicated to Philip Wadler on the Occasion of His 60th Birthday. Springer, 2016, pp. 169–186
2016
-
[23]
Property-based testing in practice,
H. Goldstein, J. W. Cutler, D. Dickstein, B. C. Pierce, and A. Head, “Property-based testing in practice, ” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–13
2024
-
[24]
Bigfuzz: Efficient fuzz testing for data analytics using framework abstraction,
Q. Zhang, J. Wang, M. A. Gulzar, R. Padhye, and M. Kim, “Bigfuzz: Efficient fuzz testing for data analytics using framework abstraction, ” inProceedings of the 35th IEEE/ACM international conference on automated software engineering, 2020, pp. 722–733
2020
-
[25]
Co-dependence aware fuzzing for dataflow-based big data analytics,
A. Humayun, M. Kim, and M. A. Gulzar, “Co-dependence aware fuzzing for dataflow-based big data analytics, ” inProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2023
2023
-
[26]
White-box testing of big data analytics with complex user-defined functions,
M. A. Gulzar, S. Mardani, M. Musuvathi, and M. Kim, “White-box testing of big data analytics with complex user-defined functions, ” inProceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2019, pp. 290–301
2019
-
[27]
Naturalfuzz: Natural input generation for big data analytics,
A. Humayun, Y. Wu, M. Kim, and M. A. Gulzar, “Naturalfuzz: Natural input generation for big data analytics, ” in2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2023, pp. 1592–1603
2023
-
[28]
Natural symbolic execution- based testing for big data analytics,
Y. Wu, A. Humayun, M. A. Gulzar, and M. Kim, “Natural symbolic execution- based testing for big data analytics, ” inProceedings of the ACM International Conference on the Foundations of Software Engineering (FSE), 2024
2024
-
[29]
Property-based testing for spark streaming,
A. Riesco and J. Rodríguez-Hortalá, “Property-based testing for spark streaming, ” arXiv preprint arXiv:1812.11838, 2018
Pith/arXiv arXiv 2018
-
[30]
Flinkcheck: Property-based testing for apache flink,
C. V. Espinosa, E. Martin-Martin, A. Riesco, and J. Rodriguez-Hortala, “Flinkcheck: Property-based testing for apache flink, ”IEEE Access, vol. 7, pp. 150 369–150 382, 2019
2019
-
[31]
Diffstream: Differential output testing for stream processing programs,
K. Kallas, F. Niksic, C. Stanford, and R. Alur, “Diffstream: Differential output testing for stream processing programs, ”Proc. ACM Program. Lang., vol. 4, no. OOPSLA, 2020
2020
-
[32]
Sqlancer: Automatic testing of database systems,
“Sqlancer: Automatic testing of database systems, ” https://github.com/sqlancer/ sqlancer, accessed 2026-01-28
2026
-
[33]
Constant optimization driven database system testing,
C. Zhang and M. Rigger, “Constant optimization driven database system testing, ” Proceedings of the ACM on Management of Data, vol. 3, no. 1, pp. 1–24, 2025
2025
-
[34]
Finding logic bugs in graph-processing systems via graph-cutting,
Q. Mang, J. Ba, P. He, and M. Rigger, “Finding logic bugs in graph-processing systems via graph-cutting, ” inProceedings of the ACM on Management of Data (SIGMOD), 2025
2025
-
[35]
Y. Wu, I. Lee, A. Humayun, M. A. Gulzar, and M. Kim, “Replication Package for “Operationalizing Property-Based Testing for Data-Intensive Scalable Computing Systems”, ” 2026. [Online]. Available: https://doi.org/10.5281/zenodo.19248115
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.