Fora: From Weight-Space to Function-Space Protection in Capability-Preserving Fine-Tuning
Pith reviewed 2026-07-01 06:06 UTC · model grok-4.3
The pith
A capability is characterized more faithfully by the activation subspace it induces than by the singular geometry of the weight matrix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
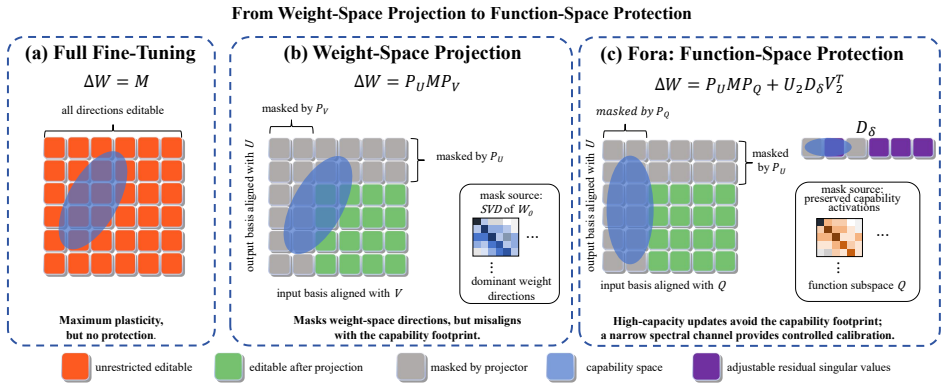
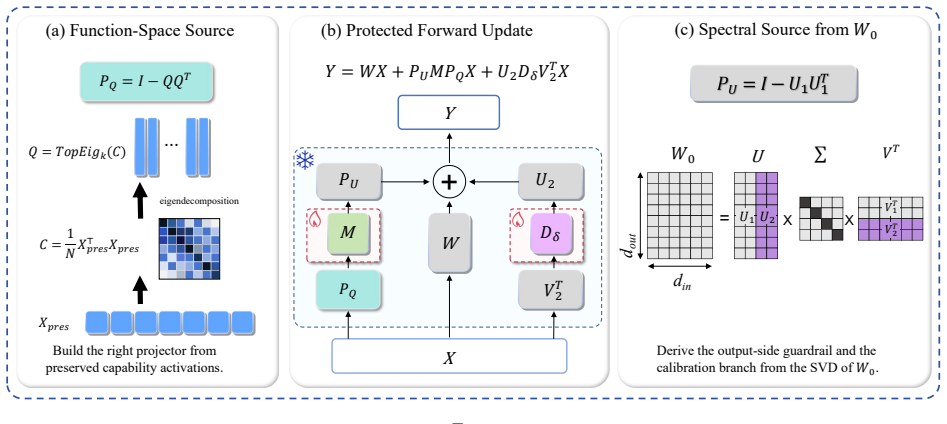
The paper argues that a capability is characterized more faithfully by the activation subspace it induces than by the singular geometry of the weight matrix, and develops function-space protection, instantiated as FORA. From label-free calibration inputs, FORA estimates, per layer, the principal directions Q of the input-activation covariance and forms a right projector P_Q = I - QQ^T. Paired with a left projector P_U from the weight SVD, the update is ΔW = P_U M P_Q + U_2 D_δ V_2^T: a high-capacity branch structurally barred from reading capability-relevant function directions, plus a narrow spectral channel for controlled plasticity. The construction extends to parameter-efficient adaptati
What carries the argument
FORA's dual projectors where the right projector P_Q = I - QQ^T is built from principal directions of input-activation covariance to structurally bar high-capacity updates from capability-relevant function directions, paired with a left projector from weight SVD and a narrow spectral term.
If this is right
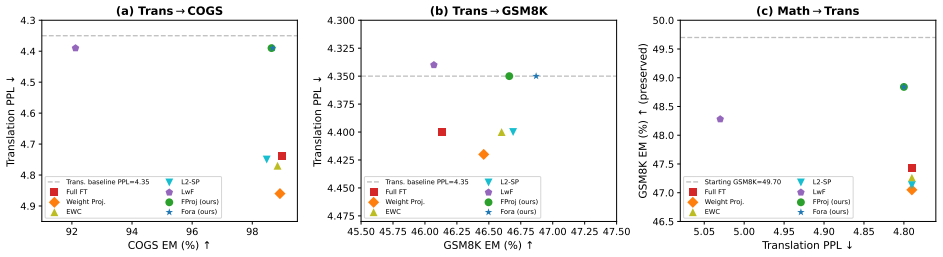
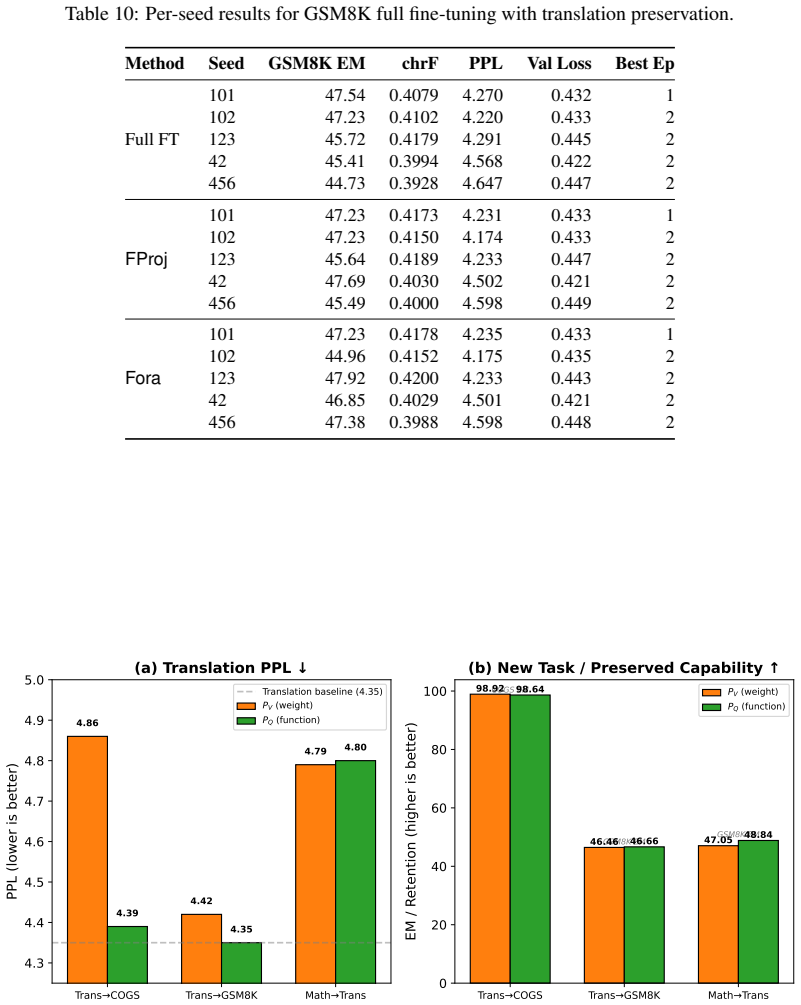
- FORA consistently improves preservation over weight-space projection and standard regularization across the tested settings.
- The advantage derives specifically from using capability-derived directions for the projection rather than weight-derived ones.
- The construction extends directly to parameter-efficient adaptation by replacing M with scaled low-rank factors.
- A small new-task trade-off appears only in the math-preservation setting.
Where Pith is reading between the lines
- The function-space approach could be tested on sequential task learning to check whether activation-based barriers reduce interference across more tasks.
- Calibration inputs might be selected or generated to target particular capabilities for stronger protection in new domains.
- Similar projectors based on observed activations rather than parameters could be explored in continual learning or multi-task settings.
Load-bearing premise
The principal directions Q of the input-activation covariance estimated from label-free calibration inputs per layer faithfully capture the capability-relevant function directions that must be protected.
What would settle it
An experiment where blocking the estimated activation directions fails to reduce capability erosion compared to unprojected updates, or where random directions achieve equivalent preservation.
Figures
read the original abstract
Full fine-tuning adapts large language models to new tasks but can erode capabilities they already possess. Existing remedies protect through proxies such as parameter distances, importance penalties, output matching, or dominant singular directions of the weights, but none directly asks which activation directions the preserved capability relies on. We argue that a capability is characterized more faithfully by the activation subspace it induces than by the singular geometry of the weight matrix, and develop function-space protection, instantiated as FORA (Function-space Orthogonal Residual Adaptation). From label-free calibration inputs, FORA estimates, per layer, the principal directions $Q$ of the input-activation covariance and forms a right projector $P_Q = I - QQ^T$. Paired with a left projector $P_U$ from the weight SVD, the update is $\Delta W = P_U M P_Q + U_2 D_{\delta} V_2^T$: a high-capacity branch structurally barred from reading capability-relevant function directions, plus a narrow spectral channel for controlled plasticity. The construction extends to parameter-efficient adaptation via $M \to (\alpha/r) BA$. Across three settings on Qwen3-1.7B, including COGS and GSM8K learned while preserving translation and translation learned while preserving math, FORA consistently improves preservation over weight-space projection and standard regularization, with only a small new-task trade-off in the math-preservation setting. A controlled ablation isolating the projection source shows that the advantage comes not from projection itself, but from projecting onto capability-derived rather than weight-derived directions. Code is available at https://github.com/zrui239/FORA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that capabilities in LLMs are more faithfully characterized by the activation subspaces they induce than by the singular geometry of weight matrices, and introduces FORA (Function-space Orthogonal Residual Adaptation) to protect these subspaces during fine-tuning. FORA estimates per-layer principal directions Q from the input-activation covariance on label-free calibration inputs, forms the right projector P_Q = I - QQ^T (paired with a left projector P_U from weight SVD), and constrains the update as ΔW = P_U M P_Q + U_2 D_δ V_2^T (extendable to LoRA-style). Experiments on Qwen3-1.7B across three settings (COGS/GSM8K while preserving translation; translation while preserving math) report consistent preservation gains over weight-space projection and regularization, with an ablation attributing the advantage to capability-derived rather than weight-derived directions.
Significance. If the central mapping from calibration statistics to capability subspaces holds, the shift from weight-space to function-space protection offers a more direct mechanism for capability preservation and could influence future regularization designs. The controlled ablation isolating projection source and the public code release are strengths that support reproducibility and allow direct testing of the function-space hypothesis.
major comments (2)
- The construction of P_Q (described in the abstract and FORA method) rests on the assumption that the top principal components of the input-activation covariance estimated from label-free calibration inputs coincide with the activation directions used by the preserved capability. No verification is provided that the calibration distribution excites those specific directions for translation or math, so the reported gains and the ablation's attribution to 'capability-derived' directions may reflect generic rather than targeted protection.
- Abstract and experimental claims of 'consistent improvement' and 'small new-task trade-off' lack quantitative deltas, error bars, or statistical testing details. This under-specification makes it impossible to evaluate whether the advantage over weight-space SVD projection is robust or load-bearing for the function-space claim.
minor comments (2)
- The abstract states the update formula but does not include an explicit equation number or derivation for the combined projectors P_U and P_Q; adding this would clarify the high-capacity branch versus narrow spectral channel.
- Notation for the SVD-derived components (U_2, D_δ, V_2) and the extension to (α/r)BA should be defined once in the main text rather than only in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify important gaps in validating the core assumption and in quantitative reporting. We respond point-by-point below.
read point-by-point responses
-
Referee: The construction of P_Q (described in the abstract and FORA method) rests on the assumption that the top principal components of the input-activation covariance estimated from label-free calibration inputs coincide with the activation directions used by the preserved capability. No verification is provided that the calibration distribution excites those specific directions for translation or math, so the reported gains and the ablation's attribution to 'capability-derived' directions may reflect generic rather than targeted protection.
Authors: We acknowledge that the manuscript provides no direct verification (e.g., via activation probing or ablation on capability-specific directions) that the top principal components from the chosen calibration inputs coincide with those used by the preserved capability. Calibration data are drawn from the domain of the preserved task, and the controlled ablation shows that these directions yield better preservation than weight-derived directions. Nevertheless, this leaves open the possibility that gains are partly generic. In revision we will add a dedicated discussion of the calibration choice together with any feasible supporting analysis of direction overlap. revision: partial
-
Referee: Abstract and experimental claims of 'consistent improvement' and 'small new-task trade-off' lack quantitative deltas, error bars, or statistical testing details. This under-specification makes it impossible to evaluate whether the advantage over weight-space SVD projection is robust or load-bearing for the function-space claim.
Authors: We agree that the abstract and experimental presentation would be strengthened by explicit numerical deltas, error bars, and statistical details. The full paper contains tables of results, but these elements are not summarized in the abstract or accompanied by run-to-run variability. In the revised manuscript we will update the abstract with key quantitative improvements and ensure all reported metrics include means and standard deviations across runs, together with any statistical tests performed. revision: yes
Circularity Check
No circularity; projectors derived directly from calibration statistics without reduction to fitted targets or self-reference.
full rationale
The derivation computes Q as the top principal components of the per-layer input-activation covariance on label-free calibration inputs, forms P_Q = I - QQ^T, and inserts it into the explicit update rule ΔW = P_U M P_Q + U_2 D_δ V_2^T. This is a structural construction, not a fit to the preserved capability. The ablation isolates the source of the projector (activation vs weight SVD) and shows differential performance, supplying independent empirical grounding. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the chain; the central claim remains a direct, non-reductive application of the estimated directions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Principal components of input-activation covariance capture capability-relevant directions
- standard math SVD of weights yields a useful left projector P_U
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.