Where Concept Erasure Should Occur: Concept-Layer Alignment in Text-to-Video Diffusion Models
Pith reviewed 2026-06-29 22:34 UTC · model grok-4.3
The pith
Aligning concept erasure to depths where target concepts separate most cleanly from other signals produces more precise suppression in text-to-video diffusion models while keeping generation quality intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
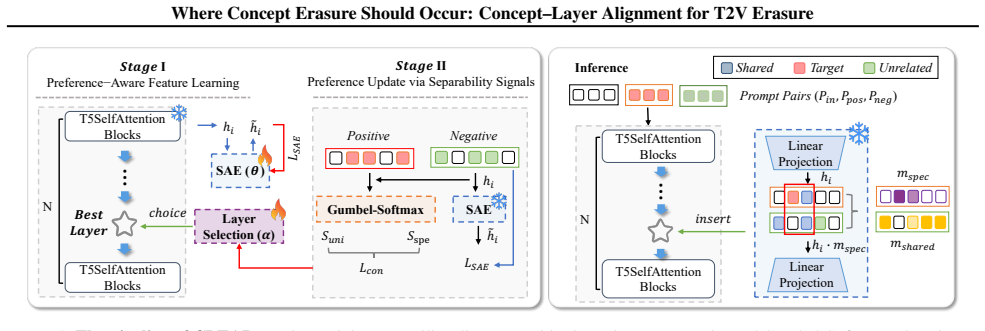
Text-to-video diffusion transformers encode semantic information unevenly across model depth, which creates a representational bottleneck termed concept-layer topological alignment. Under this bottleneck, target concepts exhibit higher separability at certain depths while remaining strongly entangled with non-target signals elsewhere. CLEAR reframes concept erasure as the task of locating and using those depths, operationalized by a separability-aware objective that selects layers through optimization rather than fixed or heuristic rules. Experiments confirm that enforcing this alignment yields more precise concept suppression while preserving generative quality.
What carries the argument
concept-layer topological alignment: the depth-dependent separability bottleneck in which target concepts naturally disentangle from non-target signals at specific representational layers, used to guide layer selection in the CLEAR optimization framework.
If this is right
- Erasure methods that ignore depth-specific separability will remain limited by entanglement outside the aligned layers.
- Layer selection formulated as separability optimization replaces heuristic or layer-agnostic choices.
- Precise suppression of target concepts becomes feasible while overall video generation quality is maintained.
- The same structural constraint applies across large-scale text-to-video diffusion transformers.
Where Pith is reading between the lines
- The same separability-driven layer selection could be tested on image-only diffusion models to check whether the alignment phenomenon is specific to the temporal components of video generation.
- If separability peaks shift with model scale or training data, the optimization in CLEAR would need to be rerun per model rather than transferred.
- The approach suggests that future editing techniques might benefit from mapping multiple concepts simultaneously to find shared or conflicting alignment depths.
Load-bearing premise
Target concepts reliably show higher separability from non-target content at particular model depths, and selecting layers by that separability metric will improve erasure without creating new entanglements or quality loss.
What would settle it
A controlled comparison in which layers chosen by the separability metric produce no measurable improvement in concept suppression or introduce greater quality degradation than layers chosen uniformly at random.
Figures







read the original abstract
Text-to-video diffusion transformers encode semantic information unevenly across model depth, which constrains effective concept erasure. We identify a representational bottleneck, termed concept-layer topological alignment, under which target concepts exhibit higher separability at certain representational depths. Outside these depths, concept and non-target signals remain strongly entangled, limiting the effectiveness of depth-specific erasure. This observation reframes concept erasure as the problem of identifying representational depths where concept-non-target separation naturally emerges. Motivated by this structural constraint, we introduce CLEAR, a separability-driven optimization framework for concept erasure that explicitly enforces concept-layer alignment. CLEAR operationalizes this principle by formulating layer selection as an optimization problem over concept-non-target separability, rather than relying on layer-agnostic or heuristic choices. To enable this, we introduce a separability-aware objective that favors layers exhibiting stronger concept-non-target separation. Experiments on large-scale text-to-video diffusion models demonstrate that enforcing concept--layer alignment leads to more precise concept suppression while preserving overall generative quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies uneven encoding of semantic information across depths in text-to-video diffusion transformers, positing a 'concept-layer topological alignment' bottleneck where target concepts show higher separability at certain representational depths. It introduces CLEAR, a separability-driven optimization framework that formulates layer selection as an optimization over concept-non-target separability (rather than heuristics) and claims that enforcing this alignment yields more precise concept suppression while preserving generative quality, supported by experiments on large-scale models.
Significance. If the experimental outcomes hold under scrutiny, the work could meaningfully advance concept erasure methods by replacing ad-hoc layer choices with an optimization grounded in measured separability, offering a structural reframing that may generalize to other generative architectures. The separability-aware objective and explicit layer-alignment principle constitute a potentially useful contribution if the metric is well-defined and the gains are shown to be robust.
minor comments (2)
- The abstract introduces the term 'concept-layer topological alignment' and a 'separability-aware objective' without providing definitions, measurement procedures, or pseudocode; these details are essential for evaluating whether the optimization is well-posed or circular.
- No quantitative results, baselines, metrics (e.g., suppression success rate, FID, CLIP scores), or controls for quality preservation are described, preventing assessment of whether the claimed improvements are statistically meaningful or confounded by other factors.
Simulated Author's Rebuttal
We thank the referee for their summary of our work on identifying the concept-layer topological alignment bottleneck in text-to-video diffusion models and introducing the CLEAR framework. The summary accurately reflects the manuscript's contributions. No specific major comments were provided in the report, so we have no point-by-point responses. We remain available to address any additional questions or provide further experimental details to resolve the uncertainty in the recommendation.
Circularity Check
No significant circularity identified
full rationale
The provided abstract and context contain no equations, derivations, fitted parameters, or self-citations that could be inspected for reduction to inputs by construction. The description of concept-layer topological alignment and the CLEAR framework is presented as an observation motivating an optimization, with claims resting on experimental results rather than any self-definitional or fitted-input structure. Per the rules, when no load-bearing step can be quoted and exhibited as circular, the score is 0 and steps remain empty. This matches the reader's note that abstract-only material precludes circularity assessment.
Axiom & Free-Parameter Ledger
invented entities (1)
-
concept-layer topological alignment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SAEmnesia: Erasing Concepts in Diffusion Models with Supervised Sparse Autoencoders
Cassano, E., Renzulli, R., Nurisso, M., Zaffaroni, M., Per- otti, A., and Grangetto, M. Saemnesia: Erasing concepts in diffusion models with supervised sparse autoencoders. arXiv preprint arXiv:2509.21379,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
He, Q., Weng, J., Tao, J., and Xue, H. A single neuron works: Precise concept erasure in text-to-image diffusion models.arXiv preprint arXiv:2509.21008, 2025a. He, Z., Jin, M., Shen, B., Payani, A., Zhang, Y ., and Du, M. SAE-SSV: Supervised steering in sparse representa- tion spaces for reliable control of language models. In EMNLP, 2025b. He, Z., Xiong,...
-
[3]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al. Hunyuan- video: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Liu, P. and Zhang, C. Erased or dormant? rethinking concept erasure through reversibility.arXiv preprint arXiv:2505.16174,
-
[5]
Liu, S. and Tan, Y . Unlearning concepts from text-to- video diffusion models.arXiv preprint arXiv:2407.14209,
-
[6]
V ., Borkakoty, H., and Hou, Y
10 Where Concept Erasure Should Occur: Concept–Layer Alignment for T2V Erasure Pham, M. V ., Borkakoty, H., and Hou, Y . Where knowl- edge collides: A mechanistic study of intra-memory knowledge conflict in language models.arXiv preprint arXiv:2601.09445,
-
[7]
Tian, Z., Nan, S., Xu, M., Zhai, S., Qu, W., Liu, J., Ren, K., Jia, R., and Zhang, J. Sparse autoencoder as a zero-shot classifier for concept erasing in text-to-image diffusion models.arXiv preprint arXiv:2503.09446,
-
[8]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W....
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Ye, X., Cheng, S., Wang, Y ., Xiong, Y ., and Li, Y . T2vunlearning: A concept erasing method for text-to- video diffusion models.arXiv preprint arXiv:2505.17550,
-
[10]
To ensure robust generalization across diverse semantic contexts, we construct a comprehensive training dataset using prompts synthesized by a Large Language Model (LLM)
Our unified SAE is configured with a hidden dimension of 131,072 , utilizing a standard ℓ1 penalty to induce sparsity. To ensure robust generalization across diverse semantic contexts, we construct a comprehensive training dataset using prompts synthesized by a Large Language Model (LLM). Each pair shares identical semantics, differing only by the target ...
2013
-
[11]
In contrast, inference-time baselines often retain recognizable identity cues, whereas parameter-update methods may introduce noticeable visual distortion or semantic drift
Compared with existing baselines, CLEAR more effectively suppresses identity-specific facial characteristics while preserving scene composition, pose, and overall visual realism. In contrast, inference-time baselines often retain recognizable identity cues, whereas parameter-update methods may introduce noticeable visual distortion or semantic drift. 16 W...
1992
-
[12]
Multi-concept Erasure Experiments Table 15 demonstrates CLEAR’s robustness in multi-concept settings
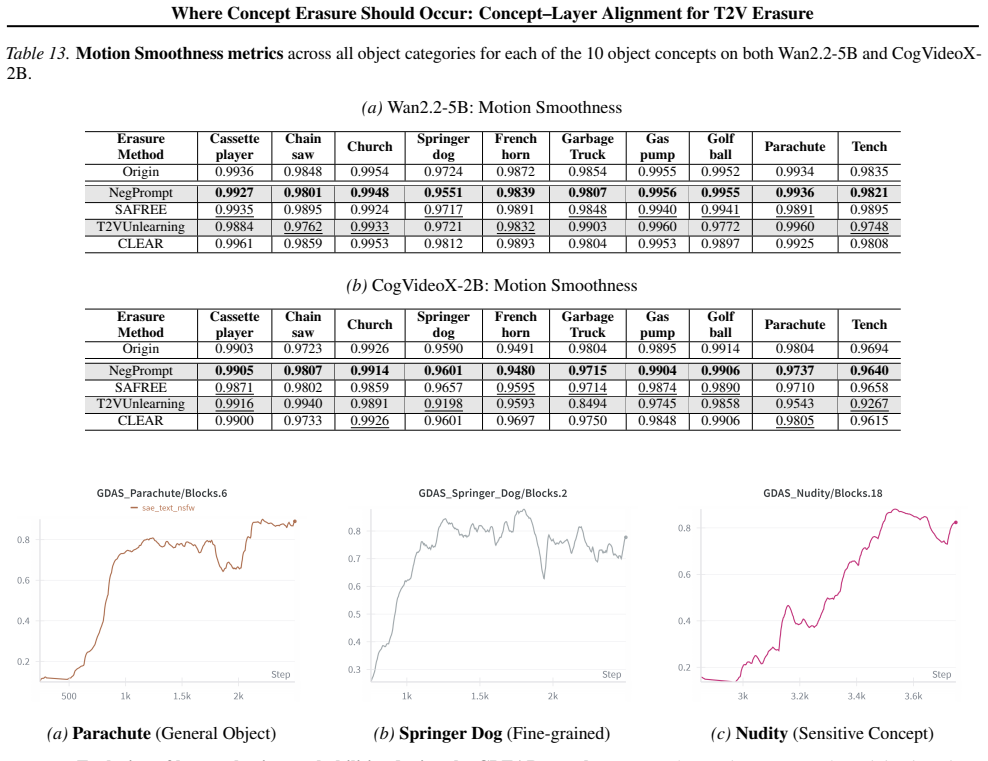
J. Multi-concept Erasure Experiments Table 15 demonstrates CLEAR’s robustness in multi-concept settings. In intra-category tasks (e.g., erasing Van Gogh and Picasso simultaneously), baselines like T2VUnlearning suffer from severe catastrophic forgetting, indiscriminately degrading un-targeted related concepts (e.g., Rembrandt’s VCLIP score plunges to 0.02...
1945
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.