Seeing Through the Weights: Privacy Leakage in Scene Coordinate Regression
Pith reviewed 2026-07-01 06:30 UTC · model grok-4.3
The pith
Scene coordinate regression models leak the 3D geometry and appearance of their training scenes through a query-based attack using unrelated proxy images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
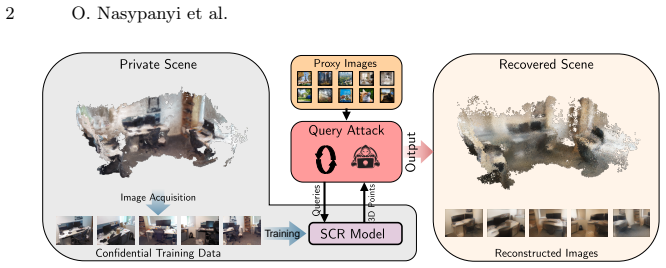
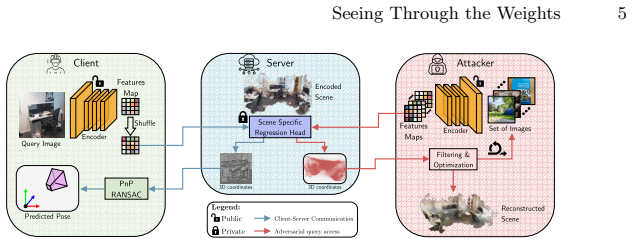
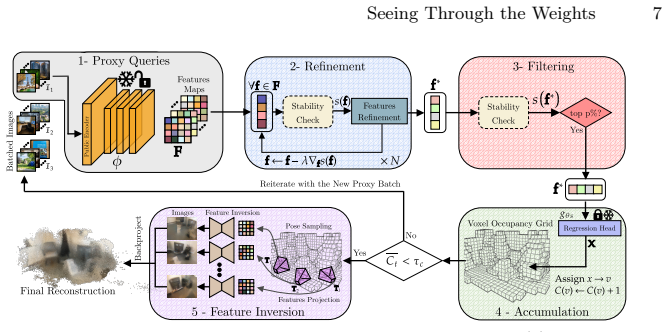
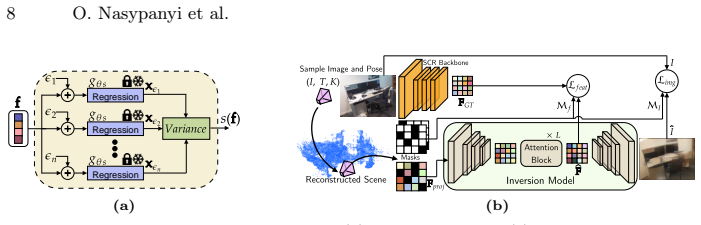
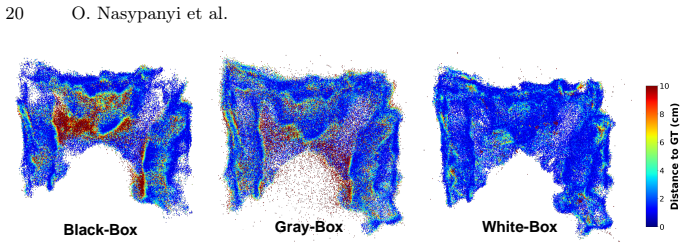
The paper claims that a query-based attack reconstructs substantial portions of an SCR model's training environment by sending batches of proxy images unrelated to the target scene, selecting reliable 3D coordinate predictions based on stability under input perturbations, accumulating these points across independent batches, and refining them in white-box settings to recover geometry; the same process further enables inversion of network features to synthesize recognizable scene appearance from arbitrary viewpoints.
What carries the argument
The query-based attack that selects stable 3D coordinate predictions from unrelated proxy images under small perturbations and accumulates them across batches to recover scene geometry.
If this is right
- Substantial portions of indoor and outdoor training scenes can be recovered with high geometric fidelity from the model alone.
- Approximate color appearance of the scene can be synthesized from arbitrary viewpoints using the recovered representation.
- Recognizable layout details and potentially sensitive scene elements become exposed through the attack.
- SCR systems cannot be considered privacy-preserving by design when used in private or security-critical environments.
Where Pith is reading between the lines
- Other implicit neural representations of 3D scenes may carry similar extractable information about their training data.
- Adding controlled noise to coordinate outputs or limiting query access could reduce leakage without full retraining.
- The attack suggests that any regression-based encoding of spatial data may retain recoverable structure unless explicitly regularized against it.
Load-bearing premise
Stable coordinate predictions obtained from unrelated proxy images correspond to actual points in the training scene and accumulate reliably into accurate geometry.
What would settle it
If querying an SCR model with batches of unrelated proxy images produces no stable points that accumulate into a 3D structure matching the actual training scene geometry, the leakage result would not hold.
Figures







read the original abstract
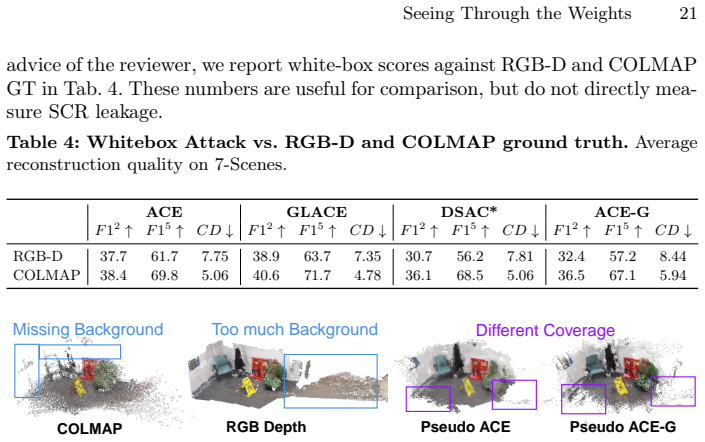
Scene Coordinate Regression (SCR) methods are increasingly adopted for visual localization. In these approaches, the scene is implicitly encoded within a neural network that regresses a 3D world coordinate for each image pixel. Because the scene is represented only through the network parameters and not stored explicitly as images or maps, such methods are often assumed to be privacy-preserving. In this work, we show that this assumption is incorrect in practice. Specifically, we introduce a query-based attack that reconstructs the 3D geometry of the training environment from an SCR model under different levels of model access. To do so, we repeatedly query the model with batches of proxy images unrelated to the target scene to obtain dense pixel-wise 3D coordinates. Reliable points are identified through their stability under small input perturbations and can be further refined in a white-box setting. These stable points are accumulated across independent query batches to recover the scene geometry. From the recovered 3D representation, we also invert the network features to synthesize images from arbitrary viewpoints, revealing additional appearance information. Experiments on indoor and outdoor datasets demonstrate that substantial portions of training environments can be reconstructed with high geometric fidelity. Beyond geometry, we also recover an approximate color appearance, which exposes recognizable layout and potentially sensitive scene elements. This directly contradicts claims in the literature that SCR representations are privacy-preserving by design, and reveals a real risk when such systems are deployed in private or security-critical spaces. The project page is available at https://jaeminch0.github.io/seeing-through-the-weights-privacy-leakage-in-scene-coordinate-regression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Scene Coordinate Regression (SCR) models, which regress 3D coordinates per pixel and implicitly encode scenes in network weights, are not privacy-preserving. It introduces a query-based attack that repeatedly queries the model with batches of unrelated proxy images, identifies reliable 3D points via stability under small input perturbations, accumulates these points across batches to reconstruct scene geometry, and optionally inverts features to synthesize appearance from novel viewpoints. Experiments on indoor and outdoor datasets are reported to recover substantial portions of the training scenes with high geometric fidelity, directly contradicting prior literature assumptions that SCR representations are privacy-preserving by design.
Significance. If the reported reconstructions hold with the claimed fidelity and generalize beyond the tested models, the work is significant because it provides the first concrete empirical demonstration of privacy leakage in SCR systems used for visual localization. The attack is falsifiable via perturbation stability and accumulation, and the project page aids reproducibility. This challenges an assumption in the visual localization literature and identifies deployment risks in private or security-critical settings.
major comments (2)
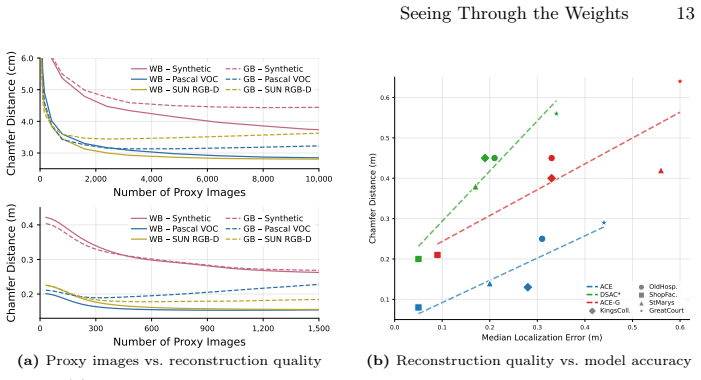
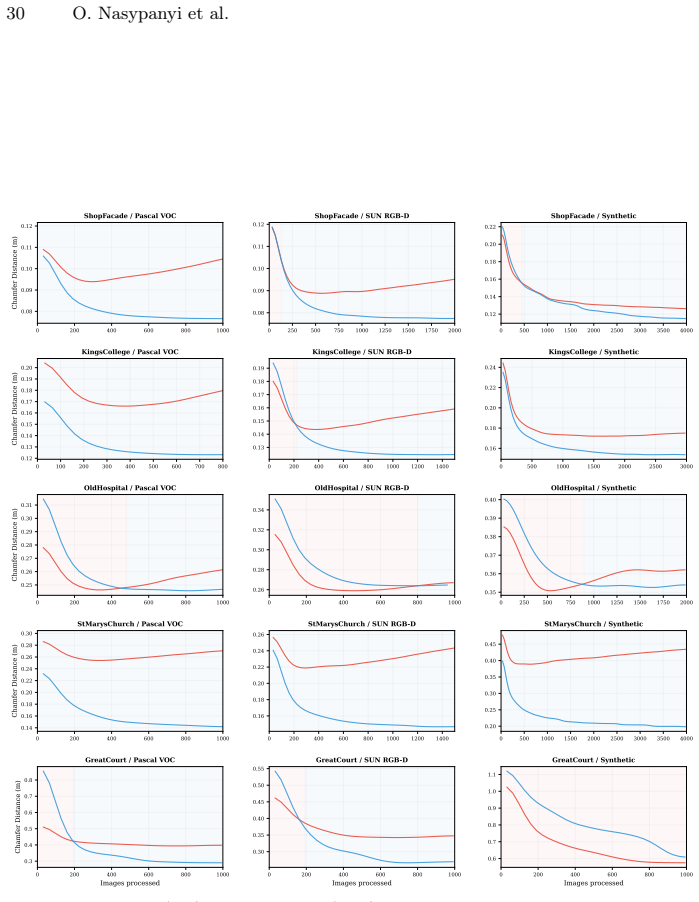
- [Abstract] Abstract: the claim that experiments 'demonstrate that substantial portions of training environments can be reconstructed with high geometric fidelity' is load-bearing for the central empirical claim but is unsupported by any quantitative metrics (e.g., point-cloud coverage, Chamfer distance, or IoU), baselines, or controls; this prevents verification that the attack exceeds chance-level accumulation of stable predictions.
- [Attack method] Attack method description: the assumption that points stable under perturbations on unrelated proxy images correspond to actual training-scene geometry (rather than spurious stable outputs) is central to the accumulation step, yet the manuscript provides no explicit verification such as overlap statistics against ground-truth 3D models or cross-batch consistency checks with known scene elements.
minor comments (2)
- [Introduction] Introduction: the statement that SCR methods are 'often assumed to be privacy-preserving' should include specific citations to prior works making that claim to ground the motivation.
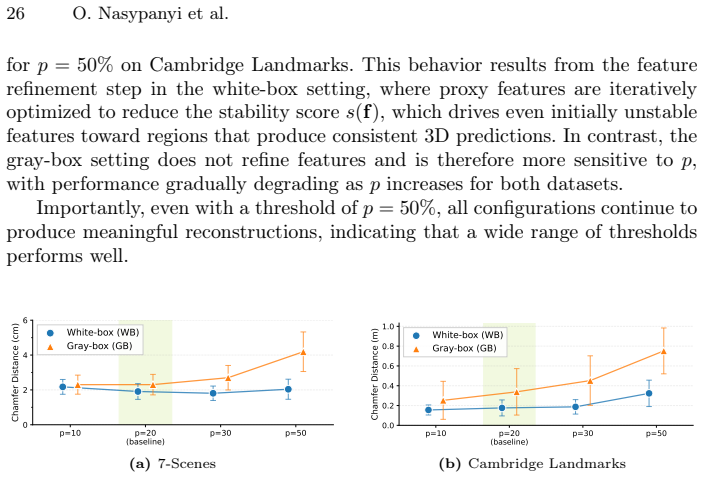
- [Experiments] Figure captions and experimental results: ensure all reported reconstructions include error bars or variance across multiple runs and models to clarify robustness.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comments. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our empirical results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that experiments 'demonstrate that substantial portions of training environments can be reconstructed with high geometric fidelity' is load-bearing for the central empirical claim but is unsupported by any quantitative metrics (e.g., point-cloud coverage, Chamfer distance, or IoU), baselines, or controls; this prevents verification that the attack exceeds chance-level accumulation of stable predictions.
Authors: We agree that the abstract claim would benefit from explicit quantitative support. In the revised version we will augment the abstract (and corresponding results section) with quantitative metrics including point-cloud coverage percentages relative to ground-truth scene models, Chamfer distances where available, and a random-accumulation baseline to demonstrate that the stable-point accumulation exceeds chance-level predictions. revision: yes
-
Referee: [Attack method] Attack method description: the assumption that points stable under perturbations on unrelated proxy images correspond to actual training-scene geometry (rather than spurious stable outputs) is central to the accumulation step, yet the manuscript provides no explicit verification such as overlap statistics against ground-truth 3D models or cross-batch consistency checks with known scene elements.
Authors: We acknowledge that additional explicit verification would improve clarity. In the revision we will include overlap statistics computed against available ground-truth 3D models on the evaluated datasets as well as cross-batch consistency metrics (e.g., fraction of points recovered in multiple independent query batches) to directly support that the stable points align with training-scene geometry rather than spurious outputs. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is an empirical demonstration of a query-based attack that extracts stable 3D points from an SCR model via perturbation stability and accumulates them into a scene reconstruction. No derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps are present. The central claim is supported by experimental results on indoor/outdoor datasets rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Arandjelovic, R., Gronat, P., Torii, A., Pajdla, T., Sivic, J.: Netvlad: Cnn ar- chitecture for weakly supervised place recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5297–5307 (2016)
2016
-
[2]
In: International confer- ence on machine learning
Athalye, A., Carlini, N., Wagner, D.: Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In: International confer- ence on machine learning. pp. 274–283. PMLR (2018)
2018
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Brachmann, E., Cavallari, T., Prisacariu, V.A.: Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5044– 5053 (2023) 16 O. Nasypanyi et al
2023
-
[4]
In: CVPR (2017)
Brachmann, E., Krull, A., Nowozin, S., Shotton, J., Michel, F., Gumhold, S., Rother, C.: Dsac-differentiable ransac for camera localization. In: CVPR (2017)
2017
-
[5]
In: European Conference on Com- puter Vision
Brachmann, E., Wynn, J., Chen, S., Cavallari, T., Monszpart, A., Turmukhambe- tov, D., Prisacariu, V.A.: Scene coordinate reconstruction: Posing of image collec- tions via incremental learning of a relocalizer. In: European Conference on Com- puter Vision. pp. 421–440. Springer (2024)
2024
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Bruns, L., Barroso-Laguna, A., Cavallari, T., Monszpart, A., Munukutla, S., Prisacariu, V.A., Brachmann, E.: Ace-g: Improving generalization of scene coor- dinate regression through query pre-training. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 26751–26761 (2025)
2025
-
[7]
In: 2017 ieee symposium on security and privacy (sp)
Carlini, N., Wagner, D.: Towards evaluating the robustness of neural networks. In: 2017 ieee symposium on security and privacy (sp). pp. 39–57. IEEE (2017)
2017
-
[8]
Chalmers Tekniska Hogskola (Sweden) (2025)
Chelani, K.: Privacy in Visual Localization. Chalmers Tekniska Hogskola (Sweden) (2025)
2025
-
[9]
In: 2025 International Conference on 3D Vision (3DV)
Chelani, K., Benbihi, A., Kahl, F., Sattler, T., Kukelova, Z.: Obfuscation based privacy preserving representations are recoverable using neighborhood information. In: 2025 International Conference on 3D Vision (3DV). pp. 189–199. IEEE (2025)
2025
-
[10]
In: CVPR (2021)
Chelani, K., Kahl, F., Sattler, T.: How privacy-preserving are line clouds? recov- ering scene details from 3d lines. In: CVPR (2021)
2021
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chelani, K., Sattler, T., Kahl, F., Kukelova, Z.: Privacy-preserving representations are not enough: Recovering scene content from camera poses. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13132–13141. IEEE (2023)
2023
-
[12]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Clark, R., Wang, S., Markham, A., Trigoni, N., Wen, H.: Vidloc: A deep spatio- temporal model for 6-dof video-clip relocalization. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6856–6864 (2017)
2017
-
[13]
In: Proceedings of the AAAI conference on artificial intelligence (2017)
Clark, R., Wang, S., Wen, H., Markham, A., Trigoni, N.: Vinet: Visual-inertial odometry as a sequence-to-sequence learning problem. In: Proceedings of the AAAI conference on artificial intelligence (2017)
2017
-
[14]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Dai,A.,Chang,A.X.,Savva,M.,Halber,M.,Funkhouser,T.,Nießner,M.:Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5828–5839 (2017)
2017
-
[15]
In: Proceedings of the IEEE conference on com- puter vision and pattern recognition workshops
DeTone, D., Malisiewicz, T., Rabinovich, A.: Superpoint: Self-supervised interest point detection and description. In: Proceedings of the IEEE conference on com- puter vision and pattern recognition workshops. pp. 224–236 (2018)
2018
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2022)
Do, T., Miksik, O., DeGol, J., Park, H.S., Sinha, S.N.: Learning to detect scene landmarks for camera localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2022)
2022
-
[17]
In: CVPR (2016)
Dosovitskiy, A., Brox, T.: Inverting visual representations with convolutional net- works. In: CVPR (2016)
2016
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Dusmanu, M., Schonberger, J.L., Sinha, S.N., Pollefeys, M.: Privacy-preserving image features via adversarial affine subspace embeddings. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14267– 14277 (2021)
2021
-
[19]
International Journal of Computer Vision88(2), 303–338 (2010)
Everingham, M., Van Gool, L., Williams, C.K.I., Winn, J., Zisserman, A.: The pascal visual object classes (voc) challenge. International Journal of Computer Vision88(2), 303–338 (2010)
2010
-
[20]
In: ECCV (2020) Seeing Through the Weights 17
Geppert, M., Larsson, V., Speciale, P., Schönberger, J.L., Pollefeys, M.: Privacy preserving structure-from-motion. In: ECCV (2020) Seeing Through the Weights 17
2020
-
[21]
In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition
Izquierdo, S., Civera, J.: Optimal transport aggregation for visual place recogni- tion. In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition. pp. 17658–17668 (2024)
2024
-
[22]
Robotics and Automation Letters9(5), 4710–4717 (2024)
Jeong,H.,Shin,J.,Rameau,F.,Kum,D.:Multi-modalplacerecognitionviavector- ized hd maps and images fusion for autonomous driving. Robotics and Automation Letters9(5), 4710–4717 (2024)
2024
-
[23]
In: Proceedings of the IEEE international con- ference on computer vision
Kendall, A., Grimes, M., Cipolla, R.: Posenet: A convolutional network for real- time 6-dof camera relocalization. In: Proceedings of the IEEE international con- ference on computer vision. pp. 2938–2946 (2015)
2015
-
[24]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[25]
In: Proceedings of the IEEE International Confer- ence on Computer Vision
Larsson, V., Kukelova, Z., Zheng, Y.: Making minimal solvers for absolute pose estimation compact and robust. In: Proceedings of the IEEE International Confer- ence on Computer Vision. pp. 2316–2324 (2017)
2017
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lee, C., Kim, J., Yun, C., Hong, J.H.: Paired-point lifting for enhanced privacy- preserving visual localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17266–17275 (2023)
2023
-
[27]
In: CVPR (2021)
Lee, D., Ryu, S., Yeon, S., Lee, Y., Kim, D., Han, C., Cabon, Y., Weinzaepfel, P., Guérin, N., Csurka, G., et al.: Large-scale localization datasets in crowded indoor spaces. In: CVPR (2021)
2021
-
[28]
Interna- tional journal of computer vision60(2), 91–110 (2004)
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. Interna- tional journal of computer vision60(2), 91–110 (2004)
2004
-
[29]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Mahendran, A., Vedaldi, A.: Understanding deep image representations by invert- ing them. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5188–5196 (June 2015)
2015
-
[30]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Moon, H., Lee, C., Hong, J.H.: Efficient privacy-preserving visual localization using 3d ray clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9773–9783 (2024)
2024
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ng, T., Kim, H.J., Lee, V.T., DeTone, D., Yang, T.Y., Shen, T., Ilg, E., Balntas, V., Mikolajczyk, K., Sweeney, C.: Ninjadesc: content-concealing visual descriptors via adversarial learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12797–12807 (2022)
2022
-
[33]
Sensitivity and Generalization in Neural Networks: an Empirical Study
Novak, R., Bahri, Y., Abolafia, D.A., Pennington, J., Sohl-Dickstein, J.: Sensi- tivity and generalization in neural networks: an empirical study. arXiv preprint arXiv:1802.08760 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Pan, L., Schönberger, J.L., Larsson, V., Pollefeys, M.: Privacy preserving localiza- tion via coordinate permutations. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 18174–18183 (2023)
2023
-
[35]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR)
Pietrantoni, M., Csurka, G., Sattler, T.: Gaussian splatting feature fields for (privacy-preserving) visual localization. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 1082–1092 (June 2025)
2025
-
[36]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Pietrantoni, M., Humenberger, M., Sattler, T., Csurka, G.: Segloc: Learning segmentation-based representations for privacy-preserving visual localization. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 15380–15391 (2023)
2023
-
[37]
Pietrantoni,M.,Humenberger,M.,Sattler,T.,Csurka,G.:Canwemakenerf-based visual localization privacy-preserving? arXiv preprint arXiv:2508.18971 (2025) 18 O. Nasypanyi et al
-
[38]
In: CVPR (2019)
Pittaluga, F., Koppal, S.J., Kang, S.B., Sinha, S.N.: Revealing scenes by inverting structure from motion reconstructions. In: CVPR (2019)
2019
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Pittaluga, F., Zhuang, B.: Ldp-feat: Image features with local differential privacy. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17580–17590 (2023)
2023
-
[40]
In: ECCV (2022)
Sarlin, P.E., Dusmanu, M., Schönberger, J.L., Speciale, P., Gruber, L., Larsson, V., Miksik, O., Pollefeys, M.: Lamar: Benchmarking localization and mapping for augmented reality. In: ECCV (2022)
2022
-
[41]
In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition
Shotton, J., Glocker, B., Zach, C., Izadi, S., Criminisi, A., Fitzgibbon, A.: Scene coordinate regression forests for camera relocalization in rgb-d images. In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition. pp. 2930–2937 (2013)
2013
-
[42]
In: MICCAI (2023)
Shrestha, P., Xie, C., Shishido, H., Yoshii, Y., Kitahara, I.: X-ray to ct rigid reg- istration using scene coordinate regression. In: MICCAI (2023)
2023
-
[43]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Song,S.,Lichtenberg,S.P.,Xiao,J.:Sunrgb-d:Argb-dsceneunderstandingbench- mark suite. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 567–576 (2015)
2015
-
[44]
Computer Vision and Image Understanding259, 104440 (2025)
Song, X., Tang, J., Yang, K., Guo, W., Lu, X., Hei, X.: A method for absolute pose regression based on cascaded attention modules. Computer Vision and Image Understanding259, 104440 (2025)
2025
-
[45]
In: CVPR (2019)
Speciale, P., Schonberger, J.L., Kang, S.B., Sinha, S.N., Pollefeys, M.: Privacy preserving image-based localization. In: CVPR (2019)
2019
-
[46]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Speciale, P., Schonberger, J.L., Sinha, S.N., Pollefeys, M.: Privacy preserving image queries for camera localization. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1486–1496 (2019)
2019
-
[47]
In: 25th USENIX security symposium (USENIX Security 16)
Tramèr, F., Zhang, F., Juels, A., Reiter, M.K., Ristenpart, T.: Stealing machine learning models via prediction{APIs}. In: 25th USENIX security symposium (USENIX Security 16). pp. 601–618 (2016)
2016
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, F., Jiang, X., Galliani, S., Vogel, C., Pollefeys, M.: Glace: Global local accelerated coordinate encoding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21562–21571 (2024)
2024
-
[49]
IEEE Robotics and Automation Letters6(2), 699–706 (2020)
Zhou, L., Koppel, D., Kaess, M.: A complete, accurate and efficient solution for the perspective-n-line problem. IEEE Robotics and Automation Letters6(2), 699–706 (2020)
2020
-
[50]
Zhou, Q., Agostinho, S., Ošep, A., Leal-Taixé, L.: Is geometry enough for matching in visual localization? In: European Conference on Computer Vision. pp. 407–425. Springer (2022)
2022
-
[51]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhu, S., Yang, L., Chen, C., Shah, M., Shen, X., Wang, H.: R2former: Unified retrieval and reranking transformer for place recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19370– 19380 (2023) Seeing Through the Weights 19 Seeing Through the Weights: Privacy Leakage in Scene Coordinate Regression Suppl...
2023
-
[52]
11, Table 5), which is considered an upper bound for PPVL
(Fig. 11, Table 5), which is considered an upper bound for PPVL. InvSfM preserves sharper local details when the 3D geometry is accurate, but it can still obtain low PSNR because sparse points create missing regions and occlusion artifacts. Appearance leakage quality.To further evaluate the information revealed by the proposed method, we assess object rec...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.