VeryTrace: Verifying Reasoning Traces through Compilable Formalism and Structured Verification
Pith reviewed 2026-06-26 00:28 UTC · model grok-4.3
The pith
VeryTrace converts natural-language reasoning traces into a compilable DSL, then applies hybrid deterministic and LLM checks to localize and repair errors step by step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
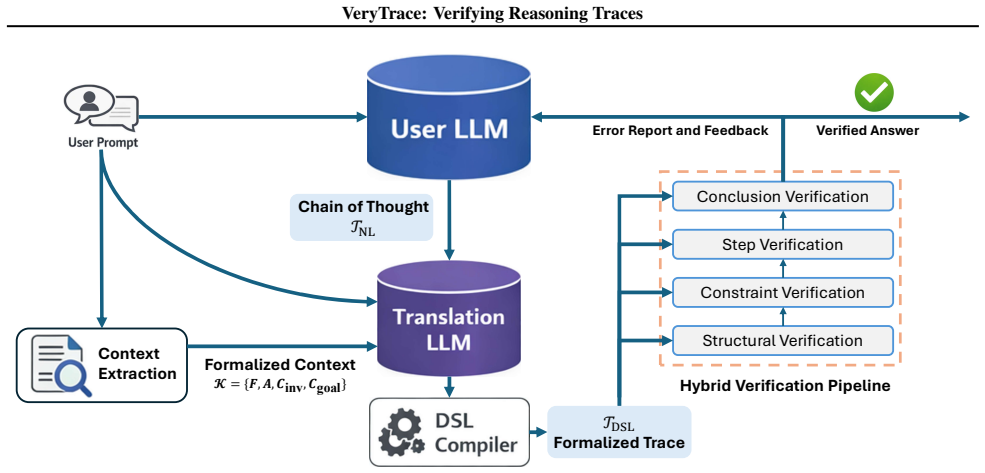
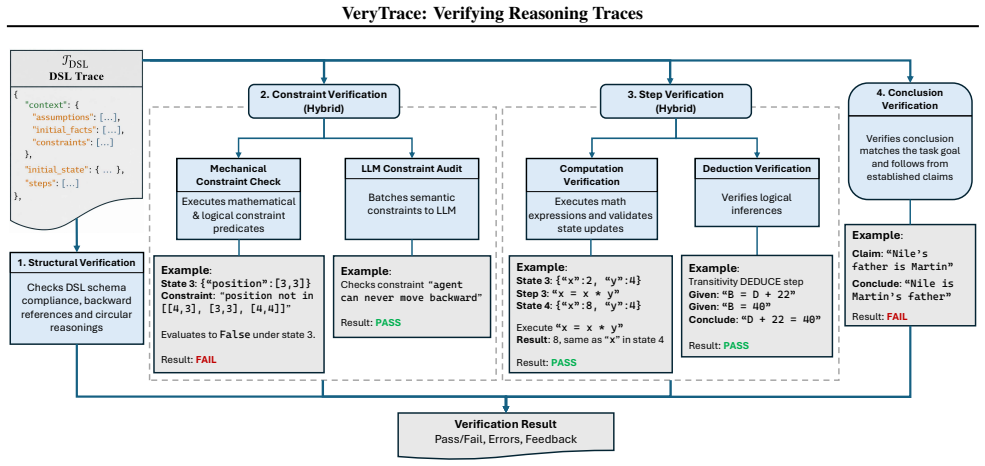
Formalizing reasoning traces into a Domain-Specific Language that captures explicit step dependencies, executable quantitative content, and structured deduction schemas, then feeding those traces to a hybrid verifier that combines deterministic constraint and computation checks with LLM-based semantic audits, enables precise localization and repair of errors and produces higher final-answer accuracy across unrelated domains.
What carries the argument
The Domain-Specific Language (DSL) that enforces explicit dependencies, executable expressions, and deduction schemas within reasoning traces, allowing the hybrid verifier to perform deterministic checks alongside targeted semantic audits.
If this is right
- Errors that would otherwise propagate through an entire trace become detectable and correctable at the individual step level.
- The same verification pipeline improves performance on competition mathematics, robotics planning, and kinship reasoning without domain-specific adaptation.
- Deterministic checks handle computable content while LLM audits handle non-mechanizable semantic judgments within a single framework.
- Accuracy gains appear on state-of-the-art LLMs in a purely zero-shot regime with no additional training or examples required.
Where Pith is reading between the lines
- The same formalization approach could be applied to other multi-step domains such as code generation or scientific reasoning where step dependencies matter.
- If the DSL translation remains reliable at scale, it might reduce reliance on sampling-based consistency methods that currently compensate for undetected errors.
- Making traces machine-checkable in this way points toward pipelines that treat verification as an explicit, separate stage rather than an implicit property of the model.
Load-bearing premise
Natural-language reasoning traces can be translated into the DSL without losing meaning or creating ambiguities that the hybrid verifier then fails to catch.
What would settle it
A concrete reasoning trace in which the DSL translation preserves a logical error that the hybrid verifier neither detects nor repairs, so final accuracy shows no improvement or declines.
Figures
read the original abstract
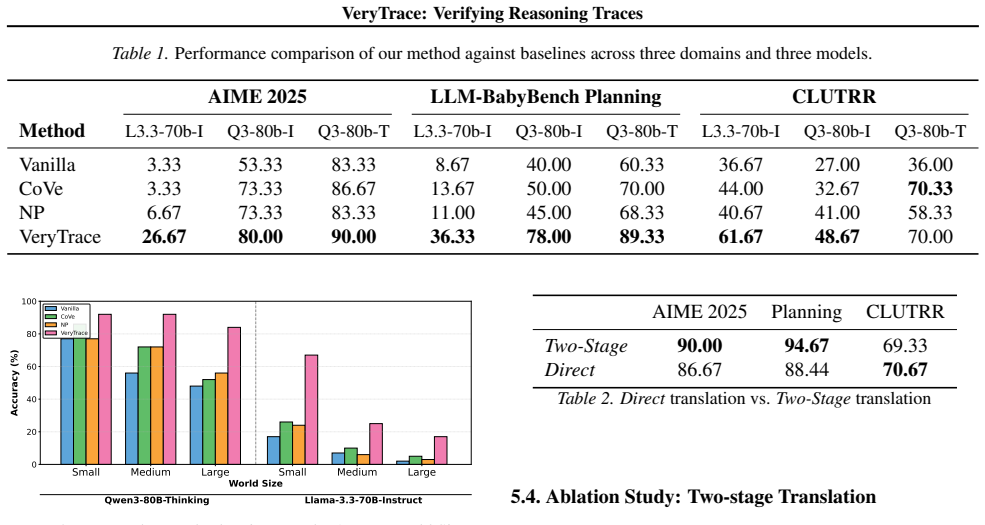
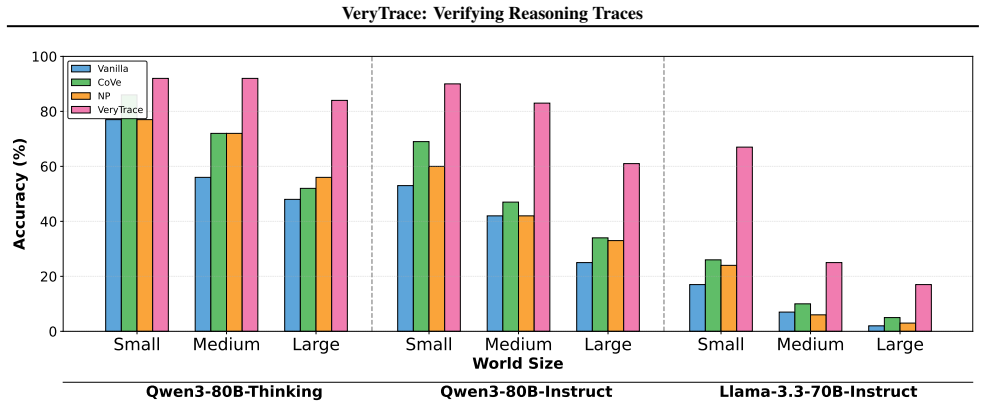
Multi-step reasoning with Chain-of-Thought (CoT) prompting remains fragile: logical errors or hallucinations in early steps silently propagate, producing confident but incorrect conclusions. This paper presents VeryTrace, a zero-shot verification-and-repair framework that formalizes natural-language reasoning traces into a structured, compilable representation. VeryTrace introduces a Domain-Specific Language (DSL) that (i) makes step dependencies explicit, (ii) mechanizes quantitative content as executable expressions, and (iii) structures semantic inferences via deduction schemas. Our hybrid verifier combines deterministic checks for computational correctness, dependency resolution, and constraint satisfaction with targeted LLM audits for non-mechanizable semantic judgments, enabling step-level error localization and repair. Across three diverse domains-competition mathematics (AIME 2025), robotics planning (LLM-BabyBench), and kinship reasoning (CLUTRR), VeryTrace improves accuracy over zero-shot baselines on state-of-the-art LLMs without requiring domain-specific training or in-context examples, demonstrating that formalized trace verification achieves both precision and generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VeryTrace, a zero-shot framework that translates natural-language Chain-of-Thought reasoning traces into a structured, compilable Domain-Specific Language (DSL) encoding explicit step dependencies, executable quantitative expressions, and deduction schemas. A hybrid verifier then applies deterministic checks (computational correctness, dependency resolution, constraint satisfaction) plus targeted LLM audits for semantic judgments to localize and repair errors. The central empirical claim is that this yields accuracy gains over zero-shot baselines on three benchmarks—AIME 2025 (competition math), LLM-BabyBench (robotics planning), and CLUTRR (kinship reasoning)—using state-of-the-art LLMs without domain-specific training or in-context examples.
Significance. If the NL-to-DSL mapping is reliable and the reported gains are robust, the work would demonstrate a general, training-free method for improving multi-step LLM reasoning reliability across mathematically and semantically distinct domains. The hybrid deterministic-plus-LLM verification design and the emphasis on compilable formalisms are potentially valuable contributions if the translation step is shown not to introduce or mask errors.
major comments (2)
- [Abstract, §3] Abstract and §3 (DSL and translation procedure): The central claim that formalized trace verification improves accuracy rests on the assumption that every natural-language trace can be mapped into the DSL without semantic loss or addition. No mechanism, prompt template, or validation (e.g., human agreement rates, ablation on translation errors, or failure cases) for this zero-shot mapping step is described. If the mapping itself is LLM-driven, it can silently drop quantifiers, invert dependencies, or mis-encode schemas, rendering the downstream deterministic checks and audits unreliable; this directly falsifies both the precision and cross-domain generalization claims.
- [§5, Tables 1–3] §5 (Experimental results) and Tables 1–3: The abstract asserts accuracy gains on AIME 2025, LLM-BabyBench, and CLUTRR but supplies no numerical values, baselines, error bars, statistical tests, or exclusion criteria. Without these data and without an ablation isolating the contribution of the translation step versus the verifier, it is impossible to determine whether the reported improvements support the claim that the hybrid verifier localizes and repairs errors rather than propagating mapping artifacts.
minor comments (2)
- [§3] Notation for the DSL operators and deduction schemas should be defined in a single table or appendix for reference; scattered inline definitions reduce readability.
- [§4] The paper should clarify whether the LLM audits in the hybrid verifier use the same model family as the original reasoner or a separate one, as this affects claims of independence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the NL-to-DSL mapping and experimental reporting. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (DSL and translation procedure): The central claim that formalized trace verification improves accuracy rests on the assumption that every natural-language trace can be mapped into the DSL without semantic loss or addition. No mechanism, prompt template, or validation (e.g., human agreement rates, ablation on translation errors, or failure cases) for this zero-shot mapping step is described. If the mapping itself is LLM-driven, it can silently drop quantifiers, invert dependencies, or mis-encode schemas, rendering the downstream deterministic checks and audits unreliable; this directly falsifies both the precision and cross-domain generalization claims.
Authors: We agree that the current manuscript does not describe the prompt templates, validation procedures, or potential failure cases for the zero-shot NL-to-DSL translation. This constitutes a genuine gap in transparency. In the revised version we will add the exact translation prompts to an appendix, include a discussion of mapping limitations with illustrative failure examples drawn from our development process, and report any available fidelity checks. The DSL was designed to require explicit encoding of dependencies and executable expressions precisely to reduce semantic drift, but we accept that additional documentation is needed to support the claims. revision: yes
-
Referee: [§5, Tables 1–3] §5 (Experimental results) and Tables 1–3: The abstract asserts accuracy gains on AIME 2025, LLM-BabyBench, and CLUTRR but supplies no numerical values, baselines, error bars, statistical tests, or exclusion criteria. Without these data and without an ablation isolating the contribution of the translation step versus the verifier, it is impossible to determine whether the reported improvements support the claim that the hybrid verifier localizes and repairs errors rather than propagating mapping artifacts.
Authors: Tables 1–3 already contain the per-benchmark accuracy numbers, baselines, and comparisons; the abstract was intentionally concise. We will revise the abstract to state the concrete gains (e.g., absolute accuracy improvements on each dataset). Error bars and statistical tests were not computed in the original experiments; we will add them if the raw trial data permit, otherwise note their absence as a limitation. An explicit ablation separating translation quality from verifier contribution is not present; we will include a paragraph explaining the difficulty of clean isolation given the end-to-end pipeline and list it as future work rather than claiming such an ablation exists. revision: partial
Circularity Check
No circularity: empirical verification framework with no self-referential derivations or fitted predictions
full rationale
The paper presents an engineering framework for trace verification via DSL formalization and hybrid checking. No equations, parameters, or predictions are defined in terms of themselves; the reported accuracy gains are empirical outcomes on external benchmarks (AIME, BabyBench, CLUTRR) rather than quantities forced by construction from the method's inputs. The central assumption of lossless NL-to-DSL translation is an unverified premise (a correctness risk), but it does not reduce any claimed result to a tautology or self-citation chain. No load-bearing self-citations or ansatzes appear in the provided text. The derivation is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Making Language Models Better Reasoners with Step-Aware Verifier
URL https://openreview.net/forum? id=rygGQyrFvH. Jiang, A. Q., Welleck, S., Zhou, J. P., Li, W., Liu, J., Jamnik, M., Lacroix, T., Wu, Y ., and Lample, G. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs.arXiv preprint arXiv:2210.12283, 2023. Kesseli, P., O’Hearn, P., and Cabral, R. S. Logic. py: Bridg- ing the gap between llm...
-
[2]
Association for Computational Linguistics. Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y ., et al. Self-refine: Iterative refinement with self- feedback.Advances in Neural Information Processing Systems, 36:46534–46594, 2023. Mao, J., Gan, C., Kohli, P., Tenenbaum, J. B., and Wu, J. T...
Pith/arXiv arXiv 2023
-
[3]
Betty starts with $50
**initial_facts**: Given facts that describe the INITIAL or STARTING conditions. - These are facts that may only hold at the beginning and can change during reasoning. - Examples: "Betty starts with $50", "Robot is at position (0, 0)", "John has 5 apples initially" - If a variable is associated or defined with a fact statement, it should also be included ...
-
[4]
All apples are whole apples (no fractions)
**assumptions**: Facts assumed to be true THROUGHOUT ALL reasoning steps. - These are persistent truths that don’t change, unlike initial_facts. - These are facts taken as given, NOT conditions to verify (those are constraints). - Look for both EXPLICIT assumptions (stated in the problem) and IMPLICIT assumptions (implied by the problem context). - Exampl...
-
[5]
description
**constraints**: Conditions that must be VERIFIED or SATISFIED during reasoning. - These are NOT assumptions (facts taken as given), but conditions to CHECK. - Each constraint has: * "description": Natural language explanation * "constraint_expr": Mathematical expression MUST uses variables from initial_state (e.g., "x < 10", "position
-
[6]
) - Leave empty if cannot be expressed mathematically *
!= 2") - Leave empty if cannot be expressed mathematically * "scope": "invariant" (must hold at ALL steps) or "goal" (must hold only at FINAL step) - Examples: "The agent cannot go to position (2, 3)", "Total must not exceed 100" - Format: {{"id": "c1", "description": "...", "constraint_expr": "...", "scope": "invariant|goal"}}
-
[7]
position
**initial_state**: Initial values of variables mentioned in the problem. - Extract starting values for quantitative reasoning. - Examples: {{"position": [0, 0], "money": 50, "direction": 0}}
-
[8]
context": {{
**goal**: The question or goal to be answered. **CRITICAL INSTRUCTIONS: ** - **Extract EVERYTHING **: Be thorough - extract all facts, assumptions, and constraints that might be relevant. - **Do NOT solve **: You are NOT solving the problem, just extracting context. - **Look for implicit assumptions **: Don’t just extract what’s explicitly stated - also i...
-
[9]
Context extracted from the prompt (provided above)
-
[10]
The COT typically doesn’t add new initial facts
Any additional context mentioned or used in the COT **How to combine: ** - **initial_facts**: Use the ones from pre-extracted context. The COT typically doesn’t add new initial facts. - **assumptions**: COMBINE (union) assumptions from pre-extracted context AND any additional assumptions mentioned 17 VeryTrace: Verifying Reasoning Traces in the COT. - If ...
-
[11]
fact_1",
Use initial_facts from pre-extracted context with IDs like "fact_1", "fact_2", etc
-
[12]
**Use initial_state from pre-extracted context **: The initial state variables have been extracted from the problem statement
-
[13]
Use goal from pre-extracted context
-
[14]
Calculate X and then use it to determine Y
**Decompose COT into atomic steps **: - Each step should be a single inference, calculation, or deduction. - If the original COT combines multiple reasoning operations in one step, SPLIT them into separate steps. - Examples of what to split: * "Calculate X and then use it to determine Y" --> Split into: Step 1 (calculate X), Step 2 (determine Y using X) *...
-
[15]
c_N+1" for additions * Give each constraint a scope:
**COMBINE constraints ** from pre-extracted context and COT: - The pre-extracted context already has constraints with mathematical expressions where possible - If the COT mentions additional constraints not in pre-extracted context, ADD them - For new constraints: * ** MAXIMALLY USE MATHEMATICAL EXPRESSIONS **: This is the MOST IMPORTANT requirement * For...
-
[16]
id": "a_N+1
**COMBINE assumptions ** from pre-extracted context and COT: - The pre-extracted context already has assumptions - If the COT explicitly mentions or relies on additional assumptions not in pre-extracted context, ADD them - Format: {{"id": "a_N+1", "content": "..."}} - Preserve IDs from pre-extracted context; assign new sequential IDs for additions
-
[17]
assume" - Establishing a fact from context/premises *
For each reasoning step: - **inference_type**: Classify the step as one of: * "assume" - Establishing a fact from context/premises * "deduce" - Logical deduction or inference (MUST provide deduction_rule and deduction_args) from premises * "compute" - Performing calculations (MUST provide compute_expr and updates) * "conclude" - Final conclusion - **claim...
-
[18]
step_#" to reference previous steps (e.g.,
Extract the final conclusion - **content**: The content must have enough information to fully answer the original problem. - **BE THOROUGH **: The content must be thorough and complete. Avoid a single-word answer. **CRITICAL RULES FOR PREMISES: ** - ALWAYS use "step_#" to reference previous steps (e.g., "step_1", "step_2") - ALWAYS use "fact_#" to referen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.