VGB for Masked Diffusion Model: Efficient Test-time Scaling for Reward Satisfaction and Sample Editing
Pith reviewed 2026-06-29 04:01 UTC · model grok-4.3
The pith
MDM-VGB extends backtracking Markov chains to masked-state graphs for quadratic-complexity reward-guided sampling in diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
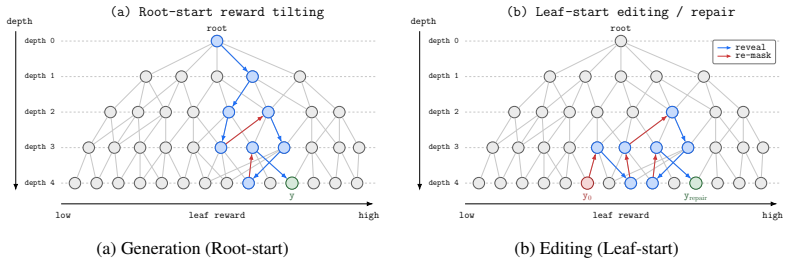
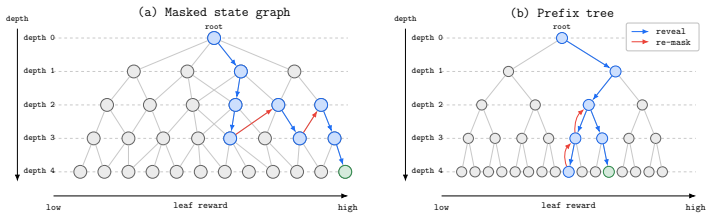
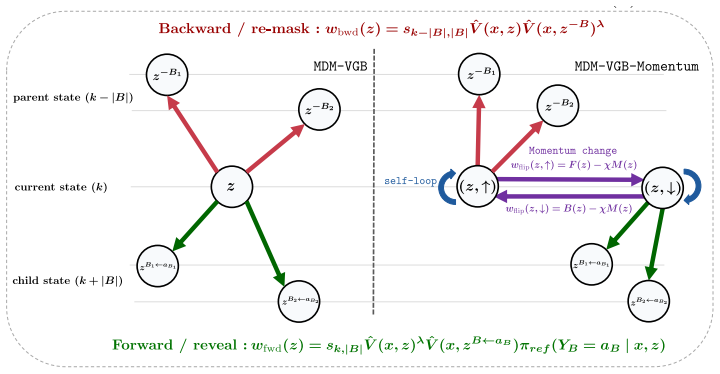
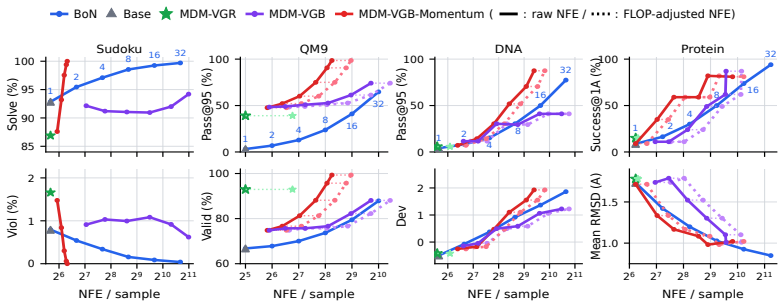
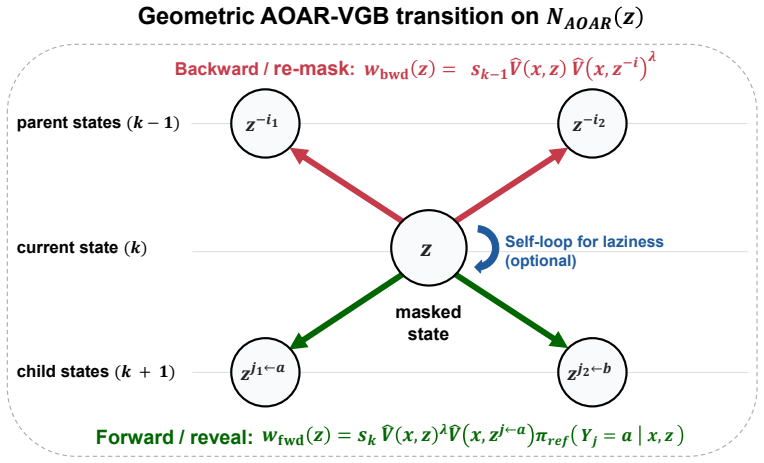
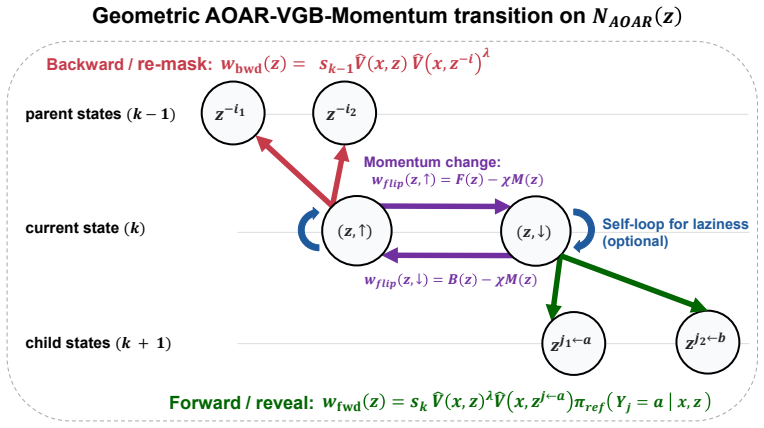
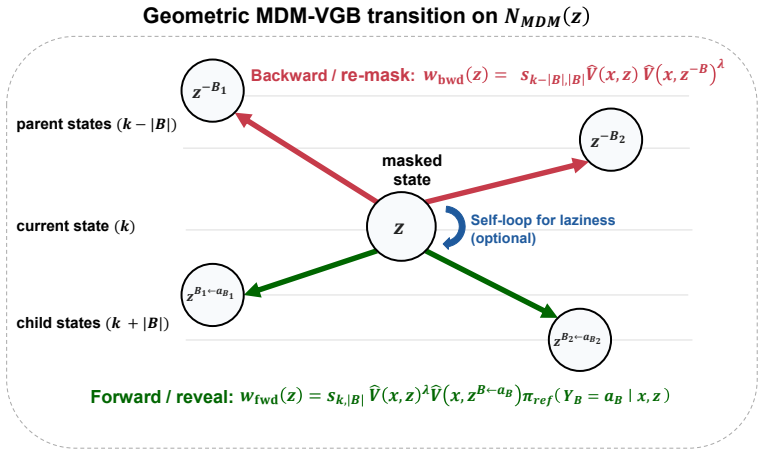
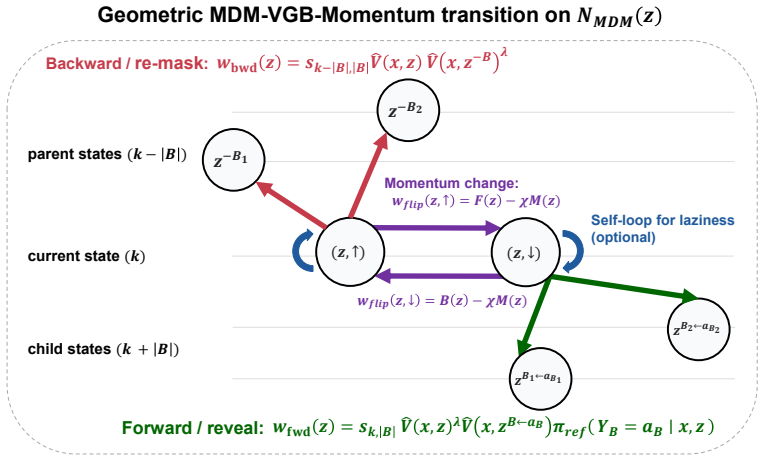
MDM-VGB extends the Jerrum-Sinclair backtracking Markov chain from a fixed prefix tree to an arbitrary masked-state graph and tilts the walk with the reward, so that unmasking and remasking moves favor higher-value partial configurations. The resulting sampler achieves quadratic complexity, remains robust to process-verifier noise, and enables both high-reward generation and efficient repair of low-reward samples, whereas best-of-N incurs exponential complexity from error accumulation.
What carries the argument
Reward-tilted backtracking random walk on the masked-state graph, which permits unmasking and remasking at arbitrary token positions.
If this is right
- High-reward samples can be produced with quadratic rather than exponential cost relative to the number of tokens.
- Low-reward outputs can be repaired by selectively remasking and re-unmasking positions.
- The sampler stays effective even when the process verifier that guides the reward is noisy.
- Performance advantages appear on constraint-satisfaction benchmarks such as Sudoku and on molecular property tasks such as QM9.
Where Pith is reading between the lines
- The masked-state graph construction may transfer to other discrete generative models that expose partial states during sampling.
- Quadratic scaling could allow hybrid training-plus-inference loops that optimize non-differentiable rewards without full retraining.
- If the mixing guarantees extend to other reward functions, similar backtracking could improve test-time methods beyond diffusion.
Load-bearing premise
Extending the Jerrum-Sinclair backtracking Markov chain from a fixed prefix tree to an arbitrary masked-state graph preserves its mixing and robustness properties when the reward is used to tilt the walk.
What would settle it
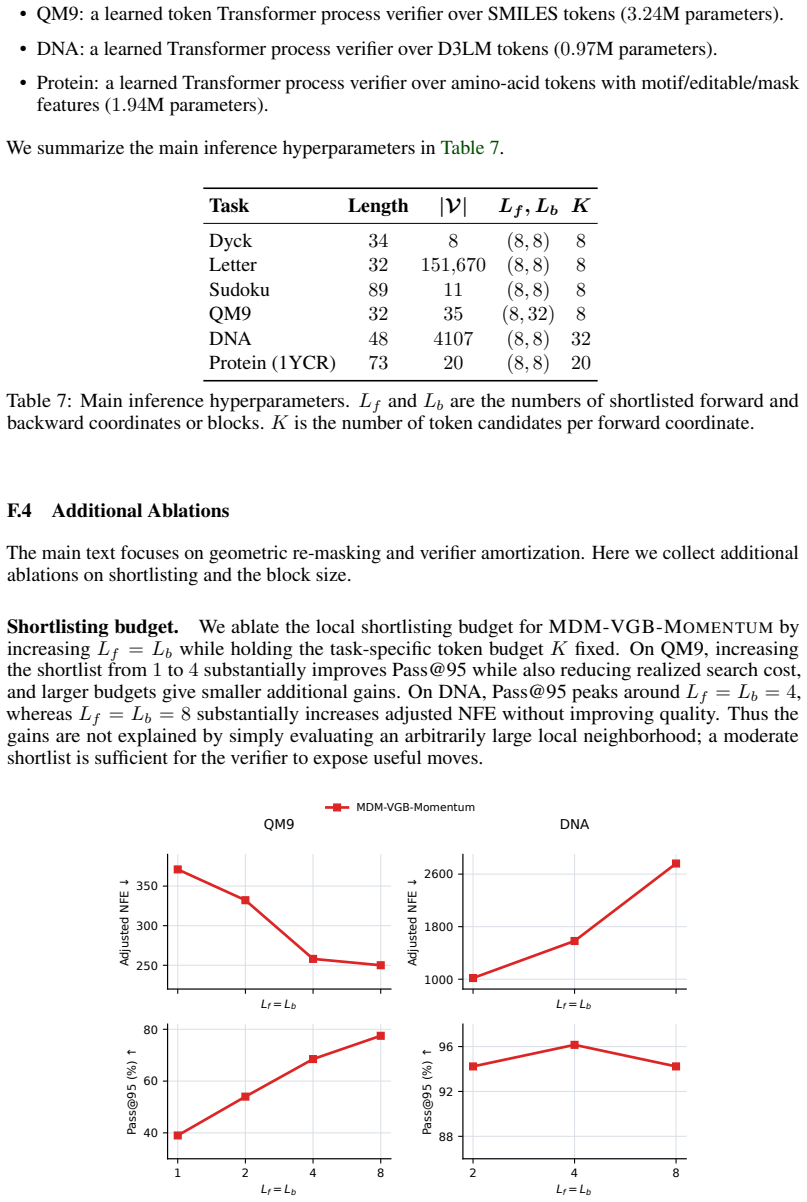
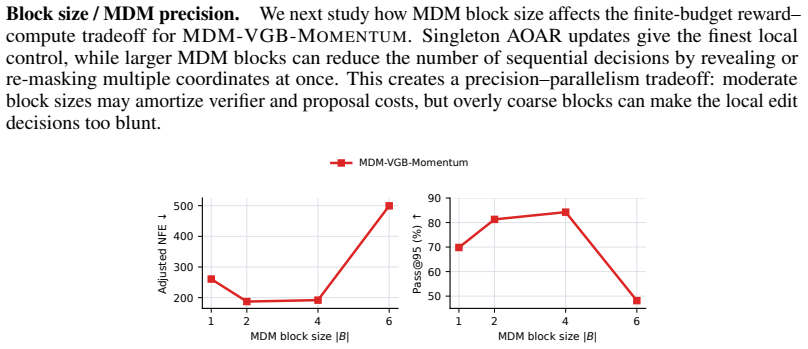
An experiment on Sudoku or QM9 showing that the number of steps needed for MDM-VGB to reach a target reward level grows exponentially with sequence length under increasing verifier noise.
Figures
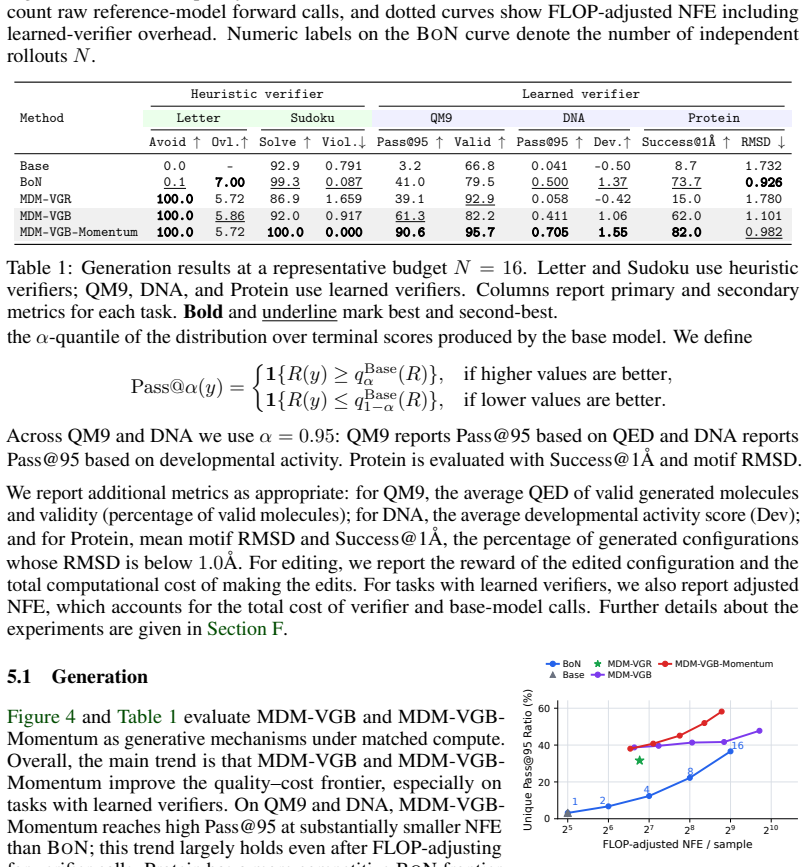
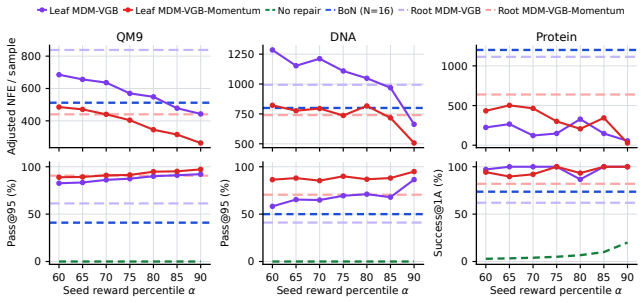


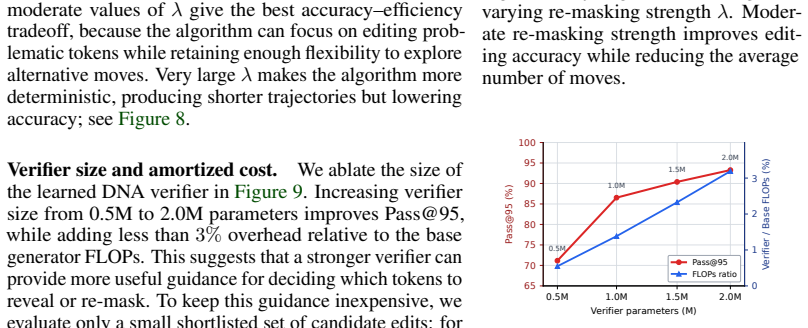
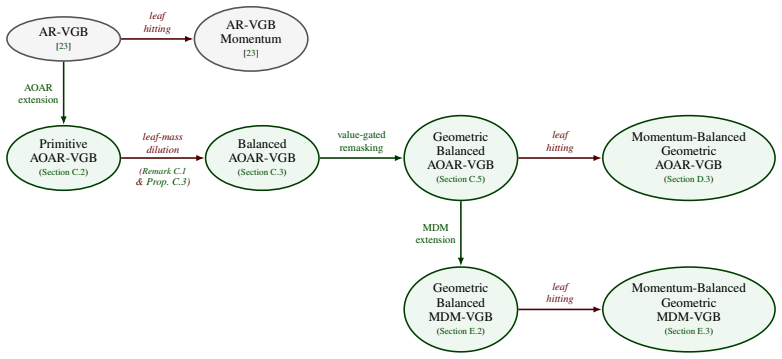

read the original abstract
Inference-time scaling is a promising paradigm to improve generative models, especially when outputs must satisfy structural constraints or optimize downstream rewards. We consider Masked Diffusion Model (MDM) and introduce MDM-VGB, a discrete diffusion sampler that augments unmasking generation with theoretically principled reward-guided remasking. Inspired by the recent success of the classical Jerrum-Sinclair backtracking Markov chain in reward-tilted generation, MDM-VGB extends the backtracking random walk from a fixed prefix tree to a masked-state graph, allowing tokens to be unmasked and remasked at arbitrary positions. The resulting sampler favors unmasking and remasking moves that lead to higher-value partial configurations, enabling both effective high-reward generation and efficient repair of low-reward samples. We prove that MDM-VGB is robust to process-verifier noise and achieves quadratic complexity, while popular test-time heuristics such as best-of-$N$ can incur exponential complexity due to error accumulation. Our theoretical findings are corroborated by strong empirical performance, particularly on popular constraint-satisfaction and scientific benchmarks such as Sudoku and QM9.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MDM-VGB, a discrete diffusion sampler for Masked Diffusion Models that augments standard unmasking with reward-guided remasking by extending the Jerrum-Sinclair backtracking Markov chain from a prefix tree to a general masked-state graph. It claims to prove that MDM-VGB is robust to process-verifier noise and achieves quadratic complexity (in contrast to exponential complexity for best-of-N due to error accumulation), while also enabling sample editing; these claims are supported by empirical results on constraint-satisfaction tasks such as Sudoku and molecular benchmarks such as QM9.
Significance. If the central theoretical claims hold, the work would provide a principled, polynomial-time test-time scaling method for reward-driven generation and editing in masked diffusion models, addressing a key limitation of heuristic approaches and offering potential advantages for structured generation tasks in ML and scientific domains.
major comments (2)
- [Abstract / Theoretical analysis] Abstract and theoretical analysis section: the claim that the extension of the Jerrum-Sinclair backtracking chain to the masked-state graph preserves quadratic mixing time and noise robustness under reward tilting is asserted without an explicit conductance bound, coupling argument, or stationary-distribution analysis that accounts for the cycles and position-dependent connectivity absent from the original tree case; if remasking moves create low-conductance cuts for non-monotonic rewards, both the quadratic-complexity guarantee and the exponential-vs-quadratic comparison to best-of-N would not follow.
- [Empirical evaluation] Empirical evaluation section: the abstract states that theoretical findings are 'corroborated by strong empirical performance' on Sudoku and QM9, yet no specific quantitative results, baselines (including best-of-N variants), metrics, or statistical details are provided in the visible summary; without these, the empirical support for the complexity and robustness claims cannot be assessed.
minor comments (1)
- Notation for the masked-state graph and reward-tilted transitions should be defined more explicitly (e.g., transition probabilities and stationary distribution) to aid readability of the theoretical claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Theoretical analysis] Abstract and theoretical analysis section: the claim that the extension of the Jerrum-Sinclair backtracking chain to the masked-state graph preserves quadratic mixing time and noise robustness under reward tilting is asserted without an explicit conductance bound, coupling argument, or stationary-distribution analysis that accounts for the cycles and position-dependent connectivity absent from the original tree case; if remasking moves create low-conductance cuts for non-monotonic rewards, both the quadratic-complexity guarantee and the exponential-vs-quadratic comparison to best-of-N would not follow.
Authors: We agree that the current theoretical section asserts preservation of quadratic mixing time and noise robustness for the masked-state graph extension but does not supply an explicit conductance bound or coupling argument that fully treats cycles and position-dependent connectivity. The manuscript sketches the graph extension from the tree case but leaves the detailed stationary-distribution analysis implicit. We will add the requested conductance bound, coupling argument, and analysis of potential low-conductance cuts under non-monotonic rewards in the revised theoretical section to substantiate the quadratic-complexity claim and the comparison to best-of-N. revision: yes
-
Referee: [Empirical evaluation] Empirical evaluation section: the abstract states that theoretical findings are 'corroborated by strong empirical performance' on Sudoku and QM9, yet no specific quantitative results, baselines (including best-of-N variants), metrics, or statistical details are provided in the visible summary; without these, the empirical support for the complexity and robustness claims cannot be assessed.
Authors: The full empirical evaluation section of the manuscript reports concrete quantitative results on Sudoku (success rates and scaling curves) and QM9 (property scores), with direct comparisons to best-of-N baselines at multiple N values, along with metrics and statistical details that support the quadratic scaling and noise-robustness claims. The abstract summarizes these findings at a high level. Because the referee references only the 'visible summary,' we interpret that the body was not reviewed; we will add a concise summary of key quantitative results to the abstract for completeness. revision: partial
Circularity Check
No circularity: theoretical claims rest on external classical MCMC result plus claimed extension proof
full rationale
The abstract states that MDM-VGB extends the classical Jerrum-Sinclair backtracking Markov chain (an external 1989 result) to a masked-state graph and proves quadratic complexity plus noise robustness. No equations, fitted parameters, or self-citations are quoted that reduce the claimed properties to inputs by construction. The derivation is presented as self-contained via the extension argument, with no load-bearing self-citation chain or renaming of known results visible.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Jerrum-Sinclair backtracking chain properties extend to the masked-state graph under reward tilting.
Reference graph
Works this paper leans on
-
[1]
Protein generation with evolutionary diffusion: sequence is all you need
Sarah Alamdari, Nitya Thakkar, Rianne van den Berg, Alex Lu, Nicolo Fusi, Ava Amini, and Kevin Yang. Protein generation with evolutionary diffusion: sequence is all you need. In NeurIPS 2023 Generative AI and Biology (GenBio) Workshop, 2023. 10, 70
2023
-
[2]
Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models. InThe Thirteenth International Conference on Learning Representations, 2025. 3
2025
-
[3]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Struc- tured denoising diffusion models in discrete state-spaces. InAdvances in Neural Information Processing Systems, volume 34, pages 17981–17993, 2021. 3, 58
2021
-
[4]
Quantifying the chemical beauty of drugs.Nature chemistry, 4:90–8, 02 2012
Richard Bickerton, Gaia Paolini, Jérémy Besnard, Sorel Muresan, and Andrew Hopkins. Quantifying the chemical beauty of drugs.Nature chemistry, 4:90–8, 02 2012. doi: 10.1038/nchem.1243. 10, 69
-
[5]
Le, Christopher Ré, and Azalia Mirhoseini
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024. 1, 10, 19
Pith/arXiv arXiv 2024
-
[6]
Schützenberger
Noam Chomsky and Marcel P. Schützenberger. The algebraic theory of context-free languages. InComputer Programming and Formal Systems, pages 118–161. North-Holland, 1963. 68
1963
-
[7]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
-
[8]
de Almeida, Hassan Sirelkhatim, Guillaume Richard, Marcin Skwark, Karim Beguir, Marie Lopez, and Thomas Pierrot
Hugo Dalla-Torre, Liam Gonzalez, Javier Mendoza-Revilla, Nicolas Lopez Carranza, Adam Henryk Grzywaczewski, Francesco Oteri, Christian Dallago, Evan Trop, Bernardo P. de Almeida, Hassan Sirelkhatim, Guillaume Richard, Marcin Skwark, Karim Beguir, Marie Lopez, and Thomas Pierrot. Nucleotide transformer: building and evaluating robust foun- dation models fo...
2025
-
[9]
de Almeida, Franziska Reiter, Michaela Pagani, and Alexander Stark
Bernardo P. de Almeida, Franziska Reiter, Michaela Pagani, and Alexander Stark. DeepSTARR predicts enhancer activity from DNA sequence and enables the de novo design of synthetic enhancers.Nature Genetics, 54:613–624, 2022. 10, 69
2022
-
[10]
Qwen3-0.6b-diffusion-mdlm-v0.1
dLLM Hub. Qwen3-0.6b-diffusion-mdlm-v0.1. https://huggingface.co/dllm-hub/ Qwen3-0.6B-diffusion-mdlm-v0.1, 2026. 10, 68
2026
-
[11]
Hayes and Alistair Sinclair
Thomas P. Hayes and Alistair Sinclair. Liftings of tree-structured markov chains. InApproxi- mation, Randomization, and Combinatorial Optimization. Algorithms and Techniques, pages 602–616. Springer, 2010. 2, 7, 8, 46
2010
-
[12]
Audrey Huang, Adam Block, Qinghua Liu, Nan Jiang, Akshay Krishnamurthy, and Dylan J. Foster. Is best-of-N the best of them? coverage, scaling, and optimality in inference-time alignment.arXiv preprint arXiv:2503.21878, 2025. 10, 19 14
arXiv 2025
-
[13]
Pan, Hyeji Kim, Sham Kakade, and Sitan Chen
Jaeyeon Kim, Seunggeun Kim, Taekyun Lee, David Z. Pan, Hyeji Kim, Sham Kakade, and Sitan Chen. Fine-tuning masked diffusion for provable self-correction.arXiv preprint arXiv:2510.01384, 2025. 69
Pith/arXiv arXiv 2025
-
[14]
Jihoon Lee, Hoyeon Moon, Kevin Zhai, Arun Kumar Chithanar, Anit Kumar Sahu, Soummya Kar, Chul Lee, Souradip Chakraborty, and Amrit Singh Bedi. Test-time scaling in diffusion llms via hidden semi-autoregressive experts.arXiv preprint arXiv:2510.05040, 2025. 3, 14
arXiv 2025
-
[15]
Sanghyun Lee, Sunwoo Kim, Seungryong Kim, Jongho Park, and Dongmin Park. Effective test- time scaling of discrete diffusion through iterative refinement.arXiv preprint arXiv:2511.05562,
-
[16]
Levin and Yuval Peres.Markov Chains and Mixing Times, volume 107
David A. Levin and Yuval Peres.Markov Chains and Mixing Times, volume 107. American Mathematical Society, 2017. 7, 28, 32, 38, 39, 44
2017
-
[17]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024. 1
2024
-
[18]
Vladimir N. Maiorov and Gordon M. Crippen. Significance of root-mean-square deviation in comparing three-dimensional structures of globular proteins.Journal of Molecular Biology, 235(2):625–634, 1994. ISSN 0022-2836. doi: https://doi.org/10.1006/jmbi.1994.1017. URL https://www.sciencedirect.com/science/article/pii/S0022283684710175. 10
-
[19]
Kou Misaki and Takuya Akiba. Unmaskfork: Test-time scaling for masked diffusion via deterministic action branching.arXiv preprint arXiv:2602.04344, 2026. 1, 3
arXiv 2026
-
[20]
Zijing Ou, Chinmay Pani, and Yingzhen Li. Inference-time scaling of discrete diffusion models via importance weighting and optimal proposal design.arXiv preprint arXiv:2505.22524, 2025. 3
arXiv 2025
-
[21]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023. 10, 69
2023
-
[22]
Dral, Matthias Rupp, and O
Raghunathan Ramakrishnan, Pavlo O. Dral, Matthias Rupp, and O. Anatole von Lilienfeld. Quantum chemistry structures and properties of 134 kilo molecules.Scientific Data, 1:140022,
-
[23]
Taming imperfect process verifiers: A sampling perspective on backtracking
Dhruv Rohatgi, Abhishek Shetty, Donya Saless, Yuchen Li, Ankur Moitra, Andrej Risteski, and Dylan J Foster. Taming imperfect process verifiers: A sampling perspective on backtracking. arXiv preprint arXiv:2510.03149, 2025. 1, 2, 3, 4, 5, 6, 7, 8, 10, 19, 24, 32, 46
arXiv 2025
-
[24]
Simple and effective masked diffusion language models
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models. InAdvances in Neural Information Processing Systems, volume 37,
-
[25]
Approximate counting, uniform generation and rapidly mixing markov chains.Information and Computation, 82(1):93–133, 1989
Alistair Sinclair and Mark Jerrum. Approximate counting, uniform generation and rapidly mixing markov chains.Information and Computation, 82(1):93–133, 1989. 1, 2, 3, 5, 6, 8
1989
-
[26]
Remasking discrete diffusion models with inference-time scaling
Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Remasking discrete diffusion models with inference-time scaling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 1, 3
2025
-
[27]
Value-guided search for efficient chain-of-thought reasoning
Kaiwen Wang, Jin Peng Zhou, Jonathan Chang, Zhaolin Gao, Nathan Kallus, Kianté Brantley, and Wen Sun. Value-guided search for efficient chain-of-thought reasoning. InAdvances in Neural Information Processing Systems, 2025. 1
2025
-
[28]
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, Bangkok, Thailand, 2024. Association for Co...
2024
-
[29]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023. 1
2023
-
[30]
High-resolution de novo structure prediction from primary sequence.bioRxiv preprint, 2022
Ruidong Wu, Fan Ding, Rui Wang, Rui Shen, Xiwen Zhang, Shitong Luo, Chenpeng Su, Zuofan Wu, Qi Xie, Bonnie Berger, Jianzhu Ma, and Jian Peng. High-resolution de novo structure prediction from primary sequence.bioRxiv preprint, 2022. 10, 70
2022
-
[31]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[32]
FUDGE: Controlled text generation with future discriminators
Kevin Yang and Dan Klein. FUDGE: Controlled text generation with future discriminators. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3511–3535, Online, 2021. Association for Computational Linguistics. 1
2021
-
[33]
Zhao Yang, Hengchang Liu, Chuan Cao, and Bing Su. D3LM: A discrete DNA diffusion language model for bidirectional DNA understanding and generation, 2026. URL https: //arxiv.org/abs/2603.01780. 10, 69 16 TABLE OFCONTENTS 1 Introduction 1 2 Other related works 3 3 Preliminaries 3 4 Methods and Theoretical Guarantees 5 4.1 Formulation of MDM-VGB . . . . . . ...
arXiv 2026
-
[34]
Ifz∈ Z +(x)andi∈R(z), thenz −i ∈ Z +(x)
-
[35]
Proof.SinceZ(x)>0, U ⋆(x,∅) =Z(x)>0, so∅∈ Z +(x)
If z∈ Z +(x), j /∈R(z), and c=z j←a /∈ Z+(x), then the AOAR edge {z, c} has zero balanced edge weight and zero geometric edge weight. Proof.SinceZ(x)>0, U ⋆(x,∅) =Z(x)>0, so∅∈ Z +(x). For the first claim, let p=z −i. Since p is obtained by re-masking one revealed coordinate of z, we have C(z)⊆ C(p). Thus U ⋆(x, p) = X y∈C(p) πref(y|x)τ(x, y)≥ X y∈C(z) πre...
-
[36]
naturalness: Does the text read like fluent natural English?
-
[37]
coherence: Is it internally coherent as a one-sentence story?
-
[38]
semantic_plausibility: Does it make semantic sense rather than feeling like token salad or broken text?
-
[39]
Use the task prompt as context when judging overall quality
overall: Overall quality as an answer to the task prompt. Use the task prompt as context when judging overall quality. Return ONLY a JSON object with integer fields naturalness, coherence, semantic_plausibility, overall. Sudoku.Sudoku is a structured constraint-satisfaction benchmark. Each puzzle is a flattened 9×9 grid with fixed clues and editable empty...
-
[40]
For partial configurations, we use a heuristic process verifier that returns the indicator that no Sudoku constraint has yet been violated
with a Diffusion Transformer backbone [21], trained on this data. For partial configurations, we use a heuristic process verifier that returns the indicator that no Sudoku constraint has yet been violated. QM9 molecule generation.QM9 is a small-molecule generation benchmark over organic molecules with up to nine heavy atoms [ 22]. We use a split with 127,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.