OpenThoughts-Agent: Data Recipes for Agentic Models
Pith reviewed 2026-06-25 22:59 UTC · model grok-4.3
The pith
An open data curation pipeline for agentic models produces a 100K-example training set that lifts fine-tuned 32B accuracy to 44.8 percent across seven benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
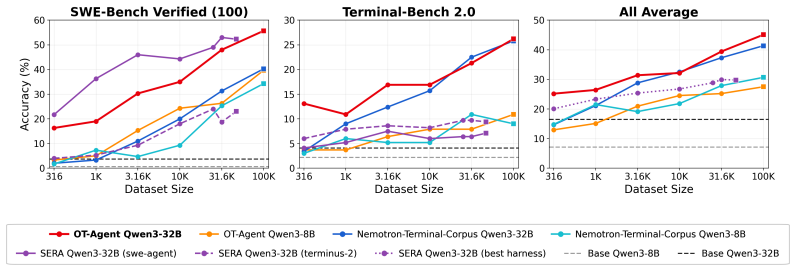
The OpenThoughts-Agent pipeline systematically varies task sources and diversity levels, then assembles 100K training examples that, after fine-tuning on Qwen3-32B, deliver 44.8 percent average accuracy on seven agentic benchmarks and a 3.9-point gain over Nemotron-Terminal-32B while also showing superior scaling behavior at every dataset size.
What carries the argument
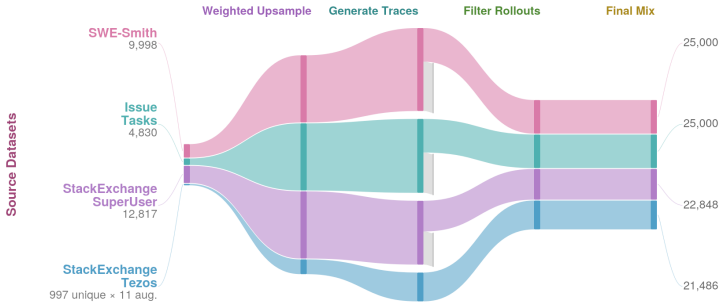
The OT-Agent data curation pipeline, which selects and balances examples from multiple task sources after ablation-driven tuning of diversity and quality filters.
If this is right
- Training sets built with the same pipeline will continue to outperform alternative open collections at every scale.
- The released 100K examples and pipeline code enable direct replication and further scaling experiments.
- Insights from the ablations on task sources can be reused to curate data for additional agent domains.
- Models trained this way exhibit measurable transfer across the tested benchmarks rather than overfitting to one.
Where Pith is reading between the lines
- The same curation logic could be applied to smaller or larger base models to test whether the diversity benefit persists.
- Public release of the full experimental logs allows others to identify which task sources contributed most to the observed gains.
- If real deployments involve tool-use patterns absent from the seven benchmarks, additional targeted sources may still be needed.
Load-bearing premise
The seven chosen agentic benchmarks are representative enough of the broader space of agent tasks that gains on them will appear on new, unseen workloads.
What would settle it
Run the released fine-tuned model on a fresh agentic benchmark outside the original seven and observe no accuracy improvement relative to the prior open baseline.
Figures

read the original abstract
Agentic language models dramatically expand the applications of AI yet little is publicly known about how to curate training data for broadly capable agents. Existing open efforts such as SWE-Smith, SERA, and Nemotron-Terminal typically target a single benchmark, leaving open the question of how to train models that generalize across diverse agentic tasks. The OpenThoughts-Agent (OT-Agent) project addresses this gap with a fully open data curation pipeline for training agentic models. We conduct more than 100 controlled ablation experiments to systematically investigate each stage of the pipeline, yielding insights on the importance of task sources and diversity. We then assemble a training set of 100K examples from our pipeline and fine-tune Qwen3-32B on this dataset, which yields an average accuracy of 44.8% across seven agentic benchmarks and a 3.9 percentage point improvement over the strongest existing open data agentic model (Nemotron-Terminal-32B, 40.9%). Moreover, our training data exhibits strong scaling properties, outperforming alternative open datasets at every training set size in compute-controlled comparisons. We publicly release our training sets, data pipeline, experimental data, and models at openthoughts.ai to support future open research on agentic model training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OpenThoughts-Agent, a fully open data curation pipeline for training agentic language models. It reports over 100 controlled ablation experiments on task sources and diversity, assembles a 100K-example training set, and fine-tunes Qwen3-32B to achieve 44.8% average accuracy across seven agentic benchmarks (a 3.9pp gain over Nemotron-Terminal-32B at 40.9%). The work also claims strong scaling properties relative to alternative open datasets and publicly releases the training sets, pipeline, experimental data, and models.
Significance. If the empirical results hold under scrutiny, the work offers a practical, reproducible recipe for curating agentic training data and provides systematic ablation insights into the roles of task sources and diversity. The public release of all artifacts is a clear strength that directly supports community follow-up and verification. The scaling comparisons and multi-benchmark gains, if statistically robust, would be useful for practitioners building open agentic models.
major comments (3)
- [Abstract / Evaluation] Abstract and evaluation protocol: The central generalization claim—that the pipeline produces models that 'generalize across diverse agentic tasks'—rests on performance across seven benchmarks, yet the manuscript provides no external validation set, out-of-distribution agentic workloads, or analysis of potential overlap between the 100K training examples and the evaluation benchmarks. Without such checks, the 3.9pp improvement could reflect benchmark-specific effects rather than broad capability.
- [Abstract / Ablations] Ablation experiments (abstract): The paper states that more than 100 controlled ablations were performed to investigate task sources and diversity, but supplies no details on statistical significance testing, error bars, run-to-run variance, or precise data-exclusion rules. These omissions make it impossible to assess whether the reported insights on pipeline stages are reliable or merely suggestive.
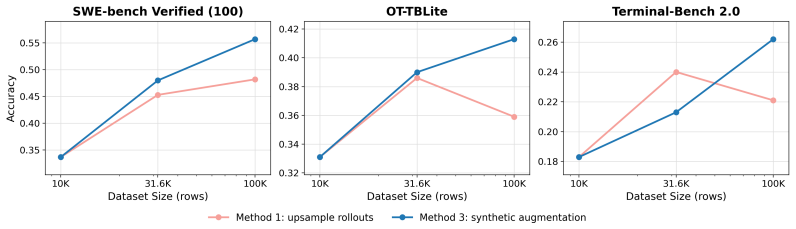
- [Abstract / Scaling] Scaling properties claim (abstract): The assertion that the training data 'exhibits strong scaling properties, outperforming alternative open datasets at every training set size in compute-controlled comparisons' is load-bearing for the data-recipe contribution, yet the manuscript does not specify the exact compute controls, the alternative datasets used, or the functional form of the scaling curves.
minor comments (2)
- [Abstract] The abstract refers to 'seven agentic benchmarks' without naming them or providing a table of per-benchmark scores; adding this information would improve clarity.
- [Abstract] Notation for model names (e.g., Qwen3-32B, Nemotron-Terminal-32B) should be defined consistently on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments identify important areas for strengthening the claims around generalization, ablation reliability, and scaling comparisons. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation protocol: The central generalization claim—that the pipeline produces models that 'generalize across diverse agentic tasks'—rests on performance across seven benchmarks, yet the manuscript provides no external validation set, out-of-distribution agentic workloads, or analysis of potential overlap between the 100K training examples and the evaluation benchmarks. Without such checks, the 3.9pp improvement could reflect benchmark-specific effects rather than broad capability.
Authors: We agree that explicit checks for overlap and out-of-distribution performance would better support the generalization claim. The seven benchmarks were selected to span distinct agentic domains (e.g., code editing, terminal use, web navigation), and the 3.9pp gain is measured against a baseline trained on the same evaluation suite. In the revision we will add an n-gram and embedding-based overlap analysis between the 100K training set and each benchmark, plus results on at least one additional held-out agentic workload if a suitable public one can be identified. This addresses the concern directly without altering the core empirical results. revision: yes
-
Referee: [Abstract / Ablations] Ablation experiments (abstract): The paper states that more than 100 controlled ablations were performed to investigate task sources and diversity, but supplies no details on statistical significance testing, error bars, run-to-run variance, or precise data-exclusion rules. These omissions make it impossible to assess whether the reported insights on pipeline stages are reliable or merely suggestive.
Authors: The 100+ ablations followed a controlled design varying one factor at a time while holding others fixed, but we omitted variance estimates and exclusion criteria in the initial draft. We will revise the relevant sections to report standard deviations from repeated runs (where compute permitted), describe the exact data-exclusion heuristics applied at each pipeline stage, and note any cases where single-run results are presented. These additions will make the reliability of the task-source and diversity insights clearer. revision: yes
-
Referee: [Abstract / Scaling] Scaling properties claim (abstract): The assertion that the training data 'exhibits strong scaling properties, outperforming alternative open datasets at every training set size in compute-controlled comparisons' is load-bearing for the data-recipe contribution, yet the manuscript does not specify the exact compute controls, the alternative datasets used, or the functional form of the scaling curves.
Authors: The scaling experiments matched total training tokens across datasets and used the same base model and optimizer settings. Alternative datasets were SWE-Smith, SERA, and Nemotron-Terminal subsets. Curves were plotted as accuracy versus log(training-set size). We will expand the scaling section to state these controls explicitly, enumerate the comparison datasets, and specify the functional form (log-linear fits with reported R^{2} values). This will make the 'strong scaling properties' claim fully reproducible from the text. revision: yes
Circularity Check
No circularity: empirical results on held-out benchmarks
full rationale
The paper describes an empirical data curation pipeline producing 100K examples, supported by >100 internal ablations on task sources and diversity. The headline result (44.8% average accuracy on seven agentic benchmarks after fine-tuning Qwen3-32B) is obtained by direct evaluation on separate benchmarks, with no equations, fitted parameters renamed as predictions, or self-citations invoked to derive the metric. Performance is measured externally rather than reduced to inputs by construction. No self-definitional, uniqueness, or ansatz patterns appear. This is a standard empirical ML study whose central claims remain independent of the reported numbers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The seven agentic benchmarks adequately sample the space of tasks that matter for generalization.
Reference graph
Works this paper leans on
-
[1]
Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12248–12267, 2024
2024
-
[2]
o1 tops aider’s new polyglot leaderboard
Aider. o1 tops aider’s new polyglot leaderboard. https://aider.chat/2024/12/21/ polyglot.html, December 2024. Aider blog post. Introduces the Polyglot coding-edit bench- mark covering C++, Go, Java, JavaScript, Python, and Rust across 225 exercises. Accessed 2026-05-18
2024
-
[3]
Coderforge-preview: Sota open dataset for training efficient agents, February 2026
Alpay Ariyak, Junda Zhang, Junxiong Wang, Shang Zhu, Federico Bianchi, Sanjana Srivastava, Ashwinee Panda, Siddhant Bharti, Chenfeng Xu, John Heo, Xiaoxia Shirley Wu, James Zhou, Percy Liang, Leon Song, Ce Zhang, Ben Athiwaratkun, Zhongzhu Zhou, and Qingyang Wu. Coderforge-preview: Sota open dataset for training efficient agents, February 2026. Project co...
2026
-
[4]
Arctic long sequence training: Scalable and efficient training for multi-million token sequences, 2025
Stas Bekman, Samyam Rajbhandari, Michael Wyatt, Jeff Rasley, Tunji Ruwase, Zhewei Yao, Aurick Qiao, and Yuxiong He. Arctic long sequence training: Scalable and efficient training for multi-million token sequences, 2025
2025
-
[5]
Llama-nemotron: Efficient reasoning models, 2025
Akhiad Bercovich, Itay Levy, Izik Golan, Mohammad Dabbah, Ran El-Yaniv, Omri Puny, Ido Galil, Zach Moshe, Tomer Ronen, Najeeb Nabwani, Ido Shahaf, Oren Tropp, Ehud Karpas, Ran Zilberstein, Jiaqi Zeng, Soumye Singhal, Alexander Bukharin, Yian Zhang, Tugrul Konuk, Ger- ald Shen, Ameya Sunil Mahabaleshwarkar, Bilal Kartal, Yoshi Suhara, Olivier Delalleau, Zi...
2025
-
[6]
Finance agent bench- mark: Benchmarking llms on real-world financial research tasks, 2025
Antoine Bigeard, Langston Nashold, Rayan Krishnan, and Shirley Wu. Finance agent bench- mark: Benchmarking llms on real-world financial research tasks, 2025
2025
-
[7]
Gonzalez, and Ion Stoica
Shiyi Cao, Sumanth Hegde, Dacheng Li, Tyler Griggs, Shu Liu, Eric Tang, Jiayi Pan, Xingyao Wang, Akshay Malik, Graham Neubig, Kourosh Hakhamaneshi, Richard Liaw, Philipp Moritz, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Skyrl-v0: Train real-world long-horizon agents via reinforcement learning, 2025
2025
-
[8]
Hegde, Connor Chen, Charlie Ruan, Tyler Griggs, Shu Liu, Eric Tang, Richard Liaw, Philipp Moritz, Matei Zaharia, Joseph E
Shiyi Cao, Dacheng Li, Fangzhou Zhao, Shuo Yuan, Sumanth R. Hegde, Connor Chen, Charlie Ruan, Tyler Griggs, Shu Liu, Eric Tang, Richard Liaw, Philipp Moritz, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Skyrl-agent: Efficient rl training for multi-turn llm agent, 2025
2025
-
[9]
Daytona: Secure and elastic infrastructure for running ai-generated code, 2026
Daytona Platforms, Inc. Daytona: Secure and elastic infrastructure for running ai-generated code, 2026
2026
-
[10]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[11]
davinci-env: Openswe environment synthesis at scale, 2026
Dayuan Fu, Shenyu Wu, Yunze Wu, Zerui Peng, Yaxing Huang, Jie Sun, Ji Zeng, Mohan Jiang, Lin Zhang, Yukun Li, Jiarui Hu, Liming Liu, Jinlong Hou, and Pengfei Liu. davinci-env: Openswe environment synthesis at scale, 2026
2026
-
[12]
Dimakis, Jenia Jitsev, Yair Carmon, Vaishaal Shankar, and Ludwig Schmidt
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, Eyal Orgad, Rahim Entezari, Giannis Daras, Sarah Pratt, Vivek Ramanujan, Yonatan Bitton, Kalyani Marathe, Stephen Mussmann, Richard Vencu, Mehdi Cherti, Ranjay Krishna, Pang Wei Koh, Olga Saukh, Alexan...
2023
-
[13]
Goodman, and Dimitris Papailiopoulos
Kanishk Gandhi, Shivam Garg, Noah D. Goodman, and Dimitris Papailiopoulos. Endless terminals: Scaling rl environments for terminal agents, 2026
2026
-
[14]
Glm-5: from vibe coding to agentic engineering, 2026
GLM-5-Team, :, Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, Chenzheng Zhu, Congfeng Yin, Cunx- iang Wang, Gengzheng Pan, Hao Zeng, Haoke Zhang, Haoran Wang, Huilong Chen, Jiajie Zhang, Jian Jiao, Jiaqi Guo, Jingsen Wang, Jingzhao Du, Jinzhu Wu, Kedong Wang, Lei Li, Lin Fan, Lucen Z...
2026
-
[15]
Gonzalez, and Ion Stoica
Tyler Griggs, Sumanth Hegde, Eric Tang, Shu Liu, Shiyi Cao, Dacheng Li, Charlie Ruan, Philipp Moritz, Kourosh Hakhamaneshi, Richard Liaw, Akshay Malik, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Evolving skyrl into a highly-modular rl framework, 2025. Notion Blog
2025
-
[16]
Merrill, Tatsunori Hashimoto, Yejin Choi, Jenia Jitsev, Reinhard Heckel, Maheswaran Sathiamoorthy, Alexandros G
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Benjamin Feuer, Liangyu Chen, Zaid Khan, Eric Frankel, Sachin Grover, Caroline Choi, Niklas Muennighoff, Shiye Su, Wanjia Zhao, John Yang, Shreyas Pimpalgaonkar, Kartik Sharma, Charlie Cheng-Jie Ji, ...
2025
-
[17]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
2025
-
[18]
Harbor: A framework for evaluating and optimizing agents and models in container environments, January 2026
Harbor Framework Team. Harbor: A framework for evaluating and optimizing agents and models in container environments, January 2026
2026
-
[19]
Qwen2.5-coder technical report, 2024
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5-coder technical report, 2024. 14
2024
-
[20]
Tmax: A simple recipe for terminal agents, 2026
Hamish Ivison, Junjie Oscar Yin, Rulin Shao, Teng Xiao, Nathan Lambert, and Hannaneh Hajishirzi. Tmax: A simple recipe for terminal agents, 2026
2026
-
[21]
R2e- gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents, 2025
Naman Jain, Jaskirat Singh, Manish Shetty, Liang Zheng, Koushik Sen, and Ion Stoica. R2e- gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents, 2025
2025
-
[22]
Medagentbench: A virtual ehr environment to benchmark medical llm agents
Yixing Jiang, Kameron C Black, Gloria Geng, Danny Park, James Zou, Andrew Y Ng, and Jonathan H Chen. Medagentbench: A virtual ehr environment to benchmark medical llm agents. NEJM AI, page AIdbp2500144, 2025
2025
-
[23]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?, 2024
2024
-
[24]
Quagmires in sft-rl post-training: When high sft scores mislead and what to use instead, 2025
Feiyang Kang, Michael Kuchnik, Karthik Padthe, Marin Vlastelica, Ruoxi Jia, Carole-Jean Wu, and Newsha Ardalani. Quagmires in sft-rl post-training: When high sft scores mislead and what to use instead, 2025
2025
-
[25]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[26]
Dimakis, Yair Carmon, Achal Dave, Ludwig Schmidt, and Vaishaal Shankar
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Reinhard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, Dhruba Ghosh, Josh Gardn...
2025
-
[27]
Deepswe: Training a state-of-the-art coding agent from scratch by scaling rl
Michael Luo, Naman Jain, Jaskirat Singh, Sijun Tan, Ameen Patel, Qingyang Wu, Alpay Ariyak, Colin Cai, Tarun Venkat, Shang Zhu, Ben Athiwaratkun, Manan Roongta, Ce Zhang, Li Erran Li, Raluca Ada Popa, Koushik Sen, and Ion Stoica. Deepswe: Training a state-of-the-art coding agent from scratch by scaling rl. https://www.together.ai/blog/deepswe, 2025. Notion Blog
2025
-
[28]
Merrill, Alexander G
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Me- nis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, ...
2026
-
[29]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023. 15
2023
-
[30]
Train your terminal-use agent with SkyRL + Harbor
NovaSky AI Team. Train your terminal-use agent with SkyRL + Harbor. https:// novasky-ai.notion.site/skyrl-harbor, February 2026. Blog post, UC Berkeley Sky Computing Lab in collaboration with Anyscale and Laude Institute
2026
-
[31]
NVIDIA, :, Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khattar, Adi Renduchintala, Aditya Vavre, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, Aleksandr Shaposhnikov, Alex Kondratenko, Alexander Bukharin, Alexandre Milesi, Ali Taghibakhshi, Alisa Liu, Amelia Barton, Ameya Sunil Mahabaleshwarkar, Amir Klein, Amit Zuker, A...
2025
-
[32]
OpenThoughts- TBLite: A High-Signal Benchmark for Iterating on Terminal Agents
OpenThoughts-Agent team, Snorkel AI, and Bespoke Labs. OpenThoughts- TBLite: A High-Signal Benchmark for Iterating on Terminal Agents. https://www.openthoughts.ai/blog/openthoughts-tblite, February 2026
2026
-
[33]
The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning (ICML), 2025
2025
-
[34]
Litecoder: Advancing small and medium-sized code agents, 2026
Xiaoxuan Peng, Xinyu Lu, Kaiqi Zhang, Taosong Fang, Boxi Cao, and Yaojie Lu. Litecoder: Advancing small and medium-sized code agents, 2026
2026
-
[35]
On data engineering for scaling llm terminal capabilities, 2026
Renjie Pi, Grace Lam, Mohammad Shoeybi, Pooya Jannaty, Bryan Catanzaro, and Wei Ping. On data engineering for scaling llm terminal capabilities, 2026
2026
-
[36]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
2026
-
[37]
Evalchemy, 2025
Negin Raoof, Etash Kumar Guha, Ryan Marten, Jean Mercat, Eric Frankel, Sedrick Keh, Hritik Bansal, Georgios Smyrnis, Marianna Nezhurina, Trung Vu, Zayne Rea Sprague, Mike A Merrill, Liangyu Chen, Caroline Choi, Zaid Khan, Sachin Grover, Benjamin Feuer, Ashima Suvarna, Shiye Su, Wanjia Zhao, Kartik Sharma, Charlie Cheng-Jie Ji, Kushal Arora, Jeffrey Li, Aa...
2025
-
[38]
Sera: Soft-verified efficient repository agents, 2026
Ethan Shen, Danny Tormoen, Saurabh Shah, Ali Farhadi, and Tim Dettmers. Sera: Soft-verified efficient repository agents, 2026
2026
-
[39]
SETA: Scaling Environments for Ter- minal Agents, January 2026
Qijia Shen, Jay Rainton, Aznaur Aliev, Ahmed Awelkair, Boyuan Ma, Zhiqi (Julie) Huang, Yuzhen Mao, Wendong Fan, Philip Torr, Bernard Ghanem, Changran Hu, Urmish Thakker, and Guohao Li. SETA: Scaling Environments for Ter- minal Agents, January 2026. Blog: https://eigent-ai.notion.site/ SETA-Scaling-Environments-for-Terminal-Agents-2d2511c70ba280a9b7c0fe3e7f1b6ab8
2026
-
[40]
Swe-lego: Pushing the limits of supervised fine-tuning for software issue resolving, 2026
Chaofan Tao, Jierun Chen, Yuxin Jiang, Kaiqi Kou, Shaowei Wang, Ruoyu Wang, Xiaohui Li, Sidi Yang, Yiming Du, Jianbo Dai, Zhiming Mao, Xinyu Wang, Lifeng Shang, and Haoli Bai. Swe-lego: Pushing the limits of supervised fine-tuning for software issue resolving, 2026
2026
-
[41]
Glm-4.5: Agentic, reasoning, and coding (arc) foundation models, 2025
GLM Team, Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, Lucen Zhong, Mingdao Liu, Rui Lu, Shulin Cao, Xiaohan Zhang, Xuancheng Huang, Yao Wei, Yean Cheng, Yifan An, Yilin Niu, Yuanhao Wen, Yushi Bai, Zhengxiao Du, Zihan Wang, Zilin Zhu, Bohan Zhang, Bosi Wen, Bowen Wu, Bo...
2025
-
[42]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, S. H. Cai, Yuan Cao, Y . Charles, H. S. Che, Cheng Chen, Guanduo Chen, Huarong Chen, Jia Chen, Jiahao Chen, Jianlong Chen, Jun Chen, Kefan Chen, Liang Chen, Ruijue Chen, Xinhao Chen, Yanru Chen, Yanxu Chen, Yicun Chen, Yimin Chen, Yingjiang Chen, Yuankun Chen, Yujie Chen, Yutian Chen, Zhirong Chen, Ziwei Che...
2026
-
[43]
Terminal-bench 2.1
The Terminal-Bench Team. Terminal-bench 2.1. https://www.tbench.ai/news/ terminal-bench-2-1, May 2026
2026
-
[44]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, 18 Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. Openhands: An open platform for AI s...
2025
-
[45]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[46]
SWE-agent: Agent-computer interfaces enable automated soft- ware engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated soft- ware engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[47]
Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang
John Yang, Kilian Lieret, Carlos E. Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. Swe-smith: Scaling data for software engineering agents, 2025
2025
-
[48]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[49]
davinci-dev: Agent-native mid-training for software engineering, 2026
Ji Zeng, Dayuan Fu, Tiantian Mi, Yumin Zhuang, Yaxing Huang, Xuefeng Li, Lyumanshan Ye, Muhang Xie, Qishuo Hua, Zhen Huang, Mohan Jiang, Hanning Wang, Jifan Lin, Yang Xiao, Jie Sun, Yunze Wu, and Pengfei Liu. davinci-dev: Agent-native mid-training for software engineering, 2026
2026
-
[50]
LlamaFactory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. LlamaFactory: Unified efficient fine-tuning of 100+ language models. In Yixin Cao, Yang Feng, and Deyi Xiong, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 400–410, Bangkok, Thailand, August
-
[51]
19 A Full SFT Pipeline Ablation Tables 21 A.1 Task Generation Strategies (Full Ranking)
Association for Computational Linguistics. 19 A Full SFT Pipeline Ablation Tables 21 A.1 Task Generation Strategies (Full Ranking) . . . . . . . . . . . . . . . . . . . . . . 21 A.2 Mixing Strategies (Full Results) . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 A.3 Filtering for Longer Episodes: A Compute-Controlled Ablation . . . . . . . . . . ...
2026
-
[52]
more verbose,
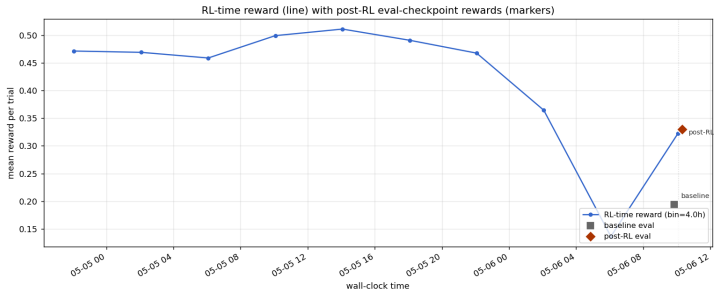
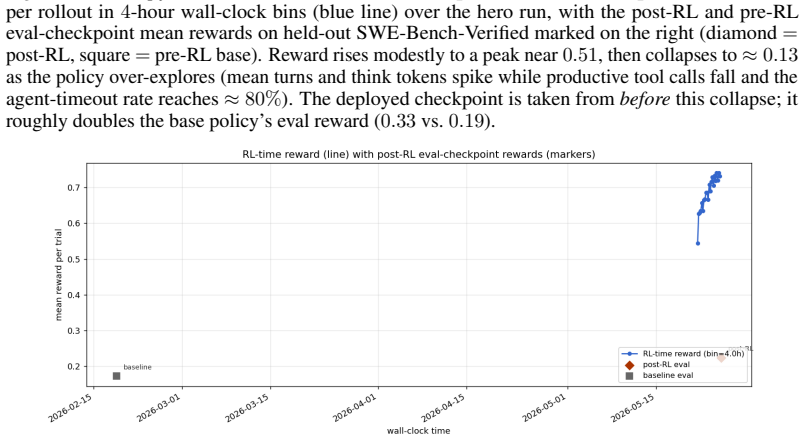
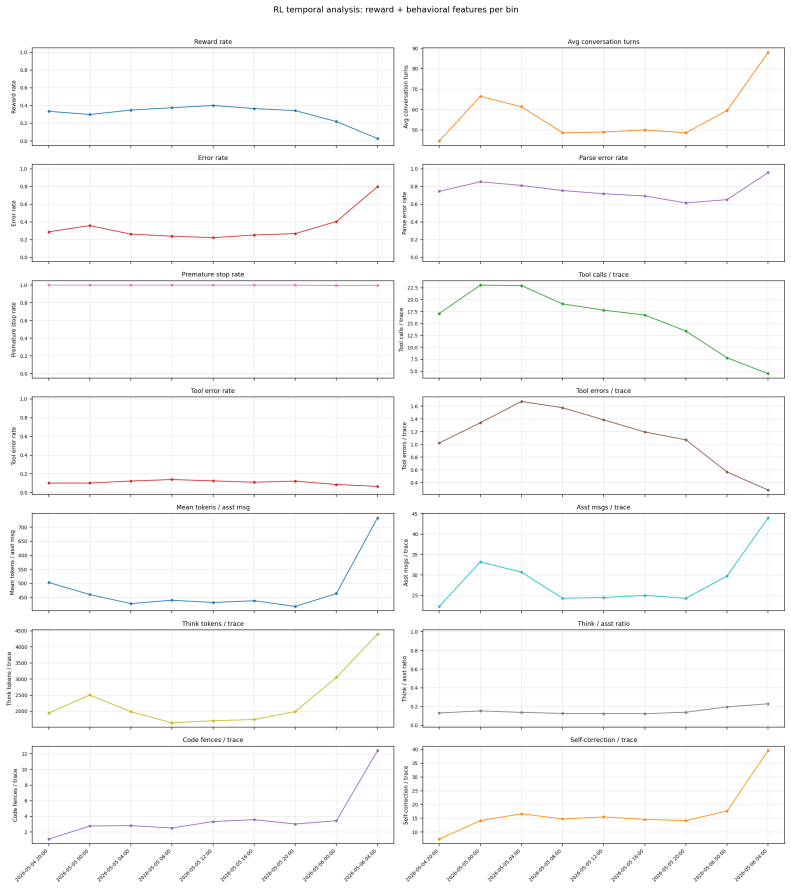
for environment, benchmark and harness management. E RL Run-to-Run Reproducibility A natural concern for any RL result is how much of the reported improvement is signal versus run-to-run noise in the training pipeline. To probe this, we evaluate three near-replicate RL runs of the pymethods2test experiment. All three start from the same GLM-4.7-distilled ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.