From Verdict to Process: Agentic Reinforcement Learning for Multi-Stage Fact Verification
Pith reviewed 2026-06-27 06:45 UTC · model grok-4.3
The pith
A unified reinforcement learning policy coordinates the full multi-stage fact verification workflow with process-aware rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
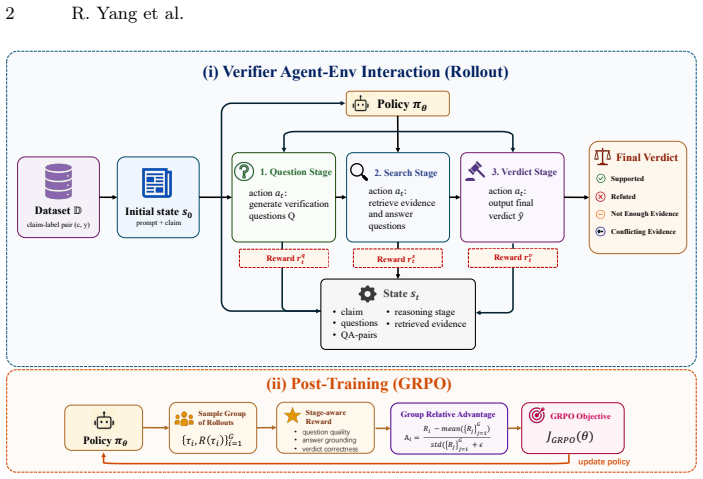
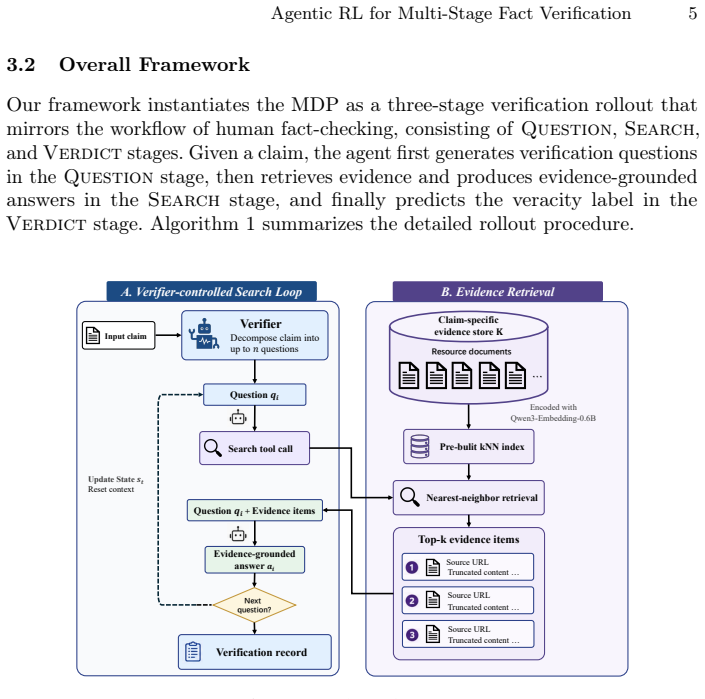
ProFact trains a unified policy via agentic reinforcement learning to coordinate claim decomposition, evidence seeking, answer generation, and verdict prediction in multi-stage fact verification. Process-aware rewards supply stage-level learning signals to address the sparse and delayed supervision from final veracity labels. The resulting end-to-end optimization consistently outperforms strong baselines in both verification performance and inference efficiency.
What carries the argument
The unified policy trained by agentic reinforcement learning together with process-aware rewards that deliver intermediate signals across the verification trajectory.
If this is right
- Adaptive coordination among stages replaces fixed heuristics and isolated optimization.
- Stage-level signals mitigate the sparsity of final veracity labels during training.
- End-to-end trajectory optimization yields both higher accuracy and lower inference cost.
- The same policy can adjust its behavior at any point based on earlier stage outcomes.
Where Pith is reading between the lines
- The same process-reward structure could be tested on other multi-step language-agent tasks such as multi-hop question answering.
- If the rewards require no extra labels, the approach reduces dependence on dense human feedback for training reasoning agents.
- The learned policy might reveal which stages most often cause verification failures, enabling targeted improvements.
Load-bearing premise
Process-aware rewards can be designed to give useful stage-level signals that improve final veracity prediction without introducing new biases or needing extra human labels.
What would settle it
An ablation that removes the process-aware rewards and measures whether the reported gains in accuracy and efficiency disappear or reverse on the same evaluation sets.
Figures
read the original abstract
Recent approaches combining Large Language Models (LLMs) with retrieval-augmented reasoning have shown promise for automated fact verification. To process complex claims, these verification pipelines typically execute multi-stage workflows that coordinate tightly coupled modules, including claim decomposition, evidence gathering, and verdict prediction. However, existing methods optimize individual stages in isolation or rely on fixed heuristics, which limits adaptive coordination among stages and can lead to suboptimal outcomes. In this work, we propose ProFact, an agentic reinforcement learning framework for end-to-end optimization of multi-stage fact verification trajectories. ProFact trains a unified policy to coordinate claim decomposition, evidence seeking, answer generation, and verdict prediction. To address the sparse and delayed supervision provided by final veracity labels, ProFact introduces process-aware rewards that provide stage-level learning signals throughout the verification process. Empirical evaluation shows that ProFact consistently outperforms strong baselines in both verification performance and inference efficiency. These results highlight the effectiveness of process-aware trajectory optimization for multi-stage fact verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ProFact, an agentic reinforcement learning framework for end-to-end optimization of multi-stage fact verification. It trains a unified policy to coordinate claim decomposition, evidence seeking, answer generation, and verdict prediction. Process-aware rewards are proposed to provide stage-level learning signals to address the sparsity of final veracity labels. The paper claims that this leads to consistent outperformance over strong baselines in both verification performance and inference efficiency.
Significance. If the results hold, the work could contribute to the field by demonstrating the value of process-aware rewards in agentic RL for complex reasoning tasks, potentially leading to more efficient and accurate automated fact verification systems.
major comments (1)
- [§4.2] §4.2 (Reward Formulation): The process-aware rewards are introduced specifically to address sparse final labels; without the explicit reward formulation, it is unclear whether they reduce to functions of the final veracity label itself, which would undermine the claim of providing additional stage-level signals.
minor comments (1)
- [Abstract] Abstract: The claim of outperformance is stated without reference to the specific datasets, baselines, metrics, or statistical tests used, which limits immediate assessment of the empirical contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the single major comment below and will revise the paper to incorporate the requested clarification.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Reward Formulation): The process-aware rewards are introduced specifically to address sparse final labels; without the explicit reward formulation, it is unclear whether they reduce to functions of the final veracity label itself, which would undermine the claim of providing additional stage-level signals.
Authors: We agree that the explicit mathematical formulation of the process-aware rewards should have been included in §4.2. The rewards are constructed as a weighted sum of stage-specific terms: R_decomp based on sub-claim quality (coverage, non-redundancy), R_retrieve based on evidence relevance and sufficiency per sub-claim (independent of the final verdict), and R_verdict based on veracity accuracy. These intermediate terms are not functions of the final label alone and are intended to supply dense signals. In the revision we will add the full equations, including the weighting scheme and how each term is computed from process traces, to make this explicit. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a standard agentic RL setup for multi-stage fact verification, introducing process-aware rewards to densify sparse final veracity labels. No equations, derivations, or self-citations are quoted that reduce any claimed prediction or result to its inputs by construction. The central claim of improved performance via unified policy and stage-level rewards is presented as an empirical outcome rather than a tautological redefinition or fitted-input prediction. No load-bearing self-citation chains, uniqueness theorems, or ansatz smuggling appear in the abstract or described content. This is a self-contained proposal whose validity rests on external benchmarks, not internal equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aly, R., Guo, Z., Schlichtkrull, M., Thorne, J., Vlachos, A., Christodoulopoulos, C., Cocarascu, O., Mittal, A.: The fact extraction and verification over unstructured and structured information (feverous) shared task (2021)
2021
-
[2]
Augenstein, I., Lioma, C., Wang, D., Lima, L.C., Hansen, C., Hansen, C., Simonsen, J.G.: Multifc: A real-world multi-domain dataset for evidence-based fact checking of claims (2019)
2019
-
[3]
Feng, L., Xue, Z., Liu, T., An, B.: Group-in-group policy optimization for llm agent training (2025),https://arxiv.org/abs/2505.10978
Pith/arXiv arXiv 2025
-
[4]
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning (2025)
2025
-
[5]
Guo, Z., Schlichtkrull, M., Vlachos, A.: A survey on automated fact-checking (2022)
2022
-
[6]
He, H., Li, Y., Wen, D., Chen, Y., Cheng, R., Chen, D., Lau, F.C.: Debating truth: Debate-driven claim verification with multiple large language model agents (2026)
2026
-
[7]
Jin, B., Zeng, H., Yue, Z., Yoon, J., Arik, S., Wang, D., Zamani, H., Han, J.: Search-r1: Training llms to reason and leverage search engines with reinforcement learning (2025),https://arxiv.org/abs/2503.09516 Agentic RL for Multi-Stage Fact Verification 13
Pith/arXiv arXiv 2025
-
[8]
Khaliq, M.A., Chang, P.Y.C., Ma, M., Pflugfelder, B., Miletić, F.: Ragar, your false- hood radar: Rag-augmented reasoning for political fact-checking using multimodal large language models (2024)
2024
-
[9]
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks (2020)
2020
-
[10]
arXiv preprint arXiv:2306.09479 (2023)
McKenzie, I.R., Lyzhov, A., Pieler, M., Parrish, A., Mueller, A., Prabhu, A., McLean, E., Kirtland, A., Ross, A., Liu, A., et al.: Inverse scaling: When bigger isn’t better. arXiv preprint arXiv:2306.09479 (2023)
arXiv 2023
-
[11]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., Lowe, R.: Training language models to follow instructions with human feedback (2022),https:// arxiv.org/abs/2203.02155
Pith/arXiv arXiv 2022
-
[12]
Rothermel, M., Braun, T., Rohrbach, M., Rohrbach, A.: Infact: A strong baseline for automated fact-checking (2024)
2024
-
[13]
Schlichtkrull, M., Guo, Z., Vlachos, A.: Averitec: A dataset for real-world claim verification with evidence from the web (2023)
2023
-
[14]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y.K., Wu, Y., Guo, D.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models (2024),https://arxiv.org/abs/2402.03300
Pith/arXiv arXiv 2024
-
[15]
Thorne, J., Vlachos, A., Cocarascu, O., Christodoulopoulos, C., Mittal, A.: The fact extraction and verification (fever) shared task (2018)
2018
-
[16]
Vykopal, I., Pikuliak, M., Ostermann, S., Šimko, M.: Generative large language models in automated fact-checking: A survey (2024)
2024
-
[17]
Wang, Z., Wang, K., Wang, Q., Zhang, P., Li, L., Yang, Z., Jin, X., Yu, K., Nguyen, M.N., Liu, L., Gottlieb, E., Lu, Y., Cho, K., Wu, J., Fei-Fei, L., Wang, L., Choi, Y., Li, M.: Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning (2025),https://arxiv.org/abs/2504.20073
Pith/arXiv arXiv 2025
-
[18]
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models (2022)
2022
-
[19]
Xia, T., Xu, M., Hu, L., Sun, Y., Li, W., Shang, L., Liu, L., Shu, P., Yu, H., Jiang, J.: Search-p1: Path-centric reward shaping for stable and efficient agentic rag training (2026)
2026
-
[20]
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y.: React: Synergizing reasoning and acting in language models (2022)
2022
-
[21]
Yoon, Y., Jung, J., Yoon, S., Park, K.: Hero at averitec: The herd of open large language models for verifying real-world claims (2024)
2024
-
[22]
Zhang, X., Gao, W.: Towards llm-based fact verification on news claims with a hierarchical step-by-step prompting method (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.