Gradient-Discrepancy Acquisition for Pool-Based Active Learning
Pith reviewed 2026-05-19 17:15 UTC · model grok-4.3
The pith
A gradient-discrepancy measure derived from a generalization bound serves as an effective acquisition criterion for pool-based active learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that a novel gradient-discrepancy acquisition criterion, derived from the generalization bound of Luo et al. (2022), can be applied in lieu of uncertainty measures in uncertainty sampling or incorporated into diversity-based methods, supported by theoretical justification and empirical evaluation on its effectiveness.
What carries the argument
The gradient-discrepancy acquisition criterion, which quantifies the discrepancy induced in model gradients by candidate points to guide selection toward those most reducing the generalization bound.
Load-bearing premise
The generalization bound from Luo et al. (2022) can be directly leveraged to create an acquisition criterion that effectively identifies informative points beyond standard uncertainty or diversity measures.
What would settle it
Experiments on standard benchmarks where the gradient-discrepancy criterion selects points that yield no better or worse model performance than random sampling or conventional uncertainty sampling after a fixed number of queries would falsify the central claim.
Figures











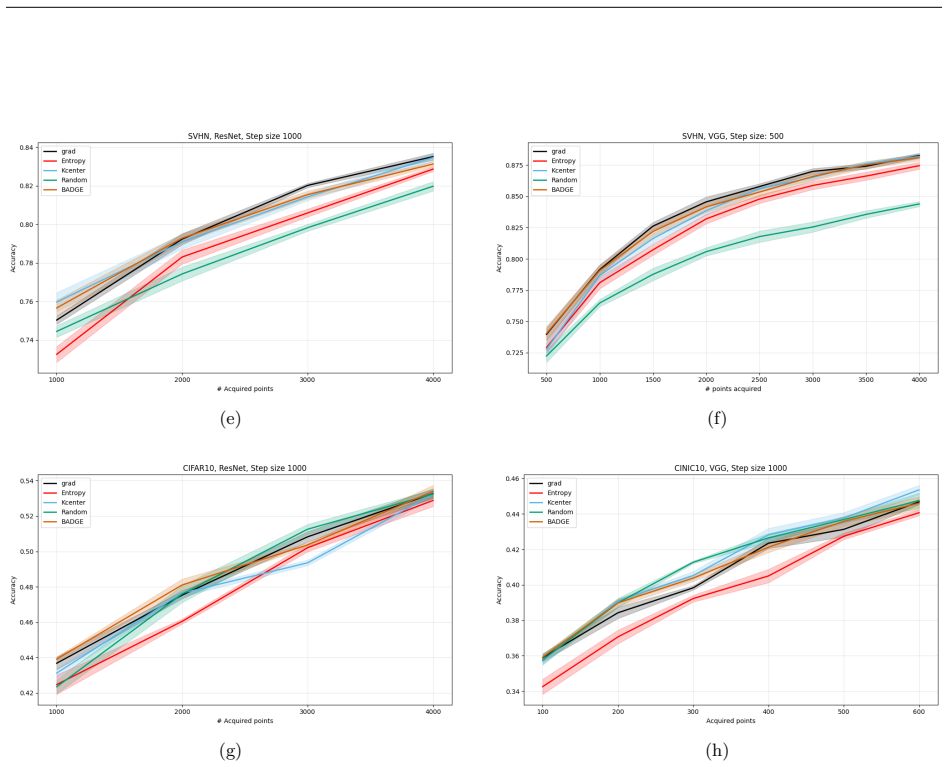





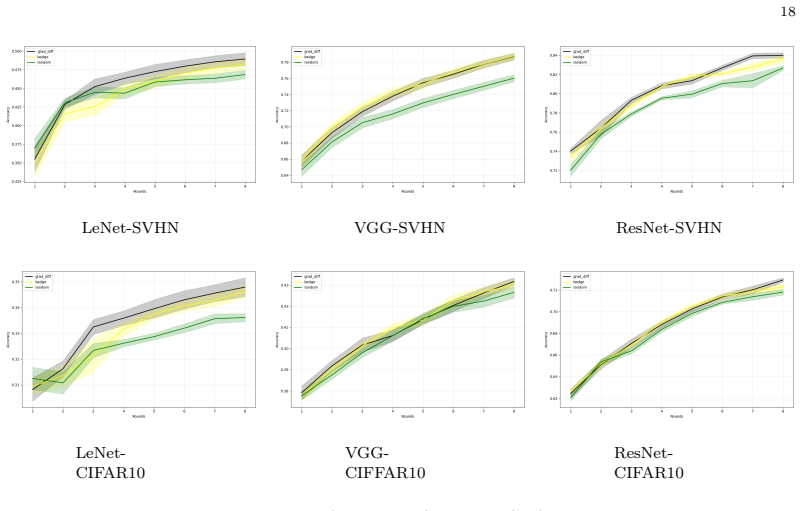
read the original abstract
The effectiveness of active learning hinges on the choice of the acquisition criterion by which a learning algorithm selects potentially informative data points whose label is subsequently queried. This paper proposes a novel gradient-based acquisition criterion, derived from a generalization bound introduced by Luo et al. (2022). This criterion can be applied in lieu of uncertainty measures in uncertainty sampling, or incorporated into diversity-based methods that consider the spread of sampled points in addition to the uncertainty of their labels. We provide a theoretical justification of the proposed acquisition criterion, and demonstrate its effectiveness in an empirical evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel gradient-discrepancy acquisition criterion for pool-based active learning, derived from a generalization bound introduced by Luo et al. (2022). This criterion is intended to replace uncertainty measures in uncertainty sampling or to be combined with diversity-based methods. The authors provide a theoretical justification for the criterion and demonstrate its effectiveness through empirical evaluation on standard benchmarks.
Significance. If the derivation is valid and the empirical gains are robust, the work would offer a theoretically grounded alternative to standard acquisition functions by directly leveraging an external generalization bound, which could improve sample efficiency in active learning settings where uncertainty or diversity heuristics fall short.
major comments (2)
- [Method section (derivation of gradient-discrepancy criterion)] The derivation of the gradient-discrepancy acquisition function from the Luo et al. (2022) bound (detailed in the method section) does not establish that the bound remains informative or non-vacuous once the labeled set is iteratively expanded by the proposed criterion. The original bound applies to a single training run on a fixed dataset; no argument or analysis is supplied showing that minimization of the derived acquisition function preserves the bound's utility for reducing true risk across multiple AL rounds.
- [Experiments section] The empirical evaluation does not include an analysis of how the tightness or validity of the underlying generalization bound evolves over successive acquisition rounds under the paper's training regime, which is required to support the central claim that the criterion identifies points that reduce risk faster than baselines.
minor comments (2)
- [Method section] Notation for the gradient discrepancy term and its relation to the bound could be introduced with an explicit equation early in the method section to improve readability.
- [Abstract] The abstract states that the criterion 'can be applied in lieu of uncertainty measures' but does not specify the exact substitution rule or hyper-parameters involved in the replacement.
Simulated Author's Rebuttal
We are grateful to the referee for their constructive comments, which have helped us identify areas where the manuscript can be improved. We respond to each major comment in turn and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Method section (derivation of gradient-discrepancy criterion)] The derivation of the gradient-discrepancy acquisition function from the Luo et al. (2022) bound (detailed in the method section) does not establish that the bound remains informative or non-vacuous once the labeled set is iteratively expanded by the proposed criterion. The original bound applies to a single training run on a fixed dataset; no argument or analysis is supplied showing that minimization of the derived acquisition function preserves the bound's utility for reducing true risk across multiple AL rounds.
Authors: We appreciate this observation. Our derivation extracts the gradient-discrepancy term as a key component of the generalization bound from Luo et al. (2022), which we then use as an acquisition function to select points likely to minimize this term. In the pool-based active learning setting, the model is retrained from scratch or fine-tuned on the augmented labeled set after each round. By choosing points that reduce the discrepancy at the current model state, we aim to iteratively tighten the bound. That said, we did not provide a formal inductive argument showing the bound stays non-vacuous over rounds. In the revised manuscript, we will expand the method section with a discussion of this point, explaining that the per-round minimization targets the same term appearing in the bound and is therefore expected to maintain its relevance for risk reduction. revision: yes
-
Referee: [Experiments section] The empirical evaluation does not include an analysis of how the tightness or validity of the underlying generalization bound evolves over successive acquisition rounds under the paper's training regime, which is required to support the central claim that the criterion identifies points that reduce risk faster than baselines.
Authors: We agree that such an analysis would provide valuable additional evidence. Our current experiments demonstrate superior performance in terms of test accuracy and label efficiency on standard benchmarks. To directly address the referee's concern, we will add to the experiments section an evaluation of the generalization bound's value (or a proxy such as the gradient discrepancy) computed at each acquisition round for the proposed method and the baselines. This will illustrate how the bound evolves under our training regime and support the claim that our criterion leads to faster risk reduction. revision: yes
Circularity Check
Derivation from external Luo et al. (2022) bound provides independent grounding
full rationale
The paper's central acquisition criterion is explicitly derived from the generalization bound of Luo et al. (2022), an independent prior result with no author overlap. No equations reduce the proposed gradient-discrepancy measure to a fitted parameter, self-defined quantity, or self-citation chain. The theoretical justification and empirical claims rest on this external bound rather than tautological re-expression of the paper's own inputs or assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generalization bound introduced by Luo et al. (2022) is valid and applicable for deriving acquisition criteria.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define a gradient-discrepancy acquisition score inspired by the theoretical study of Luo et al. (2022)... st(x) = ||DF_θt (D_L ∪ Ŝ(x), Ŝ(x))||₂ (eq. 11, Algorithm 1)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A key term in equation 6 is the cumulative gradient-discrepancy sum... Assumption 1 (Monotone contraction of DF)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://archive.ics.uci.edu/ml/datasets/poker+hand. Accessed 2025-12-15. Adam Coates, Honglak Lee, and Andrew Y. Ng. Stl-10 dataset. Stanford University,
work page 2025
-
[2]
URLhttp: //cs.stanford.edu/~acoates/stl10. Accessed 2025-12-15. Ron Cole and Mark Fanty. Isolet [dataset]. UCI Machine Learning Repository,
work page 2025
-
[3]
URLhttps:// archive.ics.uci.edu/ml/datasets/isolet. Accessed 2025-12-15. Luke N. Darlow, Elliot J. Crowley, Antreas Antoniou, and Amos Storkey. Cinic-10 is not imagenet or cifar-10 [dataset],
work page 2025
-
[4]
URLhttps://datashare.ed.ac.uk/handle/10283/3192. Accessed 2025-12-15. Janez Demšar. Statistical comparisons of classifiers over multiple data sets.Journal of Machine Learning Research, 7:1–30,
work page 2025
-
[5]
Yarin Gal, Riashat Islam, and Zoubin Ghahramani
doi: 10.1007/s101070100263. Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep bayesian active learning with image data. In International conference on machine learning, pp. 1183–1192. PMLR,
-
[6]
Deep residual learning for image recognition,
doi: 10.1109/CVPR.2016.90. URLhttps://www.cv-foundation.org/openaccess/content_ cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf. KrishnaTeja Killamsetty, Durga Sivasubramanian, Baharan Mirzasoleiman, Ganesh Ramakrishnan, Abir De, and Rishabh K. Iyer. GRAD-MATCH: A gradient matching based data subset selection for efficient learning.CoRR, ab...
-
[7]
URLhttps://arxiv.org/abs/2103.00123. 13 Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto,
-
[8]
David Lowell, Zachary C. Lipton, and Byron C. Wallace. Practical obstacles to deploying active learning. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 21–30,
work page 2019
-
[10]
URLhttps://arxiv.org/abs/ 2107.07075. Jason Rennie. 20 newsgroups data set.https://qwone.com/~jason/20Newsgroups/,
-
[11]
Accessed 2025- 12-15. David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning representations by back- propagating errors.Nature, 323:533–536,
work page 2025
-
[12]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
doi: 10.1038/323533a0. URLhttps://www.nature. com/articles/323533a0. Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. arXiv preprint arXiv:1708.00489,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/323533a0
-
[13]
Karen Simonyan and Andrew Zisserman
URLhttps://proceedings.neurips.cc/paper_files/paper/2007/file/ a1519de5b5d44b31a01de013b9b51a80-Paper.pdf. Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. InInternational Conference on Learning Representations (ICLR),
work page 2007
-
[14]
Very Deep Convolutional Networks for Large-Scale Image Recognition
URLhttps://arxiv.org/abs/ 1409.1556. Johannes Stallkamp, Marc Schlipsing, Jan Salmen, and Christian Igel. Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition.Neural Networks, 32:323–332,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
doi: 10.1016/ j.neunet.2012.02.016. Joaquin Vanschoren, Jan N. van Rijn, Bernd Bischl, and Luis Torgo. Openml: Networked science in machine learning.SIGKDD Explorations, 15(2):49–60,
work page 2012
-
[16]
van Rijn, Bernd Bischl, and Luis Torgo
doi: 10.1145/2641190.2641198. 14 A Contraction of Gradient Discrepancy The following proposition gives sufficient local conditions under which Assumption 1 can hold. We then provide qualitative empirical evidence that a decreasing discrepancy trend can appear during training. Proposition A.1(Sufficient conditions for eventual contraction of gradient discr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.