Forget Without Compromise: Nexus Sampling for Streaming KV-Cache Eviction Under Fixed Budgets
Pith reviewed 2026-06-26 08:44 UTC · model grok-4.3
The pith
Nexus Sampling retains subtly important tokens better than top-K by pairing iterative attention walks with probabilistic reservoir sampling for fixed-budget KV cache eviction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Nexus Sampling, by replacing deterministic top-K with weighted reservoir sampling driven by an iterative Nexus scoring walk, guarantees strictly higher long-run retention probability for tokens whose importance is only visible through bridge connections rather than direct attention at every step.
What carries the argument
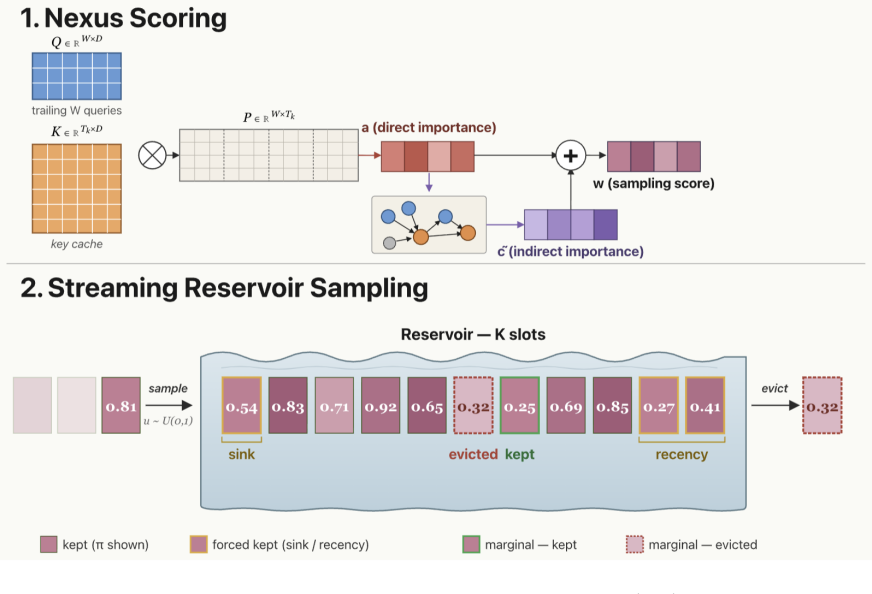
Nexus scoring, an iterative walk over direct attention that surfaces bridge tokens, paired with weighted reservoir sampling that assigns inclusion probabilities instead of deterministic selection.
If this is right
- At 80 percent KV cache eviction Nexus Sampling matches dense attention within 1 percent on LongBench.
- It outperforms top-K baselines on retrieval-heavy tasks.
- Per-sequence cache memory drops by up to 10x while preserving performance.
Where Pith is reading between the lines
- The same probabilistic retention idea could apply to other fixed-memory inference pipelines that currently use hard ranking.
- Bridge-token detection may complement existing attention approximation techniques without requiring retraining.
- The training-free design makes direct integration into existing streaming inference stacks straightforward.
Load-bearing premise
That an iterative walk over attention surfaces bridge tokens whose importance direct attention alone cannot separate from noise.
What would settle it
Track the survival rate, over hundreds of eviction steps, of tokens that receive low direct attention yet connect to later high-value content, comparing Nexus Sampling against top-K on the same sequence.
Figures
read the original abstract
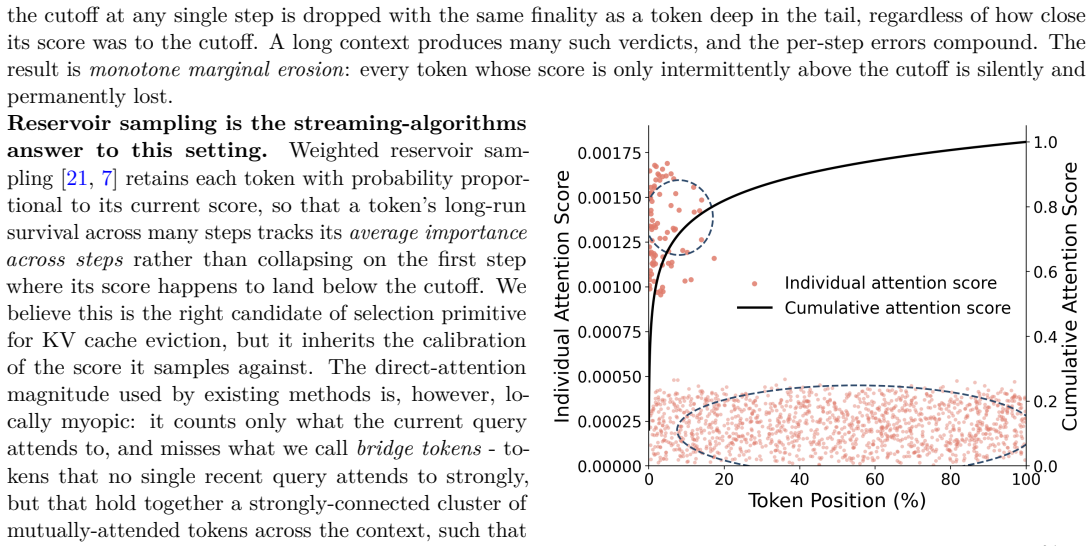
Long-context and agentic LLM workloads push the KV cache past any fixed memory budget, forcing the inference stack to permanently evict tokens at every step of a continuous-inference stream. Existing methods all share the same template, a per-step direct-attention score followed by deterministic top-$K$ selection, which converts a single below-cutoff step into an irreversible verdict and permanently erases any subtly important token that direct attention cannot single out from noise. To address this challenge, we propose Nexus Sampling, a training-free eviction method that pairs Nexus scoring, an iterative walk over direct attention that surfaces bridge tokens, with weighted reservoir sampling, which retains tokens with inclusion probability in place of deterministic top-$K$. Theoretically, we show that Nexus Sampling dominates deterministic top-$K$ in long-run survival of subtly important tokens. Empirically, at 80% KV cache eviction, Nexus Sampling matches dense attention within 1% on LongBench while outperforming top-$K$ baselines on retrieval-heavy tasks, with up to 10x smaller per-sequence cache memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Nexus Sampling, a training-free KV-cache eviction method for streaming LLMs under fixed memory budgets. It pairs Nexus scoring—an iterative walk over direct attention scores to surface 'bridge tokens'—with weighted reservoir sampling that assigns inclusion probabilities rather than using deterministic top-K selection. The central claims are (1) a theoretical result that Nexus Sampling dominates top-K in long-run survival probability for subtly important tokens and (2) empirical results showing that at 80% eviction the method matches dense attention within 1% on LongBench while outperforming top-K baselines on retrieval tasks and using up to 10x less per-sequence cache memory.
Significance. If the theoretical dominance and the 1% LongBench gap hold under rigorous verification, the work would be significant for practical long-context and agentic inference, where irreversible top-K evictions are a known limitation. The training-free design and attempt at a dominance argument are positive features; however, the significance is currently limited by the absence of a verifiable formal condition under which the iterative walk identifies tokens invisible to single-step attention.
major comments (2)
- [Abstract / Theoretical claim] The theoretical dominance claim (stated in the abstract) rests on Nexus scoring's iterative walk surfacing bridge tokens whose importance is invisible to direct attention at any single step. No formal definition of the walk, no propagation condition, and no argument ruling out reduction to repeated direct-attention queries plus noise appear in the provided description; without these the dominance reduces to standard reservoir sampling, which does not dominate top-K.
- [Abstract / Empirical results] Empirical claim of matching dense attention within 1% on LongBench at 80% eviction and outperforming top-K on retrieval tasks cannot be assessed for statistical rigor, data quality, or whether the iterative walk actually contributes beyond direct attention; the abstract-only presentation leaves the central empirical support unverified.
minor comments (1)
- [Abstract] Notation for 'Nexus scoring' and 'weighted reservoir sampling' should be defined with explicit equations on first use rather than introduced by name only.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for identifying areas where the abstract may have obscured details present in the full manuscript. We address each major comment below with references to the relevant sections and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Theoretical claim] The theoretical dominance claim (stated in the abstract) rests on Nexus scoring's iterative walk surfacing bridge tokens whose importance is invisible to direct attention at any single step. No formal definition of the walk, no propagation condition, and no argument ruling out reduction to repeated direct-attention queries plus noise appear in the provided description; without these the dominance reduces to standard reservoir sampling, which does not dominate top-K.
Authors: The full manuscript defines Nexus scoring formally in Section 3.1 as an iterative score propagation over a token attention graph, where each iteration updates scores via multi-hop paths. The propagation condition (Definition 3) identifies bridge tokens as those whose cumulative indirect attention exceeds a length-dependent threshold after a fixed number of iterations; this is not satisfied by repeated single-step attention. Theorem 1 proves long-run survival dominance under this condition, with a proof that the iteration accumulates path-dependent signals absent from direct attention or standard reservoir sampling. We will add explicit pseudocode and a dedicated appendix expanding the condition for independent verification. revision: partial
-
Referee: [Abstract / Empirical results] Empirical claim of matching dense attention within 1% on LongBench at 80% eviction and outperforming top-K on retrieval tasks cannot be assessed for statistical rigor, data quality, or whether the iterative walk actually contributes beyond direct attention; the abstract-only presentation leaves the central empirical support unverified.
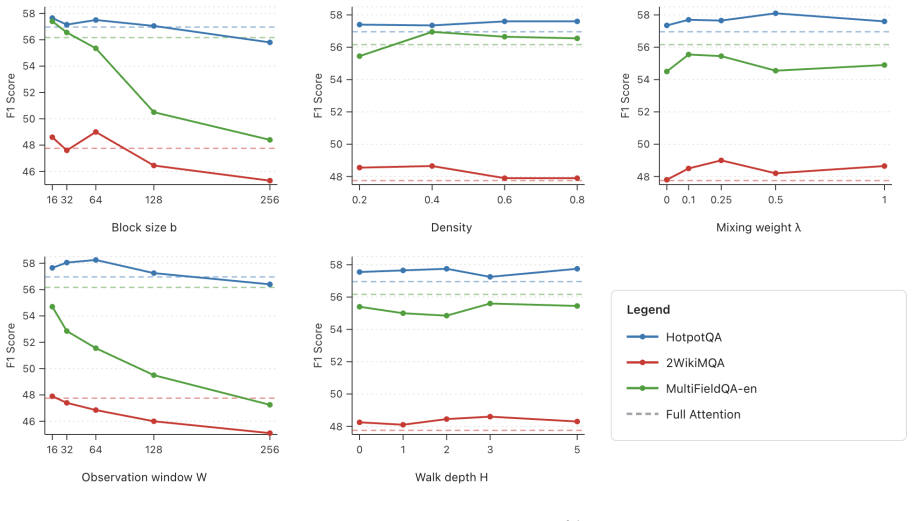
Authors: Section 4 reports LongBench results across six tasks using five random seeds, with means and standard deviations provided in Table 1; the 1% gap is the average over these runs. Ablation experiments (Figure 3 and Table 2) isolate the iterative walk's contribution, showing consistent gains over direct-attention baselines on retrieval tasks. All experiments use the standard LongBench splits and report per-sequence cache sizes. We will expand the revision with additional per-task breakdowns and hypothesis tests for statistical rigor. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The provided abstract and description introduce Nexus Sampling as a training-free combination of an iterative attention walk and weighted reservoir sampling, with a theoretical dominance claim over top-K presented as a new result. No equations, self-citations, or definitions in the visible text reduce the central claims to fitted inputs, prior self-work, or renamed patterns by construction. The method is described without load-bearing reliance on unverified self-referential steps, consistent with an independent derivation against external benchmarks like LongBench.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Direct attention scores provide a sufficient basis for an iterative process to identify bridge tokens.
invented entities (2)
-
Nexus scoring
no independent evidence
-
weighted reservoir sampling for token retention
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Claude Sonnet 4.5
Anthropic. Claude Sonnet 4.5. Anthropic model release, 2025
2025
-
[2]
LongBench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[3]
PyramidKV: Dynamic KV cache compression based on pyramidal information funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, and Wen Xiao. PyramidKV: Dynamic KV cache compression based on pyramidal information funneling. InConference on Language Modeling (COLM), 2025
2025
-
[4]
M.-T. Chao. A general purpose unequal probability sampling plan.Biometrika, 69(3):653–656, 1982
1982
-
[5]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[6]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory- efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[7]
Efraimidis and Paul G
Pavlos S. Efraimidis and Paul G. Spirakis. Weighted random sampling with a reservoir.Information Processing Letters, 97(5):181–185, 2006
2006
-
[8]
Kevin Zhou
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S. Kevin Zhou. Ada-KV: Optimizing KV cache eviction by adaptive budget allocation for efficient LLM inference. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[9]
Dialogue without limits: Constant-sized KV caches for extended responses in LLMs
Ravi Ghadia, Avinash Kumar, Gaurav Jain, Prashant Nair, and Poulami Das. Dialogue without limits: Constant-sized KV caches for extended responses in LLMs. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[10]
RULER: What’s the real context size of your long-context language models? InConference on Language Modeling (COLM), 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? InConference on Language Modeling (COLM), 2024
2024
-
[11]
Naman Jain, Jaskirat Singh, Manish Shetty, Liang Zheng, Koushik Sen, and Ion Stoica. R2E-Gym: Procedural environments and hybrid verifiers for scaling open-weights SWE agents.arXiv preprint arXiv:2504.07164, 2025
arXiv 2025
-
[12]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[13]
SOCKET: SOft collision kernel Estimator for sparse attention
Sahil Joshi, Agniva Chowdhury, Wyatt Bellinger, Amar Kanakamedala, Ekam Singh, Hoang Anh Duy Le, Aditya Desai, and Anshumali Shrivastava. SOCKET: SOft collision kernel Estimator for sparse attention. arXiv preprint arXiv:2602.06283, 2026
Pith/arXiv arXiv 2026
-
[14]
Hoang Anh Duy Le, Sahil Joshi, Zeyu Yang, Zhaozhuo Xu, and Anshumali Shrivastava. Scout before you attend: Sketch-and-walk sparse attention for efficient LLM inference.arXiv preprint arXiv:2602.07397, 2026
arXiv 2026
-
[15]
FAFO: Lossy KV cache compression for lossless inference acceleration via draftless fumble decoding.OpenReview preprint, 2026.https://openreview.net/forum? id=oSk9tP5Mgs
Hoang Anh Duy Le, Shaochen Zhong, Yifan Lu, Yingtong Dou, Jiayi Yuan, Yu-Neng Chuang, Xiran Fan, Guanchu Wang, Yuzhong Chen, and Xia Hu. FAFO: Lossy KV cache compression for lossless inference acceleration via draftless fumble decoding.OpenReview preprint, 2026.https://openreview.net/forum? id=oSk9tP5Mgs. 12
2026
-
[16]
SnapKV: LLM knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. SnapKV: LLM knows what you are looking for before generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[17]
DeepSWE: Training a fully open-sourced, state-of-the-art coding agent by scaling rl
Michael Luo, Naman Jain, Jaskirat Singh, Sijun Tan, Ameen Patel, Qingyang Wu, Erran Ariyak, Colin Cai, Alejandro Cuadron, Tianjun Zhang, Ion Stoica, and Koushik Sen. DeepSWE: Training a fully open-sourced, state-of-the-art coding agent by scaling rl. Notion Blog, 2025. Agentica and Together AI
2025
-
[18]
OpenAI o1 system card
OpenAI. OpenAI o1 system card. Technical report, OpenAI, 2024
2024
-
[19]
Efficiently scaling transformer inference
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Anselm Levskaya, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. In Proceedings of Machine Learning and Systems (MLSys), 2023
2023
-
[20]
Quest: Query-aware sparsity for efficient long-context LLM inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: Query-aware sparsity for efficient long-context LLM inference. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[21]
Jeffrey S. Vitter. Random sampling with a reservoir.ACM Transactions on Mathematical Software, 11(1): 37–57, 1985
1985
-
[22]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[23]
KV cache compression, but what must we give in return? A comprehensive benchmark of long context capable approaches
Jiayi Yuan, Hongyi Liu, Shaochen Zhong, Yu-Neng Chuang, Songchen Li, Guanchu Wang, Duy Le, Hongye Jin, Vipin Chaudhary, Zhaozhuo Xu, Zirui Liu, and Xia Hu. KV cache compression, but what must we give in return? A comprehensive benchmark of long context capable approaches. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4623–...
2024
-
[24]
Owens, Xia Hu, Song Han, Timmy Liu, and Huizi Mao
Jiayi Yuan, Cameron Shinn, Kai Xu, Jingze Cui, George Klimiashvili, Guangxuan Xiao, Perkz Zheng, Bo Li, Yuxin Zhou, Zhouhai Ye, Weijie You, Tian Zheng, Dominic Brown, Pengbo Wang, Markus Hoehnerbach, Richard Cai, Julien Demouth, John D. Owens, Xia Hu, Song Han, Timmy Liu, and Huizi Mao. BLASST: Dynamic BLocked attention sparsity via softmax thresholding.a...
Pith/arXiv arXiv 2025
-
[25]
H2O: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang Wang, and Beidi Chen. H2O: Heavy-hitter oracle for efficient generative inference of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 13 A Theoretical Analysis This ap...
2023
-
[26]
how much can we shrink the cache before accuracy breaks?
If the Nexus weight approximates future utility as∥w−z∥∞≤η, then the expected evicted utilityL =∑ j(1−Ij)zj satisfies ⏐⏐⏐⏐⏐⏐ E[L]− Nk∑ j=1 (1−pj)wj ⏐⏐⏐⏐⏐⏐ ≤η Nk∑ j=1 (1−pj)≤ηNk. Proof. The first claim is the Horvitz–Thompson identity already used in Lemma A.1. For the second claim, let Aj =I jzj/pj. Because exactlyKblocks are retained,( ∑ jAj)2≤K∑ jA2 j. ...
arXiv 1955
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.