Hypergraph as Language
Pith reviewed 2026-05-22 07:06 UTC · model grok-4.3
The pith
Hyper-Align converts hypergraph high-order relations into tokens a frozen LLM can process directly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
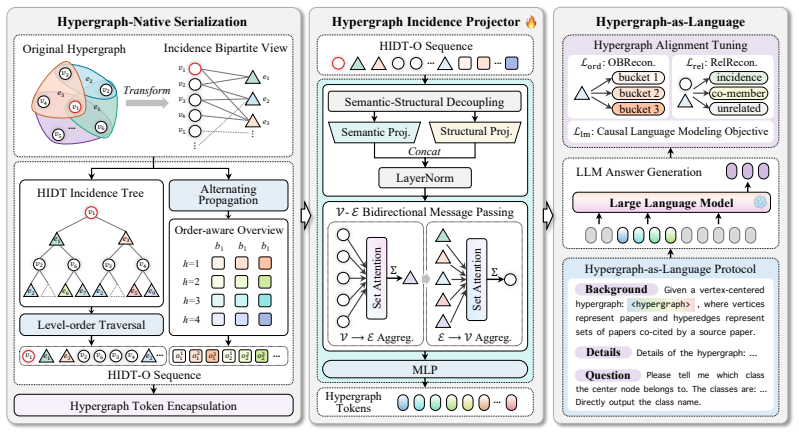
Hyper-Align compiles query-object-centered hypergraph context into hypergraph tokens by serializing high-order incidences into the fixed-shape HIDT-O template and mapping them through the HIP projector with explicit semantic-structural decoupling and bidirectional message passing, allowing a frozen base LLM to consume the structures natively.
What carries the argument
The Hypergraph Incidence Detail Template with Overview (HIDT-O) that serializes high-order associations into a fixed hybrid form, paired with the Hypergraph Incidence Projector (HIP) that maps incidences into token space via decoupling and bidirectional passing.
If this is right
- LLMs gain the ability to handle vertex-level and hyperedge-level tasks under one question-answering format.
- High-order relational patterns are modeled without forcing them into pairwise edges.
- Performance improves over graph-centric methods on both in-domain and zero-shot hypergraph tasks.
- HyperAlign-Bench supplies a standardized way to compare structural modeling approaches.
Where Pith is reading between the lines
- The same template-plus-projector pattern could be tested on other non-pairwise structures such as simplicial complexes or set systems.
- Freezing the base LLM implies the method could be applied with modest compute when structural data must be added to existing models.
- Domains with group-level interactions, such as team collaborations or molecular complexes, become more directly accessible to language-model pipelines.
Load-bearing premise
Converting high-order hypergraph associations into a fixed-shape template and projecting them with bidirectional message passing preserves enough native semantics for a frozen base LLM to use without major loss.
What would settle it
A test set of explicit multi-object hyperedges where the model must distinguish joint group connections from any pairwise approximation; failure to do so would indicate semantic loss in the serialization step.
Figures





read the original abstract
Large language models (LLMs) have recently shown strong potential in modeling relational structures. However, existing approaches remain fundamentally graph-centric: they focus on processing pairwise graph structures into tokens that LLMs can understand. In contrast, many real-world relational patterns do not naturally conform to the pairwise-edge assumption, and are better modeled as high-order associations in hypergraphs. For hypergraph structures, existing methods often fail to preserve the native semantics that multiple objects are jointly connected by the same high-order relation, limiting their ability to exploit complex structures. To address this limitation, we put forth the "Hypergraph as Language" perspective and propose Hyper-Align, a hypergraph-native alignment framework for large language models. Hyper-Align compiles the query-object-centered hypergraph context into hypergraph tokens directly consumable by a base LLM. Specifically, we introduce Hypergraph Incidence Detail Template with Overview (HIDT-O), which serializes high-order association structures into a fixed-shape hybrid template combining local incidence details and overview-level summaries. We then design a Hypergraph Incidence Projector (HIP), which maps native high-order incidence structures into the LLM token space through explicit semantic-structural decoupling and bidirectional message passing between vertices and hyperedges. We further define a concrete Hypergraph-as-Language input protocol, which jointly feeds hypergraph tokens and textual prompts into a frozen base LLM, supporting both vertex-level and hyperedge-level tasks under a unified question-answering paradigm. To systematically evaluate different methods in hypergraph structural modeling, we introduce HyperAlign-Bench. Extensive experiments show that Hyper-Align significantly outperforms existing methods across in-domain and zero-shot evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a 'Hypergraph as Language' perspective and introduces Hyper-Align, a framework that serializes query-object-centered hypergraph contexts into tokens consumable by frozen base LLMs. It defines the Hypergraph Incidence Detail Template with Overview (HIDT-O) for fixed-shape hybrid serialization of high-order associations, the Hypergraph Incidence Projector (HIP) for semantic-structural decoupling and bidirectional message passing, and a unified QA input protocol supporting vertex- and hyperedge-level tasks. A new benchmark HyperAlign-Bench is introduced, with claims of significant outperformance over existing methods in both in-domain and zero-shot evaluations.
Significance. If the central claim holds—that HIDT-O plus HIP preserves native high-order incidence semantics without substantial loss when mapped to LLM token space—this would represent a meaningful advance over graph-centric LLM alignment methods for relational modeling. The introduction of a dedicated hypergraph benchmark is a positive contribution that could enable more systematic future comparisons.
major comments (3)
- [§3.2] §3.2 (HIDT-O description): The fixed-shape hybrid template necessarily imposes bounds on the number of vertices and hyperedges per slot. The manuscript does not specify the truncation, padding, or summarization policy for overflow cases, nor does it quantify the resulting information loss relative to the original incidence structure. This directly affects the load-bearing assumption that native hypergraph semantics are preserved when the frozen LLM receives only the serialized form.
- [§4.1] §4.1 (HIP architecture): The bidirectional message passing is described as decoupling semantics from structure, yet no formal argument or ablation is provided showing that the resulting token embeddings retain joint multi-object relations that distinguish hypergraphs from graphs. If the projector collapses distinct hyperedges into aggregate features, the reported gains could arise from richer textual prompting rather than hypergraph-native modeling.
- [Table 2, §5.3] Table 2 and §5.3 (zero-shot results): The outperformance margins are presented without error bars, statistical significance tests, or details on data splits and baseline implementations. Given that the central claim attributes gains to semantic preservation, the absence of these controls makes it difficult to rule out confounding factors such as prompt length or template richness.
minor comments (2)
- [§1] The abstract and §1 use 'hypergraph tokens' without an early formal definition; a short clarifying sentence would help readers distinguish this from standard graph tokenization.
- [Figure 3] Figure 3 (HIDT-O example) would benefit from an explicit legend indicating which slots contain incidence details versus overview summaries.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity around serialization details, the HIP mechanism, and evaluation rigor. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (HIDT-O description): The fixed-shape hybrid template necessarily imposes bounds on the number of vertices and hyperedges per slot. The manuscript does not specify the truncation, padding, or summarization policy for overflow cases, nor does it quantify the resulting information loss relative to the original incidence structure. This directly affects the load-bearing assumption that native hypergraph semantics are preserved when the frozen LLM receives only the serialized form.
Authors: We agree that explicit policies for handling overflow are essential to substantiate the semantic preservation claim. In the revised manuscript, we will add a dedicated paragraph in §3.2 specifying: (i) truncation prioritizes incidences connected to the query object, (ii) padding employs special null tokens, and (iii) a quantitative coverage analysis on HyperAlign-Bench measuring retained hyperedge incidence ratios. This will directly quantify information loss and reinforce that native high-order semantics remain largely intact. revision: yes
-
Referee: [§4.1] §4.1 (HIP architecture): The bidirectional message passing is described as decoupling semantics from structure, yet no formal argument or ablation is provided showing that the resulting token embeddings retain joint multi-object relations that distinguish hypergraphs from graphs. If the projector collapses distinct hyperedges into aggregate features, the reported gains could arise from richer textual prompting rather than hypergraph-native modeling.
Authors: The HIP design uses an incidence matrix to keep hyperedge representations distinct during bidirectional passing, avoiding simple aggregation. While a formal proof of joint-relation retention is not provided, we will add an ablation study in the revision comparing HIP against a graph-flattened baseline and a unidirectional variant. Results will show that performance gains persist beyond prompt richness, supporting that the architecture preserves hypergraph-specific multi-object relations. revision: yes
-
Referee: [Table 2, §5.3] Table 2 and §5.3 (zero-shot results): The outperformance margins are presented without error bars, statistical significance tests, or details on data splits and baseline implementations. Given that the central claim attributes gains to semantic preservation, the absence of these controls makes it difficult to rule out confounding factors such as prompt length or template richness.
Authors: We acknowledge the value of statistical controls for validating the zero-shot claims. In the revised version, we will augment §5.3 and Table 2 with error bars computed over five random seeds, paired t-test p-values for significance, and explicit descriptions of data splits plus baseline re-implementations. These additions will help isolate the contribution of semantic preservation from potential confounders like prompt length. revision: yes
Circularity Check
No significant circularity; framework introduces independent novel components
full rationale
The paper defines a new 'Hypergraph as Language' perspective and proposes Hyper-Align with explicitly constructed elements: HIDT-O as a fixed-shape serialization template, HIP as a projector using semantic-structural decoupling and bidirectional message passing, and a joint input protocol for frozen LLMs. These are presented as original designs rather than derivations from prior results. No equations or claims reduce a 'prediction' to fitted inputs by construction, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The new HyperAlign-Bench benchmark further supports external evaluation. The derivation chain remains self-contained against the described inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HIDT-O serializes high-order association structures into a fixed-shape hybrid template combining local incidence details and overview-level summaries... HIP performs explicit semantic-structural decoupling and bidirectional message passing between vertices and hyperedges.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
overview suffix contains 8 tokens, corresponding to 2 hops and 4 order buckets... sample up to 8 incident hyperedges
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Adv. Neural Inform. Process. Syst., 33:1877–1901, 2020
work page 1901
-
[2]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Be- ichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models.arXiv preprint arXiv:2303.18223, 1(2):1–124, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Muhammad Usman Hadi, Rizwan Qureshi, Abbas Shah, Muhammad Irfan, Anas Zafar, Muhammad Bilal Shaikh, Naveed Akhtar, Jia Wu, Seyedali Mirjalili, et al. A survey on large language models: Applications, challenges, limitations, and practical usage.Authorea Preprints, 2023
work page 2023
-
[5]
A survey of large language models for graphs
Xubin Ren, Jiabin Tang, Dawei Yin, Nitesh Chawla, and Chao Huang. A survey of large language models for graphs. InACM SIGKDD, pages 6616–6626, 2024
work page 2024
-
[6]
Jeff Z Pan, Simon Razniewski, Jan-Christoph Kalo, Sneha Singhania, Jiaoyan Chen, Stefan Dietze, Hajira Jabeen, Janna Omeliyanenko, Wen Zhang, Matteo Lissandrini, et al. Large language models and knowledge graphs: Opportunities and challenges.arXiv preprint arXiv:2308.06374, 2023
-
[7]
Yuhan Li, Zhixun Li, Peisong Wang, Jia Li, Xiangguo Sun, Hong Cheng, and Jeffrey Xu Yu. A survey of graph meets large language model: Progress and future directions.arXiv preprint arXiv:2311.12399, 2023
-
[8]
Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. Language is all a graph needs. InFindings Assoc. Comput. Linguist., pages 1955–1973, 2024
work page 1955
-
[9]
GraphLLM: Boosting graph reasoning ability of large language model.IEEE Trans
Ziwei Chai, Tianjie Zhang, Liang Wu, Kaiqiang Han, Xiaohai Hu, Xuanwen Huang, and Yang Yang. GraphLLM: Boosting graph reasoning ability of large language model.IEEE Trans. Big Data, 2025
work page 2025
-
[10]
CodeGraph: Enhancing graph reasoning of LLMs with code.arXiv preprint arXiv:2408.13863, 2024
Qiaolong Cai, Zhaowei Wang, Shizhe Diao, James Kwok, and Yangqiu Song. CodeGraph: Enhancing graph reasoning of LLMs with code.arXiv preprint arXiv:2408.13863, 2024
-
[11]
Can large language models analyze graphs like professionals? a benchmark, datasets and models.Adv
Xin Li, Weize Chen, Qizhi Chu, Haopeng Li, Zhaojun Sun, Ran Li, Chen Qian, Yiwei Wei, Zhiyuan Liu, Chuan Shi, et al. Can large language models analyze graphs like professionals? a benchmark, datasets and models.Adv. Neural Inform. Process. Syst., 37:141045–141070, 2024
work page 2024
-
[12]
GraphGPT: Graph instruction tuning for large language models
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. GraphGPT: Graph instruction tuning for large language models. InProc. Int. ACM SIGIR Conf. Res. Dev. Inf. Retr., pages 491–500, 2024
work page 2024
-
[13]
LLaGA: Large language and graph assistant
Runjin Chen, Tong Zhao, Ajay Jaiswal, Neil Shah, and Zhangyang Wang. LLaGA: Large language and graph assistant. InProc. Int. Conf. Mach. Learn., pages 7809–7823, 2024
work page 2024
-
[14]
Duo Wang, Yuan Zuo, Fengzhi Li, and Junjie Wu. Llms as zero-shot graph learners: Alignment of gnn representations with llm token embeddings.Advances in neural information processing systems, 37:5950–5973, 2024
work page 2024
-
[15]
Xi Zhu, Haochen Xue, Ziwei Zhao, Wujiang Xu, Jingyuan Huang, Minghao Guo, Qifan Wang, Kaixiong Zhou, Imran Razzak, and Yongfeng Zhang. LLM as GNN: Graph vocabulary learning for text-attributed graph foundation models.arXiv preprint arXiv:2503.03313, 2025
-
[16]
Claude Berge.Hypergraphs: combinatorics of finite sets, volume 45. Elsevier, 1984
work page 1984
-
[17]
Learning with hypergraphs: Clustering, classification, and embedding.Adv
Dengyong Zhou, Jiayuan Huang, and Bernhard Schölkopf. Learning with hypergraphs: Clustering, classification, and embedding.Adv. Neural Inform. Process. Syst., 19, 2006
work page 2006
-
[18]
Hypergraph computation.Engineering, 2024
Yue Gao, Shuyi Ji, Xiangmin Han, and Qionghai Dai. Hypergraph computation.Engineering, 2024
work page 2024
-
[19]
Networks beyond pairwise interactions: Structure and dynamics
Federico Battiston, Giulia Cencetti, Iacopo Iacopini, Vito Latora, Maxime Lucas, Alice Patania, Jean- Gabriel Young, and Giovanni Petri. Networks beyond pairwise interactions: Structure and dynamics. Physics Reports, 874:1–92, 2020
work page 2020
-
[20]
Yifan Feng, Haoxuan You, Zizhao Zhang, Rongrong Ji, and Yue Gao. Hypergraph neural networks. In AAAI, pages 3558–3565, 2019. 11
work page 2019
-
[21]
HyperGCN: A new method for training graph convolutional networks on hypergraphs.Adv
Naganand Yadati, Madhav Nimishakavi, Prateek Yadav, Vikram Nitin, Anand Louis, and Partha Talukdar. HyperGCN: A new method for training graph convolutional networks on hypergraphs.Adv. Neural Inform. Process. Syst., 32, 2019
work page 2019
-
[22]
You are AllSet: A multiset function framework for hypergraph neural networks
Eli Chien, Chao Pan, Jianhao Peng, and Olgica Milenkovic. You are AllSet: A multiset function framework for hypergraph neural networks. InInt. Conf. Learn. Represent., 2022
work page 2022
-
[23]
Hypergraph isomorphism computation.IEEE Trans
Yifan Feng, Jiashu Han, Shihui Ying, and Yue Gao. Hypergraph isomorphism computation.IEEE Trans. Pattern Anal. Mach. Intell., 46(5):3880–3896, 2024
work page 2024
-
[24]
Zhixuan Chu, Yan Wang, Qing Cui, Longfei Li, Wenqing Chen, Zhan Qin, and Kui Ren. LLM- guided multi-view hypergraph learning for human-centric explainable recommendation.arXiv preprint arXiv:2401.08217, 2024
-
[25]
Xu Guo, Tong Zhang, Yuanzhi Wang, Chenxu Wang, Fuyun Wang, Xudong Wang, Xiaoya Zhang, Xin Liu, and Zhen Cui. Multi-modal hypergraph enhanced llm learning for recommendation.arXiv preprint arXiv:2504.10541, 2025
-
[26]
Yifan Feng, Hao Hu, Shihui Ying, Xingliang Hou, Shiquan Liu, Mingyuan Yang, Junchang Li, Shaoyi Du, Nanning Zheng, Han Hu, et al. Hyper-RAG: Combating llm hallucinations using hypergraph-driven retrieval-augmented generation.Nature Communications, 2026
work page 2026
-
[27]
Modeling hypergraph using large language models
Bingqiao Gu, Jiale Zeng, Xingqin Qi, and Dong Li. Modeling hypergraph using large language models. arXiv preprint arXiv:2510.11728, 2025
-
[28]
Beyond graphs: Can large language models comprehend hypergraphs? InInt
Yifan Feng, Chengwu Yang, Xingliang Hou, Shaoyi Du, Shihui Ying, Zongze Wu, and Yue Gao. Beyond graphs: Can large language models comprehend hypergraphs? InInt. Conf. Learn. Represent., pages 3445–3472, 2025
work page 2025
-
[29]
UniGraph: Learning a unified cross-domain foundation model for text-attributed graphs
Yufei He, Yuan Sui, Xiaoxin He, and Bryan Hooi. UniGraph: Learning a unified cross-domain foundation model for text-attributed graphs. InACM SIGKDD, pages 448–459, 2025
work page 2025
-
[30]
GOFA: A generative one-for-all model for joint graph language modeling
Lecheng Kong, Jiarui Feng, Hao Liu, Chengsong Huang, Jiaxin Huang, Yixin Chen, and Muhan Zhang. GOFA: A generative one-for-all model for joint graph language modeling. InInt. Conf. Learn. Represent., 2025
work page 2025
-
[31]
Hyper-SAGNN: a self-attention based graph neural network for hypergraphs
R Zhang, Y Zou, and J Ma. Hyper-SAGNN: a self-attention based graph neural network for hypergraphs. InInt. Conf. Learn. Represent., 2020
work page 2020
-
[32]
Adrián Bazaga, Pietro Liò, and Gos Micklem. HyperBERT: Mixing hypergraph-aware layers with language models for node classification on text-attributed hypergraphs. InProc. Conf. Empirical Methods in Nat. Lang. Process., pages 9181–9193, 2024
work page 2024
-
[33]
Mathematical foundations of hypergraph
Qionghai Dai and Yue Gao. Mathematical foundations of hypergraph. InHypergraph Computation, pages 19–40. Springer, 2023
work page 2023
-
[34]
Open graph benchmark: Datasets for machine learning on graphs.Adv
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs.Adv. Neural Inform. Process. Syst., 33:22118–22133, 2020
work page 2020
-
[35]
Heterogeneous graph attention network
Xiao Wang, Houye Ji, Chuan Shi, Bai Wang, Yanfang Ye, Peng Cui, and Philip S Yu. Heterogeneous graph attention network. InInt. World Wide Web Conf., pages 2022–2032, 2019
work page 2022
-
[36]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
OpenAI. GPT-5 mini. https://developers.openai.com/api/docs/models/gpt-5-mini, 2025. Model:gpt-5-mini
work page 2025
-
[40]
GraphPrompter: Multi-stage adaptive prompt optimization for graph in-context learning
Rui Lv, Zaixi Zhang, Kai Zhang, Qi Liu, Weibo Gao, Jiawei Liu, Jiaxia Yan, Linan Yue, and Fangzhou Yao. GraphPrompter: Multi-stage adaptive prompt optimization for graph in-context learning. InProc. IEEE Int. Conf. Data Eng., pages 3917–3930, 2025. 12
work page 2025
-
[41]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing GPT-4 with 90%* ChatGPT quality, March 2023
work page 2023
-
[42]
Sentence-BERT: Sentence embeddings using siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT-networks. InProc. Conf. Empirical Methods in Nat. Lang. Process., pages 3982–3992, 2019
work page 2019
- [43]
-
[44]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
A survey on hypergraph representation learning.ACM Comp
Alessia Antelmi, Gennaro Cordasco, Mirko Polato, Vittorio Scarano, Carmine Spagnuolo, and Dingqi Yang. A survey on hypergraph representation learning.ACM Comp. Surv., 56(1):1–38, 2023
work page 2023
-
[46]
A survey on hypergraph neural networks: An in-depth and step-by-step guide
Sunwoo Kim, Soo Yong Lee, Yue Gao, Alessia Antelmi, Mirko Polato, and Kijung Shin. A survey on hypergraph neural networks: An in-depth and step-by-step guide. InACM SIGKDD, pages 6534–6544, 2024
work page 2024
-
[47]
Hypergraph foundation model.IEEE Trans
Yue Gao, Yifan Feng, Shiquan Liu, Xiangmin Han, Shaoyi Du, Zongze Wu, and Han Hu. Hypergraph foundation model.IEEE Trans. Pattern Anal. Mach. Intell., 48(4):4063–4080, 2026
work page 2026
-
[48]
a hyperedge is a set rather than a list of edges
Fan Li, Xiaoyang Wang, Wenjie Zhang, Ying Zhang, and Xuemin Lin. DHG-Bench: A comprehensive benchmark for deep hypergraph learning.arXiv preprint arXiv:2508.12244, 2025. 13 Appendix Contents A Detailed Related Work 14 A.1 LLMs for Graph Structural Data . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 A.2 Hypergraph Learning and Preliminary Explora...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.