Activation- and Influence-Aware Ranks (AIR): Function-Preserving SVD Compression for LLMs
Pith reviewed 2026-06-26 18:06 UTC · model grok-4.3
The pith
AIR improves LLM compression by using influence metrics in SVD approximations to better preserve model function.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AIR produces function-preserving low-rank approximations of LLM weight matrices by integrating an influence metric into the SVD process through one closed-form ALS sweep that ensures monotone descent, starting from the activation-aware optimum of SVD-LLM(W).
What carries the argument
The closed-form alternating least squares sweep that integrates the influence metric element-wise under a monotone-descent guarantee.
If this is right
- AIR alone exceeds ACIP and further when combined with LoRA.
- It improves perplexity by more than 18% over SVD-LLM(W) at 60% or less parameter retention.
- It achieves comparable quality using about 90% less calibration data.
- Parameter savings translate into reductions in FLOP count, peak memory, and per-token latency.
Where Pith is reading between the lines
- The layer-local nature suggests AIR could be combined with other end-to-end compression techniques beyond LoRA.
- If the influence metric generalizes, it might apply to compressing other neural network types.
- The reduced calibration data requirement could lower the barrier for compressing models in data-scarce settings.
Load-bearing premise
The single closed-form ALS sweep that adds the influence metric produces an approximation that truly preserves the original function of the LLM weight matrices.
What would settle it
Comparing the output distributions or perplexity of the compressed model against the original on a held-out dataset after applying the AIR compression.
Figures
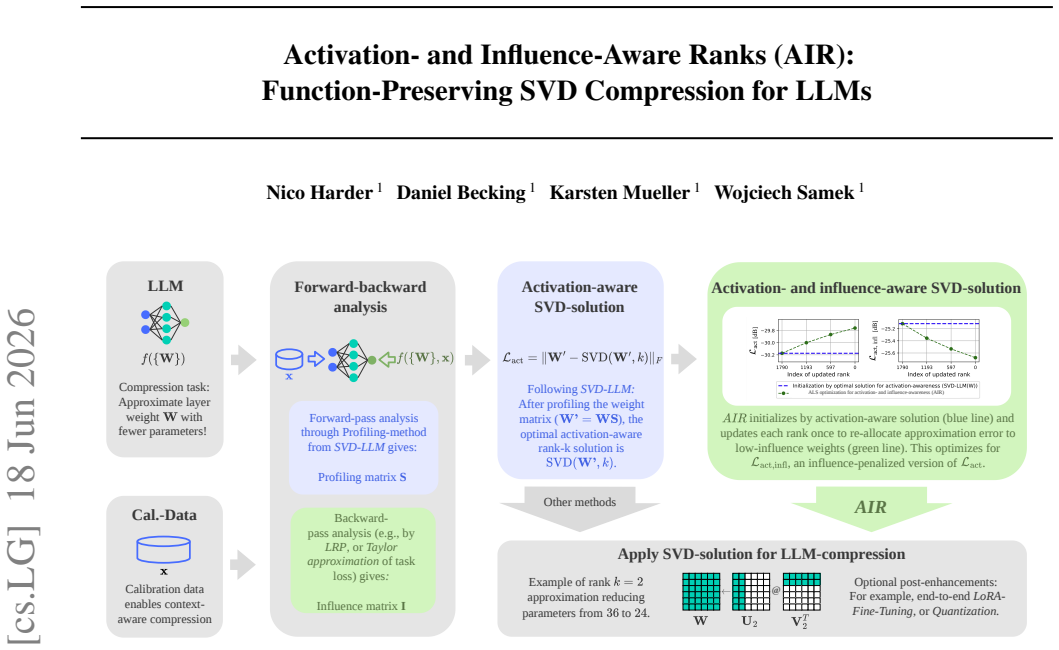
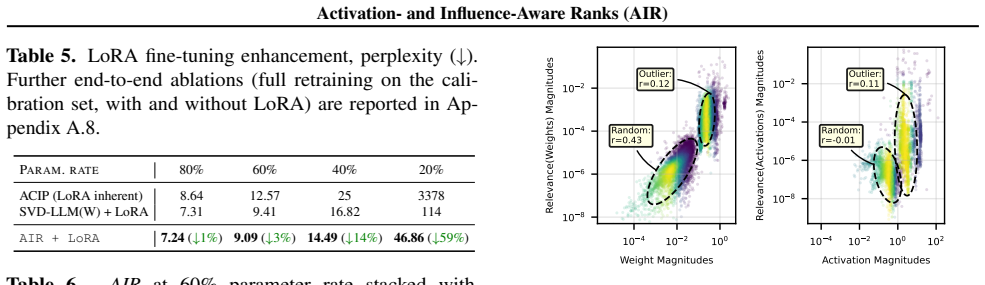
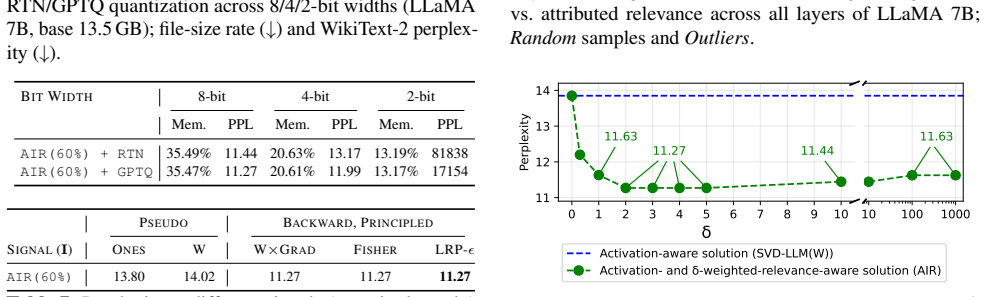
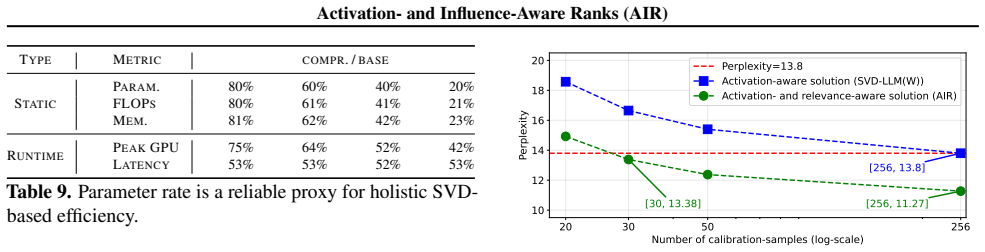

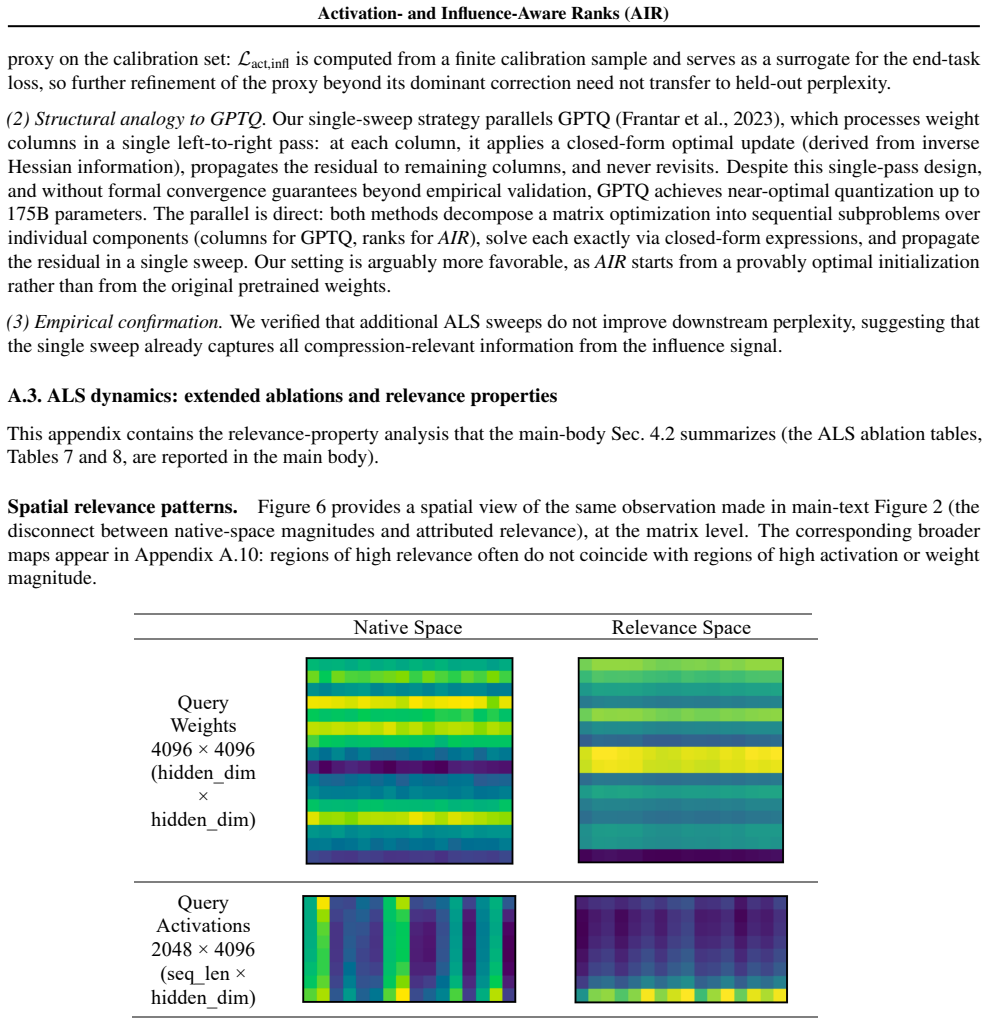
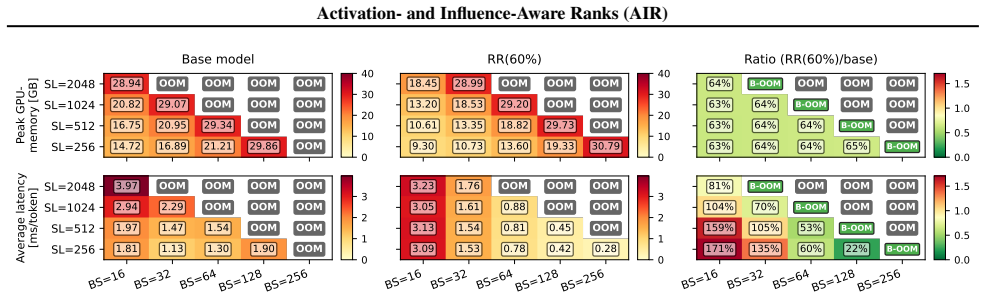
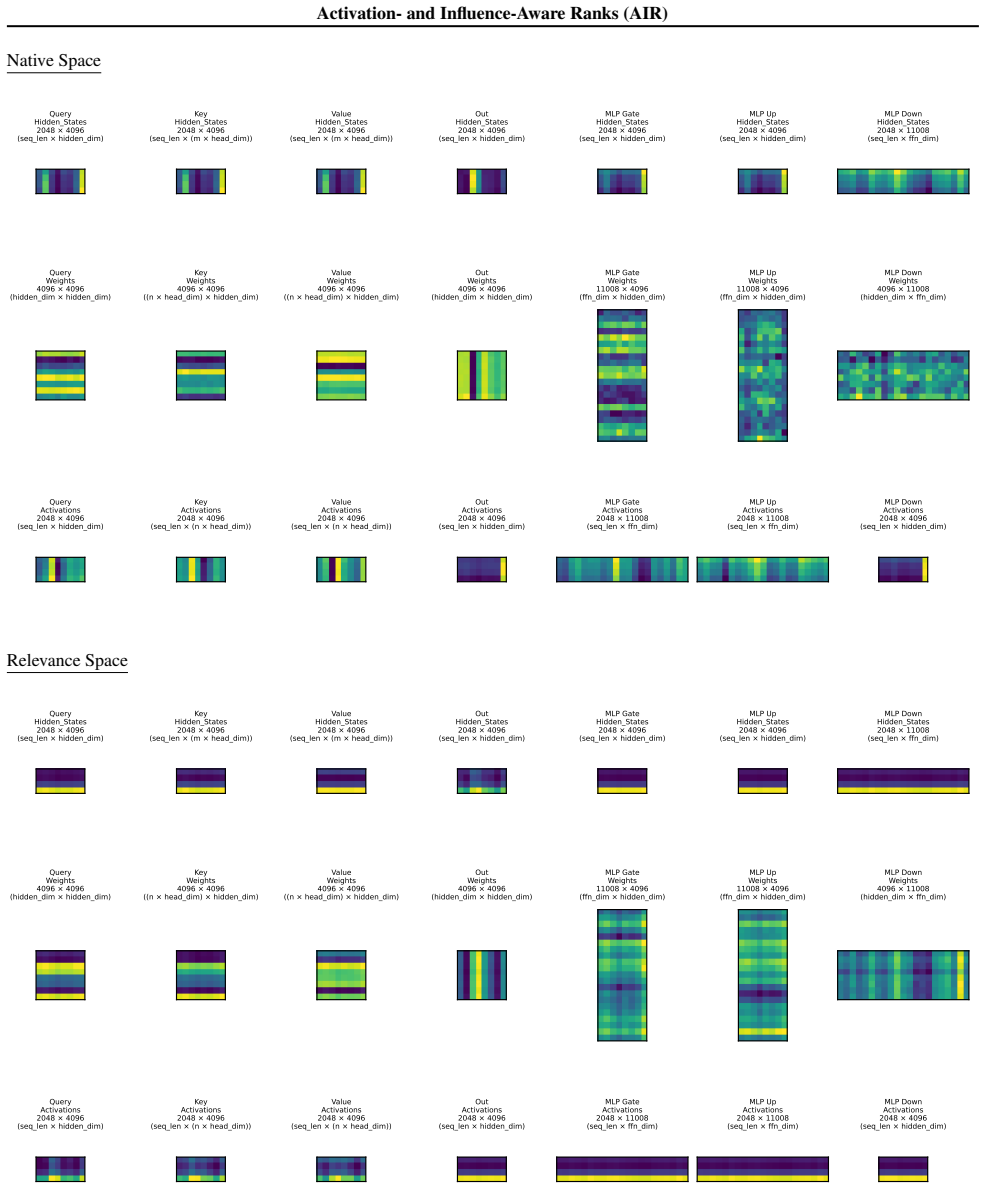
read the original abstract
We present Activation- and Influence-Aware Ranks (AIR), an SVD-based LLM compression framework that guides each weight matrix's low-rank approximation with a backward-signal influence metric. Starting from the activation-aware optimum of SVD-LLM(W), AIR runs a single closed-form alternating least squares (ALS) sweep that integrates influence element-wise under a monotone-descent guarantee. AIR is layer-local and composes orthogonally with end-to-end methods: alone it exceeds ACIP, and AIR+LoRA outperforms it further. AIR improves perplexity over SVD-LLM(W) by >18% at <=60% parameter retention, matches its quality with ~90% less calibration data, and turns parameter savings into FLOP, peak-memory, and per-token latency gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Activation- and Influence-Aware Ranks (AIR), an SVD-based LLM compression method. It begins from the activation-aware optimum of SVD-LLM(W) and applies a single closed-form alternating least squares (ALS) sweep that folds a backward-signal influence metric element-wise into the low-rank factors under a claimed monotone-descent guarantee. The approach is layer-local, composes with end-to-end techniques such as LoRA, and is reported to deliver >18% perplexity improvement over SVD-LLM(W) at ≤60% parameter retention, equivalent quality with ~90% less calibration data, and corresponding gains in FLOP count, peak memory, and per-token latency.
Significance. If the ALS step indeed yields a function-preserving approximation and the reported gains prove robust, the method would supply a lightweight, layer-local refinement to existing SVD compression pipelines that reduces calibration-data requirements while preserving composability. The explicit separation of the influence integration from end-to-end fine-tuning is a potentially useful design choice.
major comments (2)
- [Abstract / ALS description] Abstract and method description of the ALS step: the central claim that a single closed-form ALS sweep produces a function-preserving low-rank map rests on an asserted 'monotone-descent guarantee' after element-wise integration of the influence metric. No derivation, explicit update rule, or analysis addressing (a) element-wise versus joint treatment of the influence metric, (b) non-convexity induced by subsequent layers and non-linear activations, or (c) relation to the already activation-aware SVD-LLM(W) baseline is supplied; without this the attribution of the reported perplexity gains to the function-preserving property cannot be evaluated.
- [Abstract / Experimental results] Empirical claims (abstract): statements of '>18% perplexity gain' at '≤60% parameter retention' and 'matches its quality with ~90% less calibration data' are presented without error bars, dataset identities, model sizes, number of runs, or ablation controls that isolate the contribution of the influence term versus the baseline SVD-LLM(W) optimum.
minor comments (2)
- [Method] Notation for the influence metric and its element-wise incorporation should be defined with an explicit equation before the ALS update is stated.
- [Abstract] The abstract's quantitative claims would be easier to assess if the main text supplied the precise calibration-set size, model scale, and perplexity evaluation protocol used for the 90%-data-reduction result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential utility of the layer-local refinement. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / ALS description] Abstract and method description of the ALS step: the central claim that a single closed-form ALS sweep produces a function-preserving low-rank map rests on an asserted 'monotone-descent guarantee' after element-wise integration of the influence metric. No derivation, explicit update rule, or analysis addressing (a) element-wise versus joint treatment of the influence metric, (b) non-convexity induced by subsequent layers and non-linear activations, or (c) relation to the already activation-aware SVD-LLM(W) baseline is supplied; without this the attribution of the reported perplexity gains to the function-preserving property cannot be evaluated.
Authors: We agree that the abstract and high-level method description omit the requested derivation and analysis. In the revised manuscript we will add (i) the explicit closed-form ALS update rules, (ii) a self-contained derivation of the monotone-descent guarantee under element-wise influence integration, (iii) a discussion of element-wise versus joint treatment, (iv) remarks on how non-convexity arising from subsequent layers and non-linear activations is handled by the layer-local formulation, and (v) an explicit comparison to the SVD-LLM(W) optimum. These additions will make the attribution of gains to the function-preserving step directly evaluable. revision: yes
-
Referee: [Abstract / Experimental results] Empirical claims (abstract): statements of '>18% perplexity gain' at '≤60% parameter retention' and 'matches its quality with ~90% less calibration data' are presented without error bars, dataset identities, model sizes, number of runs, or ablation controls that isolate the contribution of the influence term versus the baseline SVD-LLM(W) optimum.
Authors: The main experimental section already reports the underlying datasets, model sizes, and ablations, but the abstract claims are stated without accompanying error bars or run counts. In the revision we will (i) add error bars and the number of independent runs to all reported metrics, (ii) ensure dataset identities and model sizes are stated in the abstract or immediately referenced, and (iii) expand the ablation studies to more clearly isolate the incremental contribution of the influence term over the SVD-LLM(W) baseline. These changes will be reflected in both the main text and, where space permits, the abstract. revision: yes
Circularity Check
No significant circularity; derivation is a self-contained algorithmic construction
full rationale
The paper presents AIR as an algorithmic procedure that starts from the external activation-aware optimum of SVD-LLM(W) and applies one closed-form ALS sweep integrating an influence metric under a claimed monotone-descent guarantee. No equations or steps in the provided text reduce the reported perplexity gains, parameter retention, or function-preserving property to a fitted parameter on the same test metrics, a self-defined quantity, or a load-bearing self-citation chain. The central claim is framed as a new layer-local construction that composes with other methods, with independent content relative to the cited baseline.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
McGraw-Hill Science/Engineering/Math , year=
Machine learning , author=. McGraw-Hill Science/Engineering/Math , year=
-
[2]
Nature , volume=
Learning representations by back-propagating errors , author=. Nature , volume=. 1986 , publisher=
1986
-
[3]
3rd International Conference on Learning Representations (ICLR) , year =
Adam: A Method for Stochastic Optimization , author =. 3rd International Conference on Learning Representations (ICLR) , year =
-
[4]
The Annals of Mathematical Statistics , volume =
A Stochastic Approximation Method , author =. The Annals of Mathematical Statistics , volume =. 1951 , doi =
1951
-
[5]
Proceedings of the 32nd International Conference on Machine Learning (ICML) , pages =
Optimizing Neural Networks with Kronecker-factored Approximate Curvature , author =. Proceedings of the 32nd International Conference on Machine Learning (ICML) , pages =
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Optimal Brain Damage , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[7]
Proceedings of the 20th International Conference on Machine Learning (ICML) , pages=
Weighted Low-Rank Approximations , author=. Proceedings of the 20th International Conference on Machine Learning (ICML) , pages=
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Second Order Derivatives for Network Pruning: Optimal Brain Surgeon , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[10]
International Conference on Learning Representations (ICLR) , year=
Pruning Convolutional Neural Networks for Resource Efficient Inference , author=. International Conference on Learning Representations (ICLR) , year=
-
[11]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Importance Estimation for Neural Network Pruning , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[12]
International Conference on Machine Learning (ICML) , pages=
Learning Important Features Through Propagating Activation Differences , author=. International Conference on Machine Learning (ICML) , pages=. 2017 , organization=
2017
-
[13]
Proceedings of the National Academy of Sciences , volume=
Overcoming Catastrophic Forgetting in Neural Networks , author=. Proceedings of the National Academy of Sciences , volume=
-
[14]
Journal of Machine Learning Research , volume=
New Insights and Perspectives on the Natural Gradient Method , author=. Journal of Machine Learning Research , volume=
-
[15]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Limitations of the Empirical Fisher Approximation for Natural Gradient Descent , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[16]
International Conference on Machine Learning (ICML) , year=
Understanding Black-box Predictions via Influence Functions , author=. International Conference on Machine Learning (ICML) , year=
-
[17]
2023 , eprint=
LLM-Pruner: On the Structural Pruning of Large Language Models , author=. 2023 , eprint=
2023
-
[18]
Neural computation , volume=
Long short-term memory , author=. Neural computation , volume=. 1997 , publisher=
1997
-
[19]
2025 , eprint=
BlockPruner: Fine-grained Pruning for Large Language Models , author=. 2025 , eprint=
2025
-
[20]
CVPR , year=
MobileNetV2: Inverted Residuals and Linear Bottlenecks , author=. CVPR , year=
-
[21]
2023 , howpublished=
DeepLabV3 with ResNet-50 Backbone , author=. 2023 , howpublished=
2023
-
[22]
ICML , year=
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks , author=. ICML , year=
-
[23]
2023 , eprint=
TinyStories: How Small Can Language Models Be and Still Speak Coherent English? , author=. 2023 , eprint=
2023
-
[24]
2022 , howpublished =
PyTorch , title =. 2022 , howpublished =
2022
-
[25]
ICLR , year=
Very Deep Convolutional Networks for Large-Scale Image Recognition , author=. ICLR , year=
-
[26]
2023 , url=
TinyLlama: Open Reproduction of LLaMA with 1.1B Parameters , author=. 2023 , url=
2023
-
[27]
2023 , url=
LLaMA 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , url=
2023
-
[28]
2022 , eprint=
Language model compression with weighted low-rank factorization , author=. 2022 , eprint=
2022
-
[29]
2025 , eprint=
Choose Your Model Size: Any Compression of Large Language Models Without Re-Computation , author=. 2025 , eprint=
2025
-
[30]
2023 , eprint=
QLoRA: Efficient Finetuning of Quantized LLMs , author=. 2023 , eprint=
2023
-
[31]
ICML 2023 Workshop Neural Compression: From Information Theory to Applications , year=
Daniel Becking and Paul Haase and Heiner Kirchhoffer and Karsten M. ICML 2023 Workshop Neural Compression: From Information Theory to Applications , year=
2023
-
[32]
arXiv preprint arXiv:2403.05175 , year=
Continual learning and catastrophic forgetting , author=. arXiv preprint arXiv:2403.05175 , year=
-
[33]
2025 , eprint=
Generalized Fisher-Weighted SVD: Scalable Kronecker-Factored Fisher Approximation for Compressing Large Language Models , author=. 2025 , eprint=
2025
-
[34]
NeurIPS , year=
Language Models are Few-Shot Learners , author=. NeurIPS , year=
-
[35]
DeepMind , year=
Training Compute-Optimal Large Language Models , author=. DeepMind , year=
-
[36]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[37]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[39]
, author=
Floating point operations in matrix-vector calculus. , author=. 2005 , institution=
2005
-
[40]
Netflix Technology Blog , url=
Optimizing the Netflix Streaming Experience with Data Science , author=. Netflix Technology Blog , url=
-
[41]
11th International Conference on Learning Representations , year=
OPTQ: Accurate post-training quantization for generative pre-trained transformers , author=. 11th International Conference on Learning Representations , year=
-
[42]
The Twelfth International Conference on Learning Representations , year=
A Simple and Effective Pruning Approach for Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[43]
Advances in Neural Information Processing Systems , year=
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale , author=. Advances in Neural Information Processing Systems , year=
-
[44]
CoRR , volume=
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration , author=. CoRR , volume=
-
[45]
arXiv preprint arXiv:2306.11695 , year=
A simple and effective pruning approach for large language models , author=. arXiv preprint arXiv:2306.11695 , year=
-
[46]
Advances in neural information processing systems , volume=
Llm-pruner: On the structural pruning of large language models , author=. Advances in neural information processing systems , volume=
-
[47]
Disentangled Explanations of Neural Network Predictions by Finding Relevant Subspaces , year=
Chormai, Pattarawat and Herrmann, Jan and Müller, Klaus-Robert and Montavon, Grégoire , journal=. Disentangled Explanations of Neural Network Predictions by Finding Relevant Subspaces , year=
-
[48]
Achtibat, Reduan and Dreyer, Maximilian and Eisenbraun, Ilona and Bosse, Sebastian and Wiegand, Thomas and Samek, Wojciech and Lapuschkin, Sebastian , year=. From attribution maps to human-understandable explanations through Concept Relevance Propagation , volume=. Nature Machine Intelligence , publisher=. doi:10.1038/s42256-023-00711-8 , number=
-
[49]
2014 , eprint=
Convolutional Kernel Networks , author=. 2014 , eprint=
2014
-
[50]
2017 , eprint=
Rethinking Atrous Convolution for Semantic Image Segmentation , author=. 2017 , eprint=
2017
-
[51]
2019 , eprint=
MobileNetV2: Inverted Residuals and Linear Bottlenecks , author=. 2019 , eprint=
2019
-
[52]
2017 , eprint=
Xception: Deep Learning with Depthwise Separable Convolutions , author=. 2017 , eprint=
2017
-
[53]
, journal=
Wallace, G.K. , journal=. The JPEG still picture compression standard , year=
-
[54]
arXiv preprint arXiv:2310.15929 , year=
E-sparse: Boosting the large language model inference through entropy-based n: M sparsity , author=. arXiv preprint arXiv:2310.15929 , year=
-
[55]
arXiv preprint arXiv:2304.14402 , year=
Lamini-lm: A diverse herd of distilled models from large-scale instructions , author=. arXiv preprint arXiv:2304.14402 , year=
-
[56]
arXiv preprint arXiv:2306.08543 , year=
MiniLLM: Knowledge distillation of large language models , author=. arXiv preprint arXiv:2306.08543 , year=
-
[57]
International Conference on Machine Learning , pages=
Sparsegpt: Massive language models can be accurately pruned in one-shot , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[58]
Advances in Neural Information Processing Systems , volume=
Kvquant: Towards 10 million context length llm inference with kv cache quantization , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
International Conference on Machine Learning , pages=
Smoothquant: Accurate and efficient post-training quantization for large language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[60]
Advances in Neural Information Processing Systems , volume=
Zeroquant: Efficient and affordable post-training quantization for large-scale transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
Thirty-seventh Conference on Neural Information Processing Systems , year=
LLM-Pruner: On the Structural Pruning of Large Language Models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[62]
CoRR , volume=
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization , author=. CoRR , volume=
-
[63]
acip\_llama1\_7b , year =
-
[64]
2024 , eprint=
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback , author=. 2024 , eprint=
2024
-
[65]
The Twelfth International Conference on Learning Representations , year=
MiniLLM: Knowledge Distillation of Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[66]
CoRR , volume=
LoRA: Low-Rank Adaptation of Large Language Models , author=. CoRR , volume=
-
[67]
Psychometrika , volume=
The approximation of one matrix by another of lower rank , author=. Psychometrika , volume=
-
[68]
2024 , editor =
Achtibat, Reduan and Hatefi, Sayed Mohammad Vakilzadeh and Dreyer, Maximilian and Jain, Aakriti and Wiegand, Thomas and Lapuschkin, Sebastian and Samek, Wojciech , booktitle =. 2024 , editor =
2024
-
[69]
2023 , howpublished =
Achtibat, Reduan and Hatefi, Sayed Mohammad Vakilzadeh and Dreyer, Maximilian and Lapuschkin, Sebastian and Samek, Wojciech , title =. 2023 , howpublished =
2023
-
[70]
2016 , eprint=
Layer-wise Relevance Propagation for Neural Networks with Local Renormalization Layers , author=. 2016 , eprint=
2016
-
[71]
Synthesis Lectures on Computer Architecture , volume=
Efficient methods and hardware for deep learning , author=. Synthesis Lectures on Computer Architecture , volume=. 2020 , publisher=
2020
-
[72]
Advances in Neural Information Processing Systems , volume=
Compressing neural networks: Towards determining the optimal layer-wise decomposition , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
2014 , eprint=
Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation , author=. 2014 , eprint=
2014
-
[74]
European Conference on Computer Vision (ECCV) , year=
XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks , author=. European Conference on Computer Vision (ECCV) , year=
-
[76]
International Conference on Learning Representations (ICLR) , year=
Pruning Filters for Efficient ConvNets , author=. International Conference on Learning Representations (ICLR) , year=
-
[77]
Distilling the Knowledge in a Neural Network , author=
-
[78]
arXiv preprint arXiv:2402.09352 , year=
MiniLLM: Efficient Pretraining for Language Models via Scaled Down LLMs , author=. arXiv preprint arXiv:2402.09352 , year=
-
[79]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[80]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Accelerating very deep convolutional networks for classification and detection , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[81]
Advances in Neural Information Processing Systems , volume=
MLP-Mixer: An all-MLP architecture for vision , author=. Advances in Neural Information Processing Systems , volume=
-
[82]
and Ermon, Stefano and Rudra, Atri and R
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R. Flash. Advances in Neural Information Processing Systems , year=
-
[83]
arXiv preprint arXiv:2305.13048 , year=
RWKV: Reinventing RNNs for the transformer era , author=. arXiv preprint arXiv:2305.13048 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.