FORGE: Fused On-Register Gradient Elimination for Memory-Efficient LLM Training
Pith reviewed 2026-06-26 09:08 UTC · model grok-4.3
The pith
Fusing the optimizer step into the backward pass eliminates the need to store full gradient tensors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
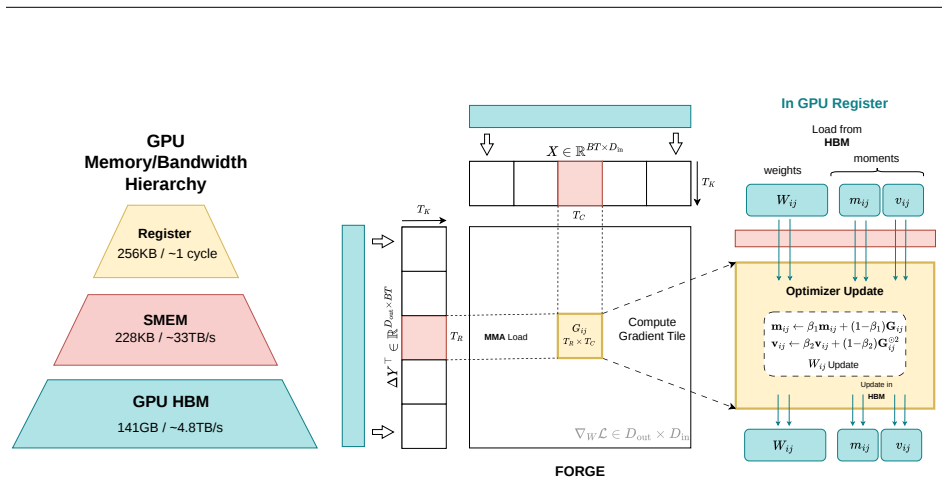
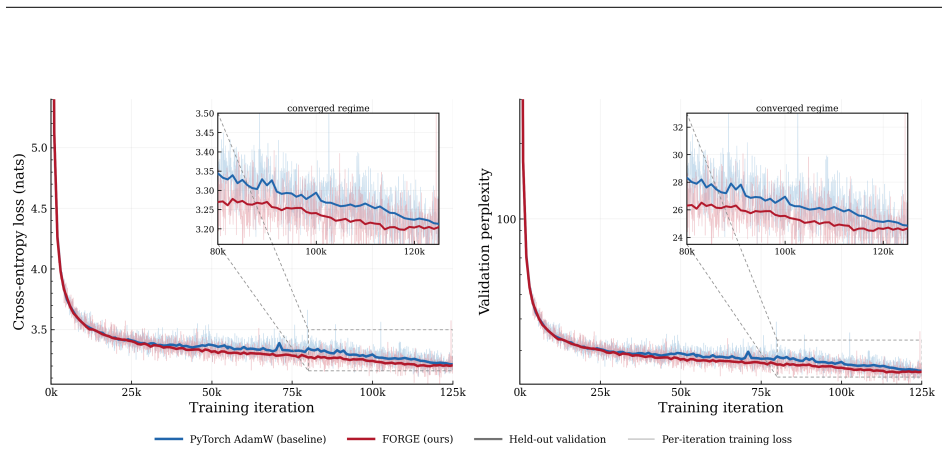
Reverse-mode differentiation computes every weight gradient, writes it to memory, and only then lets the optimizer read it back. FORGE folds the optimizer step into the backward pass and applies it one tile at a time, entirely in registers, so each gradient tile is consumed the instant it is produced and never becomes a tensor. In full precision the fused step is provably exact—the identical optimizer update, for every element-wise rule—and that exactness survives tensor- and sequence-parallel sharding. In the bf16 and 8-bit regimes the deviation is bounded and, for the weight store, rendered unbiased by stochastic rounding. Because each gradient tile is born and consumed in the same registe
What carries the argument
On-register fusion of gradient computation with the immediate element-wise optimizer update, which consumes each tile without materializing the full gradient tensor.
If this is right
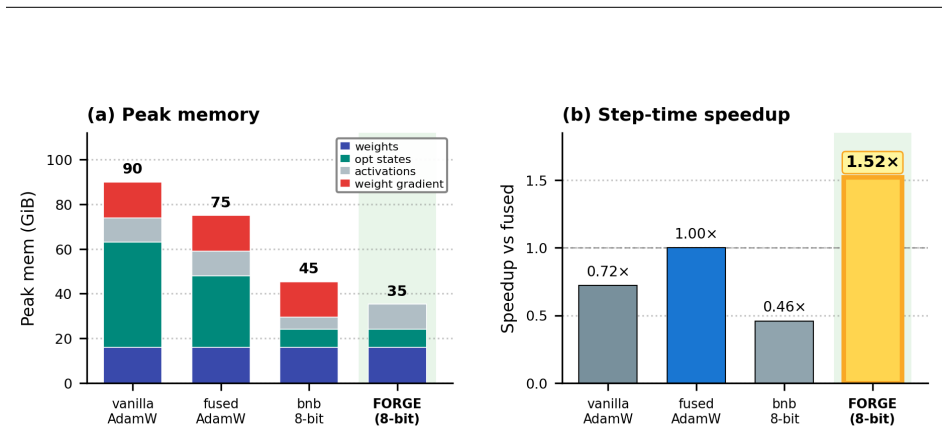
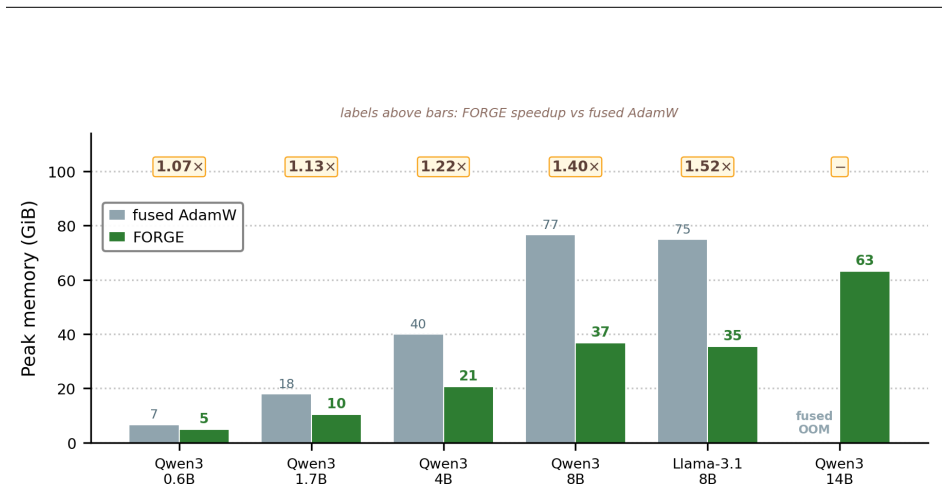
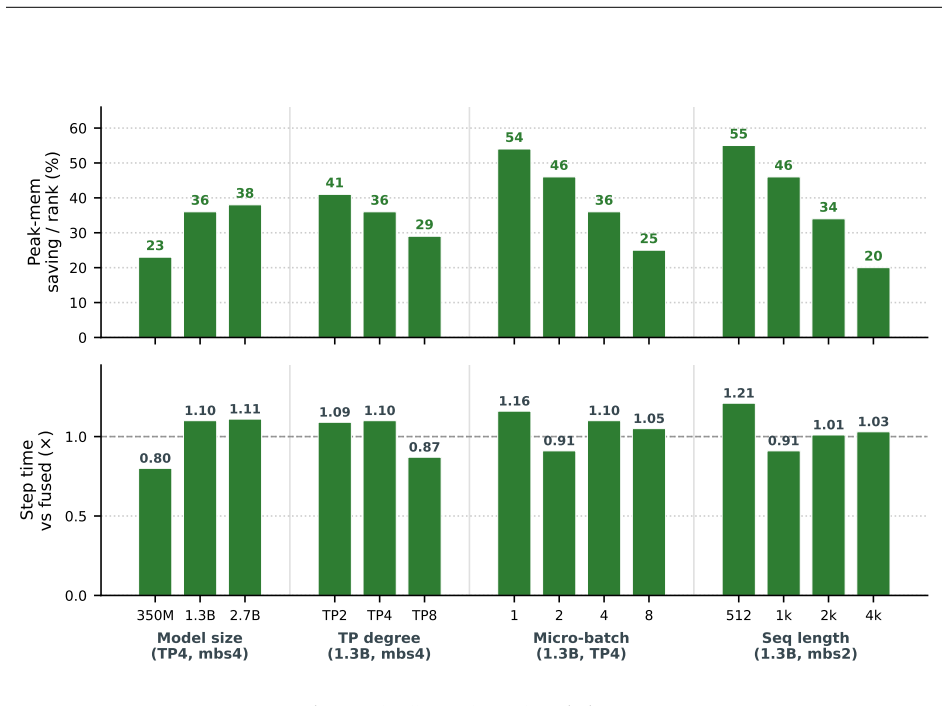
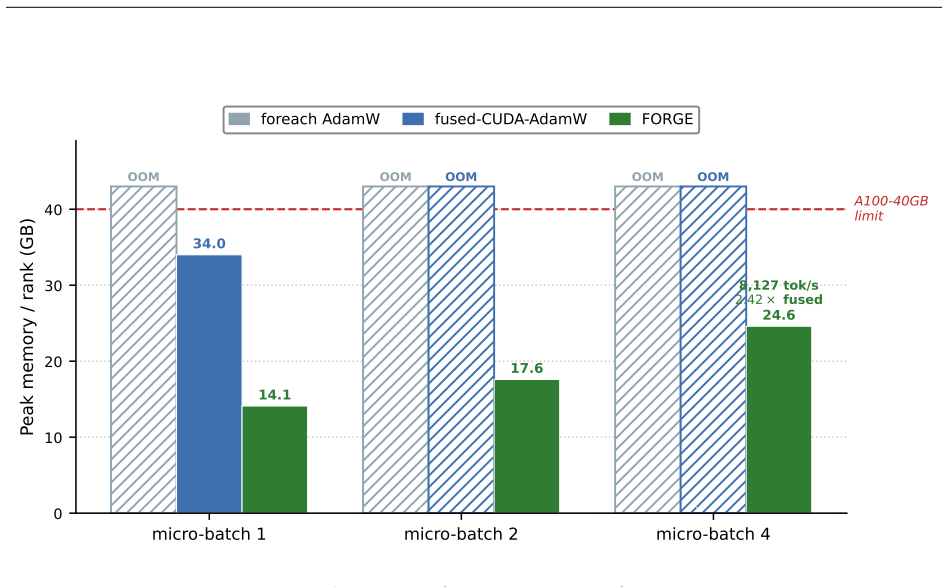
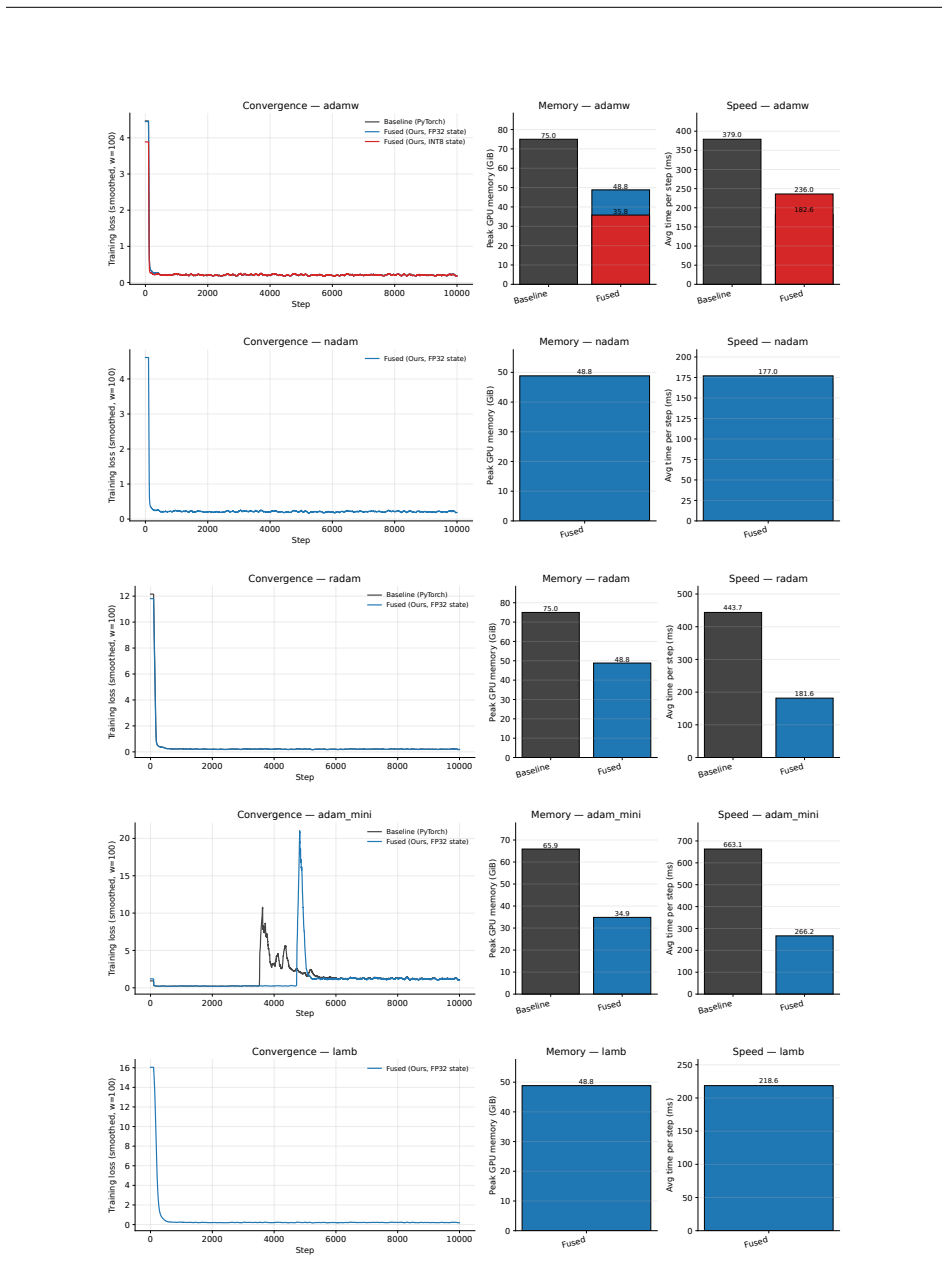
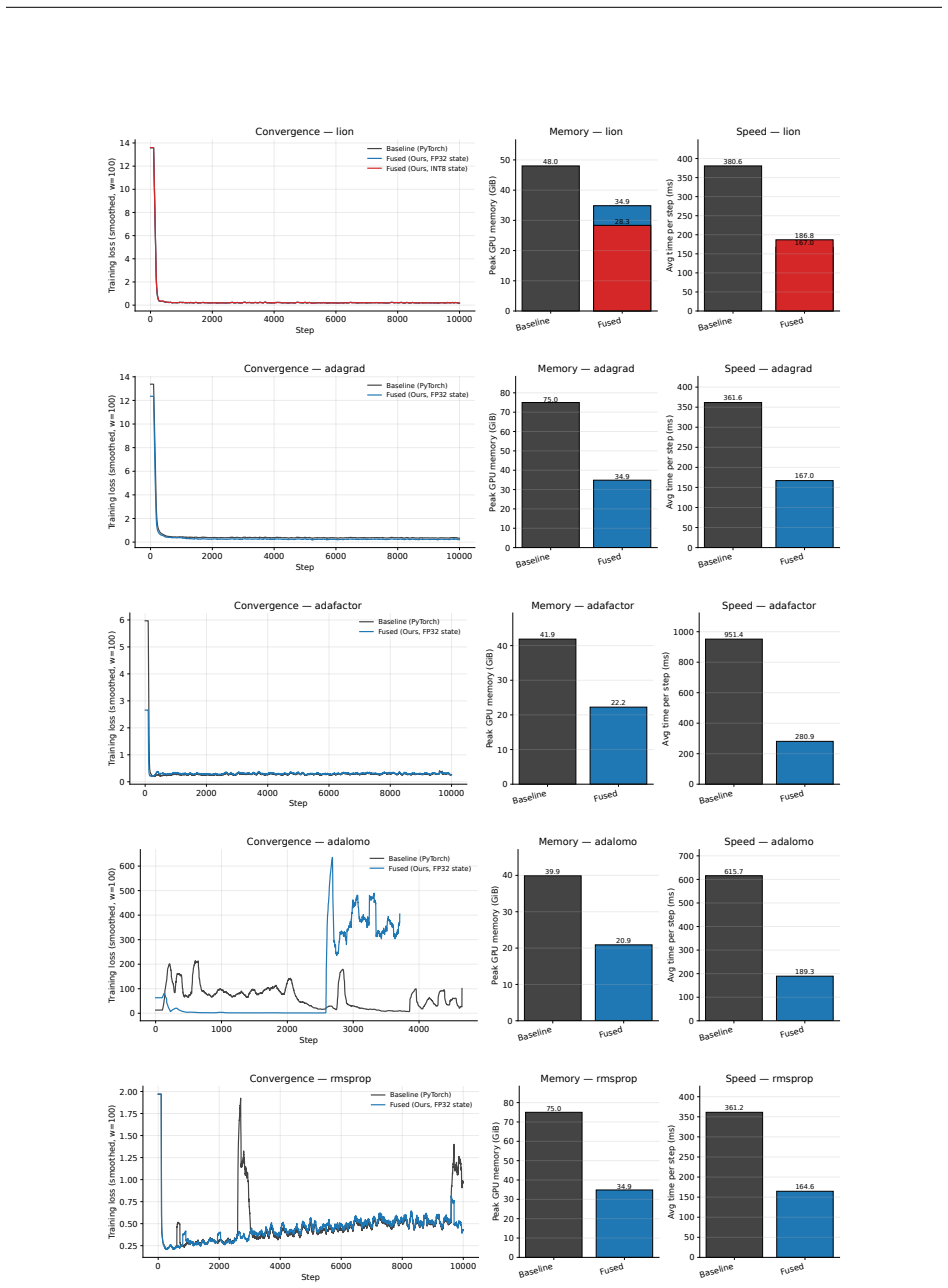
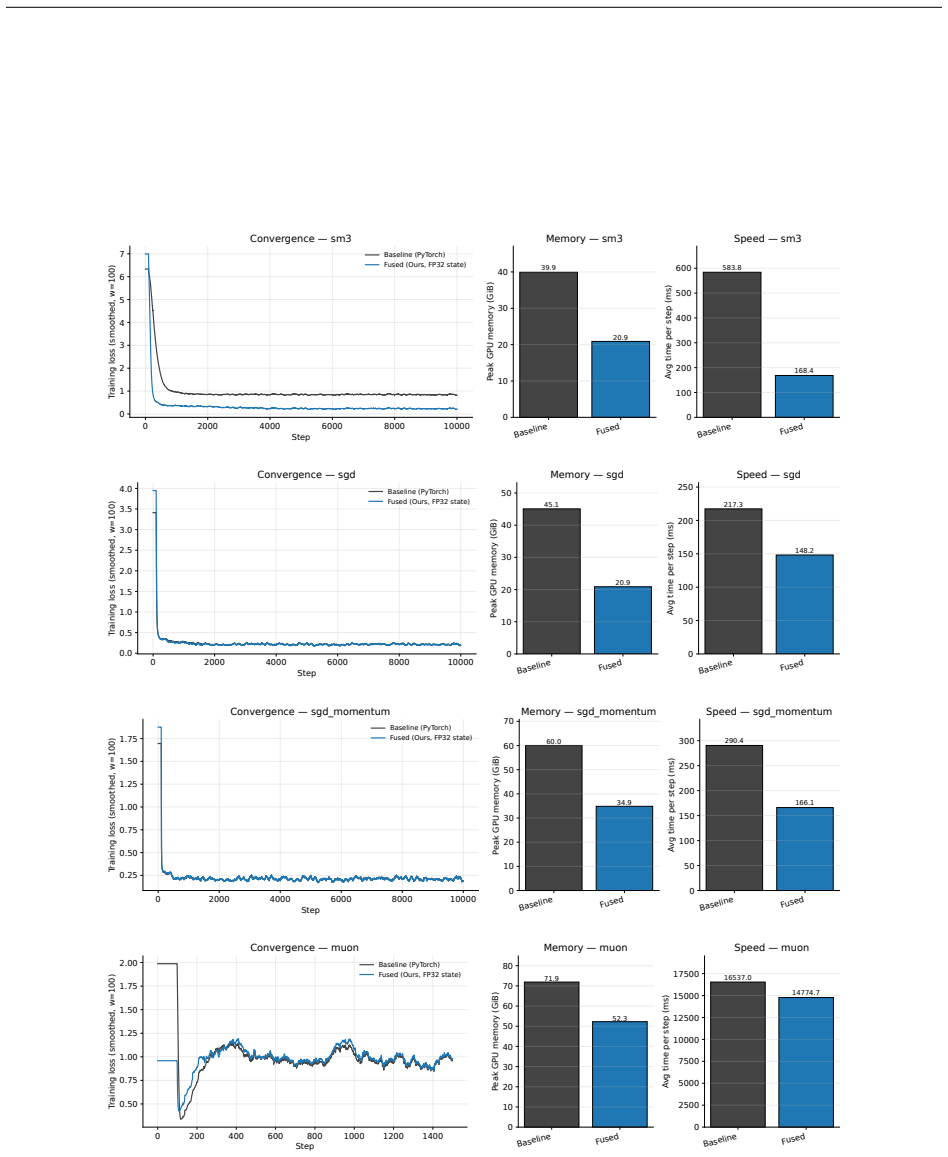
- Memory required for the optimizer step is more than halved.
- At the small batch sizes typical of fine-tuning, training runs about 1.5 times faster.
- When integrated with tensor-parallel sharding, the same hardware can support four times larger micro-batches for an 8B model.
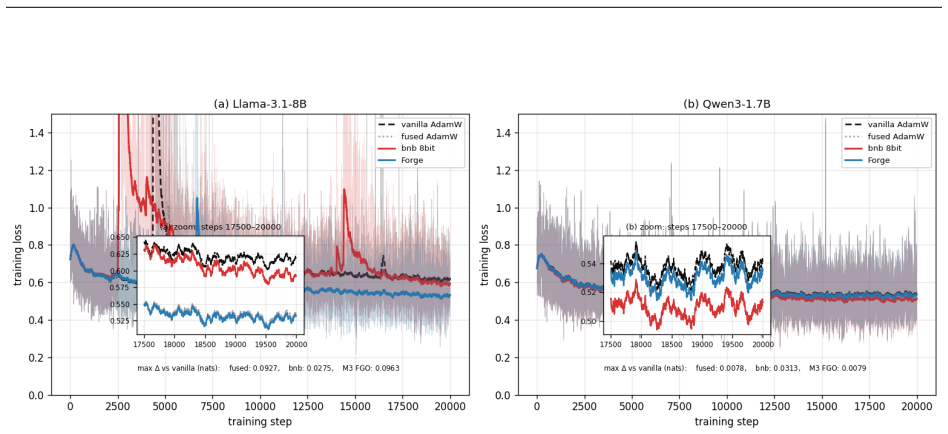
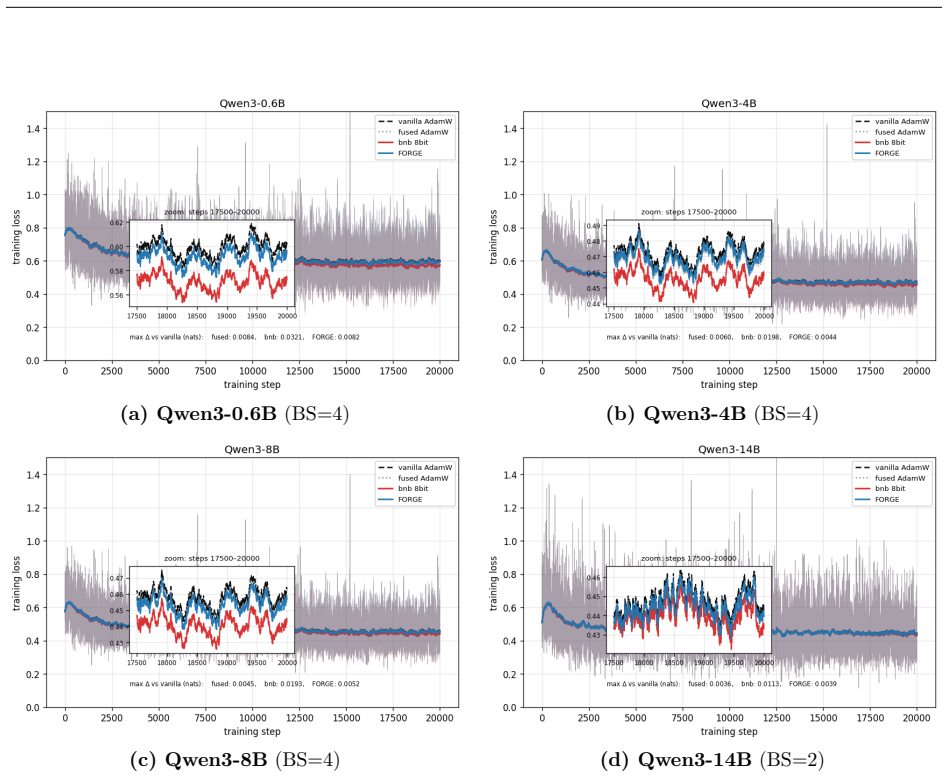
- Full-precision fidelity is preserved because gradients never undergo the down-conversion required for storage in other low-precision schemes.
- The method applies to any linear layer under any element-wise optimizer rule.
Where Pith is reading between the lines
- The tile-wise consumption pattern could be extended to other element-wise operations that occur after the backward pass if they admit register-level fusion.
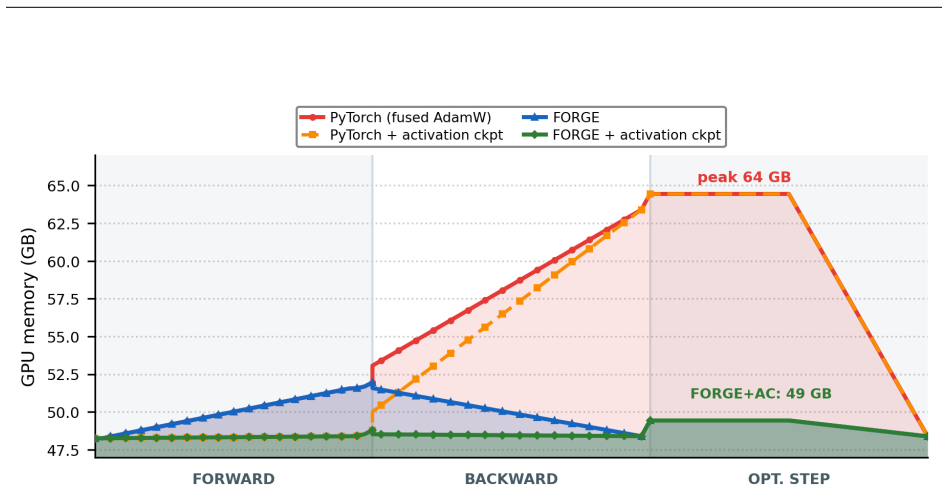
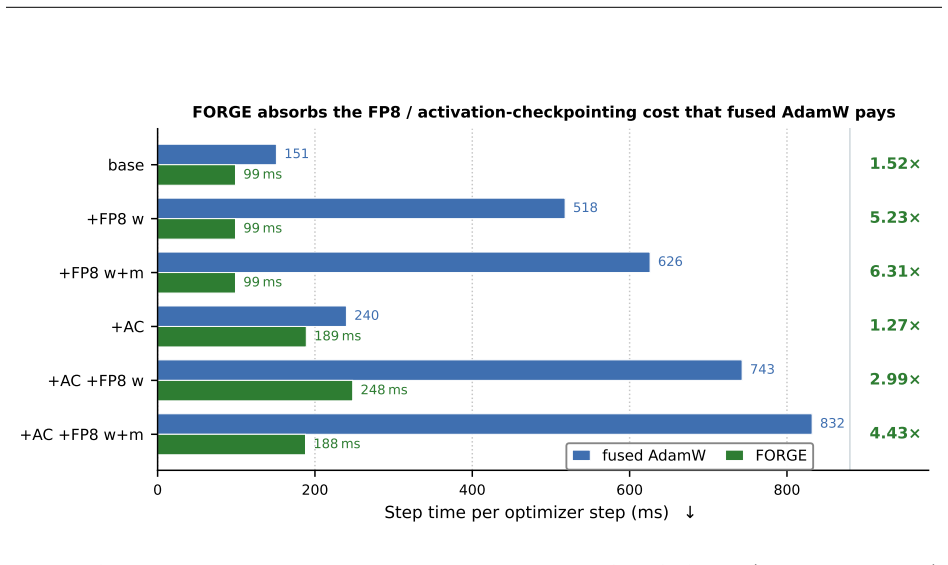
- Lower memory pressure on gradients might allow activation checkpointing to be relaxed in some training regimes without increasing peak memory.
- The avoidance of extra quantization steps for stored gradients could reduce accumulated rounding error in long training runs.
- Because the fusion survives sequence parallelism, it may directly benefit long-context training where activation memory is already high.
Load-bearing premise
Every optimizer rule used in practice must be strictly element-wise so that partial tiles can be updated independently without changing the final result.
What would settle it
A side-by-side execution of one optimizer step on a small model in full precision, comparing the exact weight values produced by the standard two-phase method versus the fused method.
Figures
read the original abstract
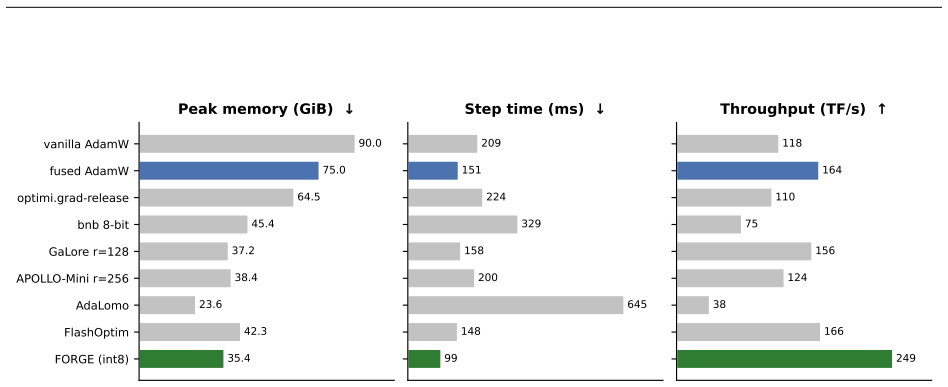
Reverse-mode differentiation computes every weight gradient, writes it to memory, and only then lets the optimizer read it back. This two-phase schedule sets the memory ceiling of modern training: at the seam between the phases, every layer's gradient is live at once. We argue that this materialized gradient is an artifact of how differentiation is staged, not a quantity that learning requires -- and we eliminate it. FORGE folds the optimizer step into the backward pass and applies it one tile at a time, entirely in registers, so each gradient tile is consumed the instant it is produced and never becomes a tensor. The fusion changes only when the update happens, not what it computes: in full precision the fused step is provably exact -- the identical optimizer update, for every element-wise rule -- and that exactness survives tensor- and sequence-parallel sharding; in the bf16 and 8-bit regimes used in practice it is faithful rather than bit-identical, its deviation bounded and, for the weight store, rendered unbiased by stochastic rounding. Because each gradient tile is born and consumed in the same registers, it is never converted down to bf16 to be stored and read back; FORGE thus preserves the full-precision fidelity that both bf16 and 8-bit optimizers lose to that conversion. Nor is the method tied to one architecture or one optimizer: linear layers are ubiquitous, and FORGE reclaims the gradient memory of any of them under any element-wise rule. Empirically FORGE more than halves the memory of an optimizer step and, at the small batch sizes typical of fine-tuning and continued pretraining, runs about 1.5x faster; integrated into tensor-parallel Megatron-LM it fits 8B training at four times the micro-batch a standard optimizer allows on the same GPUs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FORGE, a technique that fuses element-wise optimizer updates into the backward pass of reverse-mode autodiff, processing gradients tile-by-tile entirely in registers so that no full gradient tensor is ever materialized. It claims that in full precision the result is mathematically identical to the standard two-phase schedule for any element-wise optimizer rule, that this equivalence is preserved under tensor and sequence parallelism, and that in reduced-precision regimes the deviation is bounded and unbiased for the weights via stochastic rounding. Empirically it reports more than 2x reduction in optimizer memory and ~1.5x speedup at small batch sizes, enabling 4x larger micro-batches for 8B models inside Megatron-LM.
Significance. If the exactness claim holds, the work directly attacks the gradient-materialization bottleneck that dominates memory usage in LLM training. The ability to reclaim gradient memory for any linear layer under arbitrary element-wise rules, while preserving full-precision fidelity that bf16/8-bit optimizers normally lose, would be a practical advance for fine-tuning and continued pretraining. The sharding invariance is a particularly useful property for distributed training.
major comments (2)
- [Abstract / correctness argument] Abstract and the central correctness argument: the manuscript asserts that the fused on-register update is provably identical to the standard optimizer step for every element-wise rule, yet the explicit derivation (including the handling of tile boundaries, accumulation order, and why no cross-tile dependencies arise) is not supplied. This equivalence is the load-bearing claim for both the full-precision guarantee and the sharding invariance.
- [Abstract / scope of element-wise rules] The weakest assumption noted in the stress test—that every practical optimizer rule is strictly element-wise and that tiling introduces neither numerical nor synchronization side-effects—receives no counter-example analysis or formal statement of the class of supported rules (e.g., whether Adam’s second-moment state or any non-element-wise preconditioner would break the argument).
minor comments (2)
- [Empirical results] Reported speedups and memory numbers lack error bars, baseline implementation details (exact Megatron version, optimizer hyperparameters), and hardware specifications.
- [Method description] Notation for “tile” and “register” residency is used without a precise definition or pseudocode that would allow reproduction of the fusion schedule.
Simulated Author's Rebuttal
We thank the referee for the positive summary and for identifying the two points that require strengthening. Both comments correctly note that the abstract states strong claims without the supporting formal material; we will revise the manuscript to supply the requested derivation and formal scope statement.
read point-by-point responses
-
Referee: [Abstract / correctness argument] Abstract and the central correctness argument: the manuscript asserts that the fused on-register update is provably identical to the standard optimizer step for every element-wise rule, yet the explicit derivation (including the handling of tile boundaries, accumulation order, and why no cross-tile dependencies arise) is not supplied. This equivalence is the load-bearing claim for both the full-precision guarantee and the sharding invariance.
Authors: We agree that the explicit derivation is absent from the current manuscript. Section 3 sketches the argument at a high level but does not provide the tile-by-tile expansion, accumulation-order invariance, or proof that element-wise independence precludes cross-tile data dependencies. We will add a dedicated subsection (or appendix) containing the full derivation: because each optimizer step is a per-element function of the corresponding gradient entry, weight entry, and optimizer state, the result of applying the update to a tile is independent of all other tiles; hence register-level processing yields a mathematically identical weight update regardless of tiling or sharding. The same independence immediately implies invariance under tensor and sequence parallelism. Revision will be made. revision: yes
-
Referee: [Abstract / scope of element-wise rules] The weakest assumption noted in the stress test—that every practical optimizer rule is strictly element-wise and that tiling introduces neither numerical nor synchronization side-effects—receives no counter-example analysis or formal statement of the class of supported rules (e.g., whether Adam’s second-moment state or any non-element-wise preconditioner would break the argument).
Authors: We will add both the requested formal statement and counter-example analysis. The supported class is defined as any optimizer whose update for each parameter is a strictly element-wise function of that parameter’s gradient, current value, and per-parameter optimizer state (explicitly including Adam’s first- and second-moment buffers, which remain element-wise). We will state that non-element-wise preconditioners (e.g., those requiring matrix inverses or cross-parameter statistics) fall outside the class and cannot be fused without materializing the full gradient; a short counter-example paragraph will illustrate the breakage. Because all operations remain local to a tile, no additional synchronization is introduced. Revision will be made. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claim asserts that the fused on-register update produces the identical optimizer step (for any element-wise rule) in full precision, with the property preserved under sharding, because only the timing of the update is altered. This follows directly from the definition of element-wise arithmetic and the absence of cross-tile dependencies in the stated scope; no equations, fitted parameters, or self-citation chains are invoked to derive the exactness result. The argument is scoped to implementation mechanics of gradient materialization and does not reduce the claimed identity to any input quantity by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optimizer update rules are strictly element-wise operations that commute with tiling.
Reference graph
Works this paper leans on
-
[1]
doi: 10.48550/arxiv.2406.16793. Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. GaLore: Memory-efficient LLM training by gradient low-rank projection. InInternational Conference on Machine Learning, 2024. doi: 10.48550/arxiv.2403.03507. Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Les...
-
[2]
AdamW (Loshchilov & Hutter, 2019): first and second moments, decoupled weight decay
2019
-
[3]
NAdam: AdamW with Nesterov momentum correction onˆm
-
[4]
RAdam: AdamW with rectified-variance term
-
[5]
Lion: sign-of-momentum update with a single moment buffer
-
[6]
RMSprop: second moment only, no first moment
-
[7]
AdaGrad: cumulative squared gradient (no decay)
-
[8]
SGD: vanilla gradient descent (no moment buffers)
-
[9]
SGD with momentum: single moment, no second moment. (ii) Linear-layer fusion only (standard optimizer step).These five couple coordinates through a row, column, block, or global statistic, so the update cannot be formed inside one tile; FORGE runs the tiled linear-layer backward and applies the optimizer as a standard step. They are included to show the l...
-
[10]
Adam-mini (Zhang et al., 2025): AdamW with shared per-block second moment
2025
-
[11]
Adafactor (Shazeer & Stern, 2018): factored (row×column) second-moment statistics
2018
-
[12]
AdaLomo (Lv et al., 2024): low-memory AdamW with factored second moment
2024
-
[13]
LAMB: layer-wise adaptive scaling (per-tensor trust ratio)
-
[14]
SM3: per-dimension running max for the cumulative moment. 33 Each fully-fused family replaces the body of Phase 2 of Algorithm 1 with∼10 lines of Triton arithmetic; the wgrad mainloop (Phase 1) and the state read/write pattern (Phase 3) are unchanged. Cross-element preconditioners (Muon’s Newton–Schulz orthogonalization (Jordan et al., 2024), Shampoo, SOA...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.