LEGS: Fine-Tuning Teleop-Free VLAs for Humanoid Loco-manipulation in an Embodied Gaussian Splatting World
Pith reviewed 2026-06-28 16:43 UTC · model grok-4.3
The pith
A policy trained purely on synthetic LEGS data matches or exceeds one trained on human teleoperation demos across all humanoid pick-and-place experiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
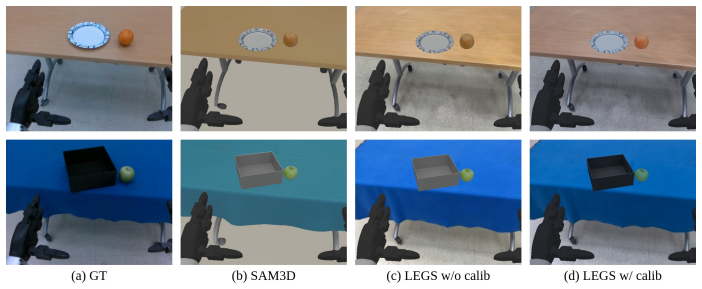
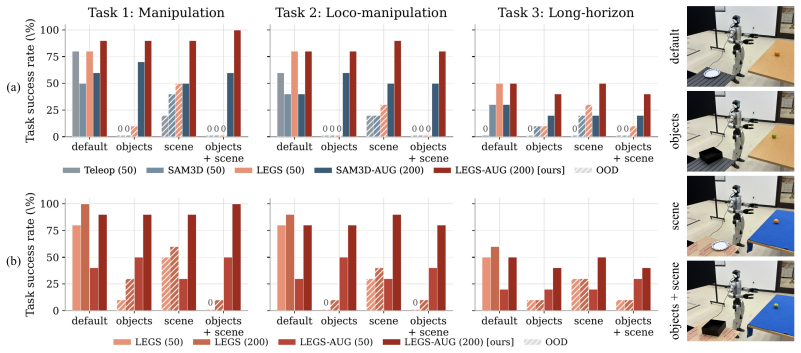
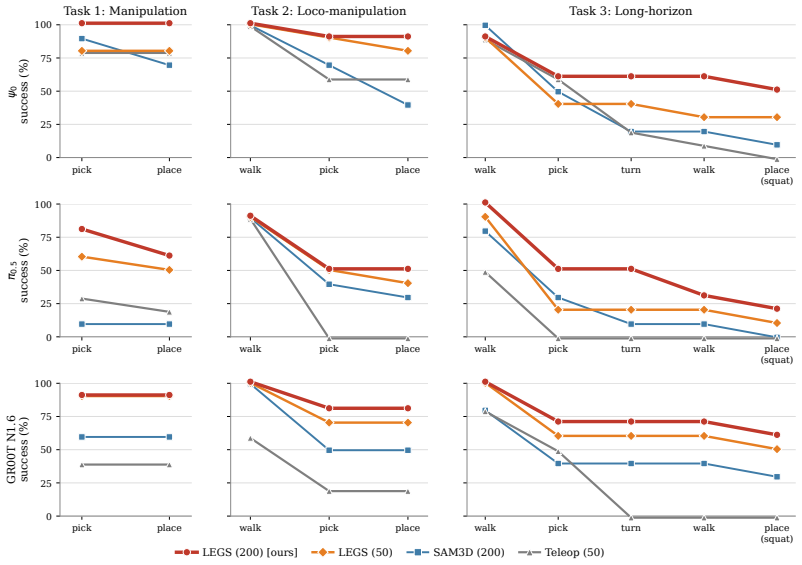
On three pick-and-place tasks of increasing whole-body difficulty and across three VLA backbones, a policy trained purely on LEGS data matches or exceeds one trained on human teleoperation demos on every experiment; the 3DGS background is essential, as shown by outperformance over a mesh-only simulation baseline, and re-rendered LEGS-AUG data maintains success under combined object-and-scene appearance shift while teleoperation-trained baselines fail entirely.
What carries the argument
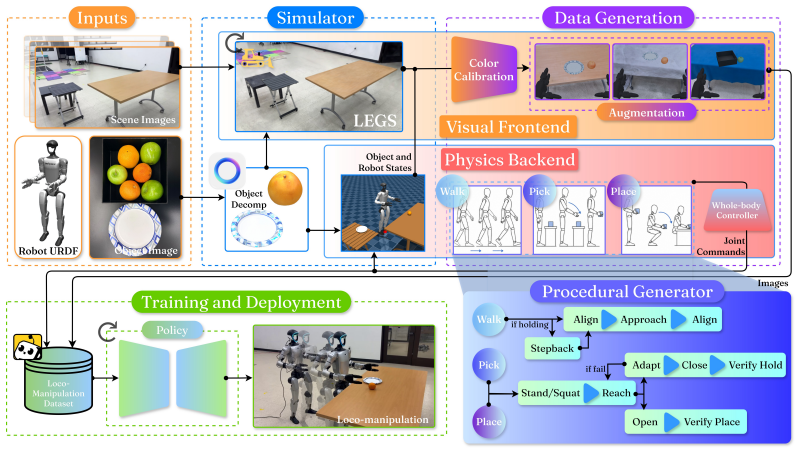
Hybrid simulator that composites a mesh foreground over a photorealistic 3D Gaussian Splatting background, paired with a procedural motion-primitive generator for demonstration synthesis and a deterministic two-stage color calibration for sim-to-real alignment.
If this is right
- Training data volume can be scaled without additional human effort because motion is recorded independently of scene appearance.
- The same set of motion demonstrations can be re-rendered under new object meshes and backgrounds at more than 15 times lower cost than collecting new teleoperation data.
- Policies become more robust to combined object and scene appearance shifts when trained on the re-rendered LEGS-AUG data.
Where Pith is reading between the lines
- The separation of motion capture from visual rendering could allow a single motion dataset to support training across many different real-world environments without new robot deployments.
- If color calibration proves stable across different camera models, the method could extend to fleets of robots with heterogeneous sensors.
- The performance gap closed by photorealistic backgrounds suggests that future sim-to-real work for loco-manipulation should prioritize scene appearance fidelity over further increases in mesh geometric accuracy.
Load-bearing premise
The procedural motion-primitive generator produces demonstrations whose distribution is close enough to real human teleoperation that policies trained on them transfer successfully to the physical robot after color calibration.
What would settle it
Record a policy trained only on LEGS data on the physical Unitree G1 performing one of the three pick-and-place tasks and observe whether its success rate falls below that of an otherwise identical policy trained on the human teleoperation dataset.
Figures




read the original abstract
Training vision-language-action (VLA) policies for humanoid loco-manipulation is constrained by the high cost and complexity of collecting human teleoperation demonstrations. VLA policies fine-tuned in simulators have, until now, failed to transfer effectively in humanoid loco-manipulation tasks. We present LEGS (Loco-manipulation via Embodied Gaussian Splatting), a hybrid simulator that composites a mesh foreground (robot, objects, props) over a photorealistic 3D Gaussian Splatting (3DGS) background reconstructed from a handheld scene capture. LEGS uses a procedural motion-primitive generator to synthesize labeled demonstrations at scale without human teleoperation, and a deterministic two-stage color calibration to align the rendered 3DGS image to the robot's deployment camera. On a Unitree G1 humanoid robot, across three pick-and-place tasks of increasing whole-body difficulty and three VLA backbones (psi_0, pi_0.5, GR00T N1.6), a policy trained purely on LEGS data matches or exceeds one trained on human teleoperation demos on every experiment. It also outperforms a mesh-only simulation baseline that ablates the effect of the 3DGS background, showing that photorealistic rendering is a key enabler for synthetic data transfer. Humanoid motion is recorded independently of scene appearance in LEGS, allowing the same auto-generated demonstrations to be re-rendered under new backgrounds and object meshes--covering a new scene at more than 15x lower cost than teleoperation--to augment training data for robustness to scene variations. Under combined object-and-scene appearance shift, the policy trained on re-rendered LEGS-AUG data maintains task success while the baseline trained on teleoperation data fails entirely. Our project page is located at https://legsvla.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LEGS, a hybrid simulator that composites mesh foregrounds (robot, objects) over photorealistic 3D Gaussian Splatting backgrounds reconstructed from handheld captures. It uses a procedural motion-primitive generator to synthesize labeled VLA demonstrations at scale without human teleoperation, combined with deterministic color calibration for sim-to-real transfer. On a Unitree G1 humanoid, policies trained purely on LEGS data match or exceed teleoperation-trained policies across three pick-and-place tasks of increasing difficulty and three VLA backbones (psi_0, pi_0.5, GR00T N1.6). An ablation shows the 3DGS background outperforms mesh-only rendering, and re-rendering the same motion primitives under new scenes enables low-cost data augmentation that maintains performance under appearance shifts where teleop baselines fail.
Significance. If the central empirical claims hold, LEGS offers a scalable path to teleop-free VLA training for humanoid loco-manipulation by decoupling motion generation from scene appearance and leveraging 3DGS for photorealism. The physical-robot validation across multiple backbones and tasks, plus the re-rendering augmentation result, would represent a practical advance over prior sim-to-real failures in this domain. Strengths include direct hardware transfer experiments and an ablation isolating the rendering component.
major comments (3)
- [§3.2] §3.2 (Procedural Motion-Primitive Generator): No quantitative metrics (e.g., histograms or statistical tests on joint-angle trajectories, velocity profiles, or inter-joint coordination) are reported comparing the generated primitives to the human teleoperation dataset. The headline result—that LEGS policies match or exceed teleop policies on physical transfer—requires that the motion distribution be sufficiently close; the mesh-only ablation tests rendering but leaves this motion-distribution assumption untested and load-bearing.
- [Results section (Tables 1–3)] Results section (Tables 1–3 and associated text): Success rates are summarized as “matches or exceeds” without reporting exact percentages, number of evaluation trials per condition, standard deviations, or statistical significance tests. This makes it impossible to judge effect size, variability, or whether parity holds under the reported task difficulties.
- [§5.2] §5.2 (Re-rendering for new scenes): The claim that the same auto-generated demonstrations can be re-rendered under new backgrounds at >15× lower cost inherits the same unverified motion-distribution premise; if the primitives lack human-like variability, the robustness benefit under combined object-and-scene shift may not generalize beyond the tested tasks.
minor comments (2)
- [Figure 3] Figure 3 (color calibration pipeline): the deterministic two-stage procedure is described at a high level; adding the exact calibration equations or pseudocode would improve reproducibility.
- [Related work] Related work section: the discussion of prior sim-to-real VLA efforts could cite additional recent humanoid-specific works on procedural generation to better situate the novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the empirical validation of our motion primitives and results reporting. We address each major comment below and will revise the manuscript to incorporate additional quantitative analyses and precise statistical details where feasible.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Procedural Motion-Primitive Generator): No quantitative metrics (e.g., histograms or statistical tests on joint-angle trajectories, velocity profiles, or inter-joint coordination) are reported comparing the generated primitives to the human teleoperation dataset. The headline result—that LEGS policies match or exceed teleop policies on physical transfer—requires that the motion distribution be sufficiently close; the mesh-only ablation tests rendering but leaves this motion-distribution assumption untested and load-bearing.
Authors: We agree that direct quantitative comparison of motion distributions would provide stronger support for the claim. The procedural generator was designed to approximate human-like coordination via parameterized primitives, and hardware transfer success offers indirect validation, but we acknowledge the assumption is load-bearing. In revision, we will add histograms of joint-angle trajectories and velocity profiles, along with statistical comparisons (e.g., Wasserstein distances or KS tests) between generated primitives and the teleoperation dataset in an expanded §3.2. revision: yes
-
Referee: [Results section (Tables 1–3)] Results section (Tables 1–3 and associated text): Success rates are summarized as “matches or exceeds” without reporting exact percentages, number of evaluation trials per condition, standard deviations, or statistical significance tests. This makes it impossible to judge effect size, variability, or whether parity holds under the reported task difficulties.
Authors: The original tables contain per-task success counts, but the text and captions summarize rather than enumerate exact values, trial numbers, and variability. We will revise the Results section and Tables 1–3 to report exact success percentages, the number of evaluation trials (e.g., 20 per condition), standard deviations across runs, and statistical significance tests (paired t-tests or McNemar’s test) comparing LEGS vs. teleoperation policies. revision: yes
-
Referee: [§5.2] §5.2 (Re-rendering for new scenes): The claim that the same auto-generated demonstrations can be re-rendered under new backgrounds at >15× lower cost inherits the same unverified motion-distribution premise; if the primitives lack human-like variability, the robustness benefit under combined object-and-scene shift may not generalize beyond the tested tasks.
Authors: The motion primitives are generated independently of scene appearance by design, enabling the re-rendering augmentation at low cost; the empirical result that LEGS-AUG maintains performance under shifts where teleoperation fails provides direct evidence of utility. We will add a clarifying paragraph in §5.2 emphasizing this decoupling and noting that the reported robustness holds for the tested tasks and backbones, while acknowledging that broader variability analysis would further support generalization claims. revision: partial
Circularity Check
No circularity: empirical robot experiments are independent of synthesis assumptions
full rationale
The paper reports direct physical-robot success rates comparing policies trained on LEGS procedural data versus human teleoperation data across three tasks and three backbones. These are external benchmarks measured on the Unitree G1; no equations, fitted parameters, or self-citations reduce the reported metrics to the procedural generator by construction. The motion-primitive generator is an input whose distribution closeness to human demos is an empirical premise tested by the transfer results themselves, not a definitional loop. The 3DGS rendering ablation and re-rendering claims are likewise measured outcomes, not self-referential. This is the common case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[2]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. π0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[3]
J. Bjorck, F. Casta˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[4]
Firoozi, J
R. Firoozi, J. Tucker, S. Tian, A. Majumdar, J. Sun, W. Liu, Y . Zhu, S. Song, A. Kapoor, K. Hausman, et al. Foundation models in robotics: Applications, challenges, and the future. The International Journal of Robotics Research, 44(5):701–739, 2025
2025
-
[5]
T. He, Z. Luo, X. He, W. Xiao, C. Zhang, W. Zhang, K. Kitani, C. Liu, and G. Shi. Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning. 2024
2024
-
[6]
Y . Ze, Z. Chen, J. P. Ara´ujo, Z.-a. Cao, X. B. Peng, J. Wu, and C. K. Liu. Twist: Teleoperated whole-body imitation system.arXiv preprint arXiv:2505.02833, 2025
arXiv 2025
-
[7]
Q. Ben, F. Jia, J. Zeng, J. Dong, D. Lin, and J. Pang. Homie: Humanoid loco-manipulation with isomorphic exoskeleton cockpit. 2025
2025
-
[8]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. 2024
2024
-
[9]
Z. Fu, Q. Zhao, Q. Wu, G. Wetzstein, and C. Finn. Humanplus: Humanoid shadowing and imitation from humans. 2024
2024
-
[10]
Jiang, J
H. Jiang, J. Chen, Q. Bu, L. Chen, M. Shi, Y . Zhang, D. Li, C. Suo, C. Wang, Z. Peng, et al. Wholebodyvla: Towards unified latent vla for whole-body loco-manipulation control. 2025
2025
-
[11]
X. Chen, F.-J. Chu, P. Gleize, K. J. Liang, A. Sax, H. Tang, W. Wang, M. Guo, T. Hardin, X. Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
Pith/arXiv arXiv 2025
-
[12]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimk¨uhler, G. Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[13]
M. Shi, S. Peng, J. Chen, H. Jiang, Y . Li, D. Huang, P. Luo, H. Li, and L. Chen. Egohumanoid: Unlocking in-the-wild loco-manipulation with robot-free egocentric demonstration.arXiv preprint arXiv:2602.10106, 2026
Pith/arXiv arXiv 2026
-
[14]
C. Lu, X. Cheng, J. Li, S. Yang, M. Ji, C. Yuan, G. Yang, S. Yi, and X. Wang. Mobile-television: Predictive motion priors for humanoid whole-body control. In2025 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 5364–5371. IEEE, 2025
2025
-
[15]
R. Nai, B. Zheng, J. Zhao, H. Zhu, S. Dai, Z. Chen, Y . Hu, Y . Hu, T. Zhang, C. Wen, et al. Humanoid manipulation interface: Humanoid whole-body manipulation from robot-free demon- strations.arXiv preprint arXiv:2602.06643, 2026. 10
arXiv 2026
-
[16]
S. Wei, H. Jing, B. Li, Z. Zhao, J. Mao, Z. Ni, S. He, J. Liu, X. Liu, K. Kang, S. Zang, W. Yuan, M. Pavone, D. Huang, and Y . Wang.Ψ0: An open foundation model towards universal humanoid loco-manipulation. InRobotics: Science and Systems, 2026. To Appear. Preprint arXiv:2603.12263
arXiv 2026
-
[17]
Y . Fu, F. Xie, C. Xu, J. Xiong, H. Yuan, and Z. Lu. Demohlm: From one demonstration to generalizable humanoid loco-manipulation.arXiv preprint arXiv:2510.11258, 2025
arXiv 2025
-
[18]
T. He, Z. Wang, H. Xue, Q. Ben, Z. Luo, W. Xiao, Y . Yuan, X. Da, F. Casta˜neda, S. Sastry, et al. Viral: Visual sim-to-real at scale for humanoid loco-manipulation.arXiv preprint arXiv:2511.15200, 2025
arXiv 2025
-
[19]
H. Xue, T. He, Z. Wang, Q. Ben, W. Xiao, Z. Luo, X. Da, F. Casta ˜neda, G. Shi, S. Sastry, et al. Opening the sim-to-real door for humanoid pixel-to-action policy transfer.arXiv preprint arXiv:2512.01061, 2025
arXiv 2025
-
[20]
F. Liu, Z. Gu, Y . Cai, Z. Zhou, H. Jung, J. Jang, S. Zhao, S. Ha, Y . Chen, D. Xu, et al. Opt2skill: Imitating dynamically-feasible whole-body trajectories for versatile humanoid loco- manipulation.IEEE Robotics and Automation Letters, 2025
2025
-
[21]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 23–30. IEEE, 2017
2017
-
[22]
J. Sun, A. Curtis, Y . You, Y . Xu, M. Koehle, Q. Chen, S. Huang, L. Guibas, S. Chitta, M. Schwa- ger, et al. Arch: Hierarchical hybrid learning for long-horizon contact-rich robotic assembly. CoRL, 2024
2024
- [23]
-
[24]
Shorinwa, J
O. Shorinwa, J. Tucker, A. Smith, A. Swann, T. Chen, R. Firoozi, M. D. Kennedy, and M. Schwager. Splat-mover: Multi-stage, open-vocabulary robotic manipulation via editable gaussian splatting. 2024
2024
-
[25]
A. Escontrela, J. Kerr, A. Allshire, J. Frey, R. Duan, C. Sferrazza, and P. Abbeel. Gaussgym: An open-source real-to-sim framework for learning locomotion from pixels.arXiv preprint arXiv:2510.15352, 2025
arXiv 2025
-
[26]
Y . Jia, H. Zhang, Z. Zhang, J. Wu, M. Yu, Z. Wang, D. Jiang, Z. Li, C. Cao, Z. Yu, et al. Gs-playground: A high-throughput photorealistic simulator for vision-informed robot learning. arXiv preprint arXiv:2604.25459, 2026
Pith/arXiv arXiv 2026
-
[27]
J. Low, M. Adang, J. Yu, K. Nagami, and M. Schwager. Sous vide: Cooking visual drone navigation policies in a gaussian splatting vacuum.IEEE Robotics and Automation Letters, 2025
2025
-
[28]
Adang, J
M. Adang, J. Low, O. Shorinwa, and M. Schwager. Singer: An onboard generalist vision- language navigation policy for drones. InIEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[29]
Q. Chen, J. Sun, N. Gao, J. Low, T. Chen, and M. Schwager. Grad-nav: Efficiently learning visual drone navigation with gaussian radiance fields and differentiable dynamics. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7941–7948. IEEE, 2025
2025
-
[30]
Q. Chen, N. Gao, S. Huang, J. Low, T. Chen, J. Sun, and M. Schwager. Grad-nav++: Vision- language model enabled visual drone navigation with gaussian radiance fields and differentiable dynamics.IEEE Robotics and Automation Letters, 11(2):1418–1425, 2025. 11
2025
-
[31]
Tucker, D
J. Tucker, D. Liu, A. Swann, A. Ren, J. Yu, J. Sun, B. Kim, L. McGranahan, Q. Vuong, and M. Schwager. π, but make it fly: Physics-guided transfer of vla models to aerial manipulation,
-
[32]
URLhttps://arxiv.org/abs/2603.25038
-
[33]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
2012
-
[34]
J. L. Schonberger and J.-M. Frahm. Structure-from-motion revisited. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
2016
-
[35]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, et al. Sam 2: Segment anything in images and videos. InInternational Conference on Learning Representations, volume 2025, pages 28085–28128, 2025
2025
-
[36]
X. Wei, M. Liu, Z. Ling, and H. Su. Approximate convex decomposition for 3d meshes with collision-aware concavity and tree search.ACM Transactions on Graphics (TOG), 41(4):1–18, 2022
2022
-
[37]
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Castaneda, Z.-A. Cao, J. Li, D. Minor, Q. Ben, et al. Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint arXiv:2511.07820, 2025
Pith/arXiv arXiv 2025
-
[38]
B. Yi, C. M. Kim, J. Kerr, G. Wu, R. Feng, A. Zhang, J. Kulhanek, H. Choi, Y . Ma, M. Tancik, et al. Viser: Imperative, web-based 3d visualization in python.arXiv preprint arXiv:2507.22885, 2025. 12 A Simulator Implementation Details A.1 Reconstruction Pipeline Background reconstruction: (1) iPhone video capture (handheld, ∼1–2 minute sweep of the room), ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.