VT-3DAD: Cross-Category 3D Anomaly Detection via Visual-Text Normal Space Alignment
Pith reviewed 2026-06-28 07:02 UTC · model grok-4.3
The pith
Fusing multi-view visual features with text-encoded semantic normal anchors improves few-shot cross-category 3D anomaly detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
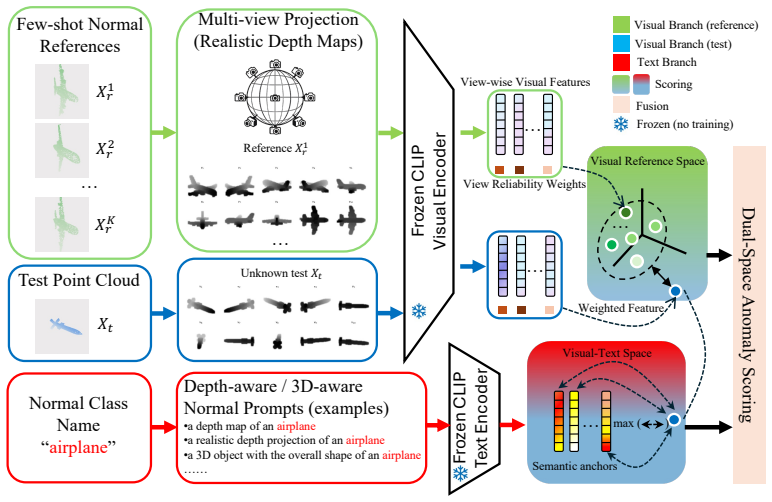
VT-3DAD builds a textual normal space from depth-aware and 3D-aware prompts passed through the frozen CLIP text encoder. These anchors supply category-specific semantic normality constraints that are combined with visual deviation scores computed in multi-view feature space from realistic depth maps of the test point cloud and the few normal references. The fused score determines whether the test sample belongs to the target normal category.
What carries the argument
Visual-Text Normal Space Alignment, which augments multi-view visual similarity with semantic normality constraints from frozen CLIP text prompts to resolve confusion between geometrically similar categories.
If this is right
- Raises one-shot average AUC-ROC on ShapeNetPart from 92.49 percent to 94.80 percent.
- Lowers average standard deviation across runs from 5.64 to 3.41.
- Operates without any category-wise training or optimization steps.
- Produces a single anomaly score by fusing visual reference deviation and semantic deviation from the textual normal space.
Where Pith is reading between the lines
- The same prompt-based semantic anchoring could be tested on real-world scanned point clouds where lighting and sensor noise differ from synthetic data.
- Extending the prompt set to include part-level or material descriptions might further tighten normality constraints for fine-grained categories.
- The training-free design suggests the approach could be paired with existing visual-only pipelines without retraining.
- Performance stability gains may matter most in settings where only one or two normal references are available per category.
Load-bearing premise
Depth-aware and 3D-aware prompts encoded by the frozen CLIP text encoder supply semantic normality constraints that meaningfully improve detection over visual similarity alone.
What would settle it
Running the method on a set of categories that share similar geometry but differ in semantic identity and observing whether the text branch still raises AUC-ROC over the visual-only baseline would test the contribution of the alignment.
Figures

read the original abstract
Few-shot cross-category 3D anomaly detection aims to determine whether an unknown point cloud belongs to a target normal category using only a few normal references. Existing training-based methods usually require category-wise optimization, while recent training-free methods based on multi-view CLIP visual features mainly rely on visual similarity and may be confused by geometrically similar categories. In this paper, we propose VT-3DAD, a training-free framework for cross-category 3D anomaly detection via Visual-Text Normal Space Alignment. Given few-shot normal references and a test point cloud, VT-3DAD first generates realistic multi-view depth maps and extracts view-wise features using a frozen CLIP visual encoder. The visual branch measures reference-test deviation in the multi-view feature space. In parallel, depth-aware and 3D-aware prompts are encoded by the frozen CLIP text encoder to construct textual normal anchors, which provide semantic normality constraints for the target category. The final anomaly score is obtained by fusing visual deviation from normal references and semantic deviation from the textual normal space. Experiments on the ShapeNetPart dataset demonstrate that VT-3DAD achieves state-of-the-art performance. In particular, VT-3DAD improves the one-shot average AUC-ROC from 92.49% to 94.80% compared with the visual-only baseline, while also reducing the average standard deviation from 5.64 to 3.41.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VT-3DAD, a training-free framework for few-shot cross-category 3D anomaly detection via Visual-Text Normal Space Alignment. It generates multi-view depth maps from point clouds, extracts features with a frozen CLIP visual encoder to measure reference-test deviation, constructs textual normal anchors from depth-aware and 3D-aware prompts encoded by the frozen CLIP text encoder, and fuses visual and semantic deviations into a final anomaly score. On ShapeNetPart it reports SOTA results, specifically lifting one-shot average AUC-ROC from 92.49% (visual-only baseline) to 94.80% while reducing average standard deviation from 5.64 to 3.41.
Significance. If the textual normal space supplies independent category-specific 3D normality constraints beyond multi-view visual features, the approach would advance training-free multimodal methods for cross-category 3D anomaly detection. Strengths include the fully frozen CLIP pipeline, absence of category-wise optimization, and the reported variance reduction alongside the AUC gain.
major comments (1)
- [Abstract] Abstract: the central claim of a 2.31-point AUC-ROC lift (and variance reduction) from adding the textual branch is load-bearing, yet the abstract supplies no prompt templates, no statement on whether textual anchors are derived from the few-shot references or generic category names, and no ablation that isolates the text branch while freezing the visual feature extraction, view sampling, and fusion rule. Without these controls the observed gain cannot be attributed to semantic alignment rather than incidental pipeline changes.
minor comments (1)
- [Abstract] Abstract: the phrase 'depth-aware and 3D-aware prompts' is used without any example templates or construction procedure, which hinders reproducibility even at the high-level description.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We address it below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 2.31-point AUC-ROC lift (and variance reduction) from adding the textual branch is load-bearing, yet the abstract supplies no prompt templates, no statement on whether textual anchors are derived from the few-shot references or generic category names, and no ablation that isolates the text branch while freezing the visual feature extraction, view sampling, and fusion rule. Without these controls the observed gain cannot be attributed to semantic alignment rather than incidental pipeline changes.
Authors: We agree the abstract should be self-contained to support the central claim. The manuscript (Section 3.2) constructs textual normal anchors from depth-aware and 3D-aware prompts using generic category names rather than the few-shot references; this design choice enables cross-category generalization without category-specific optimization. The reported 92.49% to 94.80% gain is obtained by direct comparison to the visual-only baseline, which holds visual feature extraction, view sampling, and fusion fixed while adding only the text branch. To make these controls explicit in the abstract itself, we will revise it to include representative prompt templates, state that anchors derive from generic category names, and note the isolating ablation. This change will be incorporated in the revised manuscript. revision: yes
Circularity Check
No significant circularity; framework uses external frozen encoders and independent textual anchors.
full rationale
The derivation relies on frozen external CLIP visual and text encoders to extract multi-view features and encode depth-aware prompts into textual normal anchors. The anomaly score is formed by fusing explicit visual deviation (from few-shot references) and semantic deviation (from the constructed textual space), with performance measured against a stated visual-only baseline on the external ShapeNetPart dataset. No equations, parameter fits, or self-citations appear that reduce the claimed result to its inputs by construction. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization,
P. Bergmann, X. Jin, D. Sattlegger, and C. Steger, “The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization,” arXiv preprint arXiv:2112.09045 (2021)
arXiv 2021
-
[2]
Real3d-ad: A dataset of point cloud anomaly detection,
J. Liu, G. Xie, R. Chen, X. Li, J. Wang, Y . Liu, C. Wang, and F. Zheng, “Real3d-ad: A dataset of point cloud anomaly detection,” Advances in Neural Information Processing Systems36, 30402–30415 (2023)
2023
-
[3]
Multimodal industrial anomaly detection via hybrid fusion,
Y . Wang, J. Peng, J. Zhang, R. Yi, Y . Wang, and C. Wang, “Multimodal industrial anomaly detection via hybrid fusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8032–8041 (2023)
2023
-
[4]
Back to the feature: classical 3d features are (almost) all you need for 3d anomaly detection,
E. Horwitz and Y . Hoshen, “Back to the feature: classical 3d features are (almost) all you need for 3d anomaly detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2968–2977 (2023)
2023
-
[5]
Toward unsupervised 3d point cloud anomaly detec- tion using variational autoencoder,
M. Masuda, R. Hachiuma, R. Fujii, H. Saito, and Y . Sekikawa, “Toward unsupervised 3d point cloud anomaly detec- tion using variational autoencoder,” in 2021 IEEE International Conference on Image Processing (ICIP), 3118–3122, IEEE (2021)
2021
-
[6]
Teacher–student network for 3d point cloud anomaly detection with few normal samples,
J. Qin, C. Gu, J. Yu, and C. Zhang, “Teacher–student network for 3d point cloud anomaly detection with few normal samples,” Expert Systems with Applications228, 120371 (2023)
2023
-
[7]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, and others, “Learning transferable visual models from natural language supervision,” in International conference on machine learning, 8748–8763, PmLR (2021)
2021
-
[8]
Pointclip v2: Prompting clip and gpt for powerful 3d open-world learning,
X. Zhu, R. Zhang, B. He, Z. Guo, Z. Zeng, Z. Qin, S. Zhang, and P. Gao, “Pointclip v2: Prompting clip and gpt for powerful 3d open-world learning,” in Proceedings of the IEEE/CVF international conference on computer vision, 2639–2650 (2023)
2023
-
[9]
Towards zero-shot point cloud anomaly detection: A multi-view projection framework,
Y . Cheng, Y . Cao, G. Xie, Z. Lu, and W. Shen, “Towards zero-shot point cloud anomaly detection: A multi-view projection framework,” arXiv preprint arXiv:2409.13162 (2024)
arXiv 2024
-
[10]
Clip3d-ad: Extending clip for 3d few-shot anomaly detection with multi-view images generation,
Z. Zuo, J. Dong, Y . Wu, Y . Qu, and Z. Wu, “Clip3d-ad: Extending clip for 3d few-shot anomaly detection with multi-view images generation,” arXiv preprint arXiv:2406.18941 (2024)
arXiv 2024
-
[11]
Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection,
Q. Zhou, G. Pang, Y . Tian, S. He, and J. Chen, “Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection,” arXiv preprint arXiv:2310.18961 (2023)
arXiv 2023
-
[12]
Aa-clip: Enhancing zero- shot anomaly detection via anomaly-aware clip,
W. Ma, X. Zhang, Q. Yao, F. Tang, C. Wu, Y . Li, R. Yan, Z. Jiang, and S. K. Zhou, “Aa-clip: Enhancing zero- shot anomaly detection via anomaly-aware clip,” in Proceedings of the Computer Vision and Pattern Recognition Conference, 4744–4754 (2025)
2025
-
[13]
Dmp-3dad: Cross-category 3d anomaly detection via realistic depth map projection with few normal samples,
Z. Wang, K. Hotta, K. Kamide, Y . Zou, J. Qin, C. Zhang, and J. Yu, “Dmp-3dad: Cross-category 3d anomaly detection via realistic depth map projection with few normal samples,” IEICE Transactions on Information and Systems (2026)
2026
-
[14]
Large-scale 3d shape reconstruction and segmentation from shapenet core55,
L. Yi, L. Shao, M. Savva, H. Huang, Y . Zhou, Q. Wang, B. Graham, M. Engelcke, R. Klokov, V . Lempitsky, and oth- ers, “Large-scale 3d shape reconstruction and segmentation from shapenet core55,” arXiv preprint arXiv:1710.06104 (2017)
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.