Bounded-depth spacetime lattice surgery for resource-efficient fault-tolerant quantum computation
Pith reviewed 2026-06-26 14:33 UTC · model grok-4.3
The pith
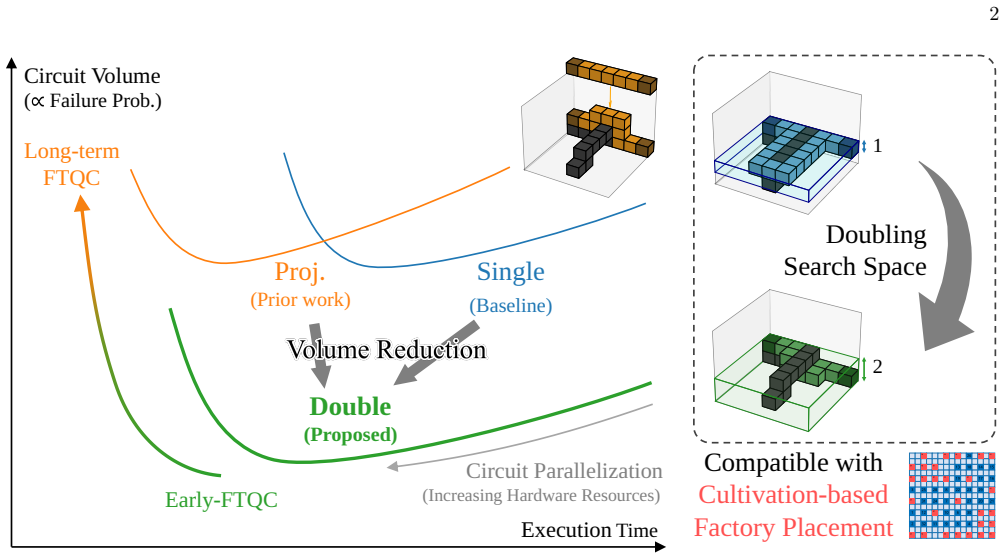
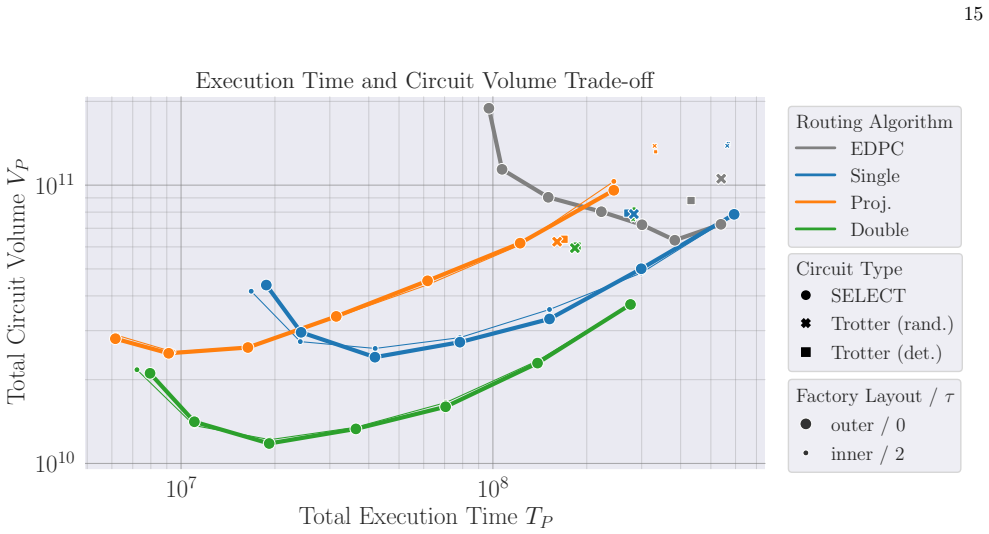
Double-slice routing reduces lattice-surgery compilation cost by up to a factor of 2.4 over single-slice baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
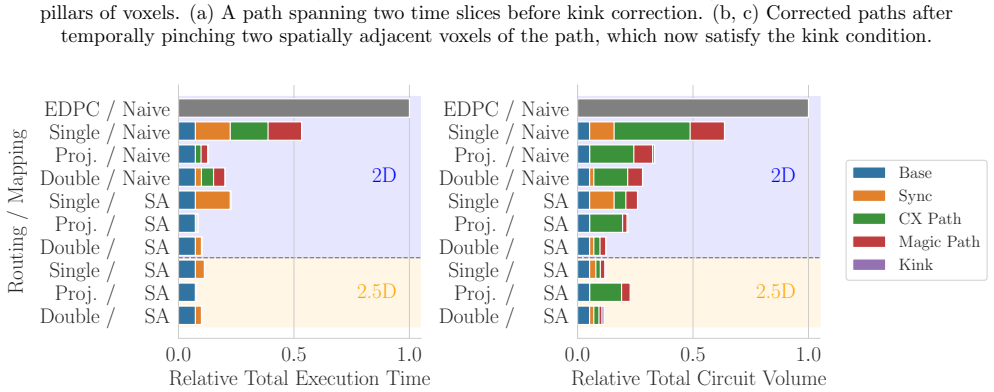
Double-slice routing is a constant-depth spacetime-routing method that uses two consecutive time slices with a guarantee that its kink-parity correction terminates under both planar and stacked architectures. Numerical benchmarks on Hamiltonian-simulation workloads show that double-slice routing reduces compilation cost by up to a factor of 2.4 over a single-slice baseline. Compared to projective routing, an existing method that allows an unbounded number of time slices per path, double-slice routing achieves smaller circuit volume with only a marginal execution-time penalty. Combined with a cultivation-compatible mapping optimization, the overall improvement reaches up to 7.5-fold over a na
What carries the argument
double-slice routing, a bounded-depth spacetime routing technique that employs two consecutive time slices together with kink-parity correction to resolve path conflicts
Load-bearing premise
The kink-parity correction is guaranteed to terminate under both planar and stacked architectures.
What would settle it
A concrete counterexample in which kink-parity correction fails to terminate for a valid path definition under either planar or stacked lattice-surgery architecture would falsify the termination guarantee.
Figures

read the original abstract
Fault-tolerant quantum computing based on lattice surgery requires place-and-route compilation with low spacetime overhead. Routing, in particular, faces a basic tension between suppressing path conflicts through greater spatial allocation and exploiting the time direction to realize ancilla-efficient spacetime routing. Existing approaches do not fully resolve this trade-off while retaining compatibility with inner factory layouts and termination guarantees. Here we introduce double-slice routing, a constant-depth spacetime-routing method that uses two consecutive time slices with a guarantee that its kink-parity correction terminates under both planar and stacked architectures. We numerically benchmark the resulting compiler on Hamiltonian-simulation workloads to show that double-slice routing reduces compilation cost by up to a factor of 2.4 over a single-slice baseline. Compared to projective routing, an existing method that allows an unbounded number of time slices per path, double-slice routing achieves smaller circuit volume with only a marginal execution-time penalty. Combined with a cultivation-compatible mapping optimization, the overall improvement reaches up to 7.5-fold over a naive single-slice compilation baseline. These results identify double-slice routing as a practically useful operating point in lattice-surgery compilation and show the substantial benefit in joint optimization of mapping and routing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces double-slice routing, a bounded-depth spacetime lattice-surgery routing method for fault-tolerant quantum computation. It asserts a termination guarantee for the associated kink-parity correction under both planar and stacked architectures, and reports numerical benchmarks on Hamiltonian-simulation workloads showing up to 2.4× reduction in compilation cost versus a single-slice baseline and up to 7.5× overall improvement when combined with cultivation-compatible mapping optimization, while achieving smaller circuit volume than projective routing at modest execution-time cost.
Significance. If the termination guarantee is established with explicit path and primitive conditions and the benchmarks are fully reproducible, the work supplies a concrete, practically useful point in the spatial-temporal trade-off for ancilla-efficient lattice-surgery compilation, with measurable resource savings on relevant workloads.
major comments (2)
- [Method definition and termination argument] The termination guarantee for kink-parity correction (asserted in the abstract and the method definition) is load-bearing for the constant-depth claim and all subsequent performance numbers, yet the manuscript supplies no lemmas, explicit path definitions, or conditions on the lattice-surgery primitives that would ensure termination for admissible configurations under planar and stacked architectures.
- [Numerical benchmark section] The headline quantitative claims (2.4× and 7.5× compilation-cost reductions) rest on numerical benchmarks whose support cannot be verified from the provided text: no benchmark parameters, error bars, exclusion criteria, or raw data are supplied, undermining assessment of the cross-method comparisons.
minor comments (1)
- [Figures] Figure captions should explicitly state the exact baselines (single-slice, projective, naive) and the metric being plotted (e.g., spacetime volume or compilation cost) for each panel.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and details.
read point-by-point responses
-
Referee: [Method definition and termination argument] The termination guarantee for kink-parity correction (asserted in the abstract and the method definition) is load-bearing for the constant-depth claim and all subsequent performance numbers, yet the manuscript supplies no lemmas, explicit path definitions, or conditions on the lattice-surgery primitives that would ensure termination for admissible configurations under planar and stacked architectures.
Authors: We agree that the termination guarantee is central to the constant-depth claim and that the current presentation would benefit from greater formality. Although the manuscript asserts the guarantee for both architectures, we acknowledge the lack of explicit lemmas, path definitions, and primitive conditions. In the revised version we will add a dedicated subsection containing: precise definitions of admissible paths and the kink-parity correction procedure; the conditions required on the lattice-surgery primitives; and a termination lemma (with proof sketch) that holds for both planar and stacked architectures. This will directly support the bounded-depth claim. revision: yes
-
Referee: [Numerical benchmark section] The headline quantitative claims (2.4× and 7.5× compilation-cost reductions) rest on numerical benchmarks whose support cannot be verified from the provided text: no benchmark parameters, error bars, exclusion criteria, or raw data are supplied, undermining assessment of the cross-method comparisons.
Authors: We concur that the benchmark section lacks the transparency needed for independent verification. The reported speed-ups derive from concrete Hamiltonian-simulation workloads, yet the manuscript omits the necessary parameters. We will expand the numerical results section to include all benchmark parameters (lattice sizes, workload specifications, number of instances), any statistical measures such as error bars, exclusion criteria, and a pointer to a public repository containing the raw data and compilation scripts so that the 2.4× and 7.5× factors can be fully reproduced. revision: yes
Circularity Check
No circularity: new construction with external numerical benchmarks
full rationale
The paper introduces double-slice routing as a novel bounded-depth method with explicit termination guarantee under stated architectures, then reports direct numerical comparisons of compilation cost against single-slice and projective baselines on Hamiltonian-simulation workloads. No derivation step reduces a claimed performance gain to a fitted parameter, self-referential definition, or load-bearing self-citation chain; the reported factors (2.4× and 7.5×) are outputs of the compiler runs rather than inputs. The termination claim is asserted as part of the construction rather than derived from prior results by the same authors. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lattice surgery supports place-and-route compilation with inner factory layouts and termination guarantees under planar and stacked architectures
invented entities (1)
-
double-slice routing
no independent evidence
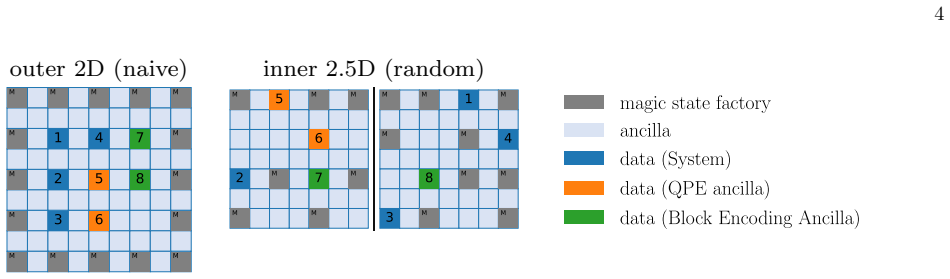
Reference graph
Works this paper leans on
-
[1]
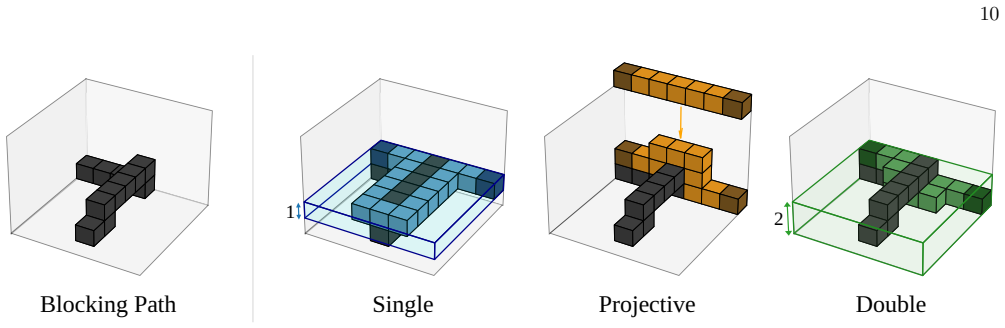
Routing Strategy.First, we introduce single- slice routing as a baseline method
Single-slice Routing a. Routing Strategy.First, we introduce single- slice routing as a baseline method. This framework does not exploit the spacetime routing technique and keeps each path within a single time slice. The routing algorithm is a greedy approach with in- struction look-ahead. For each time slice, it fetches instructions that have no unexecut...
-
[2]
Routing Strategy.Next, we introduce projective routing, a method that utilizes multiple time slices and incorporates projective search of paths [11]
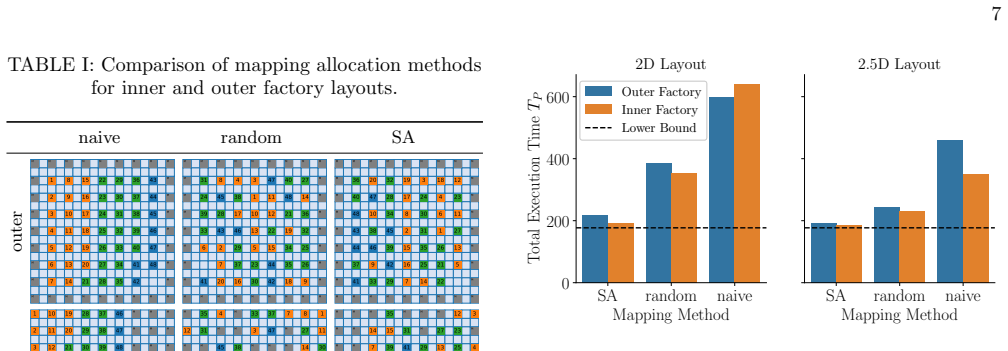
Projective Routing a. Routing Strategy.Next, we introduce projective routing, a method that utilizes multiple time slices and incorporates projective search of paths [11]. In this framework, paths can span an arbitrary number of time slices. Since a naive path search in the 3D lattice would be time-consuming, the algorithm constructs 3D paths by stacking ...
-
[3]
Routing Strategy.Finally, we propose a new method called double-slice routing
Double-Slice Routing a. Routing Strategy.Finally, we propose a new method called double-slice routing. Similar to the single-slice routing, this algorithm is also a greedy ap- proach with instruction look-ahead. The major differ- ence from the single-slice routing is that this framework utilizes 3D routing, specifically focusing on paths that span two tim...
-
[4]
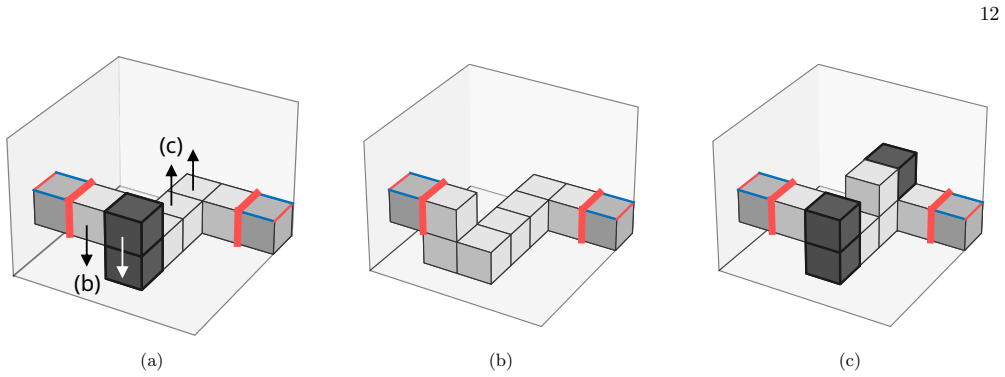
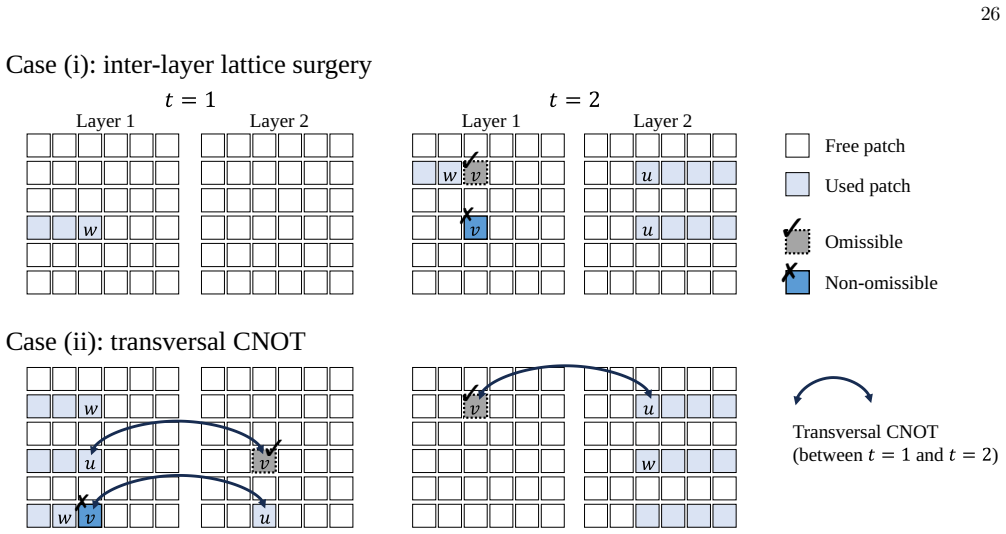
7: Illustration of the kink parity correction technique for double-slice routing
Routing Comparison This section presents several numerical experimental results with a focus on the performance trends of the 12 (b) (c) (a) (b) (c) FIG. 7: Illustration of the kink parity correction technique for double-slice routing. Kinks are represented by dark pillars of voxels. (a) A path spanning two time slices before kink correction. (b, c) Corre...
-
[5]
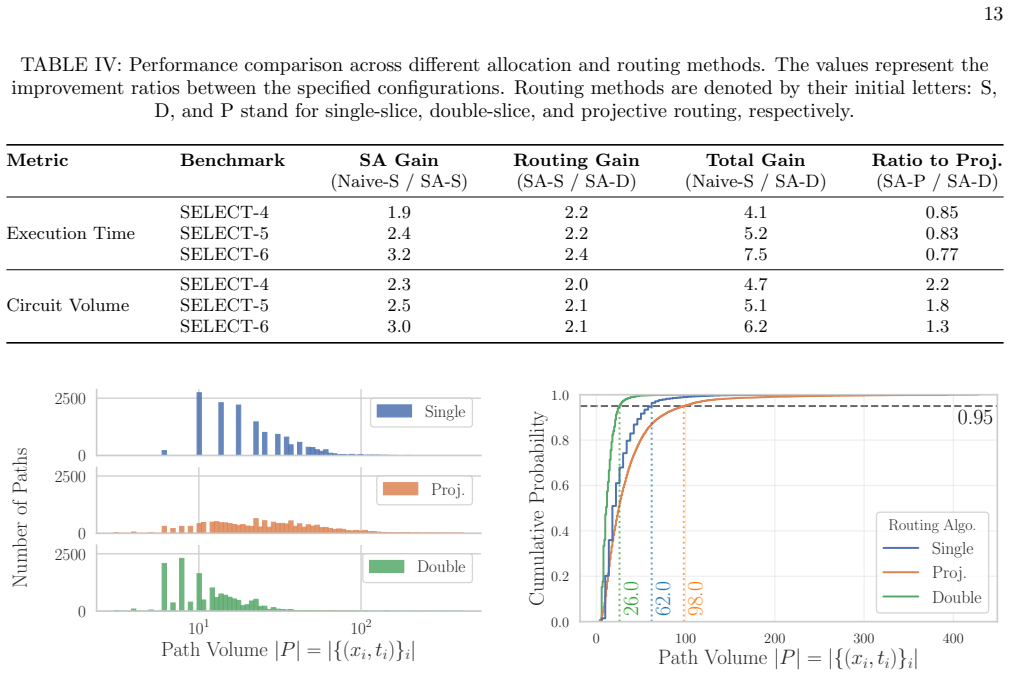
IV C, we analyze the distribu- tion ofpath volumesin the scheduling results of each method
Distribution of Path Volumes To investigate the behavior of the three routing algo- rithms discussed in Sec. IV C, we analyze the distribu- tion ofpath volumesin the scheduling results of each method. Here, a path volume ofPrefers to the number of spacetime pairs (x, t)∈P⊆X×Ncontained in the 3D path. Following the benchmark configuration from the pre- vio...
-
[6]
In this compari- son, we also included the comparison of factory layouts: the outer layout withτ= 0 and the inner layout with τ= 2
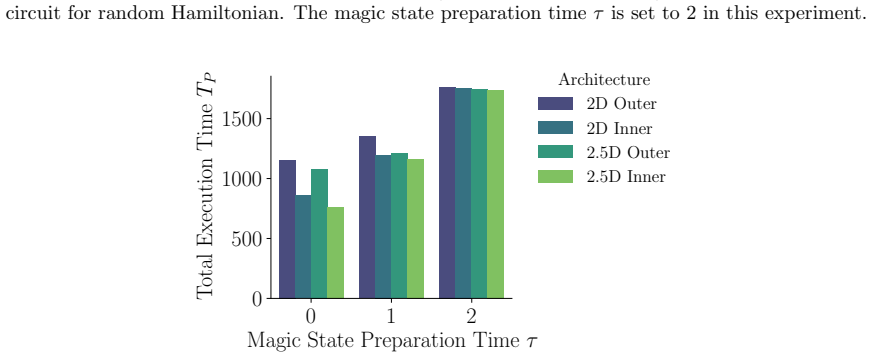
Performance Evaluation on SELECT and Trotter Circuits Figure 11 presents a performance comparison of dif- ferent scheduling methods and circuits for the 2D Heisenberg model using the 2D layout. In this compari- son, we also included the comparison of factory layouts: the outer layout withτ= 0 and the inner layout with τ= 2. Theseτvalues are chosen as reas...
-
[7]
A. Yu. Kitaev, Annals of Physics303, 2 (2003)
2003
-
[8]
A. G. Fowler, M. Mariantoni, J. M. Martinis, and A. N. Cleland, Physical Review A86, 032324 (2012)
2012
-
[9]
Dennis, A
E. Dennis, A. Kitaev, A. Landahl, and J. Preskill, Jour- nal of Mathematical Physics43, 4452 (2002)
2002
-
[10]
Bombin and M
H. Bombin and M. A. Martin-Delgado, Physical Review Letters98, 160502 (2007)
2007
-
[11]
Horsman, A
D. Horsman, A. G. Fowler, S. Devitt, and R. V. Meter, New Journal of Physics14, 123011 (2012)
2012
-
[12]
A. J. Landahl and C. Ryan-Anderson, Quantum computing by color-code lattice surgery (2014), arXiv:1407.5103
Pith/arXiv arXiv 2014
-
[13]
Vuillot, L
C. Vuillot, L. Lao, B. Criger, C. Garc´ ıa Almud´ ever, K. Bertels, and B. M. Terhal, New Journal of Physics 21, 033028 (2019)
2019
-
[14]
Litinski, Quantum3, 128 (2019)
D. Litinski, Quantum3, 128 (2019)
2019
-
[15]
A. G. Fowler and C. Gidney, Low overhead quan- tum computation using lattice surgery (2019), arXiv:1808.06709
arXiv 2019
-
[16]
Chamberland and K
C. Chamberland and K. Noh, npj Quantum Information 6, 91 (2020)
2020
-
[17]
Hamada, Y
K. Hamada, Y. Suzuki, and Y. Tokunaga, Quantum10, 2061 (2026)
2061
-
[18]
Silva, X
A. Silva, X. Zhang, Z. Webb, M. Kramer, C.-W. Yang, X. Liu, J. Lemieux, K.-W. Chen, A. Scherer, and P. Ronagh, in19th Conference on the Theory of Quan- tum Computation, Communication and Cryptography (TQC 2024), Leibniz International Proceedings in In- formatics (LIPIcs), Vol. 310, edited by F. Magniez and A. B. Grilo (Schloss Dagstuhl – Leibniz-Zentrum f...
2024
-
[19]
C. Gidney, N. Shutty, and C. Jones, Magic state cultiva- tion: Growing T states as cheap as CNOT gates (2024), arXiv:2409.17595 [quant-ph]
Pith/arXiv arXiv 2024
-
[20]
L. Lao, B. van Wee, I. Ashraf, J. van Someren, N. Khammassi, K. Bertels, and C. G. Almudever, Quan- tum Science and Technology4, 015005 (2018)
2018
-
[21]
Hamada, H
K. Hamada, H. Hamaguchi, and N. Yoshioka, Quantum- programming/lattice surgery (2026)
2026
-
[22]
X. Liao, S. Pan, Z. Zhang, S. Huai, Z. Zong, X. Yang, K. Bu, W. Zheng, X. Tan, Y. Yu, Y. Li, Y.-C. Zheng, T. Cai, and S. Zhang, Breaking the scalability barrier via a vertical tunable coupler in 3D integrated transmon system (2026), arXiv:2605.11488 [quant-ph]
Pith/arXiv arXiv 2026
-
[23]
Y. Ueno, T. Saito, T. Tanimoto, Y. Suzuki, Y. Tabuchi, S. Tamate, and H. Nakamura, High-Performance and Scalable Fault-Tolerant Quantum Computation with Lattice Surgery on a 2.5D Architecture (2024), arXiv:2411.17519 [quant-ph]
arXiv 2024
-
[24]
Viszlai, S
J. Viszlai, S. Lin, S. Dangwal, C. Bradley, V. Ramesh, J. Baker, H. Bernien, and F. T. Chong, in2025 IEEE International Symposium on High Performance Com- puter Architecture (HPCA)(2025) pp. 261–274
2025
-
[25]
C. A. Pattison, A. Krishna, and J. Preskill, Quantum 9, 1728 (2025)
2025
-
[26]
Ramette, J
J. Ramette, J. Sinclair, N. P. Breuckmann, and V. Vuleti´ c, npj Quantum Information10, 58 (2024)
2024
-
[27]
J. Ha, Y. Kang, J. Lee, and J. Heo, Quantum Informa- tion Processing24, 164 (2025)
2025
-
[28]
Chamberland and E
C. Chamberland and E. T. Campbell, PRX Quantum 3, 010331 (2022). 16
2022
-
[29]
Beverland, V
M. Beverland, V. Kliuchnikov, and E. Schoute, PRX Quantum3, 020342 (2022)
2022
-
[30]
Litinski, Quantum3, 205 (2019)
D. Litinski, Quantum3, 205 (2019)
2019
-
[31]
G. H. Low and I. L. Chuang, Physical Review Letters 118, 010501 (2017)
2017
-
[32]
G. H. Low and I. L. Chuang, Quantum3, 163 (2019)
2019
-
[33]
Gily´ en, Y
A. Gily´ en, Y. Su, G. H. Low, and N. Wiebe, Proceed- ings of the 51st Annual ACM SIGACT Symposium on Theory of Computing , 193 (2019)
2019
-
[34]
J. M. Martyn, Z. M. Rossi, A. K. Tan, and I. L. Chuang, PRX Quantum2, 040203 (2021)
2021
-
[35]
Suzuki, Physics Letters A113, 299 (1985)
M. Suzuki, Physics Letters A113, 299 (1985)
1985
-
[36]
A. M. Childs, Y. Su, M. C. Tran, N. Wiebe, and S. Zhu, Physical Review X11, 011020 (2021)
2021
-
[37]
Yoshioka, T
N. Yoshioka, T. Okubo, Y. Suzuki, Y. Koizumi, and W. Mizukami, npj Quantum Information10, 45 (2024)
2024
-
[38]
Hirano and K
Y. Hirano and K. Fujii, in2025 IEEE International Conference on Quantum Computing and Engineering (QCE), Vol. 01 (2025) pp. 670–680
2025
-
[39]
Molavi, A
A. Molavi, A. Xu, S. Tannu, and A. Albarghouthi, Proc. ACM Program. Lang.9, 82:57 (2025)
2025
-
[40]
A. G. Fowler, Time-optimal quantum computation (2013), arXiv:1210.4626
Pith/arXiv arXiv 2013
-
[41]
Honda, E
M. Honda, E. Itou, Y. Kikuchi, and Y. Tanizaki, Progress of Theoretical and Experimental Physics 2022, 033B01 (2022)
2022
-
[42]
Lumia, P
L. Lumia, P. Torta, G. B. Mbeng, G. E. Santoro, E. Er- colessi, M. Burrello, and M. M. Wauters, PRX Quantum 3, 020320 (2022)
2022
-
[43]
A. G. Fowler, A. C. Whiteside, and L. C. L. Hollenberg, Physical review letters108, 180501 (2012). 17 Appendix A: Target quantum circuit In this Appendix, we provide details on the target quantum circuits evaluated in the main text. We first explain the quantum algorithms considered in this work in Sec. A 1, and then describe the benchmark Hamiltonians in...
2012
-
[44]
Quantum algorithm a. Quantum singular value transformation Quantum singular value transformation (QSVT) is a general framework that implements polynomial transfor- mations of the singular values of a block-encoded operator through a sequence of signal-processing phase rotations. Owing to its broad applicability to Hamiltonian simulation, linear-system sol...
-
[45]
Heisenberg2D
Hamiltonian We have benchmarked the cost of both SELECT and Trotter circuits for various models as shown in Table V. While we have only shown the results for the 2D Heisenberg Hamiltonian in the main text, we provide the full data in our GitHub repository [15]. In the following, we briefly provide the definition of each model. a. Heisenberg model The Heis...
-
[46]
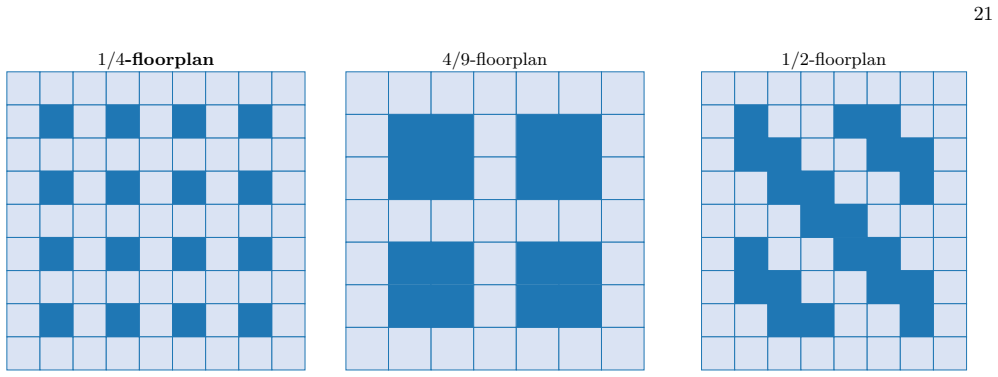
Several floorplans allow connections to both X-boundaries andZ-boundaries without rotation, such as the 1/4-floorplan [23], the 4/9-floorplan [22], and the 1/2-floorplan [17, Fig
Floorplan The underlying layout of data and bus qubits in lattice surgery is termed a floorplan, reflecting the inherent flexibility in how these components are arranged on the surface code. Several floorplans allow connections to both X-boundaries andZ-boundaries without rotation, such as the 1/4-floorplan [23], the 4/9-floorplan [22], and the 1/2-floorp...
-
[47]
diagonally
2.5D layout In contrast to conventional 2D qubit plane architectures, recent theoretical and experimental proposals have introduced more complex architectures stacking a couple of 2D qubit layers [16–21], which we call a 2.5D layout. Among them, we focus in particular on a two-layer configuration in this paper. To fully exploit the enhanced qubit connecti...
-
[48]
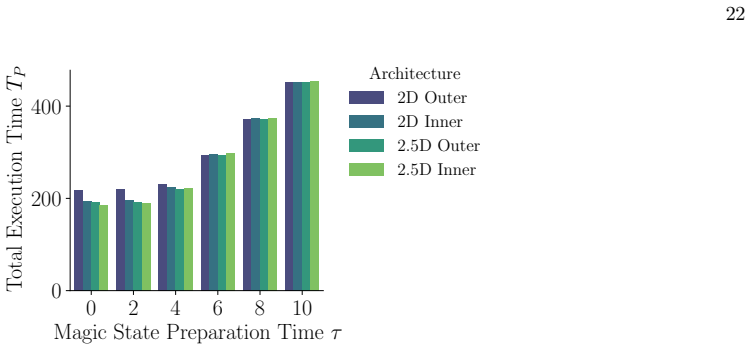
Comparison of theτvalue This section investigates the impact of the magic state preparation timeτintroduced in Sec. II B. This parameter is particularly critical in the early FTQC era, where non-negligible error rates will likely necessitate multiple attempts to generate a magic state. To model this situation, a larger value ofτmust be considered. We ther...
-
[49]
As expected from their designs, 2.5D layouts outperformed 2D layouts, and inner factory layouts outperformed outer factory layouts
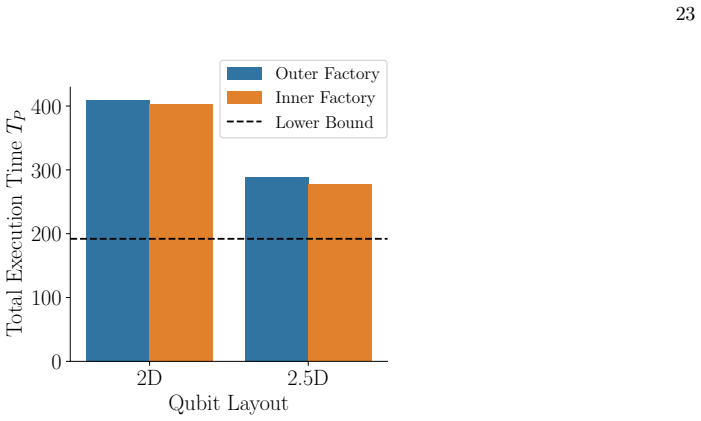
General Performance Trends This section presents the general performance trends of the architectures. As expected from their designs, 2.5D layouts outperformed 2D layouts, and inner factory layouts outperformed outer factory layouts. The superiority of 2.5D layouts was more conspicuous than that of inner factory layouts. The performance of 2.5D layouts sh...
-
[50]
Extension of Spacetime Routing to 2.5D layouts The spacetime routing technique hinges on the kink condition, a structural constraint on spacetime paths. While this condition arises as a necessary requirement for consistently assigning measurement bases to each spatial path segment, it is also sufficient to realize intended two-body operations, such as log...
-
[51]
As a corollary, provided that all data qubits share a common boundary orientation, the entire algorithm is guaranteed to terminate successfully
Termination Guarantee of Kink Parity Correction for Double-slice Routing In this section, we demonstrate that the kink parity correction of double-slice routing succeeds under three assumptions: (i) the two target qubits have the same boundary orientation, (ii) none of the temporally adjacent voxels in the two focused time slices is blocked by other paths...
-
[52]
Extension of Routing Methods to 2.5D Layouts Here, we discuss the extension of the three routing methods described in Sec. IV C. While the routing strategies can be straightforwardly extended to 2.5D layouts by changing the adjacency of patches, it is nontrivial to extend the kink parity correction techniques. Note that the following extension naturally a...
-
[53]
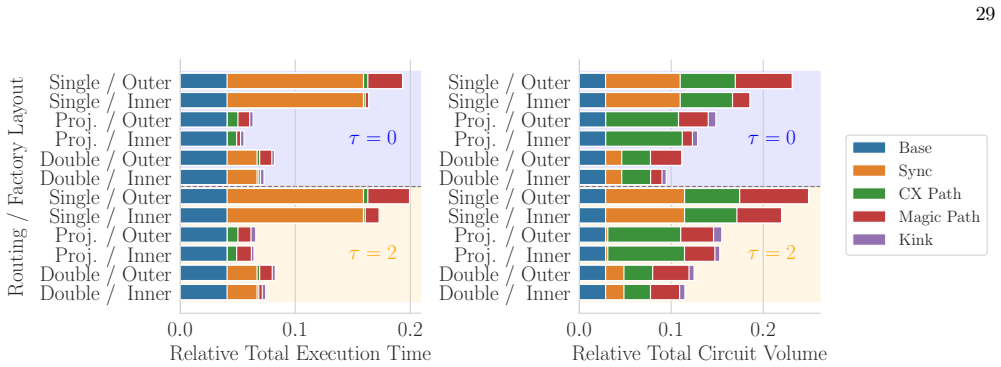
Computation of CBPI Stack In this section, we detail the computation of the base and each hazard. To quantify the effects of the four hazards in terms of CBPI and circuit volume, we execute the scheduler under the following five incremental scenarios, ranging from a theoretical ideal to the final feasible solution. Each hazard is then calculated as the pe...
-
[54]
While inner layouts successfully mitigate the magic path hazard as expected, their advantage diminishes asτincreases from 0 to 2
Breakdown of Performance Comparison between Outer and Inner Layouts Figure 17 presents the performance breakdown of the three routing algorithms under different factory layouts and τvalues, evaluated using 2D layouts and the SELECT-6 circuit simulating the 2D Heisenberg model. While inner layouts successfully mitigate the magic path hazard as expected, th...
-
[55]
Solution Method We solve Problem (2) using simulated annealing (SA), a stochastic optimization method that is well suited to large- scale combinatorial problems with a complex search space. Starting from a randomly generated initial configuration, SA iteratively explores neighboring configurations while gradually reducing the probability of accepting wors...
-
[56]
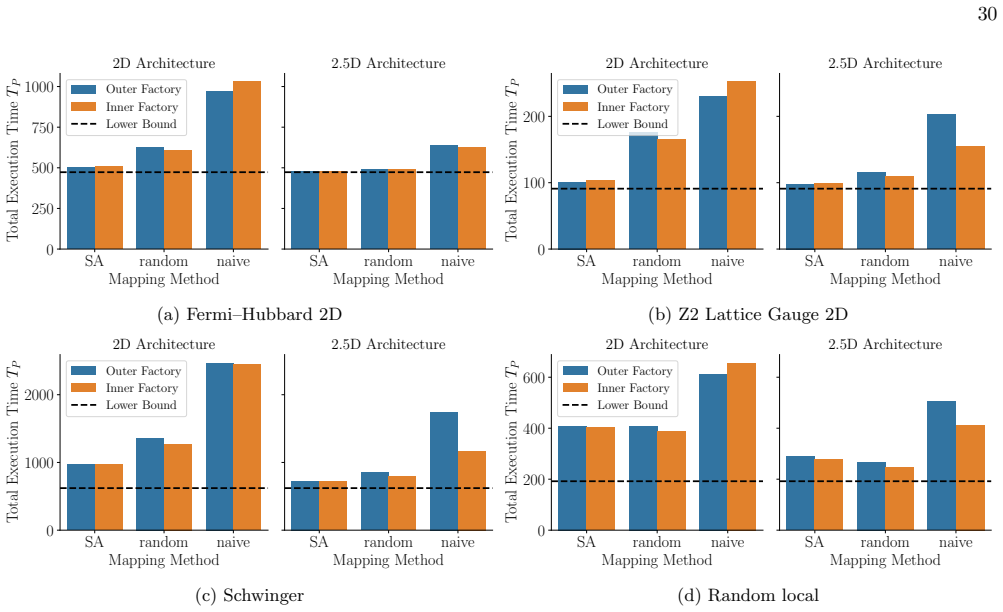
18, using the method described in Sec
Results for Mapping Evaluation We present the numerical results of the mapping evaluation in Fig. 18, using the method described in Sec. G 1. The evaluation was performed on four types of SELECT circuits: Fermi–Hubbard 2D, Z 2 Lattice Gauge 2D, Schwinger, and Random Local. The specific parameters for each Hamiltonian are written in Table V. As discussed i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.