Value Functions as Supermartingale Certificates
Pith reviewed 2026-06-28 23:26 UTC · model grok-4.3
The pith
Value functions of policies that almost surely satisfy omega-regular properties encode Streett supermartingale certificates under appropriate rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under an appropriate reward, the value function associated to a policy that almost surely satisfies an ω-regular property encodes a Streett supermartingale certificate for that specification.
What carries the argument
Value function of an a.s.-satisfying policy as a Streett supermartingale certificate.
If this is right
- RL methods can generate formal certificates for omega-regular properties in stochastic systems.
- The connection allows certificate synthesis in continuous state spaces via learning.
- Policies from RL come equipped with supermartingale-based proofs of almost-sure satisfaction.
- Experimental validation on finite MDPs confirms the theoretical bridge between the fields.
Where Pith is reading between the lines
- This unification suggests RL could automate certificate finding where manual design is difficult.
- Extending the reward construction to be automatic would enable end-to-end certified policy learning.
- Similar links might exist for other certificate types beyond Streett supermartingales.
Load-bearing premise
An appropriate reward function exists that turns the value function into a valid Streett supermartingale.
What would settle it
An example of a policy satisfying an omega-regular property almost surely, together with any reward, where the value function fails to meet the supermartingale conditions for the Streett automaton.
Figures
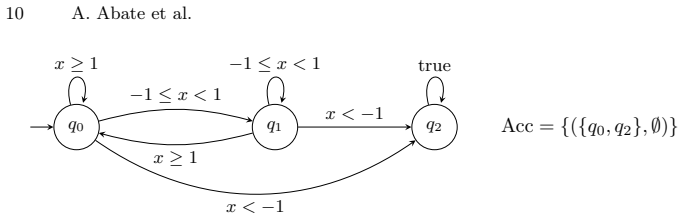
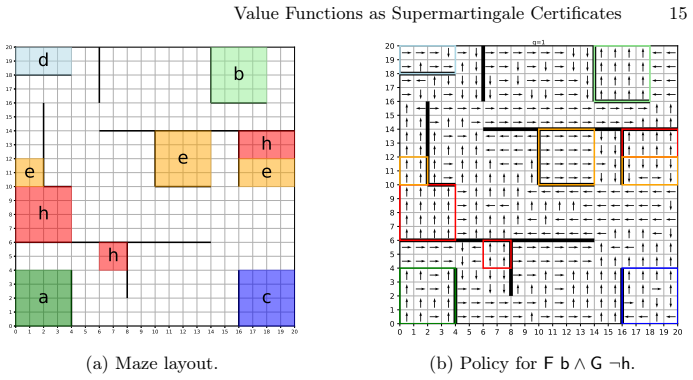
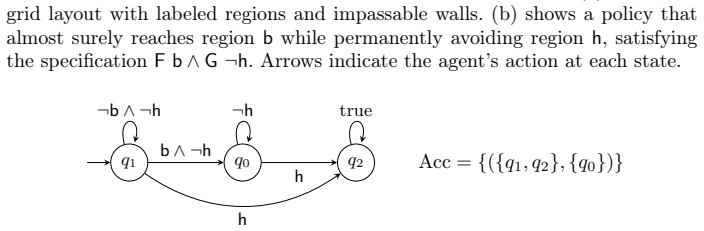


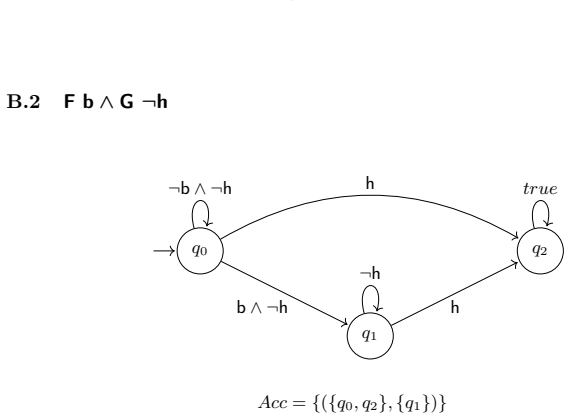
read the original abstract
Certification methods for stochastic systems provide sufficient proof rules, based on real-valued supermartingale certificates, to determine the almost-sure satisfaction of $\omega$-regular properties (and therefore of linear temporal logic) over general state spaces, encompassing both countably infinite and continuous state spaces. Conversely, reinforcement learning (RL) methods for $\omega$-regular tasks have received considerable attention, but they typically lack formal guarantees that the learned policy satisfies the specification, except possibly for finite state and action spaces. We bridge these two lines of research by establishing a novel theoretical connection: under an appropriate reward, the value function associated to a policy that almost surely satisfies an $\omega$-regular property encodes a Streett supermartingale certificate for that specification. Our results, validated experimentally on finite Markov decision processes, hold for finite, countably infinite, and continuous state spaces, suggesting a principled route to certificate synthesis via RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to bridge supermartingale-based certification of ω-regular properties (including LTL) over general state spaces with RL methods by showing that, under an appropriate reward, the value function V^π of any policy π that almost surely satisfies a Streett condition encodes a valid Streett supermartingale certificate for that specification. The result is asserted for finite, countably infinite, and continuous spaces and is supported by experiments on finite MDPs.
Significance. If the central connection holds, the work supplies a route from RL value functions to formal almost-sure certificates, which is a substantive contribution. Credit is given for the explicit theoretical link between policy value functions and Streett certificates together with the finite-MDP validation.
major comments (2)
- [Abstract] Abstract: the claim that 'under an appropriate reward' the value function encodes a Streett supermartingale certificate is asserted without an explicit construction of the reward r from the Streett pairs (A_i, B_i) or a derivation showing that the resulting V^π satisfies both the supermartingale drift E[V^π(s') | s] ≤ V^π(s) and the required boundary conditions. This step is load-bearing because the supermartingale property holds only for a carefully chosen non-positive reward that encodes progress and penalizes violations.
- [Experiments (finite MDPs)] The finite-MDP experiments do not address the additional requirements of measurability and integrability of V^π that arise in continuous state spaces; these properties are necessary for the certificate to be well-defined but are not verified beyond the discrete case.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recognition of the work's potential contribution. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'under an appropriate reward' the value function encodes a Streett supermartingale certificate is asserted without an explicit construction of the reward r from the Streett pairs (A_i, B_i) or a derivation showing that the resulting V^π satisfies both the supermartingale drift E[V^π(s') | s] ≤ V^π(s) and the required boundary conditions. This step is load-bearing because the supermartingale property holds only for a carefully chosen non-positive reward that encodes progress and penalizes violations.
Authors: The explicit construction of the reward from the Streett pairs and the derivation that V^π satisfies the supermartingale drift and boundary conditions appear in Section 3 and Theorem 3.1 of the manuscript. The abstract summarizes the high-level result without these technical details, which is conventional. We will revise the abstract to briefly indicate the form of the reward function. revision: yes
-
Referee: [Experiments (finite MDPs)] The finite-MDP experiments do not address the additional requirements of measurability and integrability of V^π that arise in continuous state spaces; these properties are necessary for the certificate to be well-defined but are not verified beyond the discrete case.
Authors: The experiments are designed to validate the core theoretical connection in the finite setting, where measurability and integrability hold by construction. The results for countably infinite and continuous spaces are stated under the standard measure-theoretic assumptions that V^π is measurable and integrable. We will add a clarifying remark in the experiments section to explicitly separate the finite validation from the general theoretical claims. revision: partial
Circularity Check
No circularity; derivation self-contained as theoretical bridge
full rationale
The paper claims a connection wherein, for policies a.s. satisfying an ω-regular property, an appropriate reward makes the value function encode a Streett supermartingale certificate. No quoted equations or self-citations reduce this claim to a definition, fitted parameter renamed as prediction, or load-bearing self-reference. The abstract and description frame it as a novel link between RL value functions and existing certification methods, with the reward construction presented as part of the result rather than presupposed. Experimental validation on finite MDPs is separate from the general claim. This is the common case of an independent theoretical result.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard definitions of supermartingales, Streett conditions, and almost-sure satisfaction from probability theory and automata.
Reference graph
Works this paper leans on
-
[1]
In: CONCUR
Abate, A., Edwards, A., Giacobbe, M., Punchihewa, H., Roy, D.: Quantitative verification with neural networks. In: CONCUR. pp. 22:1–22:18. LIPIcs, Schloss Dagstuhl - Leibniz-Zentrum für Informatik (2023)
2023
-
[2]
Abate, A., Giacobbe, M., Ichtchenko, S., Roy, D.: Completeω-regular supermartin- gale certificates (2026), https://arxiv.org/abs/2605.21134
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
In: CAV (2)
Abate, A., Giacobbe, M., Roy, D.: Learning probabilistic termination proofs. In: CAV (2). pp. 3–26. Lecture Notes in Computer Science, Springer (2021)
2021
-
[4]
Abate, A., Giacobbe, M., Roy, D.: Stochastic Omega-Regular Verification and Con- trol with Supermartingales. In: Gurfinkel, A., Ganesh, V. (eds.) Computer Aided Verification. pp. 395–419. Springer Nature Switzerland, Cham (2024). https://doi. org/10.1007/978-3-031-65633-0_18
-
[5]
In: CAV (2)
Abate, A., Giacobbe, M., Roy, D.: Quantitative supermartingale certificates. In: CAV (2). pp. 3–28. Lecture Notes in Computer Science, Springer (2025)
2025
-
[6]
In: CAV (3)
Abate, A., Giacobbe, M., Schnitzer, Y.: Bisimulation learning. In: CAV (3). pp. 161–183. Lecture Notes in Computer Science, Springer (2024)
2024
-
[7]
Agrawal, S., Chatterjee, K., Novotný, P.: Lexicographic ranking supermartingales: an efficient approach to termination of probabilistic programs. Proc. ACM Pro- gram. Lang.2(POPL), 34:1–34:32 (2018)
2018
-
[8]
IEEE Control
Ajeleye, D., Zamani, M.: Co-büchi control barrier certificates for stochastic control systems. IEEE Control. Syst. Lett.8, 2529–2534 (2024)
2024
-
[9]
In: AAAI
Alshiekh, M., Bloem, R., Ehlers, R., Könighofer, B., Niekum, S., Topcu, U.: Safe reinforcement learning via shielding. In: AAAI. pp. 2669–2678. AAAI Press (2018) 20 A. Abate et al
2018
-
[10]
In: CAV (2)
Badings, T., Koops, W., Junges, S., Jansen, N.: Policy verification in stochastic dynamical systems using logarithmic neural certificates. In: CAV (2). pp. 349–375. Lecture Notes in Computer Science, Springer (2025)
2025
-
[11]
The MIT Press, Cambridge, Mass (2008)
Baier, C., Katoen, J.P.: Principles of Model Checking. The MIT Press, Cambridge, Mass (2008)
2008
-
[12]
10349–10355
Bozkurt, A.K., Wang, Y., Zavlanos, M.M., Pajic, M.: Control synthesis from linear temporallogicspecificationsusingmodel-freereinforcementlearning.In:ICRA.pp. 10349–10355. IEEE (2020)
2020
-
[13]
Chakarov, A., Sankaranarayanan, S.: Probabilistic program analysis with martin- gales. In: CAV. pp. 511–526. Lecture Notes in Computer Science, Springer (2013)
2013
-
[14]
Springer Berlin Heidelberg, Berlin, Heidelberg, 2016
Chakarov, A., Voronin, Y.L., Sankaranarayanan, S.: Deductive Proofs of Almost Sure Persistence and Recurrence Properties. In: Chechik, M., Raskin, J.F. (eds.) Tools and Algorithms for the Construction and Analysis of Systems. pp. 260–279. Springer, Berlin, Heidelberg (2016). https://doi.org/10.1007/978-3-662-49674-9_ 15
-
[15]
In: CAV (1)
Chatterjee, K., Fu, H., Goharshady, A.K.: Termination analysis of probabilistic programs through positivstellensatz’s. In: CAV (1). pp. 3–22. Lecture Notes in Computer Science, Springer (2016)
2016
-
[16]
In: POPL
Chatterjee, K., Fu, H., Novotný, P., Hasheminezhad, R.: Algorithmic analysis of qualitativeandquantitativeterminationproblemsforaffineprobabilisticprograms. In: POPL. pp. 327–342. ACM (2016)
2016
-
[17]
In: CAV (1)
Chatterjee, K., Goharshady, A.K., Meggendorfer, T., Zikelic, D.: Sound and com- plete certificates for quantitative termination analysis of probabilistic programs. In: CAV (1). pp. 55–78. Lecture Notes in Computer Science, Springer (2022)
2022
-
[18]
In: TACAS (1)
Chatterjee, K., Henzinger, T.A., Lechner, M., Zikelic, D.: A learner-verifier frame- work for neural network controllers and certificates of stochastic systems. In: TACAS (1). pp. 3–25. Lecture Notes in Computer Science, Springer (2023)
2023
-
[19]
In: POPL
Chatterjee, K., Novotný, P., Zikelic, D.: Stochastic invariants for probabilistic ter- mination. In: POPL. pp. 145–160. ACM (2017)
2017
-
[20]
In: TACAS (2)
Chatterjee, K., Quatmann, T., Schäffeler, M., Weininger, M., Winkler, T., Zilken, D.: Fixed point certificates for reachability and expected rewards in mdps. In: TACAS (2). pp. 130–151. Lecture Notes in Computer Science, Springer (2025)
2025
-
[21]
In: CAV (2)
Dehnert, C., Junges, S., Katoen, J., Volk, M.: A storm is coming: A modern prob- abilistic model checker. In: CAV (2). pp. 592–600. Lecture Notes in Computer Science, Springer (2017)
2017
-
[22]
In: AAMAS
Delgrange, F., Avni, G., Lukina, A., Schilling, C., Nowé, A., Pérez, G.A.: Com- posing reinforcement learning policies, with formal guarantees. In: AAMAS. pp. 574–583. International Foundation for Autonomous Agents and Multiagent Sys- tems / ACM (2025)
2025
-
[23]
In: QEST
Desharnais, J., Laviolette, F., Tracol, M.: Approximate analysis of probabilistic processes: Logic, simulation and games. In: QEST. pp. 264–273. IEEE Computer Society (2008)
2008
-
[24]
Springer Series in Operations Research and Financial Engineering, Springer (2018)
Douc, R., Moulines, E., Priouret, P., Soulier, P.: Markov Chains. Springer Series in Operations Research and Financial Engineering, Springer (2018)
2018
-
[25]
Hahn, E.M., Li, Y., Schewe, S., Turrini, A., Zhang, L.: iscasmc: A web-based prob- abilistic model checker. In: FM. pp. 312–317. Lecture Notes in Computer Science, Springer (2014)
2014
-
[26]
In: TACAS (1)
Hahn, E.M., Perez, M., Schewe, S., Somenzi, F., Trivedi, A., Wojtczak, D.: Omega- regular objectives in model-free reinforcement learning. In: TACAS (1). pp. 395–
-
[27]
Lecture Notes in Computer Science, Springer (2019) Value Functions as Supermartingale Certificates 21
2019
-
[28]
Hahn, E.M., Perez, M., Schewe, S., Somenzi, F., Trivedi, A., Wojtczak, D.: Faithful and Effective Reward Schemes for Model-Free Reinforcement Learning of Omega- Regular Objectives. In: Hung, D.V., Sokolsky, O. (eds.) Automated Technology for Verification and Analysis. pp. 108–124. Springer International Publishing, Cham (2020). https://doi.org/10.1007/978...
-
[29]
Logically-Constrained Reinforcement Learning
Hasanbeig, M., Abate, A., Kroening, D.: Logically-correct reinforcement learning. CoRRabs/1801.08099(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
In: AAMAS
Hasanbeig, M., Abate, A., Kroening, D.: Logically-constrained neural fitted q- iteration. In: AAMAS. pp. 2012–2014. International Foundation for Autonomous Agents and Multiagent Systems (2019)
2012
-
[31]
In: FORMATS
Hasanbeig, M., Kroening, D., Abate, A.: Deep reinforcement learning with tempo- ral logics. In: FORMATS. pp. 1–22. Lecture Notes in Computer Science, Springer (2020)
2020
-
[32]
Hasanbeig, M., Kroening, D., Abate, A.: LCRL: Certified Policy Synthesis via Logically-Constrained Reinforcement Learning. In: Quantitative Evaluation of Systems: 19th International Conference, QEST 2022, Warsaw, Poland, September 12–16, 2022, Proceedings. pp. 217–231. Springer-Verlag, Berlin, Heidelberg (Sep 2022). https://doi.org/10.1007/978-3-031-16336-4_11
-
[33]
In: Piskac, R., Raka- marić, Z
Henzinger, T.A., Mallik, K., Sadeghi, P., Žikelić, Ð.: Supermartingale Certificates for Quantitative Omega-Regular Verification and Control. In: Piskac, R., Raka- marić, Z. (eds.) Computer Aided Verification. pp. 29–55. Springer Nature Switzer- land, Cham (2025). https://doi.org/10.1007/978-3-031-98679-6_2
-
[34]
Huang, M., Fu, H., Chatterjee, K., Goharshady, A.K.: Modular verification for almost-sure termination of probabilistic programs. Proc. ACM Program. Lang. 3(OOPSLA), 129:1–129:29 (2019)
2019
-
[35]
In: QEST
Katoen, J., Zapreev, I.S., Hahn, E.M., Hermanns, H., Jansen, D.N.: The ins and outs of the probabilistic model checker MRMC. In: QEST. pp. 167–176. IEEE Computer Society (2009)
2009
-
[36]
In: CONCUR
Kretínský, J., Pérez, G.A., Raskin, J.: Learning-based mean-payoff optimization in an unknown MDP under omega-regular constraints. In: CONCUR. pp. 8:1–8:18. LIPIcs, Schloss Dagstuhl - Leibniz-Zentrum für Informatik (2018)
2018
-
[37]
A Hierarchy of Supermartingales for $\omega$-Regular Verification
Kura, S., Unno, H.: A Hierarchy of Supermartingales forω-Regular Verification (Nov 2025). https://doi.org/10.48550/arXiv.2512.00270
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.00270 2025
-
[38]
In: Gopalakrishnan, G., Qadeer, S
Kwiatkowska, M., Norman, G., Parker, D.: PRISM 4.0: Verification of Probabilistic Real-Time Systems. In: Gopalakrishnan, G., Qadeer, S. (eds.) Computer Aided Verification. pp. 585–591. Lecture Notes in Computer Science, Springer, Berlin, Heidelberg (2011). https://doi.org/10.1007/978-3-642-22110-1_47
-
[39]
In: AAAI
Lechner, M., Zikelic, D., Chatterjee, K., Henzinger, T.A.: Stability verification in stochastic control systems via neural network supermartingales. In: AAAI. pp. 7326–7336. AAAI Press (2022)
2022
-
[40]
Majumdar, R., Sathiyanarayana, V.R.: Sound and complete proof rules for prob- abilistic termination. Proc. ACM Program. Lang.9(POPL), 1871–1902 (2025)
1902
-
[41]
In: Proceedings of the Ninth Annual ACM Symposium on Principles of Distributed Computing
Manna, Z., Pnueli, A.: A hierarchy of temporal properties (invited paper, 1989). In: Proceedings of the Ninth Annual ACM Symposium on Principles of Distributed Computing. pp. 377–410. PODC ’90, Association for Computing Machinery, New York, NY, USA (Aug 1990). https://doi.org/10.1145/93385.93442
-
[42]
Autom.42(1), 117– 126 (2006)
Prajna, S.: Barrier certificates for nonlinear model validation. Autom.42(1), 117– 126 (2006)
2006
-
[43]
Sadigh, D., Kim, E.S., Coogan, S., Sastry, S.S., Seshia, S.A.: A learning based approach to control synthesis of Markov decision processes for linear temporal logic 22 A. Abate et al. specifications. In: 53rd IEEE Conference on Decision and Control. pp. 1091–1096 (Dec 2014). https://doi.org/10.1109/CDC.2014.7039527
-
[44]
In: IJCAI
Shao, D., Kwiatkowska, M.: Sample efficient model-free reinforcement learning from LTL specifications with optimality guarantees. In: IJCAI. pp. 4180–4189. ijcai.org (2023)
2023
-
[45]
Soudjani, S.E.Z., Abate, A.: Adaptive and sequential gridding procedures for the abstraction and verification of stochastic processes. SIAM J. Appl. Dyn. Syst. 12(2), 921–956 (2013)
2013
-
[46]
Stachurski,J.,Zhang,J.:Dynamicprogrammingwithstate-dependentdiscounting. Journal of Economic Theory192, 105190 (Mar 2021). https://doi.org/10.1016/j. jet.2021.105190
work page doi:10.1016/j 2021
-
[47]
In: The 10th International Conference on Au- tonomous Agents and Multiagent Systems - Volume 2
Sutton, R.S., Modayil, J., Delp, M., Degris, T., Pilarski, P.M., White, A., Precup, D.: Horde: A scalable real-time architecture for learning knowledge from unsu- pervised sensorimotor interaction. In: The 10th International Conference on Au- tonomous Agents and Multiagent Systems - Volume 2. pp. 761–768. AAMAS ’11, International Foundation for Autonomous...
2011
-
[48]
ACM Trans
Takisaka, T., Oyabu, Y., Urabe, N., Hasuo, I.: Ranking and repulsing supermartin- gales for reachability in randomized programs. ACM Trans. Program. Lang. Syst. 43(2), 5:1–5:46 (2021)
2021
-
[49]
In: HSCC
Tkachev, I., Abate, A.: Formula-free finite abstractions for linear temporal verifi- cation of stochastic hybrid systems. In: HSCC. pp. 283–292. ACM (2013)
2013
-
[50]
On Convergence of Emphatic Temporal-Difference Learning
Yu, H.: On Convergence of Emphatic Temporal-Difference Learning (Dec 2017). https://doi.org/10.48550/arXiv.1506.02582
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1506.02582 2017
-
[51]
Zhang, L., She, Z., Ratschan, S., Hermanns, H., Hahn, E.M.: Safety verification for probabilistic hybrid systems. In: CAV. pp. 196–211. Lecture Notes in Computer Science, Springer (2010)
2010
-
[52]
In: CAV (2)
Zhi, D., Wang, P., Liu, S., Ong, C.L., Zhang, M.: Unifying qualitative and quan- titative safety verification of dnn-controlled systems. In: CAV (2). pp. 401–426. Lecture Notes in Computer Science, Springer (2024)
2024
-
[53]
In: AAAI
Zikelic, D., Lechner, M., Henzinger, T.A., Chatterjee, K.: Learning control policies for stochastic systems with reach-avoid guarantees. In: AAAI. pp. 11926–11935. AAAI Press (2023)
2023
-
[54]
ℓX t=0 γN(A∪B) t rB1{St∈B} −r A\B1{St∈A\B} # ≥0. It remains to bound the tail fromℓ+ 1toL. Betweenℓ+ 1andLthere are no visits toBby definition ofℓ, so ther B term vanishes: Eπ
Zikelic,D.,Lechner,M.,Verma,A.,Chatterjee,K.,Henzinger,T.A.:Compositional policy learning in stochastic control systems with formal guarantees. In: NeurIPS (2023) Value Functions as Supermartingale Certificates 23 A Proofs Measurability and integrability.Under our MDP definition, the transition kernel P, policy kernelπ, and all sets such asU, A, B, Iare m...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.