TriageRA-CCF: Source-Side Clinical Confidence and Coverage Signals for Adaptive Rank Budgeting in Medical LLMs
Pith reviewed 2026-06-30 07:38 UTC · model grok-4.3
The pith
Source-side clinical signals can supervise an adaptive rank router that delivers the highest average accuracy for medical LLMs among compared adapters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
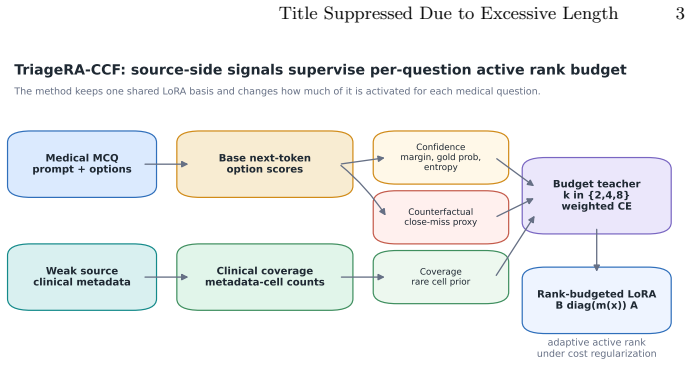
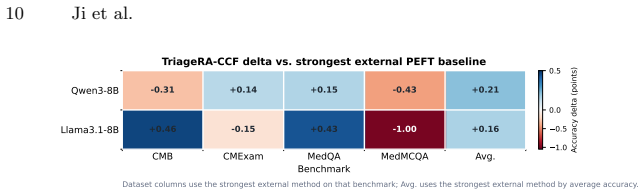
The paper establishes that base-model answer confidence, metadata-cell clinical coverage, and a counterfactual close-miss proxy, all derived solely from source training data, can supervise a straight-through budget router over active ranks {2,4,8} and thereby produce TriageRA-CCF, which attains the highest average accuracy among LoRA, DoRA, and MoELoRA baselines on medical question-answering tasks for both Qwen3-8B and Llama3.1-8B under a matched CMB-source training protocol.
What carries the argument
TriageRA-CCF, the source-side teacher that fuses three training-data signals to supervise a straight-through budget router over ranks {2,4,8}.
If this is right
- Adaptive rank selection for medical QA can be trained without any target-domain examples.
- Base-model confidence, clinical coverage, and close-miss signals each supply distinct supervision to the router.
- Budget-cost, entropy, and rank-balance regularization keep the router stable during training.
- The same source-side approach yields top average accuracy on two different 8B-scale base models.
- Component ablations confirm that omitting any one signal reduces supervision quality on at least one backbone.
Where Pith is reading between the lines
- The source-only design implies that similar triage signals could be tested for adaptive budgeting in non-medical domains that also face domain shift.
- If the router remains stable on further benchmarks, practitioners could reduce reliance on expensive target-domain validation sets.
- Non-uniform gains across benchmarks suggest that certain question types systematically benefit from higher ranks, opening a path for type-specific analysis.
- The method could be extended by replacing the discrete rank set with a continuous rank parameter while retaining the same source signals.
Load-bearing premise
Signals computed only from source training data will reliably supervise a straight-through budget router over ranks without producing unstable choices or capacity waste on shifted benchmarks.
What would settle it
A new medical benchmark on which TriageRA-CCF produces either lower average accuracy than the strongest baseline or visibly unstable rank assignments across similar questions.
Figures
read the original abstract
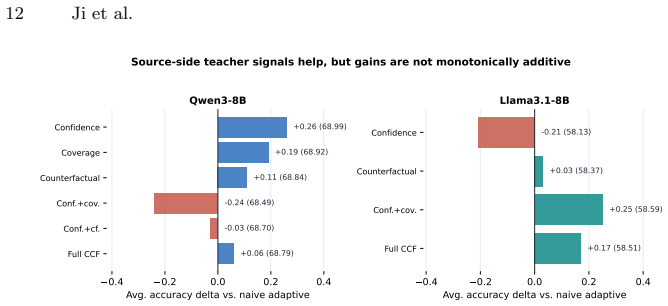
Medical large language models are commonly adapted with a fixed low-rank budget, even though medical questions differ substantially in confidence, clinical coverage, and cross-domain difficulty. We study adaptive rank budgeting for parameter-efficient medical question answering: for each question, the adapter decides whether to activate a small, medium, or large subset of LoRA rank channels. The central challenge is that a naive adaptive budget router can collapse to unstable choices or spend capacity without improving shifted benchmarks. We propose TriageRA-CCF, a source-side teacher for adaptive rank-budgeted LoRA. It combines three signals computed only from source training data: base-model answer confidence, metadata-cell clinical coverage, and a counterfactual close-miss proxy. These signals supervise a straight-through budget router over active ranks {2,4,8}, together with budget-cost, entropy, and rank-balance regularization. Under a matched CMB-source training protocol, TriageRA-CCF achieves the best average accuracy among LoRA, DoRA, and MoELoRA baselines on both Qwen3-8B and Llama3.1-8B. The gains are modest and non-uniform across benchmarks: +0.21 average points over the strongest external baseline on Qwen3-8B and +0.16 on Llama3.1-8B. Component ablations show that confidence, coverage, and counterfactual signals all provide useful budget supervision, but their combination is not monotonically best on every backbone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
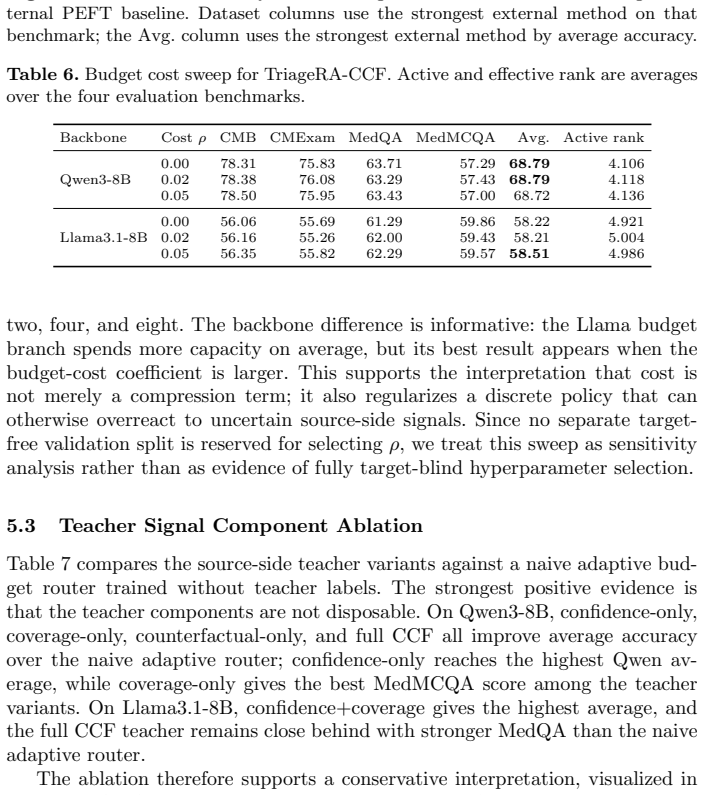
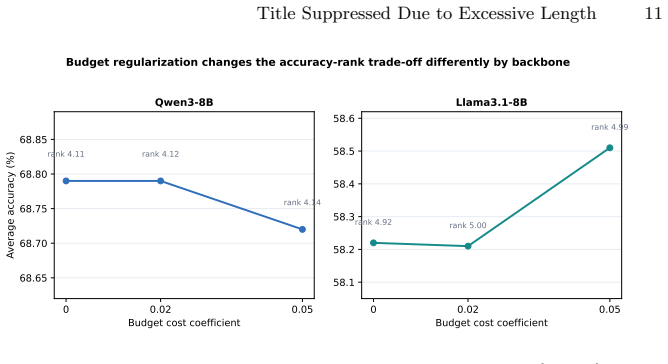
Summary. The manuscript proposes TriageRA-CCF, a source-side teacher for adaptive rank budgeting in medical LLMs. It computes three signals exclusively from source training data—base-model answer confidence, metadata-cell clinical coverage, and a counterfactual close-miss proxy—to supervise a straight-through estimator that routes each question to one of three LoRA rank budgets {2,4,8}, augmented by budget-cost, entropy, and rank-balance regularization. Under a matched CMB-source training protocol, the method is reported to achieve the highest average accuracy among LoRA, DoRA, and MoELoRA baselines on both Qwen3-8B and Llama3.1-8B, with modest gains of +0.21 and +0.16 points respectively; component ablations indicate that the three signals contribute useful supervision but their combination is not monotonically optimal on every backbone.
Significance. If the source-only signals reliably produce stable rank selections that improve accuracy without capacity waste on shifted medical benchmarks, the work would offer a practical route to more efficient parameter adaptation in domain-specific LLMs. The modest headline gains and the explicit acknowledgment that the three-signal combination is not always best temper the potential impact, but the emphasis on preventing router collapse via regularization is a constructive contribution. No machine-checked proofs or fully reproducible artifacts are described.
major comments (2)
- [Abstract] Abstract: the central claim of best average accuracy and useful component contributions cannot be evaluated because the text supplies no experimental protocol details, error bars, statistical tests, or description of how the budget router is trained and optimized.
- [Abstract] Abstract: the acknowledged risk that source-only signals may produce unstable router choices or capacity waste on shifted benchmarks is not addressed by any reported diagnostics; no per-benchmark rank histograms, stability metrics across runs, or adaptive-vs-fixed capacity usage comparisons on out-of-distribution items are provided, leaving the modest aggregate gains compatible with either successful triage or defaulting behavior under regularization.
minor comments (1)
- [Abstract] The abstract refers to a 'matched CMB-source training protocol' without expanding the acronym or protocol; a brief definition or reference would aid readability.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract. Both points correctly identify that the abstract's brevity limits standalone evaluation of the claims and risks. We will revise the abstract to incorporate key protocol details and add a new diagnostics subsection (or expand existing analysis) in the main text to address stability concerns. No standing objections.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of best average accuracy and useful component contributions cannot be evaluated because the text supplies no experimental protocol details, error bars, statistical tests, or description of how the budget router is trained and optimized.
Authors: We agree the abstract is too terse to support evaluation of the headline claims. The full manuscript details the matched CMB-source training protocol (Section 3), the straight-through estimator for the rank router (Section 2.2), and reports per-table standard deviations from multiple runs. We will revise the abstract to add one sentence on the training protocol and explicitly note that accuracy figures include error bars and are compared against LoRA/DoRA/MoELoRA baselines under identical conditions. revision: yes
-
Referee: [Abstract] Abstract: the acknowledged risk that source-only signals may produce unstable router choices or capacity waste on shifted benchmarks is not addressed by any reported diagnostics; no per-benchmark rank histograms, stability metrics across runs, or adaptive-vs-fixed capacity usage comparisons on out-of-distribution items are provided, leaving the modest aggregate gains compatible with either successful triage or defaulting behavior under regularization.
Authors: We accept this observation. The abstract already flags modest/non-uniform gains and the main text describes the three regularization terms intended to avoid collapse, but we did not supply the requested per-benchmark histograms, run-to-run stability metrics, or explicit adaptive-vs-fixed capacity comparisons on OOD items. We will add these diagnostics (rank selection histograms and capacity-usage tables) in the revision to demonstrate that the router does not default under the regularization. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical method for adaptive rank budgeting in medical LLMs using source-side signals (confidence, coverage, counterfactual proxy) to supervise a straight-through router, with reported accuracy gains on benchmarks. No derivation chain, equations, or fitted quantities are described that reduce any claimed result or prediction to the inputs by construction. The supervision signals are computed externally from source data and the evaluation is on separate benchmarks; no self-citation load-bearing, self-definitional steps, or renaming of known results appear in the provided text. The central claim remains an empirical observation rather than a tautological reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dettmers, T., Pagnoni, A., Holtzman, A., Zettlemoyer, L.: QLoRA: Efficient fine- tuning of quantized LLMs (2023),https://arxiv.org/abs/2305.14314
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Journal of Machine Learning Research 23(120), 1–39 (2022)
Fedus, W., Zoph, B., Shazeer, N.: Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research 23(120), 1–39 (2022)
2022
-
[3]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The Llama 3 herd of models (2024),https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
In: Proceedings of the 34th International Conference on Machine Learn- ing
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neural networks. In: Proceedings of the 34th International Conference on Machine Learn- ing. Proceedings of Machine Learning Research, vol. 70, pp. 1321–1330. PMLR (2017)
2017
-
[5]
In: International Conference on Learning Representations (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Conference on Learning Representations (2022)
2022
-
[6]
In: First Conference on Lan- guage Modeling (2024)
Huang, C., Liu, Q., Lin, B.Y., Pang, T., Du, C., Lin, M.: LoraHub: Efficient cross- task generalization via dynamic LoRA composition. In: First Conference on Lan- guage Modeling (2024)
2024
- [7]
-
[8]
Jin, Q., Dhingra, B., Liu, Z., Cohen, W.W., Lu, X.: PubMedQA: A dataset for biomedical research question answering (2019),https://arxiv.org/abs/1909. 06146
2019
- [9]
- [10]
-
[11]
Liu, J., Zhou, P., Hua, Y., Chong, D., Tian, Z., Liu, A., Wang, H., You, C., Guo, Z., Zhu, L., Li, M.L.: Benchmarking large language models on CMExam – a com- prehensive chinese medical exam dataset (2023),https://arxiv.org/abs/2306. 03030
2023
-
[12]
In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (2024)
Liu, Q., Wu, X., Zhao, X., Zhu, Y., Xu, D., Tian, F., Zheng, Y.: When MOE meets LLMs: Parameter efficient fine-tuning for multi-task medical applications. In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (2024)
2024
-
[13]
DoRA: Weight-Decomposed Low-Rank Adaptation
Liu, S.Y., Wang, C.Y., Yin, H., Molchanov, P., Wang, Y.C.F., Cheng, K.T., Chen, M.H.: DoRA: Weight-decomposed low-rank adaptation (2024),https://arxiv. org/abs/2402.09353
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
-
[15]
In: Proceed- ings of the Conference on Health, Inference, and Learning
Pal, A., Umapathi, L.K., Sankarasubbu, M.: MedMCQA: A large-scale multi- subject multi-choice dataset for medical domain question answering. In: Proceed- ings of the Conference on Health, Inference, and Learning. Proceedings of Machine Learning Research, vol. 174, pp. 248–260. PMLR (2022)
2022
-
[16]
In: International Conference on Learning Representations (2017)
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., Dean, J.: Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In: International Conference on Learning Representations (2017)
2017
- [17]
-
[18]
Singhal, K., Tu, T., Gottweis, J., Sayres, R., Wulczyn, E., Hou, L., Clark, K., Pfohl, S., Cole-Lewis, H., Neal, D., et al.: Towards expert-level medical question answering with large language models (2023),https://arxiv.org/abs/2305.09617
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
In: Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (2023)
Valipour, M., Rezagholizadeh, M., Kobyzev, I., Ghodsi, A.: DyLoRA: Parameter efficient tuning of pre-trained models using dynamic search-free low-rank adap- tation. In: Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (2023)
2023
-
[20]
In: International Conference on Learning Representations (2021)
Wang, D., Shelhamer, E., Liu, S., Olshausen, B., Darrell, T.: Tent: Fully test- time adaptation by entropy minimization. In: International Conference on Learning Representations (2021)
2021
- [21]
- [22]
-
[23]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report (2025),https://arxiv.org/abs/2505. 09388
2025
- [24]
-
[25]
Zhang, Q., Chen, M., Bukharin, A., Karampatziakis, N., He, P., Cheng, Y., Chen, W., Zhao, T.: AdaLoRA: Adaptive budget allocation for parameter-efficient fine- tuning (2023),https://arxiv.org/abs/2303.10512
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.