Revisiting Positive Samples in Graph Contrastive Learning: From the Perspective of Message Passing
Pith reviewed 2026-06-27 13:49 UTC · model grok-4.3
The pith
Message passing in graph encoders trivializes the benefit of maximizing positive sample similarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
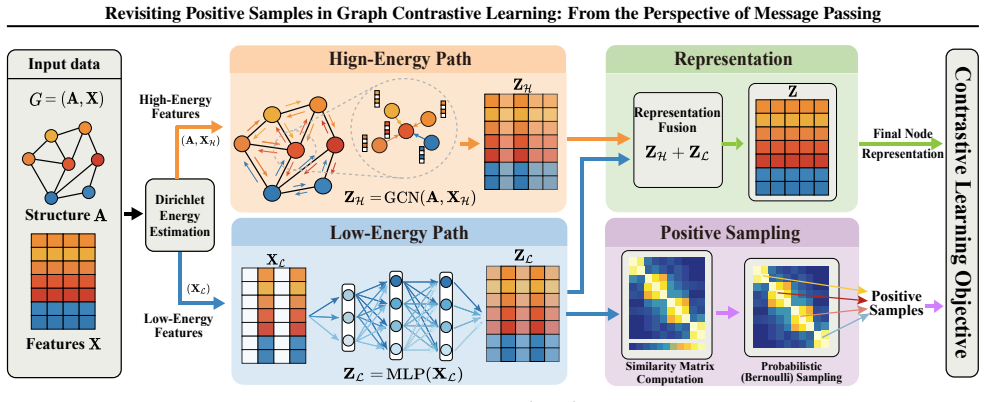
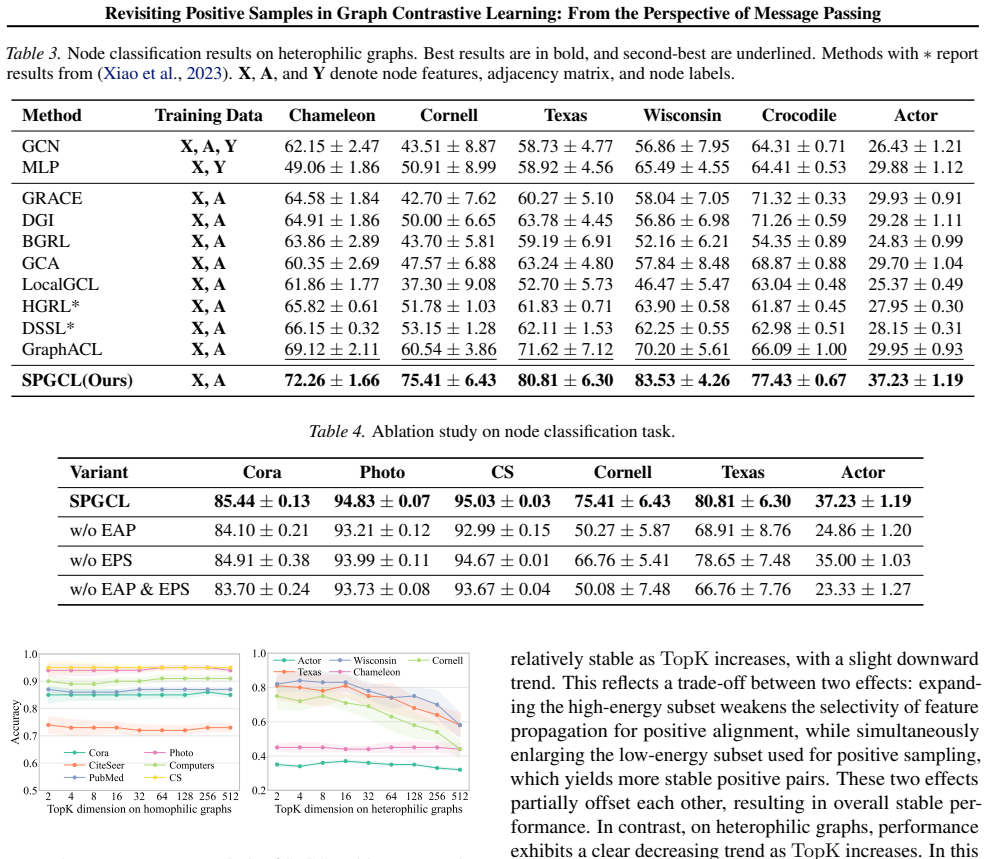
Message passing trivializes positive-sample maximization because it lowers Dirichlet energy of node features, so the contrastive term for positives contributes little to learning; SPGCL restores the signal by propagating only high-energy features and using low-energy features solely to form a probability matrix for positive sampling.
What carries the argument
Dirichlet energy of node features, which decreases under message passing and thereby renders positive-pair alignment redundant; SPGCL uses energy level to decide which features propagate and which only help sample positives.
If this is right
- Positive samples regain informative gradients once only high-energy features are allowed to propagate.
- The same selective-energy rule can be inserted into existing GCL pipelines without altering the contrastive loss itself.
- Low-energy features remain useful but only for constructing reliable positive pairs rather than for representation learning.
Where Pith is reading between the lines
- The energy-based separation of propagation and sampling roles may extend to other message-passing self-supervised tasks on graphs.
- One could test whether similar trivialization appears when contrastive objectives are applied to non-graph data that still uses neighborhood aggregation.
- Replacing the fixed high/low energy cutoff with a learned threshold per layer is a direct next experiment.
Load-bearing premise
The Dirichlet energy drop during message passing is the main reason positive-sample maximization stops supplying useful gradients in standard graph contrastive learning.
What would settle it
Train a standard GCL model and an SPGCL model on the same graphs but replace the graph encoder with a non-propagating MLP, then measure whether the performance lift from using positives becomes large again once message passing is removed.
Figures
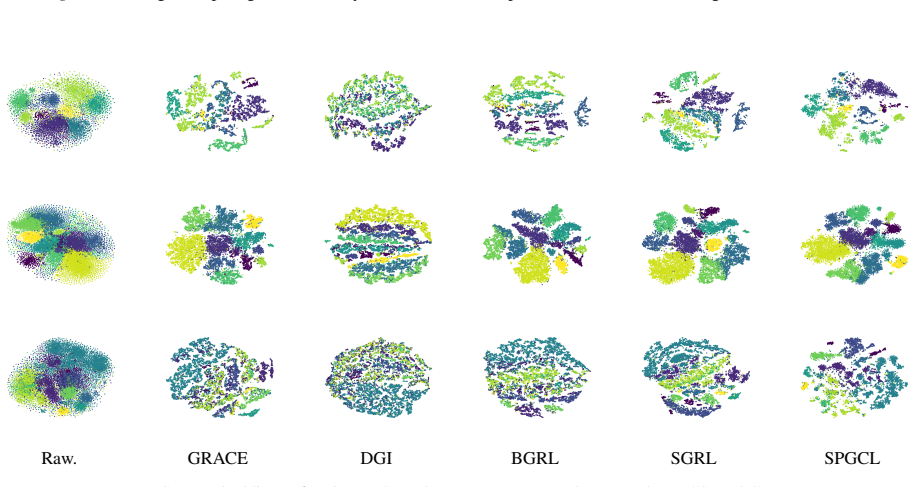
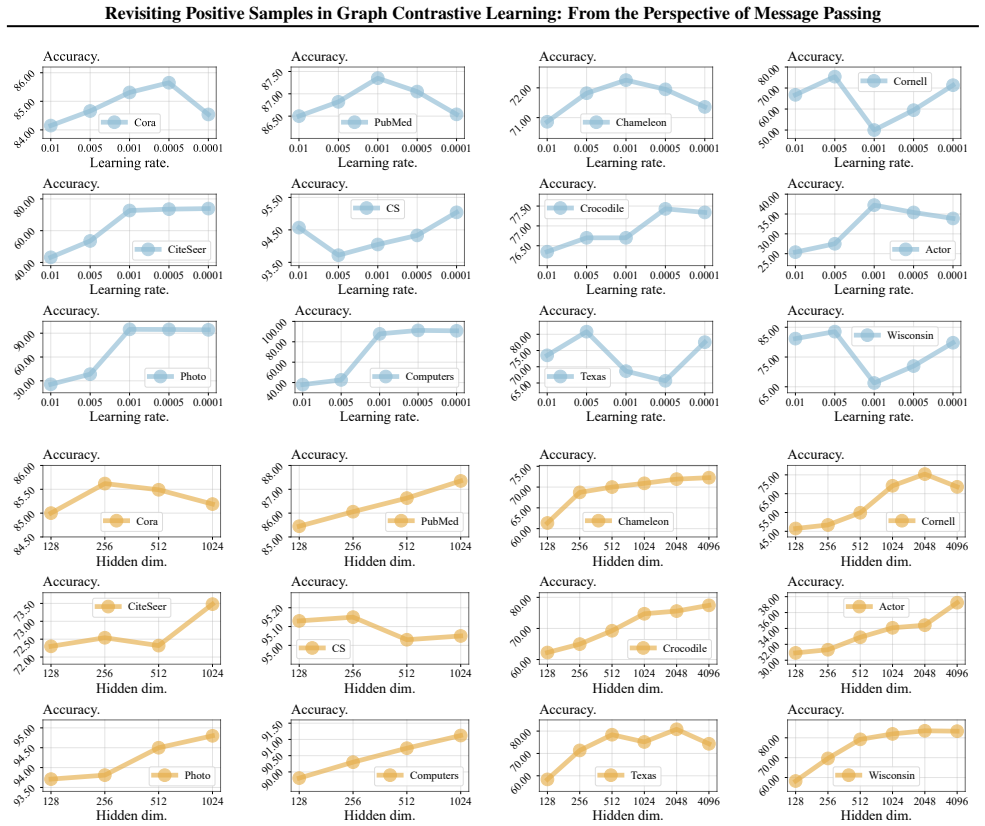
read the original abstract
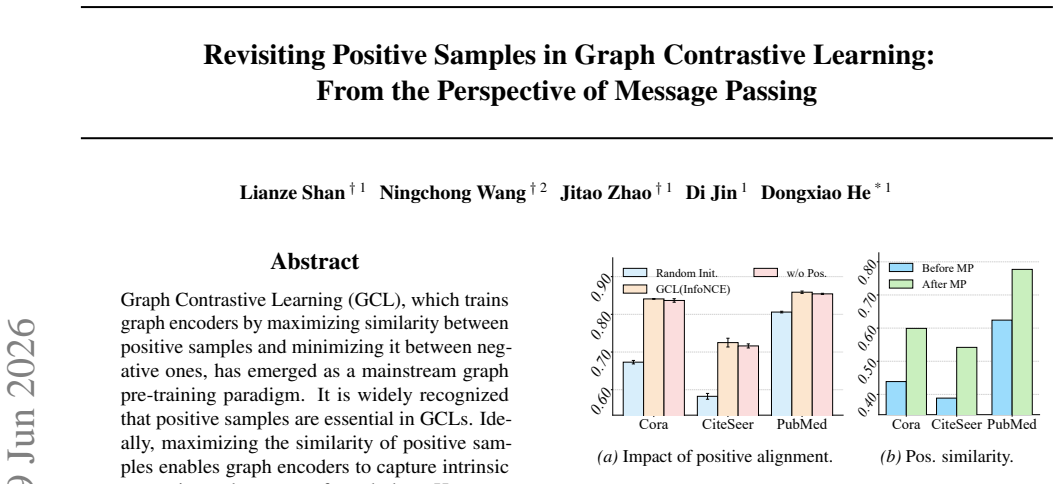
Graph Contrastive Learning (GCL), which trains graph encoders by maximizing similarity between positive samples and minimizing it between negative ones, has emerged as a mainstream graph pre-training paradigm. It is widely recognized that positive samples are essential in GCLs. Ideally, maximizing the similarity of positive samples enables graph encoders to capture intrinsic semantic and patterns of graph data. However, we discover an interesting phenomenon: GCLs can achieve competitive performance even without positive samples. This motivates us to revisit the fundamental mechanism of positive samples in GCLs. From the perspective of Dirichlet energy, we theoretically finds that message passing, a key mechanism in graph encoders, trivializes the maximization of positive samples, preventing GCLs from effectively learning from positive samples. To address this, we propose SPGCL to mitigate the trivialization caused by message passing and restore the learning efficacy of positive samples. Specifically, we find that high Dirichlet energy features help positive samples provide effective learning signals while low Dirichlet energy features contribute little to positive learning signal but is useful for positive sampling. Based on this, SPGCL propagates only high Dirichlet energy features and uses low energy features to construct a probability matrix for reliable positive sampling. Extensive experiments demonstrate the effectiveness of SPGCL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that message passing in standard graph encoders trivializes the maximization of positive samples in Graph Contrastive Learning (GCL), as shown via a Dirichlet energy analysis; this explains the empirical observation that GCL achieves competitive performance even without positive samples. To address the issue, the authors propose SPGCL, which propagates only high Dirichlet energy features through the encoder while using low-energy features solely to construct a probability matrix for positive sample selection.
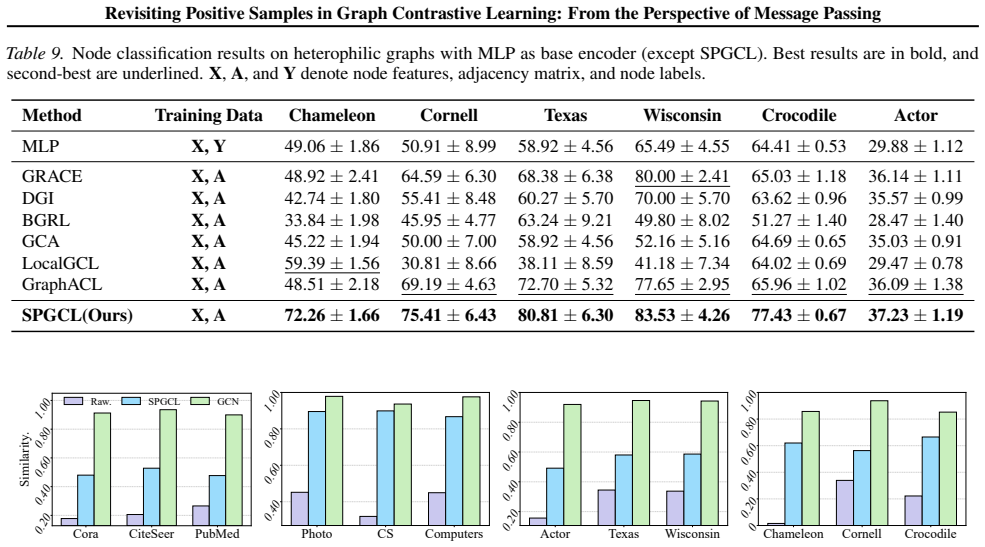
Significance. If the Dirichlet energy analysis correctly explains the limited utility of positive-sample maximization under message passing and if SPGCL demonstrably restores effective learning signals, the work would supply both a mechanistic account of a known GCL phenomenon and a concrete architectural fix. The selective propagation idea is a strength, but its value hinges on whether the theoretical result applies to the non-linear encoders actually used in practice.
major comments (2)
- [Abstract and §3] Abstract and §3 (theoretical analysis): the central claim that message passing 'trivializes the maximization of positive samples' is asserted from the Dirichlet energy perspective, yet the abstract supplies no equations, proof steps, or derivation. Without these, it is impossible to verify whether the analysis models only linear aggregation or also accounts for the non-linear activations and multi-layer stacking present in the GCN/GAT encoders used in the experiments.
- [§4] §4 (experiments) and the skeptic note: the claim that SPGCL restores positive-sample efficacy rests on the transfer of the linear Dirichlet-energy result to the non-linear encoders; if the derivation does not extend, the performance gains cannot be attributed to the proposed mechanism. Concrete verification (e.g., energy trajectories before/after the selective propagation step) is required.
minor comments (2)
- [Abstract] Abstract: 'theoretically finds' should be 'theoretically find'; 'is useful for positive sampling' is grammatically incomplete.
- [Abstract] The abstract states that 'extensive experiments demonstrate the effectiveness of SPGCL' without naming datasets, baselines, or metrics; these details belong in the abstract or a dedicated results paragraph.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our theoretical analysis and its connection to the experiments. Below we respond point-by-point to the major comments. We are happy to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (theoretical analysis): the central claim that message passing 'trivializes the maximization of positive samples' is asserted from the Dirichlet energy perspective, yet the abstract supplies no equations, proof steps, or derivation. Without these, it is impossible to verify whether the analysis models only linear aggregation or also accounts for the non-linear activations and multi-layer stacking present in the GCN/GAT encoders used in the experiments.
Authors: The abstract is a concise summary and therefore omits the full derivation, which appears in Section 3. The analysis there starts from the linear message-passing operator and shows that repeated aggregation monotonically decreases Dirichlet energy, driving positive-pair representations toward each other irrespective of the contrastive objective. While the derivation is stated for the linear case, the smoothing effect it isolates is the dominant behavior observed even when non-linear activations and multiple layers are present; the experiments with GCN and GAT encoders are consistent with this view. To improve verifiability we will add a one-sentence pointer to the key energy bound (Equation 4 in §3) inside the abstract. revision: partial
-
Referee: [§4] §4 (experiments) and the skeptic note: the claim that SPGCL restores positive-sample efficacy rests on the transfer of the linear Dirichlet-energy result to the non-linear encoders; if the derivation does not extend, the performance gains cannot be attributed to the proposed mechanism. Concrete verification (e.g., energy trajectories before/after the selective propagation step) is required.
Authors: We agree that explicit verification of the energy-reduction mechanism under the non-linear encoders used in the experiments would strengthen the causal link. SPGCL’s selective propagation is directly motivated by the linear analysis, and the reported gains appear across both GCN and GAT backbones. In the revised manuscript we will add plots of Dirichlet energy trajectories computed on the actual (non-linear) feature maps before and after the high-energy propagation step, thereby providing the requested concrete evidence. revision: yes
Circularity Check
No significant circularity; theoretical claim independent of construction
full rationale
The provided abstract and description present the Dirichlet energy analysis of message passing as a standalone theoretical finding that explains the observed phenomenon of GCL performance without positives. No equations, fitted parameters renamed as predictions, or self-citation chains are visible that would reduce the central claim to its own inputs by construction. The SPGCL proposal follows from the analysis rather than defining or presupposing it, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Message passing in graph encoders trivializes maximization of positive samples as diagnosed by Dirichlet energy
Reference graph
Works this paper leans on
-
[1]
Csgcl: community-strength-enhanced graph contrastive learning.arXiv preprint arXiv:2305.04658,
Chen, H., Zhao, Z., Li, Y ., Zou, Y ., Li, R., and Zhang, R. Csgcl: community-strength-enhanced graph contrastive learning.arXiv preprint arXiv:2305.04658,
-
[2]
Fast Graph Representation Learning with PyTorch Geometric
Fey, M. and Lenssen, J. E. Fast graph representation learning with pytorch geometric.arXiv preprint arXiv:1903.02428,
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[3]
He, D., Shan, L., Zhao, J., Zhang, H., Wang, Z., and Zhang, W. Exploitation of a latent mechanism in graph con- trastive learning: Representation scattering.Advances in Neural Information Processing Systems, 37:115351– 115376, 2024a. He, D., Zhao, J., Huo, C., Huang, Y ., Huang, Y ., and Feng, Z. A new mechanism for eliminating implicit conflict in graph ...
-
[4]
Lightgcn: Simplifying and powering graph convolution network for recommendation
He, X., Deng, K., Wang, X., Li, Y ., Zhang, Y ., and Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Huang, J. X., Chang, Y ., Cheng, X., Kamps, J., Murdock, V ., Wen, J., and Liu, Y . (eds.),Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2...
2020
-
[5]
doi: 10.1145/3397271. 3401063. Huang, Y ., Zhao, J., He, D., Jin, D., Huang, Y ., and Wang, Z. Does gcl need a large number of negative samples? en- hancing graph contrastive learning with effective and effi- cient negative sampling. InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 39, pp. 17511– 17518,
-
[6]
Kipf, T. N. and Welling, M. Semi-supervised classification with graph convolutional networks. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net,
2017
-
[7]
Augmentation-free self- supervised learning on graphs
Lee, N., Lee, J., and Park, C. Augmentation-free self- supervised learning on graphs. InThirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty- Fourth Conference on Innovative Applications of Artifi- cial Intelligence, IAAI 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI 2022 Virtual Event, Februar...
2022
-
[8]
doi: 10.1609/aaai.v36i7. 20700. Li, S., Zhou, J., Xu, T., Dou, D., and Xiong, H. Geomgcl: Geometric graph contrastive learning for molecular prop- erty prediction. InProceedings of the AAAI conference on artificial intelligence, volume 36, pp. 4541–4549,
-
[9]
Oord, A. v. d., Li, Y ., and Vinyals, O. Representation learn- ing with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Pei, H., Wei, B., Chang, K. C.-C., Lei, Y ., and Yang, B. Geom-gcn: Geometric graph convolutional networks. arXiv preprint arXiv:2002.05287, 2020a. Pei, H., Wei, B., Chang, K. C.-C., Lei, Y ., and Yang, B. Geom-gcn: Geometric graph convolutional networks. arXiv preprint arXiv:2002.05287, 2020b. Ribeiro, L. F., Saverese, P. H., and Figueiredo, D. R. struc2...
-
[11]
Dropout: a simple way to prevent neural networks from overfitting.The journal of machine learning research, 15(1):1929–1958,
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R. Dropout: a simple way to prevent neural networks from overfitting.The journal of machine learning research, 15(1):1929–1958,
1929
-
[12]
Adversarial graph augmentation to improve graph contrastive learning
Suresh, S., Li, P., Hao, C., and Neville, J. Adversarial graph augmentation to improve graph contrastive learning. In Ranzato, M., Beygelzimer, A., Dauphin, Y . N., Liang, P., and Vaughan, J. W. (eds.),Advances in Neural Infor- mation Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021,...
2021
-
[13]
G., Munos, R., Veliˇckovi´c, P., and Valko, M
Thakoor, S., Tallec, C., Azar, M. G., Munos, R., Veliˇckovi´c, P., and Valko, M. Bootstrapped representation learning 10 Revisiting Positive Samples in Graph Contrastive Learning: From the Perspective of Message Passing on graphs. InICLR 2021 Workshop on Geometrical and Topological Representation Learning,
2021
-
[14]
Graph attention networks
Velickovic, P., Cucurull, G., Casanova, A., Romero, A., Li`o, P., and Bengio, Y . Graph attention networks. In6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net,
2018
-
[15]
L., Li`o, P., Bengio, Y ., and Hjelm, R
Velickovic, P., Fedus, W., Hamilton, W. L., Li`o, P., Bengio, Y ., and Hjelm, R. D. Deep graph infomax. In7th Inter- national Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9,
2019
-
[16]
Wu, L., Lin, H., Tan, C., Gao, Z., and Li, S. Z. Self- supervised learning on graphs: Contrastive, generative, or predictive.IEEE Transactions on Knowledge and Data Engineering, 35(4):4216–4235, 2021a. Wu, Z., Pan, S., Chen, F., Long, G., Zhang, C., and Philip, S. Y . A comprehensive survey on graph neural networks. IEEE Trans. Neural Networks Learn. Syst...
2022
-
[17]
Zhang, H., Wu, Q., Wang, Y ., Zhang, S., Yan, J., and Yu, P. S. Localized contrastive learning on graphs.arXiv preprint arXiv:2212.04604, 2022a. Zhang, S., Huang, Z., Zhou, H., and Zhou, Z. Sce: Scal- able network embedding from sparsest cut. InProceed- ings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 257–265,
-
[18]
Zhang, Y . An introduction to matrix factorization and factor- ization machines in recommendation system, and beyond. arXiv preprint arXiv:2203.11026,
-
[19]
Deep graph contrastive representation learning.CoRR, abs/2006.04131,
Zhu, Y ., Xu, Y ., Yu, F., Liu, Q., Wu, S., and Wang, L. Deep graph contrastive representation learning.CoRR, abs/2006.04131,
-
[20]
Graph contrastive learning with adaptive augmentation
Zhu, Y ., Xu, Y ., Yu, F., Liu, Q., Wu, S., and Wang, L. Graph contrastive learning with adaptive augmentation. InWWW ’21: The Web Conference 2021, Virtual Event / Ljubljana, Slovenia, April 19-23, 2021, pp. 2069–2080. ACM / IW3C2,
2021
-
[21]
Unified graph augmentations for generalized contrastive learning on graphs
Zhuo, J., Lu, Y ., Ning, H., Fu, K., Niu, B., He, D., Wang, C., Guo, Y ., Wang, Z., Cao, X., and Yang, L. Unified graph augmentations for generalized contrastive learning on graphs. InNeurIPS, 2024a. Zhuo, J., Qin, F., Cui, C., Fu, K., Niu, B., Wang, M., Guo, Y ., Wang, C., Wang, Z., Cao, X., and Yang, L. Improving graph contrastive learning via adaptive ...
2020
-
[22]
or random walk–based techniques (Lawler & Limic, 2010), which focus on either graph structure or node attributes and thus struggle to jointly model both (Ribeiro et al., 2017). With the emergence of Graph Neural Networks (GNNs), such as GCN (Kipf & Welling, 2017), GAT (Velickovic et al., 2018), and GraphSAGE (Hamilton et al., 2017), message passing and ag...
2010
-
[23]
They employ two asymmetric graph encoders and learn representations by aligning positive pairs across different views
adopt a bootstrap framework that trains models without negative samples. They employ two asymmetric graph encoders and learn representations by aligning positive pairs across different views. These methods represent an early attempt to exploit positive samples learning in GCLs. However, recent studies show that the effectiveness of such bootstrap framewor...
2020
-
[24]
Each node denotes a paper and each edge denotes a citation relation
Citation networks.Cora, CiteSeer, and PubMed are widely used citation datasets from Planetoid (Sen et al., 2008; Yang 12 Revisiting Positive Samples in Graph Contrastive Learning: From the Perspective of Message Passing et al., 2016). Each node denotes a paper and each edge denotes a citation relation. Node attributes come from sparse bag-of-words represe...
2008
-
[25]
false hard negatives
describe co-purchasing relations in e-commerce. Nodes are products in their respective catalogs. Edges link items that are often purchased together. Each node uses sparse text features extracted from user reviews. Labels mark high-level product types.. Co-author networks.The Co.CS dataset is built from the Microsoft Academic Graph (MAG) (Sinha et al., 201...
2015
-
[26]
Table 6.Experimental environment servers. Server 1 Server 2 OS Linux 6.8.0-87-generic Linux 6.14.0-33-generic CPU Intel(R) Xeon(R) Silver 4410Y Intel(R) Core(TM) i5-12400 CPU @ 3.00GHz GPU Nvidia GeForce RTX 5090 Nvidia GeForce RTX 3090 15 Revisiting Positive Samples in Graph Contrastive Learning: From the Perspective of Message Passing Table 7.Hyper-para...
2048
-
[27]
We consider a binary random variable S∈ {0,1} indicating whether a node pair is a positive or a negative sample. Specifically, we sample(i, j)as (i, j)∼ ( P+ :i∼π, j∼T(i,·), S= 1, P− :i∼π, j∼πindependently, S= 0, (26) which corresponds to local neighborhood–based positives and randomly sampled negatives. For the m-th feature dimension, we define the simil...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.