From Learning Resources to Competencies: LLM-Based Tagging with Evidence and Graph Constraints
Pith reviewed 2026-06-29 12:37 UTC · model grok-4.3
The pith
A constrained LLM pipeline using BM25 retrieval and graph context for candidate selection, evidence span production, and graph refinement outperforms baselines in linking learning resources to competencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
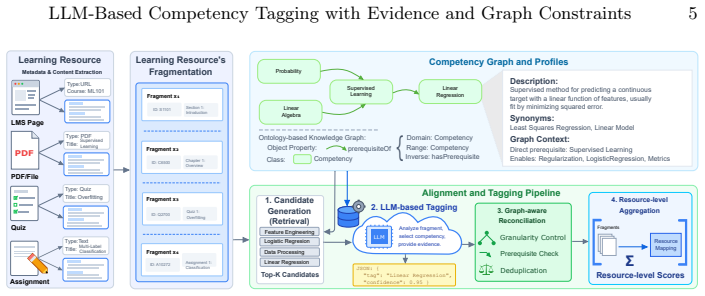
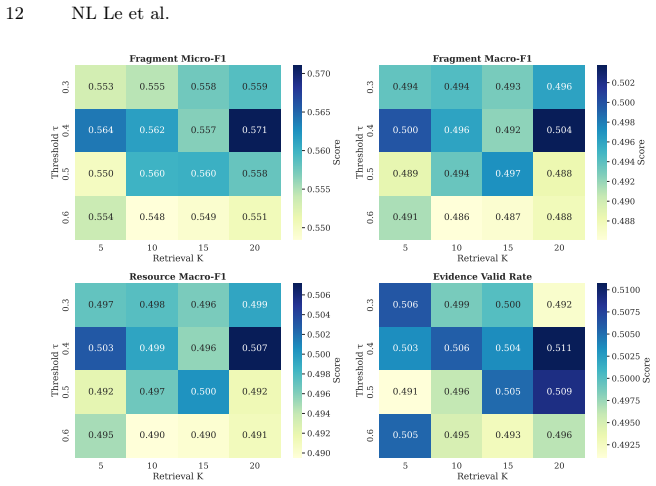
The end-to-end pipeline segments LMS resources into pedagogical fragments, retrieves candidate competencies from graph-enriched profiles using BM25, lets the LLM select the most relevant and provide supporting evidence spans from the text, refines the predictions using the competency graph structure, and aggregates at the resource level. Evaluated on the UTC Computer Science competency referential with 22 competencies, the LLM+BM25+Graph (LBG) pipeline achieves micro-F1 of 0.57 and macro-F1 of 0.50 at fragment level, macro-F1 of 0.51 at resource level, and MRR of 0.82, outperforming zero-shot, few-shot, retrieval, and supervised baselines while producing traceable evidence spans for auditing
What carries the argument
The LLM+BM25+Graph (LBG) pipeline that constrains the LLM to a small set of graph-contextualized candidates and requires it to output evidence spans before graph-based refinement.
If this is right
- Competency-based search and curriculum analytics in LMS become more practical without full manual tagging.
- Human auditors can verify the tags using the mechanically traceable evidence spans from the original fragments.
- Resource-level aggregation supports overall curriculum analysis across courses.
- The method applies to both instructional content and assessments.
- It yields higher accuracy and transparency than pure LLM prompting or traditional classifiers.
Where Pith is reading between the lines
- The approach could be tested on competency frameworks from other disciplines or institutions to check generalizability.
- Evidence spans might be used to create targeted feedback for learners on which parts of a resource address specific competencies.
- If the graph contains inconsistencies, the refinement step risks amplifying those errors in the final tags.
- Real-time integration into an LMS could allow automatic re-tagging when resources or competencies are updated.
Load-bearing premise
The competency graph is a reliable source of constraints that improves LLM predictions rather than distorting them, and the LLM reliably identifies accurate evidence spans from the fragments.
What would settle it
On the UTC dataset, the micro-F1 score at fragment level drops below 0.45 when the graph refinement is removed, or human review finds that over 40 percent of the LLM-provided evidence spans do not actually support the assigned competency tags.
Figures
read the original abstract
Linking learning resources to a structured competency framework is key to enabling competency-based search and curriculum analytics in Learning Management Systems (LMS). However, manual tagging is labor-intensive, and fully automatic methods often lack transparency. In this paper, we present an end-to-end alignment pipeline that uses a large language model (LLM) as a constrained, evidence-producing tagger. LMS resources -both instructional content and assessments -are first segmented into meaningful pedagogical fragments. For each fragment, a small set of candidate competencies is retrieved from structured competency profiles enriched with graph-based context. The LLM then selects the most relevant competencies from this set and provides supporting evidence spans from the fragment text. These predictions are refined using the structure of the competency graph and aggregated at the resource level. We evaluate our approach on a dataset built from the Computer Science department's competency referential at the Universit\'e de Technologie de Compi\`egne (UTC), covering 22 competencies across multiple course materials. Our LLM+BM25+Graph (LBG) pipeline achieves strong results, with a micro-F1 of 0.57 and macro-F1 of 0.50 at the fragment level, 0.51 macro-F1 at the resource level, and an MRR of 0.82outperforming zero-shot and few-shot LLM variants, retrieval/similarity baselines, and supervised classifiers -while also producing more mechanically traceable evidence spans to support human auditing and educational analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims an end-to-end LLM+BM25+Graph (LBG) pipeline for tagging learning-resource fragments to competencies: fragments are segmented, candidates retrieved via BM25 from graph-enriched profiles, an LLM selects tags with evidence spans, predictions are refined via the competency graph, and tags are aggregated to the resource level. On a UTC CS dataset covering 22 competencies, it reports fragment-level micro-F1 0.57 / macro-F1 0.50, resource-level macro-F1 0.51, and MRR 0.82, outperforming zero-shot/few-shot LLM, retrieval, and supervised baselines while producing auditable evidence spans.
Significance. If the performance numbers and traceability claims hold after proper validation, the work would offer a practical, evidence-producing method for competency alignment in LMS and curriculum tools. The combination of retrieval, LLM selection, and graph refinement is a reasonable direction; however, the evaluation scale (only 22 competencies from one institution) and missing controls limit immediate impact.
major comments (1)
- [Pipeline description and evaluation sections] The central LBG claim rests on graph refinement improving LLM predictions, yet the manuscript provides neither an ablation isolating this step nor a formal description (pseudocode, equations, or constraint definition) of how the competency graph is applied to refine fragment-level tags. Without this, it is impossible to determine whether the reported micro-F1 of 0.57 is driven by the graph or by the LLM+BM25 components alone.
minor comments (2)
- [Evaluation] No dataset statistics (number of fragments, resources, or label distribution), error bars, or significance tests accompany the F1 and MRR figures.
- [Abstract] The abstract states outperformance over 'supervised classifiers' without naming the models, features, or training protocol used for those baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the need for greater transparency regarding the graph refinement component of the LBG pipeline. We address the point below.
read point-by-point responses
-
Referee: [Pipeline description and evaluation sections] The central LBG claim rests on graph refinement improving LLM predictions, yet the manuscript provides neither an ablation isolating this step nor a formal description (pseudocode, equations, or constraint definition) of how the competency graph is applied to refine fragment-level tags. Without this, it is impossible to determine whether the reported micro-F1 of 0.57 is driven by the graph or by the LLM+BM25 components alone.
Authors: We agree that the manuscript as submitted does not contain a formal description or ablation isolating the graph refinement step. In the revision we will add (1) a precise definition of the refinement operation, including pseudocode that specifies the graph constraints (e.g., propagation along prerequisite and hierarchical edges to enforce consistency and remove contradictory tags) and (2) an ablation that reports fragment-level micro- and macro-F1 for the LLM+BM25 stage alone versus the full LBG pipeline. These additions will allow readers to quantify the incremental contribution of the graph component to the reported 0.57 micro-F1. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an empirical pipeline (LLM+BM25+Graph) for competency tagging, with the competency graph supplied as an external input from the university referential and all reported metrics (micro-F1 0.57, macro-F1 0.50, MRR 0.82) obtained by direct comparison against independent baselines (zero-shot/few-shot LLM, retrieval, supervised classifiers). No equations, derivations, or self-citations appear that reduce any claimed result to a fitted parameter or input defined by the authors themselves; the graph refinement step is presented as an applied heuristic on external structure rather than a self-referential prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The competency graph accurately encodes relationships that can be used to refine tagging predictions.
Reference graph
Works this paper leans on
-
[1]
https://www.francetravail.org/opendata/repertoire-operationnel-des-meti.html, [Accessed January 2026]
Rome: Répertoire opérationnel des métiers et emplois. https://www.francetravail.org/opendata/repertoire-operationnel-des-meti.html, [Accessed January 2026]
2026
-
[2]
Advances in neural information processing systems 33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., et al.: Language models are few-shot learners. Advances in neural information processing systems 33, 1877–1901 (2020)
1901
-
[3]
Publications Office of the EU (2019)
Commission, E.: Esco handbook european skills, competences, qualifications and occupations. Publications Office of the EU (2019)
2019
-
[4]
In: Proceedings of the 32nd in- ternational ACM SIGIR conference on Research and development in information retrieval
Cormack, G.V., Clarke, C.L., Buettcher, S.: Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In: Proceedings of the 32nd in- ternational ACM SIGIR conference on Research and development in information retrieval. pp. 758–759 (2009)
2009
-
[5]
In: Proceedings of the 58th annual meeting of the association for computational linguistics
DeYoung, J., Jain, S., Rajani, N.F., et al.: Eraser: A benchmark to evaluate ratio- nalized nlp models. In: Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 4443–4458 (2020)
2020
-
[6]
Goff, L., Potter, M.K., Pierre, E., Carey, T., et al.: Learning outcomes assessment a practitioner’s handbook (2015)
2015
-
[7]
Education and Information Technologies23(1), 41–60 (2018)
Gottipati, S., Shankararaman, V.: Competency analytics tool: Analyzing curricu- lum using course competencies. Education and Information Technologies23(1), 41–60 (2018)
2018
-
[8]
In: European conference on machine learning
Joachims, T.: Text categorization with support vector machines: Learning with many relevant features. In: European conference on machine learning. pp. 137–
-
[9]
In: International Con- ference on Intelligent Tutoring Systems
Karlovec, M., Córdova-Sánchez, M., Pardos, Z.A.: Knowledge component sugges- tion for untagged content in an intelligent tutoring system. In: International Con- ference on Intelligent Tutoring Systems. pp. 195–200. Springer (2012) LLM-Based Competency Tagging with Evidence and Graph Constraints 15
2012
-
[10]
In: EMNLP (1)
Karpukhin, V., Oguz, B., Min, S., et al.: Dense passage retrieval for open-domain question answering. In: EMNLP (1). pp. 6769–6781 (2020)
2020
-
[11]
British Journal of Educational Technology55(5), 2039–2057 (2024)
Kwak, Y., Pardos, Z.A.: Bridging large language model disparities: Skill tagging of multilingual educational content. British Journal of Educational Technology55(5), 2039–2057 (2024)
2039
-
[12]
arXiv preprint arXiv:2507.18479 (2025)
Le, N.L., Abel, M.H.: How well do llms predict prerequisite skills? zero-shot com- parison to expert-defined concepts. arXiv preprint arXiv:2507.18479 (2025)
-
[13]
Advances in neural information pro- cessing systems33, 9459–9474 (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information pro- cessing systems33, 9459–9474 (2020)
2020
-
[14]
Computers & Edu- cation216, 105027 (2024)
Li, Z., Pardos, Z.A., Ren, C.: Aligning open educational resources to new tax- onomies: How ai technologies can help and in which scenarios. Computers & Edu- cation216, 105027 (2024)
2024
-
[15]
arXiv preprint arXiv:2510.11313 (2025)
Luyen, L.N., Abel, M.H.: Automated skill decomposition meets expert ontologies: Bridging the granularity gap with llms. arXiv preprint arXiv:2510.11313 (2025)
-
[16]
Heliyon10(7) (2024)
Milosz, M., Nazyrova, A., Mukanova, A., Bekmanova, G., et al.: Ontological ap- proach for competency-based curriculum analysis. Heliyon10(7) (2024)
2024
-
[17]
In: Proceedings of the eleventh ACM conference on learning@ scale
Moore, S., Schmucker, R., Mitchell, T., Stamper, J.: Automated generation and tagging of knowledge components from multiple-choice questions. In: Proceedings of the eleventh ACM conference on learning@ scale. pp. 122–133 (2024)
2024
-
[18]
Applied Sciences13(4), 2661 (2023)
Nazyrova, A., Milosz, M., Bekmanova, G., et al.: Analysis of the consistency of prerequisites and learning outcomes of educational programme courses by using the ontological approach. Applied Sciences13(4), 2661 (2023)
2023
-
[19]
Nogueira, R., Cho, K.: Passage re-ranking with bert. arXiv preprint arXiv:1901.04085 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[20]
In: Proceedings of the 25th Conference on User Modeling, Adaptation and Personalization
Pardos, Z.A., Dadu, A.: Imputing kcs with representations of problem content and context. In: Proceedings of the 25th Conference on User Modeling, Adaptation and Personalization. pp. 148–155 (2017)
2017
-
[21]
American Journal of Pharmaceutical Education71(2), 20 (2007)
Plaza, C.M., Draugalis, J.R., Slack, M.K., et al.: Curriculum mapping in program assessment and evaluation. American Journal of Pharmaceutical Education71(2), 20 (2007)
2007
-
[22]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. arXiv preprint arXiv:1908.10084 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[23]
Foundations and trends in information retrieval3(4), 333–389 (2009)
Robertson, S., Zaragoza, H., et al.: The probabilistic relevance framework: Bm25 and beyond. Foundations and trends in information retrieval3(4), 333–389 (2009)
2009
-
[24]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Sanh, V., Debut, L., Chaumond, J., Wolf, T.: Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[25]
Cogent Education11(1), 2342662 (2024)
Smith, H.R., Chittams, J.: Defining best practices and validation for curriculum mapping. Cogent Education11(1), 2342662 (2024)
2024
-
[26]
In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Tang, R., Zhu, C., Chen, B., Zhang, W., et al.: Llm4tag: Automatic tagging system for information retrieval via large language models. In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. pp. 4882–4890 (2025)
2025
-
[27]
In: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics
Wang, S.I., Manning, C.D.: Baselines and bigrams: Simple, good sentiment and topic classification. In: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. pp. 90–94 (2012)
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.