The MMM Data Model -- A Normative Specification for Knowledge Interoperability in a Decentralisable Knowledge Commons
Pith reviewed 2026-07-02 21:30 UTC · model grok-4.3
The pith
MMM combines a small set of normative constraints with free-text labels to enable knowledge interoperability across disciplines without requiring semantic convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MMM is a data model that emerged from practical needs in interdisciplinary collaborative research. It specifies a small set of normative constraints on how knowledge units are documented while allowing full expressive freedom through free-text labels. The design supports interoperability across disciplines, applications, and deployments without requiring semantic convergence, positioning it as a normative specification for a decentralisable knowledge commons.
What carries the argument
The MMM data model, which applies a small set of normative constraints to knowledge units while relying on free-text labels to carry expressive content.
If this is right
- Knowledge can be structured and updated in ways that overcome the linear and self-contained limits of documents.
- Interoperability becomes possible across fields and systems without first achieving agreement on meanings.
- The model supports decentralisable commons where contributions remain portable across different deployments.
- Human usability and scope are maintained alongside the normative constraints, as shown in the pilot data.
Where Pith is reading between the lines
- This structure could allow AI-generated content to be exchanged in a form that remains directly usable by humans without additional translation layers.
- It offers a route for collaborative platforms to lower barriers to contribution by avoiding the need for full formal ontologies.
- The approach invites direct tests in larger-scale settings to check whether the balance of constraints and freedom holds as user diversity increases.
Load-bearing premise
That a small set of normative constraints combined with free-text labels suffices to achieve interoperability without semantic convergence while preserving human usability and broad scope.
What would settle it
A documented case where users from different disciplines follow the MMM constraints yet still cannot effectively share or reuse knowledge units due to incompatible interpretations of the free-text labels.
Figures




read the original abstract
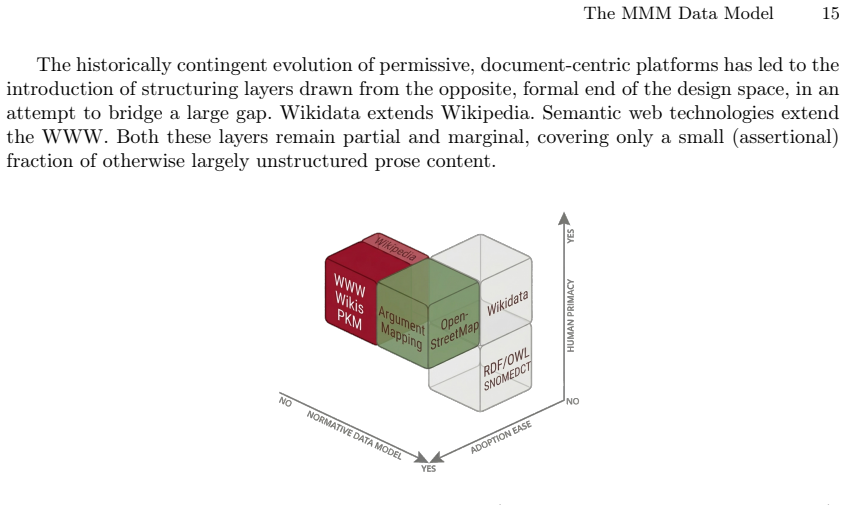
Many information systems are built around documents: self-contained units optimised for print production and linear reading. While effective for large-scale dissemination, the document-centric organisation constrains how knowledge can be structured, updated, shared, and reused. Formal approaches address some of these limitations but struggle to achieve widespread contribution and adoption due to their prioritisation of formal structure over other system properties such as human usability and scope. AI systems are reshaping document production, but without providing a unified portable alternative to traditional documents for humans' expression and exchange of knowledge. This paper presents MMM, a data model for knowledge documentation that emerged from the practical needs of interdisciplinary collaborative research, and positioned here within a comparative analysis of the design space of information systems. MMM combines a small set of normative constraints with the expressive freedom of free-text labels. It is designed for interoperability across disciplines, applications and deployments without requiring semantic convergence. A reference implementation and pilot deployment data demonstrate implementability and early usability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the MMM data model as a normative specification for knowledge documentation. It positions MMM within a comparative analysis of information system design spaces, arguing that a small set of normative constraints paired with free-text labels enables interoperability across disciplines, applications, and deployments without requiring semantic convergence. The design is motivated by practical needs in interdisciplinary research; support is provided via a reference implementation and pilot deployment data demonstrating implementability and early usability.
Significance. If the claims hold, MMM offers a pragmatic middle path between document-centric systems and rigid formalisms, potentially supporting decentralized knowledge commons with better human usability and scope. The reference implementation and pilot data constitute concrete strengths for a specification paper, as they allow direct assessment of the normative constraints' sufficiency.
minor comments (2)
- [Abstract] The abstract states that pilot deployment data demonstrate 'early usability,' but the main text should include explicit metrics or qualitative criteria used to evaluate interoperability and usability (e.g., contribution rates, cross-deployment consistency).
- Notation for the normative constraints and free-text label mechanism should be introduced with a single running example early in the paper to aid readability for readers unfamiliar with the design space.
Simulated Author's Rebuttal
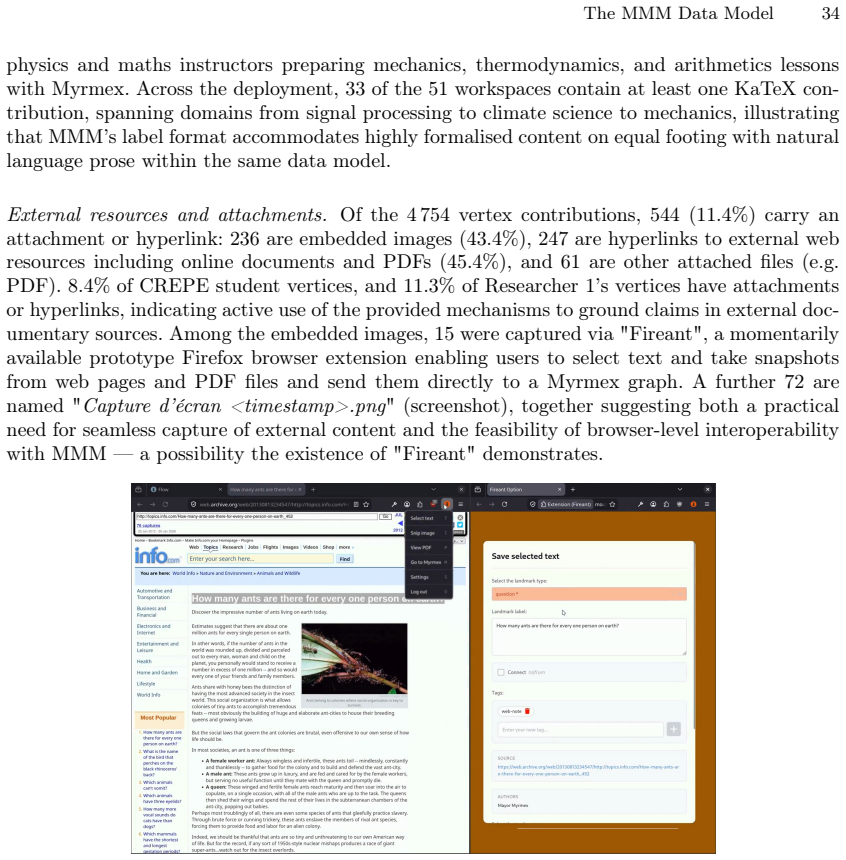
We thank the referee for their positive summary of the manuscript and for recommending minor revision. The report accurately captures the core positioning of MMM as a middle path in the design space of information systems. No specific major comments were raised in the report.
Circularity Check
No significant circularity in normative specification
full rationale
This is a design specification paper that introduces the MMM data model as a set of normative constraints paired with free-text labels. No equations, fitted parameters, predictions, or derivation chains are present in the abstract or described structure. Claims of interoperability are positioned as outcomes of the design choices themselves rather than derived from prior results or self-citations. The reference implementation is cited as external demonstration, not as a self-referential fit. The argument is self-contained as a normative proposal without reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A small set of normative constraints is sufficient for interoperability without semantic convergence
invented entities (1)
-
MMM data model
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.