Pooled Leaderboards Hide System-Specific Winners: A Reporting-Protocol Audit of Offline Root-Cause Analysis Benchmarks
Pith reviewed 2026-06-30 07:50 UTC · model grok-4.3
The pith
Pooled leaderboards in root-cause analysis benchmarks select a method that loses on many individual subsystems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
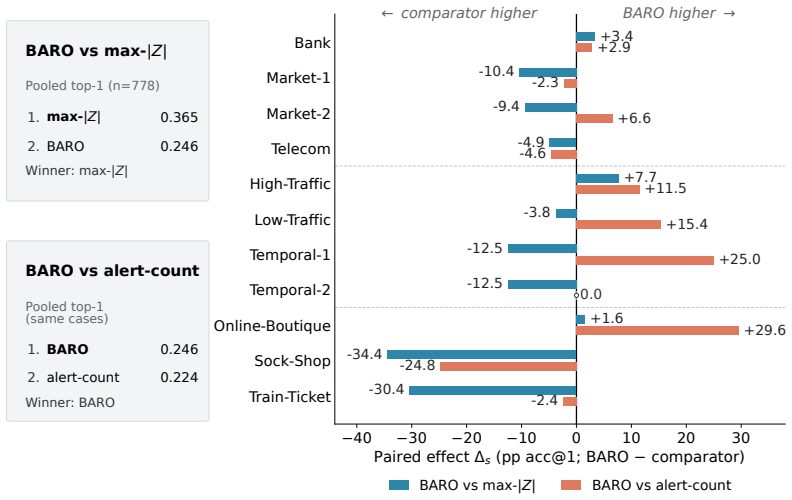
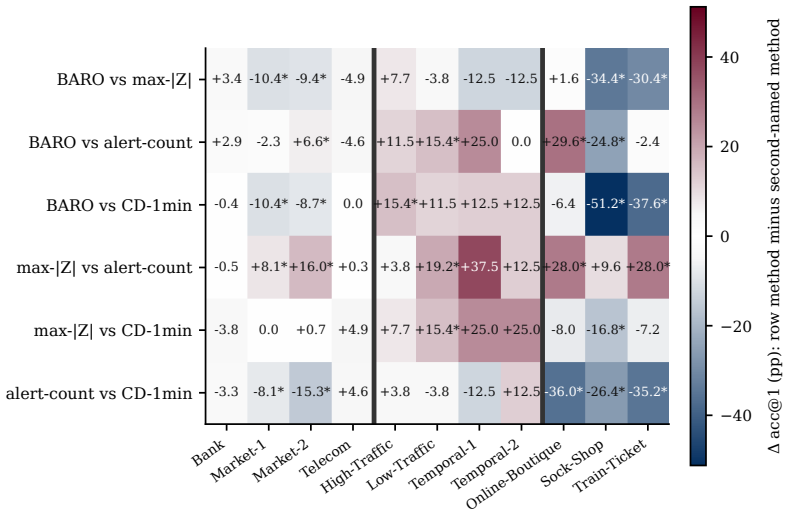
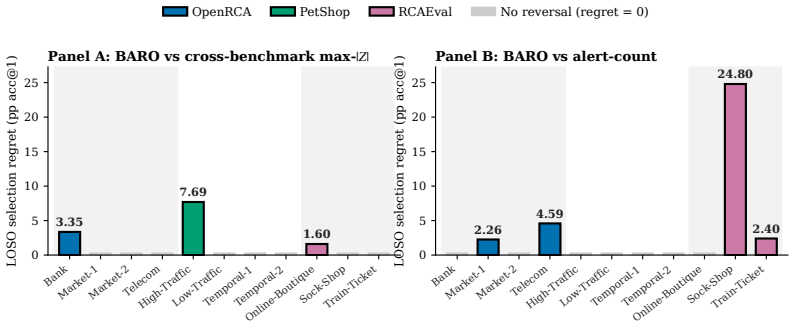
Pooled top-1 accuracy across subsystems does not identify a method that wins on any particular subsystem; all six pairwise comparisons exhibit subsystem-level effects of both signs, every random-effects 95% prediction interval crosses zero, interaction tests reject exchangeability in five of six pairs, and leave-one-system-out selection incurs regret up to 24.8 percentage points on held-out subsystems.
What carries the argument
Matched scoring units across subsystems, random-effects meta-analysis, case-level interaction tests for non-exchangeability, and leave-one-system-out validation to quantify selection regret.
If this is right
- Engineers cannot safely treat a pooled leaderboard winner as the method to deploy on their own subsystem.
- Per-subsystem stability checks are required before generalizing a ranking.
- Reporting protocols should include both pooled scores and the per-subsystem variation metrics shown here.
Where Pith is reading between the lines
- The same pooled-versus-specific mismatch is likely to appear in other benchmark domains that aggregate across heterogeneous test environments.
- Benchmarks could adopt the released 320-line audit module as a standard post-processing step to surface these effects automatically.
- The regret number offers a practical way to set a minimum acceptable stability threshold when choosing among methods.
Load-bearing premise
The four methods kept for full coverage represent the broader space of RCA techniques and the 778 matched units allow unbiased pairwise comparisons without differential missingness across subsystems.
What would settle it
A new RCA benchmark in which the method with the single highest pooled score also records the highest score on every individual subsystem would contradict the central claim.
Figures
read the original abstract
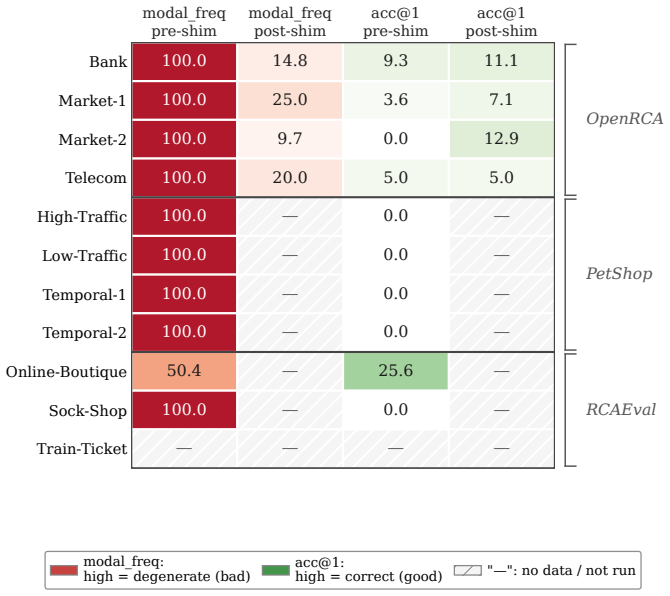
Offline root-cause-analysis (RCA) benchmarks commonly rank methods by a single pooled top-1 accuracy across multiple subsystems, and engineers often read the pooled winner as a recommendation for their own subsystem. We audit that reading on three public RCA benchmark families -- OpenRCA, RCAEval, and PetShop -- covering 11 subsystems and 778 matched scoring units. To keep pairwise comparisons on identical cases, the main analysis retains four methods or comparators with complete coverage: BARO, a CD-1min adapter, max-$|Z|$, and per-service alert-count. All six pairwise comparisons show subsystem-level effects of both signs, every random-effects 95\% prediction interval crosses zero, and case-level interaction tests reject exchangeability in 5 of 6 pairs. Leave-one-system-out selection picks the lower-scoring method on up to 5 of 11 held-out subsystems, with regret reaching 24.8 pp on RCAEval / Sock-Shop. We release a 320-line audit module; given a matched RCA benchmark score table, it recomputes the same per-subsystem stability checks alongside pooled scores.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript audits the common practice of ranking offline root-cause analysis (RCA) methods via a single pooled top-1 accuracy across multiple subsystems. On three public benchmark families (OpenRCA, RCAEval, PetShop) spanning 11 subsystems and 778 matched scoring units, the authors retain four methods with complete coverage (BARO, CD-1min adapter, max-|Z|, per-service alert-count) and show that all six pairwise comparisons exhibit subsystem-level effects of both signs, every random-effects 95% prediction interval crosses zero, case-level interaction tests reject exchangeability in 5 of 6 pairs, and leave-one-system-out selection picks the lower-scoring method on up to 5 of 11 held-out subsystems (regret up to 24.8 pp on RCAEval/Sock-Shop). A 320-line audit module is released to recompute the checks from any matched score table.
Significance. If the results hold, the work demonstrates a concrete reporting-protocol flaw in RCA benchmarks and supplies a reusable tool for per-subsystem stability checks. The matched-pair design and release of reproducible code are strengths that allow direct verification and extension to new benchmarks.
major comments (1)
- [Abstract / Methods] Abstract / Methods: The restriction to the four methods with complete coverage (BARO, CD-1min adapter, max-|Z|, per-service alert-count) for the main pairwise analysis is load-bearing for the claim that pooled leaderboards hide system-specific winners. If methods excluded for incomplete coverage exhibit systematically different subsystem-level heterogeneity or if missingness correlates with subsystem traits, the observed sign flips, prediction intervals crossing zero, and exchangeability rejections may not generalize beyond this filtered set. A sensitivity analysis or explicit discussion of selection effects is needed.
Simulated Author's Rebuttal
We thank the referee for the detailed comment on selection effects from restricting to methods with complete coverage. We address the point directly below and will revise the manuscript to incorporate an explicit discussion of this limitation.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract / Methods: The restriction to the four methods with complete coverage (BARO, CD-1min adapter, max-|Z|, per-service alert-count) for the main pairwise analysis is load-bearing for the claim that pooled leaderboards hide system-specific winners. If methods excluded for incomplete coverage exhibit systematically different subsystem-level heterogeneity or if missingness correlates with subsystem traits, the observed sign flips, prediction intervals crossing zero, and exchangeability rejections may not generalize beyond this filtered set. A sensitivity analysis or explicit discussion of selection effects is needed.
Authors: The restriction to the four methods with complete coverage is required to ensure all pairwise comparisons use identical scoring units, as stated in the Methods section; without it, missingness would confound the matched-pair design and the random-effects models. We agree that this choice is load-bearing for the reported sign flips, prediction intervals, and exchangeability tests, and that the findings may not automatically extend to methods with incomplete coverage. A full sensitivity analysis is not possible from the public benchmark releases because the excluded methods lack scores on the same cases. In the revised manuscript we will add an explicit subsection in the Discussion that (i) lists the coverage patterns of the excluded methods, (ii) notes that missingness could in principle correlate with subsystem traits, and (iii) states that the released audit module is intended precisely to allow such checks once more complete score tables become available. This addition will qualify the scope of the current results without altering the core claim for the comparable methods. revision: yes
Circularity Check
No circularity: empirical audit on public data with standard statistics
full rationale
The paper performs a direct empirical audit of public RCA benchmark score tables using standard statistical procedures (random-effects models, 95% prediction intervals, case-level interaction tests, and leave-one-system-out selection). No derivation chain, fitted parameters, or predictions are defined in terms of the target quantities; all reported effects and regrets are computed from the 778 matched scoring units. No self-citations are load-bearing for the central claims, and the released audit module simply recomputes the same checks. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Random-effects model assumptions hold for subsystem-level performance differences
- domain assumption The 778 matched scoring units permit unbiased pairwise comparisons
Reference graph
Works this paper leans on
-
[1]
Bender and Alexander Koller
Emily M. Bender and Alexander Koller. Climbing towards NLU : On meaning, form, and understanding in the age of data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pages 5185--5198. Association for Computational Linguistics, 2020
2020
-
[2]
Bowman and George E
Samuel R. Bowman and George E. Dahl. What will it take to fix benchmarking in natural language understanding? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pages 4843--4855. Association for Computational Linguistics, 2021
2021
-
[3]
AIOpsLab : A holistic framework to evaluate AI agents for enabling autonomous clouds
Yinfang Chen, Manish Shetty, Gagan Somashekar, Minghua Ma, Yogesh Simmhan, Jonathan Mace, Chetan Bansal, Rujia Wang, et al. AIOpsLab : A holistic framework to evaluate AI agents for enabling autonomous clouds. arXiv preprint arXiv:2501.06706, 2025
-
[4]
William G. Cochran. The combination of estimates from different experiments. Biometrics, 10 0 (1): 0 101--129, 1954
1954
-
[5]
Gritsenko, Zhe Zhao, Neil Houlsby, Fernando Diaz, Donald Metzler, and Oriol Vinyals
Mostafa Dehghani, Yi Tay, Alexey A. Gritsenko, Zhe Zhao, Neil Houlsby, Fernando Diaz, Donald Metzler, and Oriol Vinyals. The benchmark lottery. arXiv preprint arXiv:2107.07002, 2021
-
[6]
Meta-analysis in clinical trials
Rebecca DerSimonian and Nan Laird. Meta-analysis in clinical trials. Controlled Clinical Trials, 7 0 (3): 0 177--188, 1986
1986
-
[7]
Rethinking the evaluation of microservice RCA with a fault propagation-aware benchmark
Aoyang Fang, Songhan Zhang, Yifan Yang, Haotong Wu, Junjielong Xu, Xuyang Wang, Rui Wang, Manyi Wang, Qisheng Lu, and Pinjia He. Rethinking the evaluation of microservice RCA with a fault propagation-aware benchmark. In Proceedings of the 33rd ACM International Conference on the Foundations of Software Engineering (FSE), 2026
2026
-
[8]
Orchard, Patrick Bl \"o baum, Elke Kirschbaum, and Shiva Kasiviswanathan
Michaela Hardt, William R. Orchard, Patrick Bl \"o baum, Elke Kirschbaum, and Shiva Kasiviswanathan. The PetShop dataset --- finding causes of performance issues across microservices. In Proceedings of the Third Conference on Causal Learning and Reasoning, volume 236 of Proceedings of Machine Learning Research, pages 957--978. PMLR, 2024
2024
-
[9]
On tests of the overall treatment effect in meta-analysis with normally distributed responses
Joachim Hartung and Guido Knapp. On tests of the overall treatment effect in meta-analysis with normally distributed responses. Statistics in Medicine, 20 0 (12): 0 1771--1782, 2001
2001
-
[10]
Joanna IntHout, John P. A. Ioannidis, Maroeska M. Rovers, and Jelle J. Goeman. Plea for routinely presenting prediction intervals in meta-analysis. BMJ Open, 6 0 (7): 0 e010247, 2016
2016
-
[11]
ITBench : Evaluating AI agents across diverse real-world IT automation tasks
Saurabh Jha, Rohan Arora, Yuji Watanabe, Takumi Yanagawa, Yinfang Chen, Jackson Clark, Bhavya Bhavya, Mudit Verma, et al. ITBench : Evaluating AI agents across diverse real-world IT automation tasks. arXiv preprint arXiv:2502.05352, 2025
-
[12]
Taeyoon Kim, Woohyeok Park, Hoyeong Yun, and Kyungyong Lee. Why do AI agents systematically fail at cloud root cause analysis? arXiv preprint arXiv:2602.09937, 2026
-
[13]
Causal inference-based root cause analysis for online service systems with intervention recognition
Mingjie Li, Zeyan Li, Kanglin Yin, Xiaohui Nie, Wenchi Zhang, Kaixin Sui, and Dan Pei. Causal inference-based root cause analysis for online service systems with intervention recognition. In Aidong Zhang and Huzefa Rangwala, editors, KDD '22: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, August 14--18, 2022, p...
2022
-
[14]
Holistic evaluation of language models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, et al. Holistic evaluation of language models. Transactions on Machine Learning Research (TMLR), 2023
2023
-
[15]
Papke and Jeffrey M
Leslie E. Papke and Jeffrey M. Wooldridge. Econometric methods for fractional response variables with an application to 401(k) plan participation rates. Journal of Applied Econometrics, 11 0 (6): 0 619--632, 1996
1996
-
[16]
Paule and John Mandel
Robert C. Paule and John Mandel. Consensus values and weighting factors. Journal of Research of the National Bureau of Standards, 87 0 (5): 0 377--385, 1982
1982
-
[17]
BARO : Robust root cause analysis for microservices via multivariate Bayesian online change point detection
Luan Pham, Huong Ha, and Hongyu Zhang. BARO : Robust root cause analysis for microservices via multivariate Bayesian online change point detection. Proceedings of the ACM on Software Engineering, 1 0 (FSE): 0 2214--2237, 2024 a
2024
-
[18]
Luan Pham, Huong Ha, and Hongyu Zhang. Root cause analysis for microservice system based on causal inference: How far are we? In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 706--715. ACM, 2024 b
2024
-
[19]
RCAEval : A benchmark for root cause analysis of microservice systems with telemetry data
Luan Pham, Hongyu Zhang, Huong Ha, Flora Salim, and Xiuzhen Zhang. RCAEval : A benchmark for root cause analysis of microservice systems with telemetry data. In Companion Proceedings of the ACM on Web Conference 2025 (WWW Companion), pages 777--780. ACM, 2025
2025
-
[20]
Beyond accuracy: Behavioral testing of NLP models with CheckList
Marco T \'u lio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. Beyond accuracy: Behavioral testing of NLP models with CheckList . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pages 4902--4912. Association for Computational Linguistics, 2020
2020
-
[21]
Stalled, biased, and confused: Uncovering reasoning failures in LLMs for cloud-based root cause analysis
Evelien Riddell, James Riddell, Gengyi Sun, Micha Antkiewicz, and Krzysztof Czarnecki. Stalled, biased, and confused: Uncovering reasoning failures in LLMs for cloud-based root cause analysis. In Proceedings of the 2026 IEEE/ACM Third International Conference on AI Foundation Models and Software Engineering (FORGE). ACM, 2026
2026
-
[22]
Kurex Sidik and Jeffrey N. Jonkman. Simple heterogeneity variance estimation for meta-analysis. Journal of the Royal Statistical Society: Series C (Applied Statistics), 54 0 (2): 0 367--384, 2005
2005
-
[23]
Kurex Sidik and Jeffrey N. Jonkman. Robust variance estimation for random effects meta-analysis. Computational Statistics & Data Analysis, 50 0 (12): 0 3681--3701, 2006
2006
-
[24]
Beyond the imitation game: Quantifying and extrapolating the capabilities of language models
Aarohi Srivastava et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (TMLR), 2023
2023
-
[25]
Conducting meta-analyses in R with the metafor package
Wolfgang Viechtbauer. Conducting meta-analyses in R with the metafor package. Journal of Statistical Software, 36 0 (3): 0 1--48, 2010
2010
- [26]
-
[27]
OpenRCA : Can large language models locate the root cause of software failures? In Proceedings of the 13th International Conference on Learning Representations (ICLR), 2025
Junjielong Xu, Qinan Zhang, Zhiqing Zhong, Shilin He, Chaoyun Zhang, Qingwei Lin, Dan Pei, Pinjia He, Dongmei Zhang, and Qi Zhang. OpenRCA : Can large language models locate the root cause of software failures? In Proceedings of the 13th International Conference on Learning Representations (ICLR), 2025
2025
-
[28]
Lemma-rca: A large multi-modal multi-domain dataset for root cause analysis,
Lecheng Zheng, Zhengzhang Chen, Dongjie Wang, Chengyuan Deng, Reon Matsuoka, and Haifeng Chen. LEMMA-RCA : A large multi-modal multi-domain dataset for root cause analysis. arXiv preprint arXiv:2406.05375, 2024
-
[29]
Latent error prediction and fault localization for microservice applications by learning from system trace logs
Xiang Zhou, Xin Peng, Tao Xie, Jun Sun, Chao Ji, Dewei Liu, Qilin Xiang, and Chuan He. Latent error prediction and fault localization for microservice applications by learning from system trace logs. In Proceedings of the 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE),...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.