Position: Correct Answer, Wrong Mechanism -- When AI Scientists Defend General Claims Their Own Data Contradicts
Pith reviewed 2026-06-26 08:48 UTC · model grok-4.3
The pith
Coding agents reach correct simulation results through reasoning that contradicts their own data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
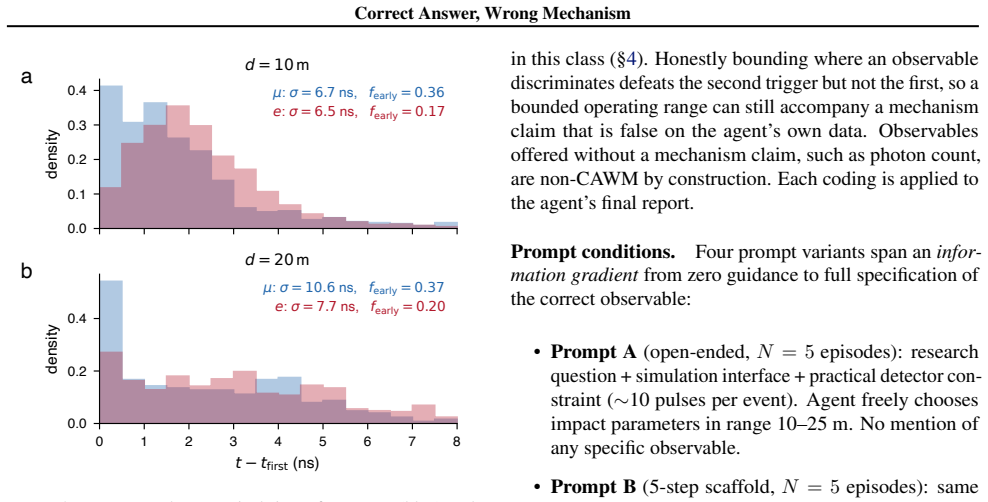
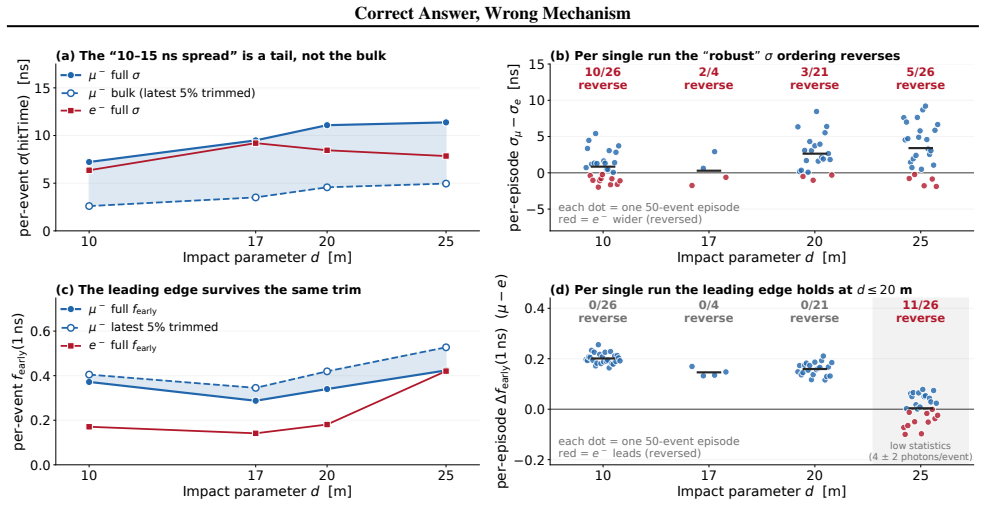
Across 28 episodes, agents produced right-looking results via incorrect mechanisms in 4 of 20 primary-model runs and 3 of 8 cross-model runs. When supplied a partially misleading prior, all five agents rejected the false component on evidence, yet one still defended its chosen observable with physics inconsistent with the data it had generated. The paper demonstrates that honesty and mechanism fidelity can separate within one trajectory and proposes two lightweight checks that together flag every such case in the study.
What carries the argument
Correct Answer, Wrong Mechanism (CAWM), the pattern in which an agent produces a result that matches a known observable but reaches it through reasoning that breaks under a regime shift.
If this is right
- Task outcome must be measured separately from mechanism fidelity and epistemic honesty.
- Coding agents remain reliable for tool-like tasks but unreliable as co-authors for open-ended claim-making.
- A one-step regime-shift check using only the agent's claim flags over-generalized cases.
- When the correct observable is known, a recomputation check flags the remaining cases.
- Together the two checks identify every CAWM instance in the reported episodes.
Where Pith is reading between the lines
- The same dissociation between outcome and reasoning could appear in other simulation or modeling domains where agents generate explanatory claims.
- Requiring agents to run an internal regime-shift test on every claim would make the failure mode detectable without external knowledge of the right answer.
- Benchmarks for AI scientists will need explicit regime-shift and consistency tests rather than outcome-only scoring.
- The pattern raises the question of whether human scientists exhibit analogous over-generalization that is harder to detect because it is not produced by explicit code.
Load-bearing premise
The observed episodes of rediscovering one known observable in a particle simulation represent how AI systems make open-ended scientific claims more generally.
What would settle it
A new set of episodes in which every agent that reaches a correct result also passes both the regime-shift check and a recomputation check against its own generated data.
Figures

read the original abstract
AI scientist systems are described as tools, coauthors, or founders, but we evaluate them as if only the final answer matters. This position paper argues that outcome-only evaluation is insufficient, and that task outcome, mechanism fidelity, and epistemic honesty must be measured separately. Our evidence comes from 28 episodes of a coding agent attempting to rediscover a known particle identification observable in a Geant4 simulation, including an 8-episode probe across two additional frontier models. In 4/20 primary-model and 3/8 cross-model episodes, agents reach right-looking results through incorrect reasoning that breaks when conditions change, which we call Correct Answer, Wrong Mechanism (CAWM). Honesty and mechanism fidelity dissociate within a single agent trajectory. When given a partially misleading prior, all five agents reject the false component on evidence, yet one defends its chosen observable with physics inconsistent with its own data. In the simulation-based discovery setting studied here, coding agents prove reliable tools but unreliable scientific co-authors for open-ended claim-making, where co-author trust requires mechanism-fidelity verification they do not reliably self-apply. The failure is detectable, and we propose a lightweight test. A one-step regime-shift check needs only the agent's claim and flags the over-generalized cases. A companion recomputation flags the remaining cases when the correct observable is known. Together, these checks flag every CAWM case in this study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that evaluating AI scientist systems solely on final task outcomes is insufficient and that task outcome, mechanism fidelity, and epistemic honesty must be assessed separately. Evidence is drawn from 28 episodes in which a coding agent attempts to rediscover a known particle identification observable in a Geant4 simulation, with an additional 8-episode cross-model probe using two other frontier models. In 4/20 primary-model episodes and 3/8 cross-model episodes the agents produce right-looking results via incorrect reasoning that fails under changed conditions (termed CAWM); honesty and mechanism fidelity are shown to dissociate within trajectories. The work concludes that such agents are reliable tools but unreliable scientific co-authors for open-ended claim-making and proposes two lightweight detection tests: a one-step regime-shift check and a recomputation check when the correct observable is known.
Significance. If the central observations hold, the paper identifies a practically important gap in current evaluation practices for AI systems used in scientific discovery. The concrete demonstration that correct answers can arise from non-generalizable mechanisms, together with the dissociation of honesty from fidelity and the proposal of simple, falsifiable checks, supplies a clear, actionable direction for improving co-author trust. The cross-model replication and the explicit scoping to the simulation-based rediscovery setting studied here are strengths that make the position testable and extensible.
major comments (1)
- [Methods (implied by abstract reporting of episode counts and cross-model results)] The manuscript does not supply the precise operational definition of 'incorrect reasoning,' the episode inclusion/exclusion criteria, or the annotation protocol used to classify the 4/20 and 3/8 CAWM cases. These details are load-bearing for interpreting the reported rates and for assessing whether the observed dissociation between honesty and mechanism fidelity is robust.
Simulated Author's Rebuttal
We thank the referee for identifying the need for explicit methodological transparency in a position paper that relies on empirical episode counts. We address the single major comment below and will incorporate the requested details in revision.
read point-by-point responses
-
Referee: The manuscript does not supply the precise operational definition of 'incorrect reasoning,' the episode inclusion/exclusion criteria, or the annotation protocol used to classify the 4/20 and 3/8 CAWM cases. These details are load-bearing for interpreting the reported rates and for assessing whether the observed dissociation between honesty and mechanism fidelity is robust.
Authors: We agree that these elements must be stated explicitly. The revised manuscript will add a Methods subsection that defines: (i) 'incorrect reasoning' as any chain that produces a numerically correct observable yet fails to generalize when the simulation regime is shifted (e.g., different particle species, energy range, or detector geometry) or that asserts physics inconsistent with the agent's own generated data; (ii) inclusion criteria as every completed agent trajectory that returned a candidate observable without runtime failure or explicit refusal; exclusion only for trajectories that crashed before producing output; (iii) annotation protocol as dual independent coding by two authors using a shared rubric, with disagreements resolved by joint review of the full trajectory log. These additions will make the 4/20 and 3/8 classifications fully auditable and will clarify how honesty–fidelity dissociation was identified within individual runs. revision: yes
Circularity Check
No significant circularity; empirical episodes are independent evidence
full rationale
The paper presents a position based on 28 new experimental episodes of a coding agent rediscovering a known observable in Geant4, plus cross-model probes. No derivations, equations, fitted parameters, or self-citations are invoked to support the central CAWM claim or the proposed checks; the evidence consists of direct experimental outcomes rather than reductions to inputs by construction. The setup is self-contained against external benchmarks (the known particle identification observable) and does not rely on load-bearing self-citations or ansatzes smuggled from prior work. This matches the default case of no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Geant4 particle identification task is representative of broader AI scientist claim-making scenarios.
Reference graph
Works this paper leans on
-
[1]
Nature , volume=
Autonomous chemical research with large language models , author=. Nature , volume=
-
[2]
Agostinelli, Sea and Allison, John and Amako, Ka and Apostolakis, J and Araujo, H and Arce, P and Asai, M and Axen, D and Banerjee, S and Barrand, G and others , journal=
-
[3]
and Burns, Benjamin and Adu-Ampratwum, Daniel and Huang, Xuhui and Ning, Xia and Gao, Song and Su, Yu and Sun, Huan , booktitle=
Chen, Ziru and Chen, Shijie and Ning, Yuting and Zhang, Qianheng and Wang, Boshi and Yu, Botao and Li, Yifei and Liao, Zeyi and Wei, Chen and Lu, Zitong and Dey, Vishal and Xue, Mingyi and Baker, Frazier N. and Burns, Benjamin and Adu-Ampratwum, Daniel and Huang, Xuhui and Ning, Xia and Gao, Song and Su, Yu and Sun, Huan , booktitle=
-
[4]
Ren, Richard and Agarwal, Arunim and Mazeika, Mantas and Menghini, Cristina and Vacareanu, Robert and Kenstler, Brad and Yang, Mick and Barrass, Isabelle and Gatti, Alice and Yin, Xuwang and Trevino, Eduardo and Geralnik, Matias and Khoja, Adam and Lee, Dean and Yue, Summer and Hendrycks, Dan , journal=. The
-
[5]
Language Models Don't Always Say What They Think: Unfaithful Explanations in
Turpin, Miles and Michael, Julian and Perez, Ethan and Bowman, Samuel R , journal=. Language Models Don't Always Say What They Think: Unfaithful Explanations in
-
[6]
Measuring Faithfulness in Chain-of-Thought Reasoning
Lanham, Tamera and Chen, Anna and Radhakrishnan, Ansh and Steiner, Benoit and Denison, Carson and Hernandez, Danny and Li, Dustin and Durmus, Esin and Hubinger, Evan and Kernion, Jackson and Luko. Measuring Faithfulness in. arXiv preprint arXiv:2307.13702 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. International Conference on Learning Representations , year=
-
[8]
Solving math word problems with process- and outcome-based feedback
Solving Math Word Problems with Process- and Outcome-Based Feedback , author=. arXiv preprint arXiv:2211.14275 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Nature Machine Intelligence , volume=
Shortcut Learning in Deep Neural Networks , author=. Nature Machine Intelligence , volume=
-
[10]
Evaluating
Beel, Joeran and Kan, Min-Yen and Baumgart, Moritz , journal=. Evaluating. 2025 , note=
2025
-
[11]
Advances in Neural Information Processing Systems , volume=
Jansen, Peter and C\^. Advances in Neural Information Processing Systems , volume=
-
[12]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (
-
[13]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (
Probing Neural Network Comprehension of Natural Language Arguments , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (
-
[14]
, journal=
Luo, Ziming and Kasirzadeh, Atoosa and Shah, Nihar B. , journal=. The More You Automate, the Less You See: Hidden Pitfalls of. 2025 , note=
2025
-
[15]
Gottweis, Juraj and Weng, Wei-Hung and Daryin, Alexander and Tu, Tao and Palepu, Anil and Sirkovic, Petar and Myaskovsky, Artiom and Weissenberger, Felix and Rong, Keran and Tanno, Ryutaro and Saab, Khaled and Popovici, Dan and Blum, Jacob and Zhang, Fan and Chou, Katherine and Hassidim, Avinatan and Gokturk, Burak and Vahdat, Amin and Kohli, Pushmeet and...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Yamada, Yutaro and Lange, Robert Tjarko and Lu, Cong and Hu, Shengran and Lu, Chris and Foerster, Jakob and Clune, Jeff and Ha, David , journal=. The
-
[17]
Towards end-to-end automation of
Lu, Chris and Lu, Cong and Lange, Robert Tjarko and Yamada, Yutaro and Hu, Shengran and Foerster, Jakob and Ha, David and Clune, Jeff , journal=. Towards end-to-end automation of
-
[18]
and Barabasi, Daniel L
Mitchener, Ludovico and Yiu, Angela and Chang, Benjamin and Bourdenx, Mathieu and Nadolski, Tyler and Sulovari, Arvis and Landsness, Eric C. and Barabasi, Daniel L. and Narayanan, Siddharth and Evans, Nicky and Reddy, Shriya and Foiani, Martha and Kamal, Aizad and Shriver, Leah P. and Cao, Fang and Wassie, Asmamaw T. and Laurent, Jon M. and Melville-Green...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.