Dango: A Strictly L1-Only Large Language Model for Studying Second Language Acquisition
Pith reviewed 2026-06-26 21:09 UTC · model grok-4.3
The pith
A 1.8B model pretrained only on filtered Japanese data acquires human-like English production after targeted lessons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
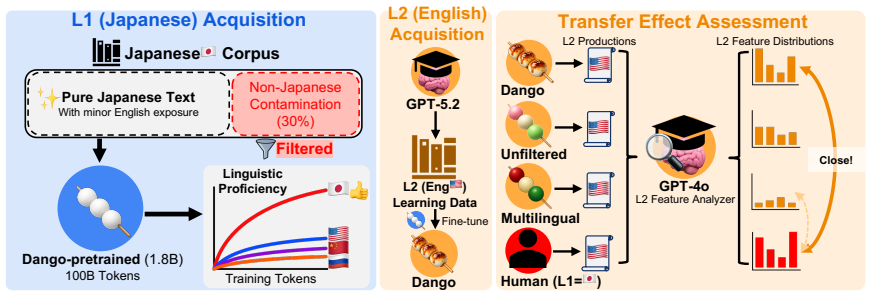
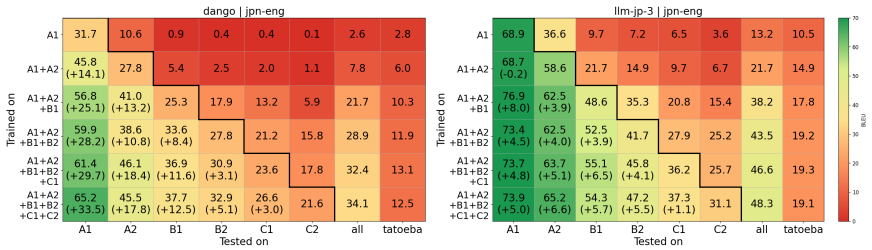
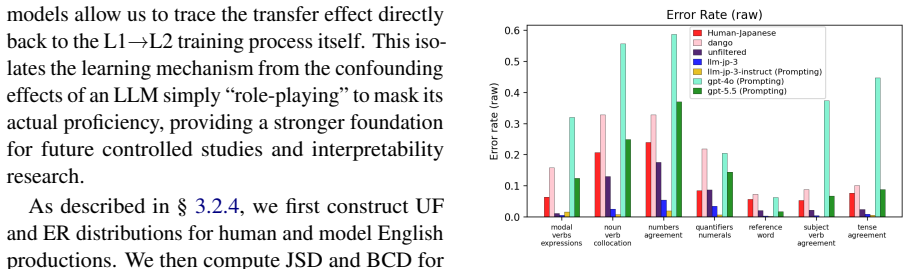
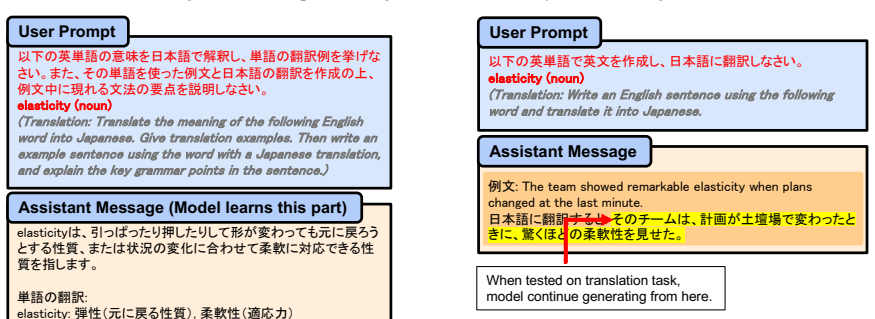
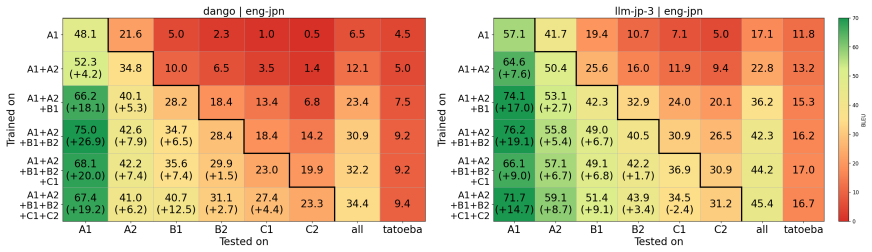
Dango is created by filtering a Japanese corpus to limit premature English exposure, pretraining the 1.8B decoder on the cleaned data, and then fine-tuning on generated L2 lessons; the resulting model exhibits human-like L2 production patterns that outperform unfiltered and standard multilingual baselines.
What carries the argument
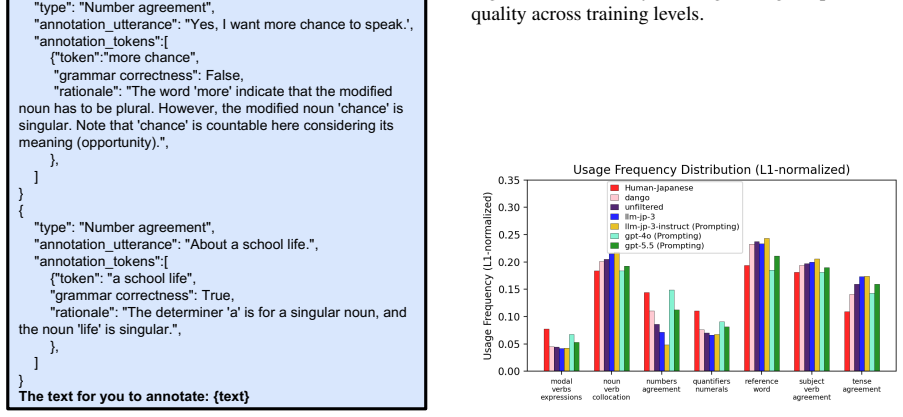
The filtering method that reduces L2 contamination in the monolingual pretraining corpus while preserving realistic minimal exposure.
If this is right
- Dango supplies a controllable simulator for testing specific L1-to-L2 transfer predictions at decoder scale.
- The same filtering-plus-lesson pipeline can be applied to other language pairs to isolate exposure effects.
- Releasing the model, data, and code enables direct replication of SLA experiments that were previously limited to smaller models.
- Human-like error patterns in the fine-tuned model can be compared against learner corpora to validate computational SLA claims.
Where Pith is reading between the lines
- If the filtering step proves robust, similar cleaning could improve other multilingual models that currently suffer from unintended cross-lingual leakage.
- The approach opens the possibility of running ablation studies that vary only the amount of minimal L2 exposure while holding model size fixed.
- Learner-facing tools could eventually be built by swapping the lesson generator for real classroom materials and measuring alignment with actual student output.
Load-bearing premise
The filtering method successfully reduces premature L2 exposure in the monolingual pretraining corpus while still preserving realistic minimal exposure.
What would settle it
A direct measurement of English token probability or translation accuracy on the filtered model before any L2 fine-tuning that shows no reduction compared with the unfiltered baseline.
Figures














read the original abstract
We introduce Dango, a 1.8B-parameter large language model designed for controlled studies of L1-to-L2 (Japanese-to-English) transfer in second language acquisition (SLA). While previous studies have explored SLA in language models, they have predominantly relied on smaller or non-decoder models, limiting their ability to generate open-ended text and reducing their suitability as practical L2 simulators. We identify a key challenge when scaling models to this size: L2 contamination within the "monolingual" pretraining corpus used for L1 acquisition. To address this, we propose a filtering method to reduce premature exposure to English while preserving realistic, minimal exposure. We then fine-tune the model on LLM-generated L2-learning lessons to simulate the L2 acquisition process. Our evaluations confirm that Dango develops human-like L2 production patterns, outperforming both unfiltered and standard multilingual baselines. We release the model, data, and code to facilitate reproducible computational SLA research and learner-facing applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dango, a 1.8B-parameter decoder-only LLM for controlled studies of Japanese-to-English second language acquisition. It identifies L2 contamination in monolingual pretraining corpora as a scaling challenge, proposes a filtering method to enforce realistic minimal English exposure during L1 pretraining, and then fine-tunes the model on LLM-generated L2 lessons. The central claim is that evaluations demonstrate human-like L2 production patterns, with Dango outperforming both unfiltered and standard multilingual baselines; the model, data, and code are released for reproducibility.
Significance. If the filtering successfully produces an L1-dominant corpus and the performance claims are substantiated with detailed metrics, this work would supply a scalable, open decoder-only model for computational SLA research, enabling controlled transfer experiments that smaller or non-decoder models cannot support. The explicit release of model, data, and code is a concrete strength that directly aids reproducibility and downstream learner-facing applications.
major comments (2)
- [Abstract] Abstract and evaluation sections: the claim that 'evaluations confirm that Dango develops human-like L2 production patterns, outperforming both unfiltered and standard multilingual baselines' is asserted without any reported metrics, test sets, baselines, statistical tests, or human-judgment protocols, rendering the central empirical result unverifiable from the provided description.
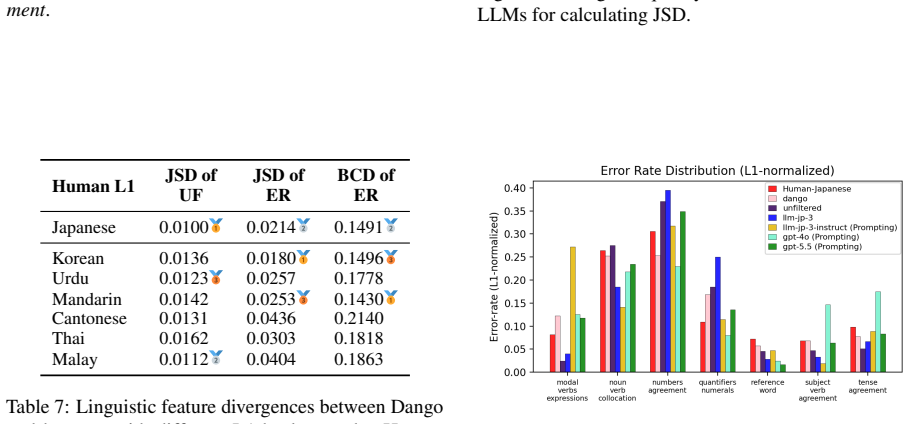
- [Methods (filtering procedure)] Methods section on corpus filtering: the proposed filtering procedure is described as the sole mechanism for reducing premature L2 exposure while preserving 'realistic, minimal exposure,' yet no quantitative validation (residual English n-gram rates, ablation on filter aggressiveness, or comparison against actual Japanese child-directed corpora) is supplied; this leaves the load-bearing precondition for attributing later L2 transfer to controlled SLA unanchored.
minor comments (1)
- [Introduction] Notation for the 1.8B model size and the distinction between 'unfiltered' and 'standard multilingual' baselines should be defined explicitly on first use to avoid ambiguity for readers outside the immediate SLA subfield.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments. We address each major comment below and plan to incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation sections: the claim that 'evaluations confirm that Dango develops human-like L2 production patterns, outperforming both unfiltered and standard multilingual baselines' is asserted without any reported metrics, test sets, baselines, statistical tests, or human-judgment protocols, rendering the central empirical result unverifiable from the provided description.
Authors: We agree with the referee that the abstract and evaluation sections should provide the supporting metrics, test sets, baselines, statistical tests, and human-judgment protocols to substantiate the central claim. We will revise the manuscript to include these details, ensuring the empirical results are fully verifiable. revision: yes
-
Referee: [Methods (filtering procedure)] Methods section on corpus filtering: the proposed filtering procedure is described as the sole mechanism for reducing premature L2 exposure while preserving 'realistic, minimal exposure,' yet no quantitative validation (residual English n-gram rates, ablation on filter aggressiveness, or comparison against actual Japanese child-directed corpora) is supplied; this leaves the load-bearing precondition for attributing later L2 transfer to controlled SLA unanchored.
Authors: We agree that quantitative validation is essential for the filtering procedure. We will supplement the methods section with residual English n-gram rates, ablations on filter aggressiveness, and comparisons against actual Japanese child-directed corpora. revision: yes
Circularity Check
No circularity; sequential training and evaluation steps remain independent
full rationale
The paper describes a linear pipeline: propose and apply an L2 filter to a Japanese corpus, pretrain the 1.8B model, fine-tune on generated L2 lessons, then run separate evaluations against unfiltered and multilingual baselines. No equations, fitted parameters renamed as predictions, or self-citations are invoked to derive the human-like L2 patterns; the outcome is presented as an empirical result of the procedure rather than a definitional or load-bearing reduction to the filter itself. The filtering step is an assumption whose effectiveness is not independently verified in the provided text, but that is a question of evidence strength, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Thirtieth Annual Meeting of the Association for Natural Language Processing (NLP2024) , year =
Uzushio: A Distributed Huge Corpus Processor for the LLM Era , author =. Proceedings of the Thirtieth Annual Meeting of the Association for Natural Language Processing (NLP2024) , year =
-
[2]
Proceedings of the Thirtieth Annual Meeting of the Association for Natural Language Processing (NLP2024) , year =
Han, Namgi and. Proceedings of the Thirtieth Annual Meeting of the Association for Natural Language Processing (NLP2024) , year =
-
[3]
2024 , eprint=
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs , author=. 2024 , eprint=
2024
-
[4]
Can LLM s Simulate L 2- E nglish Dialogue? An Information-Theoretic Analysis of L 1-Dependent Biases
Gao, Rena and Wu, Xuetong and Kuribayashi, Tatsuki and Ye, Mingrui and Qi, Siya and Roever, Carsten and Liu, Yuanxing and Yuan, Zheng and Lau, Jey Han. Can LLM s Simulate L 2- E nglish Dialogue? An Information-Theoretic Analysis of L 1-Dependent Biases. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long...
-
[5]
Second Language Acquisition of Neural Language Models
Oba, Miyu and Kuribayashi, Tatsuki and Ouchi, Hiroki and Watanabe, Taro. Second Language Acquisition of Neural Language Models. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.856
-
[6]
Modeling Nonnative Sentence Processing with L 2 Language Models
Aoyama, Tatsuya and Schneider, Nathan. Modeling Nonnative Sentence Processing with L 2 Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.283
-
[7]
BL i MP : The Benchmark of Linguistic Minimal Pairs for E nglish
Warstadt, Alex and Parrish, Alicia and Liu, Haokun and Mohananey, Anhad and Peng, Wei and Wang, Sheng-Fu and Bowman, Samuel R. BL i MP : The Benchmark of Linguistic Minimal Pairs for E nglish. Transactions of the Association for Computational Linguistics. 2020. doi:10.1162/tacl_a_00321
-
[8]
2025 , eprint=
MultiBLiMP 1.0: A Massively Multilingual Benchmark of Linguistic Minimal Pairs , author=. 2025 , eprint=
2025
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-26) , year =
HSKBenchmark: Modeling and Benchmarking Chinese Second Language Acquisition in Large Language Models through Curriculum Tuning , author =. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-26) , year =. 2511.15574 , archivePrefix =
-
[10]
SLABERT Talk Pretty One Day: Modeling Second Language Acquisition with BERT
Yadavalli, Aditya and Yadavalli, Alekhya and Tobin, Vera. SLABERT Talk Pretty One Day: Modeling Second Language Acquisition with BERT. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.657
-
[11]
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ...
-
[12]
JBL i MP : J apanese Benchmark of Linguistic Minimal Pairs
Someya, Taiga and Oseki, Yohei. JBL i MP : J apanese Benchmark of Linguistic Minimal Pairs. Findings of the Association for Computational Linguistics: EACL 2023. 2023. doi:10.18653/v1/2023.findings-eacl.117
-
[13]
Second Language Acquisition Modeling
Settles, Burr and Brust, Chris and Gustafson, Erin and Hagiwara, Masato and Madnani, Nitin. Second Language Acquisition Modeling. Proceedings of the Thirteenth Workshop on Innovative Use of NLP for Building Educational Applications. 2018. doi:10.18653/v1/W18-0506
-
[14]
CALL for Widening Participation: Short Papers from EUROCALL 2020 , editor =
The Development of an Online Game-based Simulation for the Training of English Language Teachers in Virtual Environments , author =. CALL for Widening Participation: Short Papers from EUROCALL 2020 , editor =. 2020 , month = dec, pages =. doi:10.14705/rpnet.2020.48.1210 , url =
-
[15]
Effectiveness of Chatbots in Improving Language Learning: A Meta‐Analysis of Comparative Studies , doi =
Lyu, Boning and Lai, Chun and Guo, Jianing , month =. Effectiveness of Chatbots in Improving Language Learning: A Meta‐Analysis of Comparative Studies , doi =. 2024 , journal =
2024
-
[16]
Japanese English: Language and Culture Contact , urldate =
James Stanlaw , publisher =. Japanese English: Language and Culture Contact , urldate =
-
[17]
The ICNALE Spoken Dialogue: A New Dataset for the Study of Asian Learners’ Performance in L2 English Interviews , doi =
Ishikawa, Shin’ichiro , month =. The ICNALE Spoken Dialogue: A New Dataset for the Study of Asian Learners’ Performance in L2 English Interviews , doi =. 2019 , journal =
2019
-
[18]
2022 , eprint=
Training Compute-Optimal Large Language Models , author=. 2022 , eprint=
2022
-
[19]
言語処理学会 第30回年次大会 発表論文集 , pages =
ichikara-instruction: LLM のための日本語インストラクションデータの作成 , author =. 言語処理学会 第30回年次大会 発表論文集 , pages =. 2024 , url =
2024
-
[20]
2020 , eprint=
Language Models are Few-Shot Learners , author=. 2020 , eprint=
2020
-
[21]
Council of Europe , title =
-
[22]
Common European Framework of Reference for Languages: Learning, Teaching, Assessment , year =
-
[23]
Tono, Yukio , title =
-
[24]
Tono, Yukio , title =. CEFR Journal---Research and Practice , year =. doi:10.37546/JALTSIG.CEFR1-1 , url =
-
[25]
Lai, Viet Dac and Ngo, Nghia and Pouran Ben Veyseh, Amir and Man, Hieu and Dernoncourt, Franck and Bui, Trung and Nguyen, Thien Huu. C hat GPT Beyond E nglish: Towards a Comprehensive Evaluation of Large Language Models in Multilingual Learning. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.878
-
[26]
1957 , publisher =
Robert Lado , title =. 1957 , publisher =
1957
-
[27]
1989 , publisher =
Terence Odlin , title =. 1989 , publisher =
1989
-
[28]
2023 , eprint=
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model , author=. 2023 , eprint=
2023
-
[29]
2023 , eprint=
YAYI 2: Multilingual Open-Source Large Language Models , author=. 2023 , eprint=
2023
-
[30]
Constantinescu, Ionut and Pimentel, Tiago and Cotterell, Ryan and Warstadt, Alex. Investigating Critical Period Effects in Language Acquisition through Neural Language Models. Transactions of the Association for Computational Linguistics. 2025. doi:10.1162/tacl_a_00725
-
[31]
Issues in the Assessment and Evaluation of English Language Education at the Elementary School Level: Implications for Policies in South Korea, Taiwan, and Japan , volume =
Butler, Yuko , year =. Issues in the Assessment and Evaluation of English Language Education at the Elementary School Level: Implications for Policies in South Korea, Taiwan, and Japan , volume =
-
[32]
Japan's emblematic English , doi =
Hyde, Barbara , month =. Japan's emblematic English , doi =. 2002 , journal =
2002
-
[33]
Learning from the Linguistic Landscape: A Project-Based Learning Approach to Investigating English in Japan , doi =
Barrs, Keith , month =. Learning from the Linguistic Landscape: A Project-Based Learning Approach to Investigating English in Japan , doi =. 2020 , journal =
2020
-
[34]
JALT2021 Postconference Publication: Reflections and New Perspectives , editor =
Nakayama, Shusaku , title =. JALT2021 Postconference Publication: Reflections and New Perspectives , editor =. 2022 , publisher =. doi:10.37546/JALTPCP2021-24 , url =
-
[35]
CCN et: Extracting High Quality Monolingual Datasets from Web Crawl Data
Wenzek, Guillaume and Lachaux, Marie-Anne and Conneau, Alexis and Chaudhary, Vishrav and Guzm \'a n, Francisco and Joulin, Armand and Grave, Edouard. CCN et: Extracting High Quality Monolingual Datasets from Web Crawl Data. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[36]
Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus
Caswell, Isaac and Breiner, Theresa and van Esch, Daan and Bapna, Ankur. Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.579
-
[37]
Language Contamination Helps Explains the Cross-lingual Capabilities of E nglish Pretrained Models
Blevins, Terra and Zettlemoyer, Luke. Language Contamination Helps Explains the Cross-lingual Capabilities of E nglish Pretrained Models. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.233
-
[38]
L1 INFLUENCE ON THE ACQUISITION ORDER OF ENGLISH GRAMMATICAL MORPHEMES , doi =
Murakami, Akira and Alexopoulou, Theodora , month =. L1 INFLUENCE ON THE ACQUISITION ORDER OF ENGLISH GRAMMATICAL MORPHEMES , doi =. 2015 , journal =
2015
-
[39]
and Miller, Paul W
Chiswick, Barry R. and Miller, Paul W. , month =. Linguistic Distance: A Quantitative Measure of the Distance Between English and Other Languages , doi =. 2005 , journal =
2005
-
[40]
The ICNALE and Sophisticated Contrastive Interlanguage Analysis of Asian Learners of English , doi =
Ishikawa, Shin'ichiro , month =. The ICNALE and Sophisticated Contrastive Interlanguage Analysis of Asian Learners of English , doi =. 2013 , journal =
2013
-
[41]
Ishikawa, Shin'ichiro , title =. 2023 , publisher =. doi:10.4324/9781003252528 , isbn =
-
[42]
2025 , eprint=
A Systematic Assessment of Language Models with Linguistic Minimal Pairs in Chinese , author=. 2025 , eprint=
2025
-
[43]
Jarvis, Scott and Pavlenko, Aneta , title =
-
[44]
1983 , isbn =
Strategies in Interlanguage Communication , publisher =. 1983 , isbn =
1983
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.