Disease-Centric Vision-Language Pretraining with Hybrid Visual Encoding for 3D Computed Tomography
Pith reviewed 2026-06-25 21:22 UTC · model grok-4.3
The pith
A disease-centric VLP framework with hybrid encoding and query tokens reaches new SOTA zero-shot diagnosis on 3D CT.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
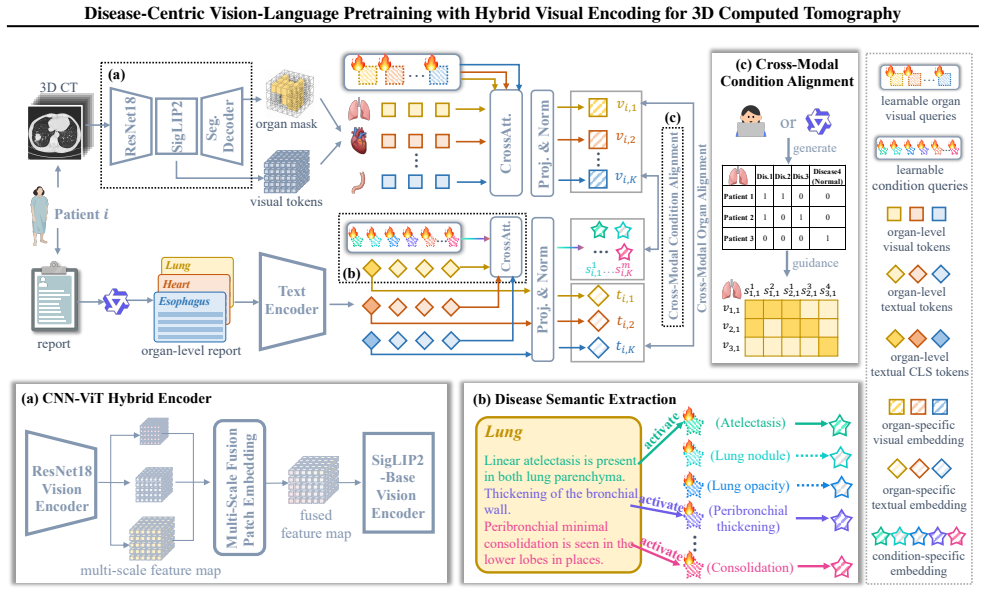
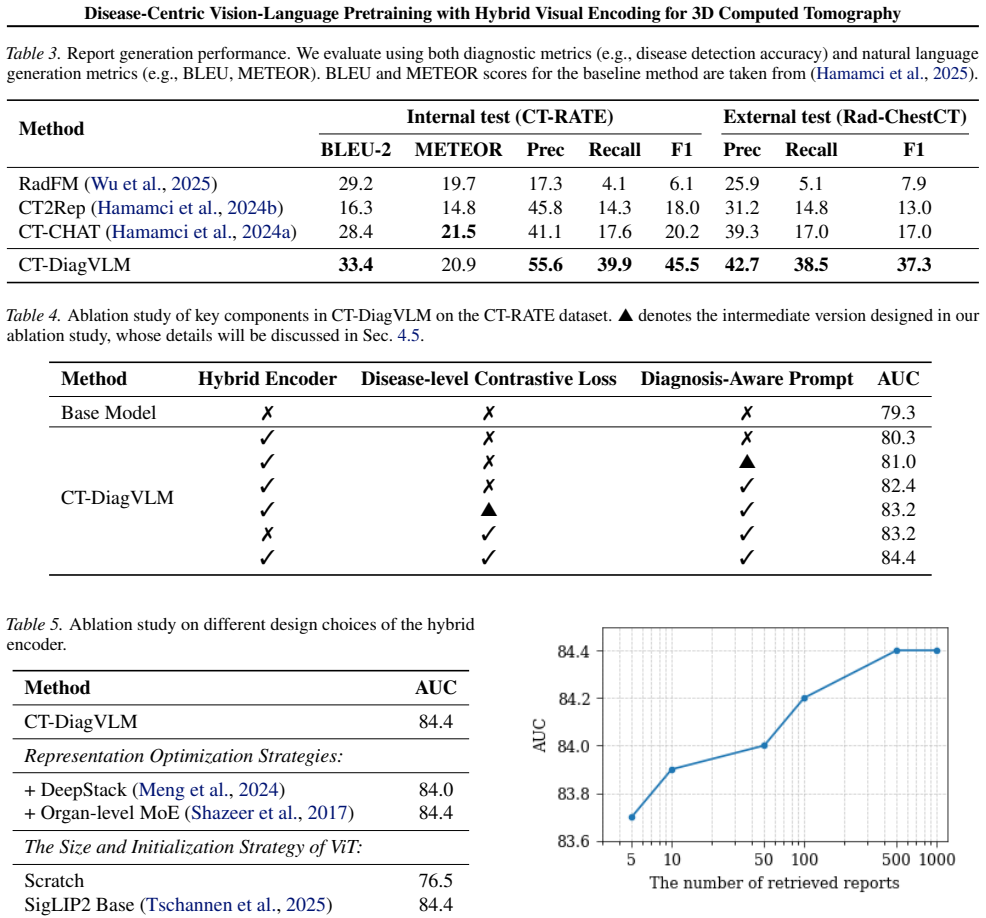
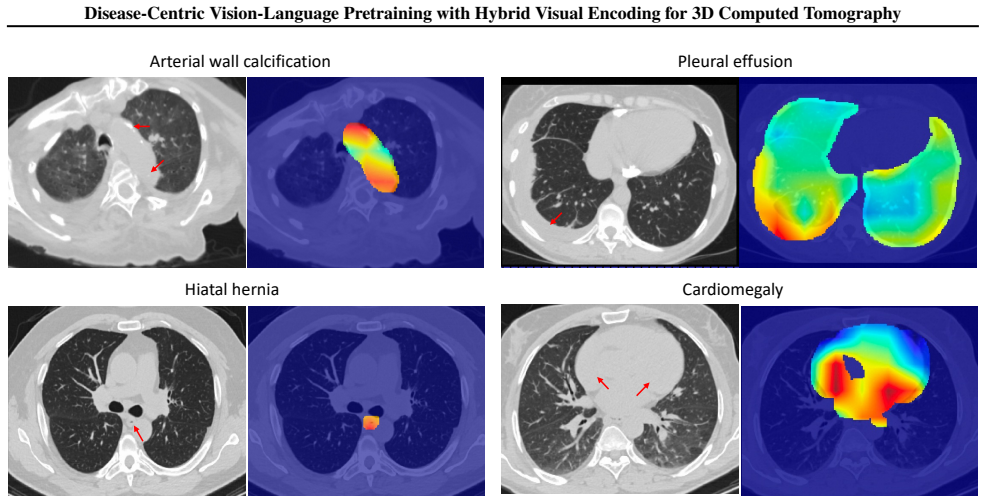
The paper claims that its tailored VLP framework, built around a CNN-ViT hybrid visual encoder, disease-level contrastive learning via learnable query tokens that dynamically align report semantics with 3D visual features, and diagnosis-aware prompts that employ real clinical phrases plus aggregated prototypes, delivers state-of-the-art AUC of 84.4 percent on CT-RATE (+5.1 percent) and 75.4 percent on Rad-ChestCT (+5.4 percent), with a 9.8 percent AUC gain on a 60-disease benchmark, plus improved transfer to report generation.
What carries the argument
Learnable query tokens that dynamically extract disease-specific semantics from full radiology reports and align them with corresponding visual features in 3D CT volumes.
If this is right
- The framework produces larger gains on challenging benchmarks that involve many co-occurring diseases within the same anatomical region.
- The method transfers from pretraining to improved performance on the downstream task of radiology report generation.
- The hybrid encoder captures local anatomical details while preserving compatibility with existing pre-trained cross-modal priors.
- Diagnosis-aware prompts narrow the gap between pretraining and inference, raising zero-shot diagnostic reliability.
Where Pith is reading between the lines
- The query-token mechanism for fine-grained disease disentanglement could be tested on other volumetric modalities such as MRI when paired with report text.
- If the alignment holds, the same disease-centric contrastive objective may reduce errors in multi-label settings where diseases overlap spatially.
- The reported gains on a 60-disease set suggest the approach could lower the annotation burden for rare disease combinations in clinical datasets.
Load-bearing premise
Learnable query tokens can reliably disentangle distinct diseases from full radiology reports and align them with the corresponding visual features in 3D CT volumes without introducing alignment errors that affect downstream diagnosis.
What would settle it
A controlled test on CT volumes with expert-annotated disease locations showing that query-token features frequently misalign with actual lesion sites and that AUC gains vanish would falsify the central alignment claim.
Figures
read the original abstract
Vision-language pre-training (VLP) holds great promise for general-purpose medical AI by leveraging radiology reports as rich textual supervision, yet existing methods struggle with 3D CT imaging due to inefficient visual backbones and coarse semantic alignment. To address these issues, we propose a tailored VLP framework featuring three key components: (1) a CNN-ViT hybrid encoder that replaces ViT's patch embedding with a 3D CNN backbone to efficiently capture local anatomical details while preserving global attention and compatibility with pre-trained cross-modal priors; (2) a disease-level contrastive learning mechanism using learnable query tokens to dynamically extract disease-specific semantics from full reports and align them with corresponding visual features, thereby disentangling distinct diseases within the same anatomical region; and (3) a diagnosis-aware prompt strategy that employs real clinical phrases and aggregated disease prototypes to bridge the pre-training-inference gap and enhance zero-shot diagnostic reliability. Our model achieves state-of-the-art performance on CT-RATE (84.4% AUC, +5.1%) and Rad-ChestCT (75.4% AUC, +5.4%), with even larger gains (+9.8% AUC) on a challenging 60-disease benchmark, and demonstrates strong transferability to radiology report generation, underscoring the generality and clinical utility of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a vision-language pretraining framework for 3D CT imaging with three components: (1) a CNN-ViT hybrid encoder replacing ViT patch embedding with a 3D CNN backbone, (2) disease-level contrastive learning using learnable query tokens to extract disease-specific semantics from full radiology reports and align them to visual features, and (3) a diagnosis-aware prompt strategy using clinical phrases and disease prototypes. It reports SOTA zero-shot AUC of 84.4% (+5.1%) on CT-RATE, 75.4% (+5.4%) on Rad-ChestCT, and +9.8% on a 60-disease benchmark, plus transfer to report generation.
Significance. If the empirical results hold under scrutiny, the work would advance medical VLP for 3D CT by addressing visual efficiency and fine-grained disease alignment, offering a practical path to improved zero-shot diagnosis and report generation with potential clinical impact.
major comments (2)
- [Abstract, component (2)] Abstract, component (2): The headline SOTA claims rest on the disease-level contrastive objective with learnable query tokens successfully disentangling co-occurring diseases from reports for alignment to 3D features. The manuscript supplies no ablation removing this component, no attention-map evidence, and no failure-case analysis for cases where multiple diseases share anatomical regions; without these, the reported AUC gains cannot be confidently attributed to this mechanism rather than the hybrid encoder or prompts.
- [Experimental results] Experimental results section: The performance numbers (84.4% AUC on CT-RATE, 75.4% on Rad-ChestCT, +9.8% on 60-disease benchmark) are presented without accompanying details on baseline implementations, hyperparameter choices, statistical testing, or error bars. This makes it impossible to verify robustness or rule out post-hoc selection effects that could inflate the gains.
minor comments (2)
- The hybrid encoder description would benefit from explicit comparison of parameter count and FLOPs versus a standard 3D ViT to substantiate the efficiency claim.
- Ensure consistent definition of all acronyms (e.g., AUC, VLP) at first use in the main body.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects for strengthening the attribution of gains and the reproducibility of results. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract, component (2)] Abstract, component (2): The headline SOTA claims rest on the disease-level contrastive objective with learnable query tokens successfully disentangling co-occurring diseases from reports for alignment to 3D features. The manuscript supplies no ablation removing this component, no attention-map evidence, and no failure-case analysis for cases where multiple diseases share anatomical regions; without these, the reported AUC gains cannot be confidently attributed to this mechanism rather than the hybrid encoder or prompts.
Authors: We agree that the current version does not include an ablation isolating the disease-level contrastive learning with learnable query tokens, nor does it provide attention maps or targeted failure-case analysis for co-occurring diseases in shared anatomical regions. These elements would strengthen the causal attribution of the reported AUC improvements. In the revised manuscript we will add: (i) an ablation that removes the query-token contrastive objective while retaining the hybrid encoder and prompt strategy, (ii) qualitative attention-map visualizations comparing disease-specific token activations, and (iii) a quantitative breakdown of performance on subsets of cases with multiple overlapping diseases. These additions will allow readers to assess the contribution of component (2) more rigorously. revision: yes
-
Referee: [Experimental results] Experimental results section: The performance numbers (84.4% AUC on CT-RATE, 75.4% on Rad-ChestCT, +9.8% on 60-disease benchmark) are presented without accompanying details on baseline implementations, hyperparameter choices, statistical testing, or error bars. This makes it impossible to verify robustness or rule out post-hoc selection effects that could inflate the gains.
Authors: The referee correctly notes that the experimental section lacks sufficient implementation details, hyperparameter specifications, statistical tests, and error bars. To enable verification of robustness and to mitigate concerns about post-hoc selection, the revised manuscript will expand the experimental results section with: full descriptions of baseline re-implementations (including any adaptations made to 3D CT), complete hyperparameter tables, results reported as mean ± standard deviation over multiple random seeds, and paired statistical significance tests (e.g., Wilcoxon or t-tests) against the strongest baselines. We will also clarify the model-selection protocol used during development. revision: yes
Circularity Check
No significant circularity; empirical performance claims rest on standard contrastive objectives without reduction to fitted inputs or self-citations
full rationale
The paper introduces a VLP framework with a hybrid CNN-ViT encoder, disease-level contrastive learning via learnable queries, and diagnosis-aware prompts, then reports empirical AUC gains on CT-RATE, Rad-ChestCT, and a 60-disease benchmark. No equations, parameter-fitting steps, or self-citation chains are described that would make any claimed result equivalent to its inputs by construction. The contrastive mechanism is a standard alignment technique applied to the proposed architecture rather than a self-definitional loop, and the SOTA numbers are presented as measured outcomes on external benchmarks. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Menze, Bjoern , journal=
Hamamci, Ibrahim Ethem and Er, Sezgin and Almas, Furkan and Simsek, Ayse Gulnihan and Esirgun, Sevval Nil and Dogan, Irem and Dasdelen, Muhammed Furkan and Wittmann, Bastian and Simsar, Enis and Simsar, Mehmet and Erdemir, Emine Bensu and Alanbay, Abdullah and Sekuboyina, Anjany and Lafci, Berkan and Ozdemir, Mehmet K. and Menze, Bjoern , journal=. A foun...
-
[2]
Machine-learning-based multiple abnormality prediction with large-scale chest computed tomography volumes , author=. Med. Image Anal. , volume=. 2021 , publisher=
2021
-
[3]
2021 , organization=
Learning transferable visual models from natural language supervision , author=. 2021 , organization=
2021
-
[4]
Radiology: Artificial Intelligence , volume=
TotalSegmentator: robust segmentation of 104 anatomic structures in CT images , author=. Radiology: Artificial Intelligence , volume=. 2023 , publisher=
2023
-
[5]
Grounded language-image pre-training , author=
-
[6]
Scaling language-image pre-training via masking , author=
-
[7]
2020 , organization=
Uniter: Universal image-text representation learning , author=. 2020 , organization=
2020
-
[8]
Expert-level detection of pathologies from unannotated chest
Tiu, Ekin and Talius, Ellie and Patel, Pujan and Langlotz, Curtis P and Ng, Andrew Y and Rajpurkar, Pranav , journal=. Expert-level detection of pathologies from unannotated chest. 2022 , publisher=
2022
-
[9]
Prior: Prototype representation joint learning from medical images and reports , author=
-
[10]
Advancing radiograph representation learning with masked record modeling , author=
-
[11]
Align, reason and learn: Enhancing medical vision-and-language pre-training with knowledge , author=
-
[12]
Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition , author=
-
[13]
Nature Communications , volume=
Knowledge-enhanced visual-language pre-training on chest radiology images , author=. Nature Communications , volume=. 2023 , publisher=
2023
-
[14]
Dynamic Graph Enhanced Contrastive Learning for Chest
Li, Mingjie and Lin, Bingqian and Chen, Zicong and Lin, Haokun and Liang, Xiaodan and Chang, Xiaojun , booktitle=CVPR, pages=. Dynamic Graph Enhanced Contrastive Learning for Chest
-
[15]
Medklip: Medical knowledge enhanced language-image pre-training for
Wu, Chaoyi and Zhang, Xiaoman and Zhang, Ya and Wang, Yanfeng and Xie, Weidi , booktitle=CVPR, pages=. Medklip: Medical knowledge enhanced language-image pre-training for
-
[16]
When radiology report generation meets knowledge graph , author=
-
[17]
Bootstrapping Large Language Models for Radiology Report Generation , author=
-
[18]
2022 , organization=
Joint learning of localized representations from medical images and reports , author=. 2022 , organization=
2022
-
[19]
Multi-granularity cross-modal alignment for generalized medical visual representation learning , author=
-
[20]
arXiv preprint arXiv:2310.07355 , year=
Imitate: Clinical prior guided hierarchical vision-language pre-training , author=. arXiv preprint arXiv:2310.07355 , year=
-
[21]
arXiv preprint arXiv:2403.09294 , year=
Anatomical Structure-Guided Medical Vision-Language Pre-training , author=. arXiv preprint arXiv:2403.09294 , year=
-
[22]
Lin, Jingyang and Xia, Yingda and Zhang, Jianpeng and Yan, Ke and Lu, Le and Luo, Jiebo and Zhang, Ling , journal=
-
[23]
Bootstrapping Chest
Cao, Weiwei and Zhang, Jianpeng and Xia, Yingda and Mok, Tony CW and Li, Zi and Ye, Xianghua and Lu, Le and Zheng, Jian and Tang, Yuxing and Zhang, Ling , booktitle=CVPR, pages=. Bootstrapping Chest
-
[24]
Nature , volume=
Merlin: a computed tomography vision–language foundation model and dataset , author=. Nature , volume=
-
[25]
Medical image analysis , volume=
A survey on deep learning in medical image analysis , author=. Medical image analysis , volume=. 2017 , publisher=
2017
-
[26]
Computers in biology and medicine , volume=
Deep learning for diagnosis of COVID-19 using 3D CT scans , author=. Computers in biology and medicine , volume=. 2021 , publisher=
2021
-
[27]
Annals of translational medicine , volume=
A review of the application of deep learning in medical image classification and segmentation , author=. Annals of translational medicine , volume=. 2020 , publisher=
2020
-
[28]
Nature methods , volume=
nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation , author=. Nature methods , volume=. 2021 , publisher=
2021
-
[29]
2016 fourth international conference on 3D vision (3DV) , pages=
V-net: Fully convolutional neural networks for volumetric medical image segmentation , author=. 2016 fourth international conference on 3D vision (3DV) , pages=. 2016 , organization=
2016
-
[30]
2017 , pages=
Neural discrete representation learning , author=. 2017 , pages=
2017
-
[31]
Supervised contrastive learning , author=
-
[32]
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results , author=
-
[33]
Miccai multi-atlas labeling beyond the cranial vault--workshop and challenge , author=. Proc. MICCAI Multi-Atlas Labeling Beyond Cranial Vault—Workshop Challenge , volume=
-
[34]
arXiv preprint arXiv:1810.04805 , year=
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. arXiv preprint arXiv:1810.04805 , year=
-
[35]
Minds and Machines , volume=
GPT-3: Its nature, scope, limits, and consequences , author=. Minds and Machines , volume=. 2020 , publisher=
2020
-
[36]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[37]
arXiv preprint arXiv:2302.13971 , year=
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
-
[38]
IEEE Transactions on Medical Imaging , year=
An Organ-aware Diagnosis Framework for Radiology Report Generation , author=. IEEE Transactions on Medical Imaging , year=
-
[39]
arXiv preprint arXiv:2403.06728 , year=
Large Model driven Radiology Report Generation with Clinical Quality Reinforcement Learning , author=. arXiv preprint arXiv:2403.06728 , year=
-
[40]
Masked image modeling advances
Chen, Zekai and Agarwal, Devansh and Aggarwal, Kshitij and Safta, Wiem and Balan, Mariann Micsinai and Brown, Kevin , booktitle=. Masked image modeling advances
-
[41]
U-net: Convolutional networks for biomedical image segmentation , author=. Int. Conf. Med. Image Comput. Comput.-Assist. Interv. , pages=
-
[42]
Align before fuse: Vision and language representation learning with momentum distillation , author=
-
[43]
2024 , publisher=
Medical image segmentation review: The success of u-net , author=. 2024 , publisher=
2024
-
[44]
Momentum contrast for unsupervised visual representation learning , author=
-
[45]
arXiv preprint arXiv:1807.03748 , year=
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
-
[46]
ACM computing surveys (CSUR) , volume=
Deep learning for anomaly detection: A review , author=. ACM computing surveys (CSUR) , volume=. 2021 , publisher=
2021
-
[47]
arXiv preprint arXiv:2309.16609 , year=
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
-
[48]
Neural discrete representation learning , author=
-
[49]
Attention is all you need , author=
-
[50]
Cmt: Convolutional neural networks meet vision transformers , author=
-
[51]
Cotr: Efficiently bridging cnn and transformer for 3d medical image segmentation , author=. Medical Image Computing and Computer Assisted Intervention--MICCAI 2021: 24th International Conference, Strasbourg, France, September 27--October 1, 2021, Proceedings, Part III 24 , pages=. 2021 , organization=
2021
-
[52]
arXiv preprint arXiv:2310.19061 , year=
Multimodal ChatGPT for medical applications: an experimental study of GPT-4V , author=. arXiv preprint arXiv:2310.19061 , year=
-
[53]
Large-scale and Fine-grained Vision-language Pre-training for Enhanced
Shui, Zhongyi and Zhang, Jianpeng and Cao, Weiwei and Wang, Sinuo and Guo, Ruizhe and Lu, Le and Yang, Lin and Ye, Xianghua and Liang, Tingbo and Zhang, Qi and Zhang, Ling , booktitle=ICLR, pages=. Large-scale and Fine-grained Vision-language Pre-training for Enhanced
-
[54]
Interactive and explainable region-guided radiology report generation , author=
-
[55]
arXiv preprint arXiv:2405.03595 , year=
Green: Generative radiology report evaluation and error notation , author=. arXiv preprint arXiv:2405.03595 , year=
-
[56]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[57]
Masked autoencoders are scalable vision learners , author=
-
[58]
Deep residual learning for image recognition , author=
-
[59]
2022 , organization=
Making the most of text semantics to improve biomedical vision--language processing , author=. 2022 , organization=
2022
-
[60]
International conference on machine learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[61]
Boosting vision semantic density with anatomy normality modeling for medical vision-language pre-training , author=
-
[62]
Tschannen, Michael and Gritsenko, Alexey and Wang, Xiao and Naeem, Muhammad Ferjad and Alabdulmohsin, Ibrahim and Parthasarathy, Nikhil and Evans, Talfan and Beyer, Lucas and Xia, Ye and Mustafa, Basil and Hénaff, Olivier and Harmsen, Jeremiah and Steiner, Andreas and Zhai, Xiaohua , journal=
-
[63]
Towards generalist foundation model for radiology by leveraging web-scale
Wu, Chaoyi and Zhang, Xiaoman and Zhang, Ya and Hui, Hui and Wang, Yanfeng and Xie, Weidi , journal=. Towards generalist foundation model for radiology by leveraging web-scale. 2025 , publisher=
2025
-
[64]
2024 , organization=
Hamamci, Ibrahim Ethem and Er, Sezgin and Menze, Bjoern , booktitle=. 2024 , organization=
2024
-
[65]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[66]
Technical report , year =
Qwen3-Max: Just Scale it , author =. Technical report , year =
-
[67]
Neural Comput
Adaptive mixtures of local experts , author=. Neural Comput. , volume=. 1991 , publisher=
1991
-
[68]
Meng, Lingchen and Yang, Jianwei and Tian, Rui and Dai, Xiyang and Wu, Zuxuan and Gao, Jianfeng and Jiang, Yu-Gang , journal=NIPS, volume=
-
[69]
arXiv preprint arXiv:2507.05201 , year=
Sellergren, Andrew and Kazemzadeh, Sahar and Jaroensri, Tiam and Kiraly, Atilla and Traverse, Madeleine and Kohlberger, Timo and Xu, Shawn and Jamil, Fayaz and Hughes, C. arXiv preprint arXiv:2507.05201 , year=
-
[70]
Towards Scalable Language-Image Pre-training for
Zhao, Chenhui and Lyu, Yiwei and Chowdury, Asadur and Harake, Edward and Kondepudi, Akhil and Rao, Akshay and Hou, Xinhai and Lee, Honglak and Hollon, Todd , journal=. Towards Scalable Language-Image Pre-training for
-
[71]
More performant and scalable: Rethinking contrastive vision-language pre-training of radiology in the
Li, Yingtai and Lai, Haoran and Zhou, Xiaoqian and Ming, Shuai and Ma, Wenxin and Wei, Wei and Zhou, Shaohua Kevin , booktitle=. More performant and scalable: Rethinking contrastive vision-language pre-training of radiology in the
-
[72]
and Korfiatis, Panagiotis and Salvatelli, Valentina and Alvarez-Valle, Javier and Pérez-García, Fernando , journal=
Wald, Tassilo and Hamamci, Ibrahim Ethem and Gao, Yuan and Bond-Taylor, Sam and Sharma, Harshita and Ilse, Maximilian and Lo, Cynthia and Melnichenko, Olesya and Codella, Noel CF and Wetscherek, Maria Teodora and Maier-Hein, Klaus H. and Korfiatis, Panagiotis and Salvatelli, Valentina and Alvarez-Valle, Javier and Pérez-García, Fernando , journal=. Compre...
-
[73]
2023 , publisher=
Wasserthal, Jakob and Breit, Hanns-Christian and Meyer, Manfred T and Pradella, Maurice and Hinck, Daniel and Sauter, Alexander W and Heye, Tobias and Boll, Daniel T and Cyriac, Joshy and Yang, Shan and Bach, Michael and Segeroth, Martin , journal=. 2023 , publisher=
2023
-
[74]
An image is worth 16x16 words: Transformers for image recognition at scale , author=
-
[75]
Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations , author=. Int. Workshop Deep Learn. Med. Image Anal. , pages=
-
[76]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=
-
[77]
Contrastive learning of medical visual representations from paired images and text , author=. Mach. Learn. Healthc. Conf. , pages=. 2022 , organization=
2022
-
[78]
A visual--language foundation model for pathology image analysis using medical twitter , author=. Nat. Med. , volume=. 2023 , publisher=
2023
-
[79]
Shi, Bowen and Zhao, Peisen and Wang, Zichen and Zhang, Yuhang and Wang, Yaoming and Li, Jin and Dai, Wenrui and Zou, Junni and Xiong, Hongkai and Tian, Qi and Zhang, Xiaopeng , booktitle=ECCV, pages=
-
[80]
Sigmoid loss for language image pre-training , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.