Detecting Sensitive Personal Information in Japanese Pre-Training Corpora for Large Language Models
Pith reviewed 2026-06-27 09:53 UTC · model grok-4.3
The pith
A classifier trained on LLM-annotated Japanese text can detect special care-required personal information in pre-training corpora.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
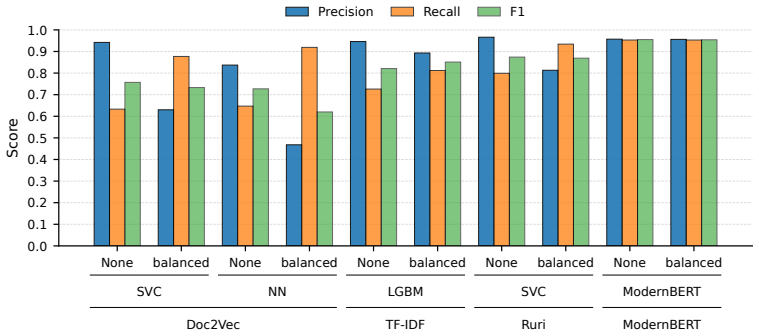
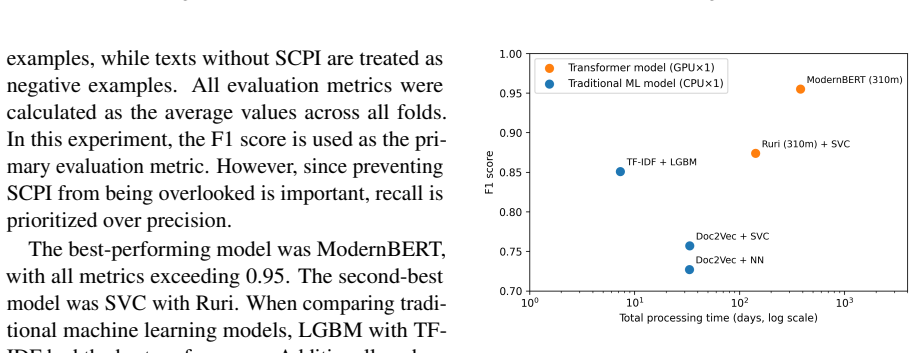
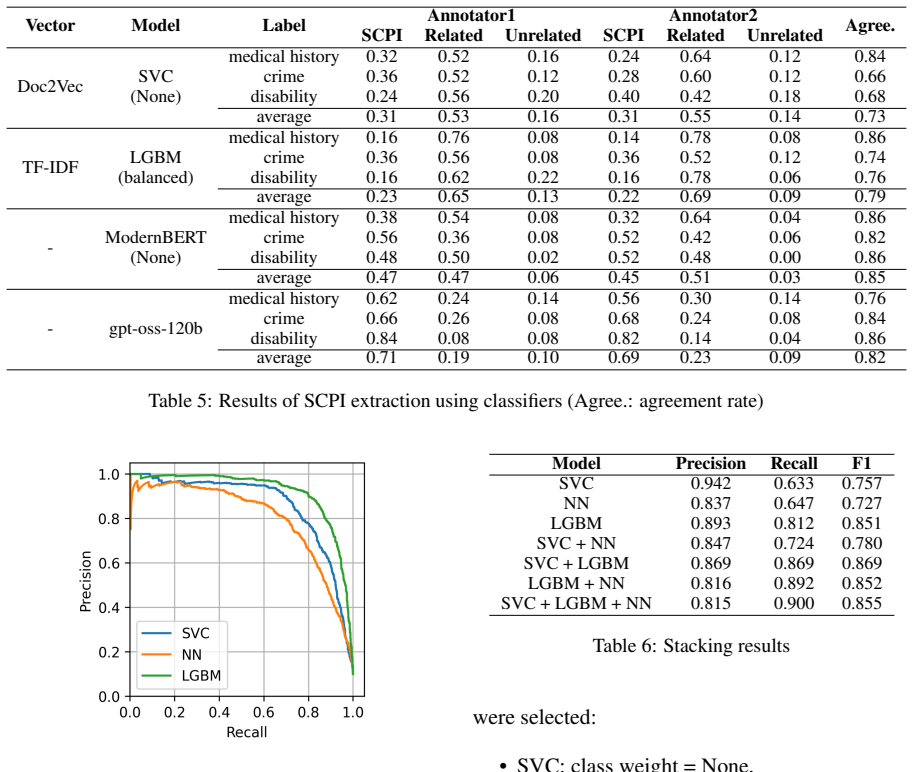
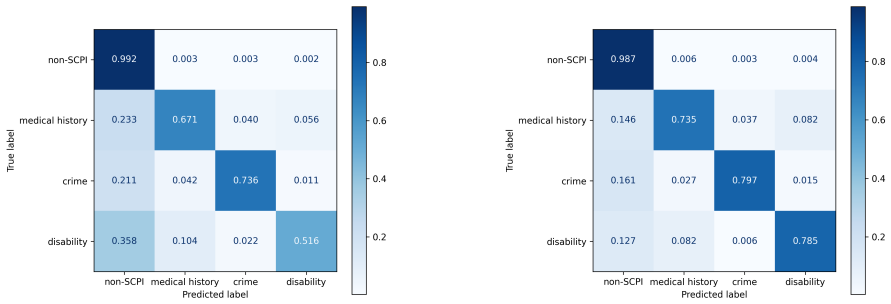
We construct an SCPI dataset using LLM-based annotation and train machine learning models to rapidly detect SCPI in text. As a result, our SCPI classifier can effectively identify information related to SCPI. This study is the first to explore SCPI detection in Japanese text corpora, highlighting the challenges of accurate detection.
What carries the argument
The SCPI classifier, a machine learning model trained on an LLM-annotated dataset of Japanese text labeled for special care-required personal information under Japan's APPI.
If this is right
- Japanese LLM pre-training pipelines can insert the classifier as a filter step to remove SCPI before model training.
- Compliance with Japan's Act on the Protection of Personal Information becomes more feasible for large-scale text collection.
- Rapid scanning of web-scale Japanese corpora becomes practical without exhaustive manual review.
- Future work can treat the reported classifier performance as a baseline for Japanese SCPI detection.
Where Pith is reading between the lines
- The same LLM-annotation-plus-classifier pattern could be tested on other languages that lack mature sensitive-data detectors.
- Error patterns in the Japanese results may point to language-specific cues that future detectors must handle explicitly.
- Deploying the classifier inside data-cleaning pipelines could shift standard practice for any non-English LLM training effort.
- Hybrid human review of borderline cases flagged by the model might further raise label quality beyond pure LLM annotation.
Load-bearing premise
Labels produced by the LLM annotator are accurate and unbiased enough to serve as reliable training data for the downstream SCPI detector.
What would settle it
A side-by-side human review of several hundred LLM-annotated examples that finds more than 20 percent label errors on SCPI presence or absence.
Figures


read the original abstract
Sensitive personal information can appear in large-scale pre-training corpora for large language models (LLMs). Detecting and filtering such information is therefore essential to ensure compliance with privacy regulations and prevent unintended information leakage. However, in contrast to English and other languages, research into sensitive personal information has been limited in the Japanese language. In this study, we focus on sensitive personal data defined as special care-required personal information (SCPI) under Japan's Act on the Protection of Personal Information (APPI). We construct an SCPI dataset using LLM-based annotation and train machine learning models to rapidly detect SCPI in text. As a result, our SCPI classifier can effectively identify information related to SCPI. This study is the first to explore SCPI detection in Japanese text corpora, highlighting the challenges of accurate detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to be the first study on detecting special care-required personal information (SCPI) under Japan's APPI in Japanese pre-training corpora for LLMs. It constructs an SCPI dataset via LLM-based annotation, trains machine learning classifiers on this data, and asserts that the resulting SCPI classifier can effectively identify SCPI instances.
Significance. If the effectiveness claim were supported by rigorous validation, the work would fill a genuine gap in privacy-preserving data curation for Japanese LLMs and offer a practical detection tool. The absence of any quantitative evidence for either label quality or classifier performance, however, prevents assessment of whether this contribution is realized.
major comments (3)
- [Abstract] Abstract: the central claim that 'our SCPI classifier can effectively identify information related to SCPI' is stated without any reported precision, recall, F1, accuracy, baseline comparisons, or error analysis. This directly undermines evaluation of the paper's primary result.
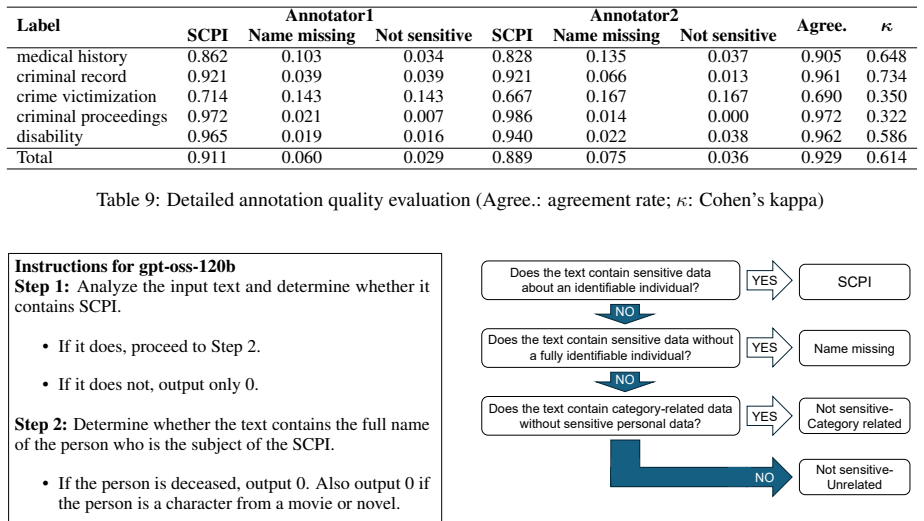
- [Methods / Dataset construction] The construction of the training labels relies on LLM-based annotation, yet no human validation, inter-annotator agreement, or bias audit is described. Because SCPI definitions involve culturally specific phrasing under APPI, unvalidated LLM labels constitute a load-bearing risk to all downstream claims.
- [Results / Experiments] No section or table presents classifier performance metrics or ablation studies. Without these, the assertion of effective detection cannot be distinguished from an untested pipeline.
minor comments (2)
- [Introduction] Clarify the exact definition of SCPI used for annotation and whether it follows the APPI statutory language verbatim.
- [Methods] Provide the full list of LLM prompts and any post-processing rules applied during annotation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments identifying gaps in quantitative support and validation. We agree these elements are necessary to substantiate the claims and will perform a major revision to add the missing details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'our SCPI classifier can effectively identify information related to SCPI' is stated without any reported precision, recall, F1, accuracy, baseline comparisons, or error analysis. This directly undermines evaluation of the paper's primary result.
Authors: We agree that the abstract claim requires supporting metrics. In the revised manuscript we will update the abstract to report precision, recall, F1, accuracy, baseline comparisons, and a concise error analysis so readers can evaluate the primary result. revision: yes
-
Referee: [Methods / Dataset construction] The construction of the training labels relies on LLM-based annotation, yet no human validation, inter-annotator agreement, or bias audit is described. Because SCPI definitions involve culturally specific phrasing under APPI, unvalidated LLM labels constitute a load-bearing risk to all downstream claims.
Authors: We accept that LLM annotation requires validation given the cultural and legal specificity of SCPI. The revision will add human validation on a sample, inter-annotator agreement statistics, and a bias audit in the methods section. revision: yes
-
Referee: [Results / Experiments] No section or table presents classifier performance metrics or ablation studies. Without these, the assertion of effective detection cannot be distinguished from an untested pipeline.
Authors: We acknowledge the results section lacks the required metrics and ablations. The revised manuscript will add a results section containing tables with performance metrics (precision, recall, F1, accuracy), baseline comparisons, and ablation studies. revision: yes
Circularity Check
Standard empirical ML pipeline with no definitional or self-referential reduction
full rationale
The paper constructs an SCPI dataset via LLM-based annotation then trains standard ML classifiers on that dataset. This matches the reader's assessment of a conventional annotation-plus-supervised-training workflow. No equations, fitted parameters renamed as predictions, self-citation chains, or uniqueness theorems appear in the provided abstract or description. The central claim ('our SCPI classifier can effectively identify information related to SCPI') is presented as the outcome of ordinary training and evaluation rather than any reduction to its own inputs by construction. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Are Large Pre- Trained Language Models Leaking Your Personal Information?
Huang, Jie and Shao, Hanyin and Chang, Kevin Chen-Chuan. Are Large Pre-Trained Language Models Leaking Your Personal Information?. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.148
-
[2]
California Civil Code Section 1798.140 , year =
-
[3]
Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) , year =
2016
-
[4]
Act on the Protection of Personal Information (Translated Version) , year =
-
[5]
Cabinet Order to Enforce the Act on the Protection of Personal Information (Translated Version) , year =
-
[6]
Notices and warnings regarding the use of AI generation services , year =
-
[7]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[8]
Detecting Personal Information in Training Corpora: an Analysis
Subramani, Nishant and Luccioni, Sasha and Dodge, Jesse and Mitchell, Margaret. Detecting Personal Information in Training Corpora: an Analysis. Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023). 2023. doi:10.18653/v1/2023.trustnlp-1.18
-
[9]
2025 , eprint=
Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training , author=. 2025 , eprint=
2025
-
[10]
Soldaini, Luca and Kinney, Rodney and Bhagia, Akshita and Schwenk, Dustin and Atkinson, David and Authur, Russell and Bogin, Ben and Chandu, Khyathi and Dumas, Jennifer and Elazar, Yanai and Hofmann, Valentin and Jha, Ananya and Kumar, Sachin and Lucy, Li and Lyu, Xinxi and Lambert, Nathan and Magnusson, Ian and Morrison, Jacob and Muennighoff, Niklas and...
-
[11]
Sensitive Data Detection and Classification in S panish Clinical Text: Experiments with BERT
Garc \'i a Pablos, Aitor and Perez, Naiara and Cuadros, Montse. Sensitive Data Detection and Classification in S panish Clinical Text: Experiments with BERT. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[12]
Future Internet , VOLUME =
Petrolini, Michael and Cagnoni, Stefano and Mordonini, Monica , TITLE =. Future Internet , VOLUME =. 2022 , NUMBER =
2022
-
[13]
Is Your Model Sensitive? SPEDAC: A New Resource for the Automatic Classification of Sensitive Personal Data , year=
Gambarelli, Gaia and Gangemi, Aldo and Tripodi, Rocco , journal=. Is Your Model Sensitive? SPEDAC: A New Resource for the Automatic Classification of Sensitive Personal Data , year=
-
[14]
The Thirteenth International Conference on Learning Representations , year=
A benchmark for semantic sensitive information in llms outputs , author=. The Thirteenth International Conference on Learning Representations , year=
-
[15]
Detecting Personal Identifiable Information in S wedish Learner Essays
Szawerna, Maria Irena and Dobnik, Simon and Mu. Detecting Personal Identifiable Information in S wedish Learner Essays. Proceedings of the Workshop on Computational Approaches to Language Data Pseudonymization (CALD-pseudo 2024). 2024
2024
-
[16]
2025 , eprint=
Olmo 3 , author=. 2025 , eprint=
2025
-
[17]
Proceedings of the First Conference on Language Modeling
Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities , author=. Proceedings of the First Conference on Language Modeling. 2024
2024
-
[18]
Proceedings of the First Conference on Language Modeling
Building a Large Japanese Web Corpus for Large Language Models , author=. Proceedings of the First Conference on Language Modeling. 2024
2024
-
[19]
2025 , eprint=
Youmi Ma and Sakae Mizuki and Kazuki Fujii and Taishi Nakamura and Masanari Ohi and Hinari Shimada and Taihei Shiotani and Koshiro Saito and Koki Maeda and Kakeru Hattori and Takumi Okamoto and Shigeki Ishida and Rio Yokota and Hiroya Takamura and Naoaki Okazaki , title=. 2025 , eprint=
2025
-
[20]
Gemma , url=. doi:10.34740/KAGGLE/M/3301 , publisher=
-
[21]
Llama 3.1 Swallow , year=
-
[22]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[23]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[24]
and Varoquaux, G
Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V. and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P. and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E. , journal=. Scikit-learn: Machine Learning in
-
[25]
2017 , url =
Microsoft , title =. 2017 , url =
2017
-
[26]
Ansel, Jason and Yang, Edward and He, Horace and Gimelshein, Natalia and Jain, Animesh and Voznesensky, Michael and Bao, Bin and Bell, Peter and Berard, David and Burovski, Evgeni and Chauhan, Geeta and Chourdia, Anjali and Constable, Will and Desmaison, Alban and DeVito, Zachary and Ellison, Elias and Feng, Will and Gong, Jiong and Gschwind, Michael and ...
-
[27]
Tsukagoshi, Hayato and Li, Shengzhe and Fukuchi, Akihiko and Shibata, Tomohide , title =
-
[28]
Hayato Tsukagoshi and Ryohei Sasano , year=. 2409.07737 , archivePrefix=
-
[29]
Proceedings of the 25th
Optuna: A Next-generation Hyperparameter Optimization Framework , author=. Proceedings of the 25th
-
[30]
Nature Machine Intelligence , volume=
From local explanations to global understanding with explainable AI for trees , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[31]
2024 , url =
Microsoft , title =. 2024 , url =
2024
-
[32]
Llama 3.1 Acceptable Use Policy , year =
-
[33]
2024 , url =
Google , title =. 2024 , url =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.