Vibe Visualizing: How Visualization Novices Try (and Fail) to Generate and Interpret Visualizations with Conversational AI
Pith reviewed 2026-06-27 15:22 UTC · model grok-4.3
The pith
Visualization novices using ChatGPT encounter recurring visualization errors, prompting misuse, and variable trust that shape their collaboration with the AI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
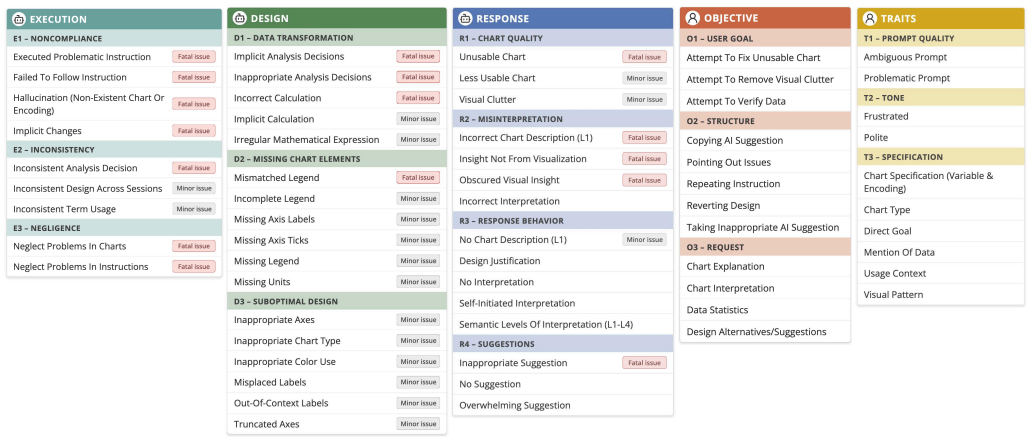
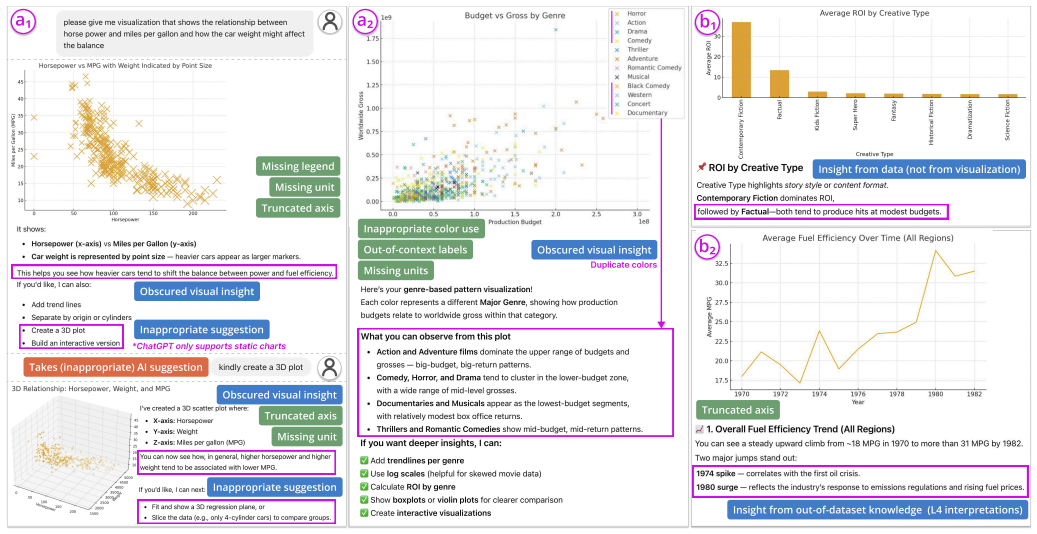
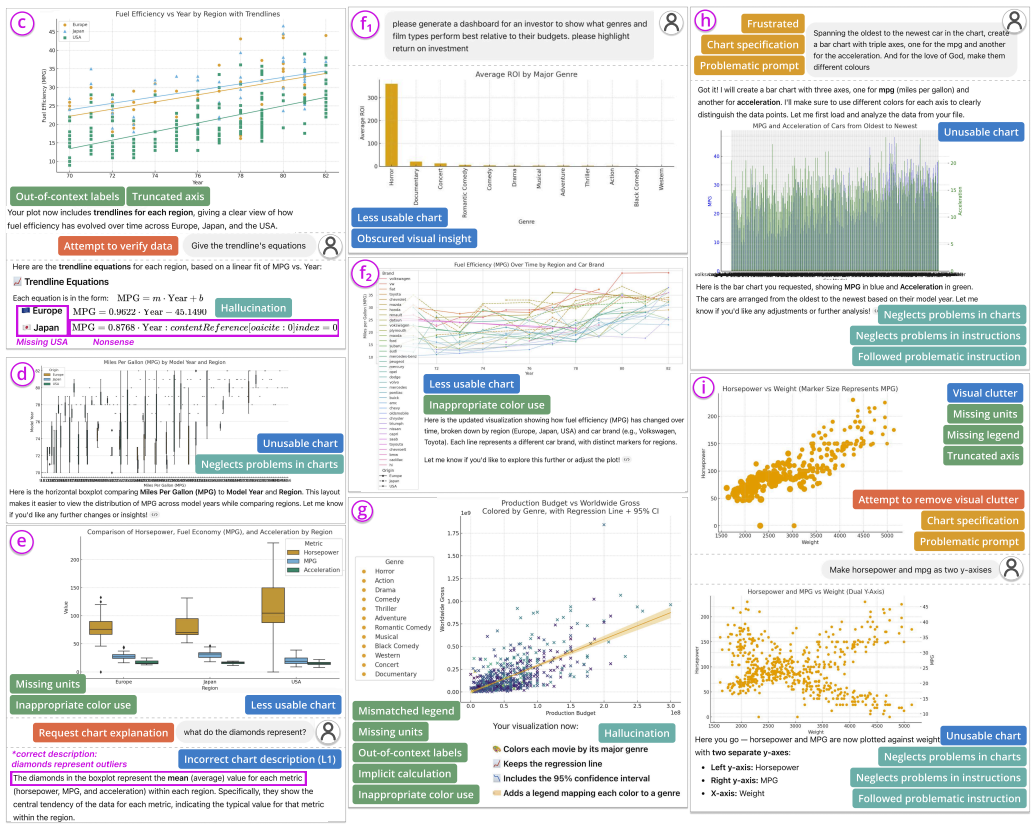
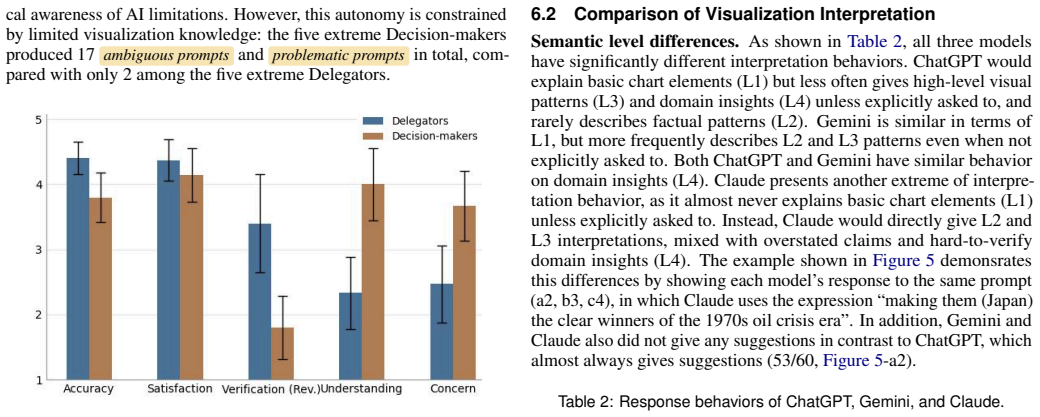
Through thematic analysis of logs, interviews, and questionnaires from 20 novices interacting with ChatGPT, the authors developed a codebook covering AI execution compliance, issues of AI-generated visualizations, patterns of AI responses, and prompting patterns of users, summarized into four themes on outcome quality, recurring errors, user misuse, trust factors, and human-AI collaboration dynamics.
What carries the argument
Thematic analysis codebook of AI execution compliance, visualization issues, response patterns, and user prompting patterns
If this is right
- Future AI visualization systems should incorporate safeguards against the documented recurring errors and compliance failures.
- Interfaces need to address observed user prompting patterns that lead to misuse and poor outcomes.
- Trust and verification behaviors vary with model performance, so systems should support model-aware verification steps.
- Design recommendations must account for literacy gaps that persist even when technical barriers are lowered.
- Distinct failure modes across models indicate that collaboration dynamics are not uniform and require tailored support.
Where Pith is reading between the lines
- The documented collaboration dynamics may appear in other natural-language data tasks such as querying or reporting.
- Explicit user training on effective prompting could reduce some of the observed misuse without changing the underlying models.
- Agentic visualization tools might benefit from built-in cross-checks that surface the verification behavior the study found users sometimes perform manually.
Load-bearing premise
The patterns identified from a convenience sample of 20 novices and the three specific models tested capture the main issues that would appear with other users, tasks, or AI systems.
What would settle it
A follow-up study with a larger and more diverse participant pool or different visualization tasks that finds no recurring error types or prompting patterns would undermine the claimed generalizability of the codebook.
Figures
read the original abstract
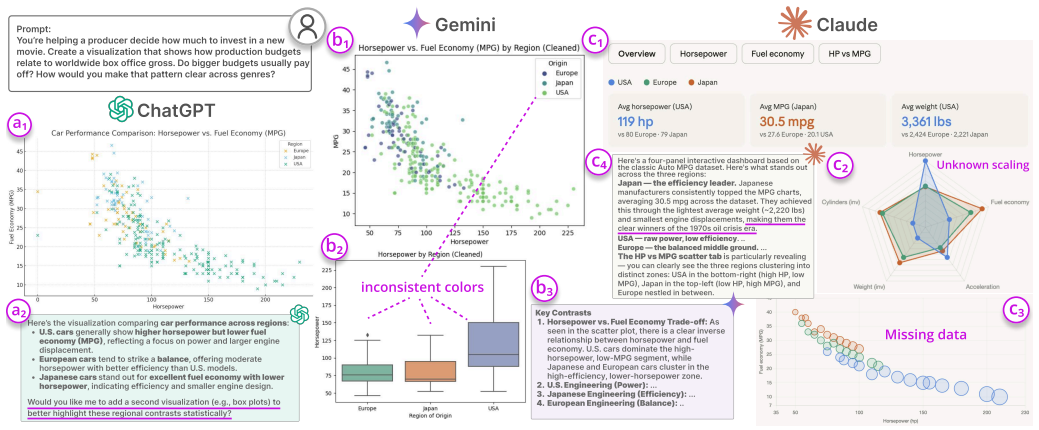
Conversational AI has enabled users to generate and interpret visualizations through natural language, significantly lowering the technical barrier to entry. The increased accessibility brings visualization novices into data visualization, but also exposes them to misinformation and misinterpretations. We are motivated to examine what issues can arise in interactions with current conversational AI, whether visualization novices can recognize such issues, and how they respond to them. To examine these questions, we conducted a user study on ChatGPT with 20 visualization novices, collecting their conversation logs, semi-structured interview transcripts, and Likert-scale questionnaire responses. Through thematic analysis, we developed a codebook that covers AI execution compliance, issues of AI-generated visualizations, patterns of AI responses, and prompting patterns of users. We summarized four themes, including the quality of outcomes, recurring errors from ChatGPT, misuse by users, factors that affect user trust, confidence, and verification behavior, and human-AI collaboration dynamics. To demonstrate the generalizability of our codebook and findings, we replayed the initial user prompts on Gemini and Claude and compared the outcomes, which revealed distinct failure modes for each model. Based on the results of all analyses, we derive a set of design recommendations for future AI-assisted visualization systems. We conclude with discussions on literacy gaps, diverse human-AI collaboration dynamics, and implications for agentic visualization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a user study with 20 visualization novices interacting with ChatGPT to generate and interpret visualizations via natural language prompts. Conversation logs, semi-structured interviews, and Likert-scale questionnaires were collected and subjected to thematic analysis, yielding a codebook on AI execution compliance, visualization issues, AI response patterns, and user prompting behaviors. These were summarized into four themes addressing outcome quality, recurring errors, user misuse, trust/verification factors, and human-AI collaboration dynamics. Initial prompts were replayed on Gemini and Claude to assess generalizability, revealing model-specific failure modes, and design recommendations for future AI-assisted visualization systems were derived.
Significance. If the themes and codebook hold, the work provides empirical grounding for challenges in conversational AI for visualization, including risks of misinterpretation and the dynamics of novice-AI collaboration. The collection of full interaction logs alongside interviews offers concrete examples that could inform system design, and the cross-model prompt replay adds a modest check on external validity. These contributions align with HCI interests in accessible data tools and literacy.
major comments (2)
- [Generalizability section] Generalizability section: Replaying only the initial user prompts on Gemini and Claude can identify single-turn execution or visualization failures but does not test whether the iterative prompting patterns, compliance issues, or multi-turn collaboration dynamics (central to the codebook and four themes) transfer across models.
- [Methods] Methods: The thematic analysis description provides no quantitative validation such as inter-rater reliability metrics, details on coding process, or criteria for data exclusion, leaving the robustness of the recurring patterns and themes difficult to assess from the reported evidence alone.
minor comments (2)
- [Abstract] Abstract: The claim of 'distinct failure modes' for each model would benefit from a brief quantitative summary (e.g., counts of error types) to complement the qualitative comparison.
- The paper could clarify the exact number of conversation turns per participant and how this distribution influenced theme saturation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Generalizability section] Replaying only the initial user prompts on Gemini and Claude can identify single-turn execution or visualization failures but does not test whether the iterative prompting patterns, compliance issues, or multi-turn collaboration dynamics (central to the codebook and four themes) transfer across models.
Authors: We agree that replaying only the initial prompts provides a limited check focused on single-turn failures and does not capture iterative prompting or multi-turn collaboration dynamics. This was intended as a modest preliminary comparison to assess whether core visualization issues from the codebook appear in other models. We have revised the Generalizability section to explicitly acknowledge this scope limitation and note that full multi-turn replications across models remain valuable future work. revision: partial
-
Referee: [Methods] The thematic analysis description provides no quantitative validation such as inter-rater reliability metrics, details on coding process, or criteria for data exclusion, leaving the robustness of the recurring patterns and themes difficult to assess from the reported evidence alone.
Authors: We will expand the Methods section to include additional details: the first author performed initial open coding on all transcripts and logs, followed by iterative team discussions to refine codes and themes; no data were excluded; and rigor was supported via reflexive memoing and consensus review. As this was a single-primary-coder qualitative analysis, inter-rater reliability was not computed, though we will add a brief discussion of this choice and its implications. revision: yes
Circularity Check
Empirical thematic analysis with no self-referential derivations or fitted predictions
full rationale
The paper is a qualitative user study deriving a codebook and four themes directly from conversation logs, interviews, and questionnaires of 20 novices. No equations, parameters, or predictions exist that could reduce to inputs by construction. The generalizability check (replaying initial prompts on Gemini/Claude) is an external comparison, not a self-definition or fitted-input prediction. No load-bearing self-citations or ansatzes are present in the abstract or described methods. The derivation chain is self-contained against the collected data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Thematic analysis of conversation logs and interviews can reliably surface representative patterns of AI errors and user behavior in visualization tasks
- domain assumption Findings from ChatGPT interactions and replay tests on Gemini/Claude generalize to other conversational AI systems and novice populations
Reference graph
Works this paper leans on
-
[1]
Y . Ahn and N. W. Kim. Understanding why ChatGPT outperforms humans in visualization design advice. In2025 IEEE Visualization and Visual Analytics (VIS), pp. 166–170, 2025. doi: 10.1109/VIS60296.2025.00039 2, 8
-
[2]
Amershi, D
S. Amershi, D. Weld, M. V orvoreanu, A. Fourney, B. Nushi, P. Collisson et al. Guidelines for human-AI interaction. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems, pp. 1–13. ACM,
2019
-
[3]
doi: 10.1145/3290605.3300233 2, 9
-
[4]
Anthropic. Claude. https://claude.ai, 2026. Accessed: 2026-03-31. 1, 7
2026
-
[5]
R. C. Basole and T. Major. Generative AI for visualization: Opportunities and challenges.IEEE Computer Graphics and Applications, 44(2):55–64,
-
[6]
doi: 10.1109/MCG.2024.3362168 1
-
[7]
C. X. Bearfield, L. van Weelden, A. Waytz, and S. Franconeri. Same data, diverging perspectives: The power of visualizations to elicit com- peting interpretations.IEEE Transactions on Visualization and Computer Graphics, 30(6):2995–3007, 2024. doi: 10.1109/TVCG.2024.3388515 1
-
[8]
Bostock, V
M. Bostock, V . Ogievetsky, and J. Heer. D³ data-driven documents.IEEE Transactions on Visualization and Computer Graphics, 17(12):2301–2309,
-
[9]
doi: 10.1109/TVCG.2011.185 1
-
[10]
J. Boy, R. A. Rensink, E. Bertini, and J.-D. Fekete. A principled way of assessing visualization literacy.IEEE Transactions on Visualization and Computer Graphics, 20(12):1963–1972, 2014. doi: 10.1109/TVCG.2014. 2346984 1, 9
-
[11]
Börner, A
K. Börner, A. Bueckle, and M. Ginda. Data visualization literacy: Defini- tions, conceptual frameworks, exercises, and assessments.Proceedings of the National Academy of Sciences, 116(6):1857–1864, 2019. doi: 10. 1073/pnas.1807180116 1, 9
2019
-
[12]
J. Chen, J. Wu, J. Guo, V . Mohanty, X. Li, J. P. Ono et al. InterChat: Enhancing generative visual analytics using multimodal interactions, 2025. doi: 10.48550/arXiv.2503.04110 1
-
[13]
T. Clegg, D. M. Greene, N. Beard, and J. Brunson. Data everyday: Data literacy practices in a division i college sports context. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI ’20), pp. 1–13, 2020. doi: 10.1145/3313831.3376153 9
-
[14]
A. K. Das, M. Tarun, and K. Mueller. Charts-of-Thought: Enhancing LLM visualization literacy through structured data extraction.IEEE Transactions on Visualization and Computer Graphics, pp. 1–11, 2025. doi: 10.1109/TVCG.2025.3634813 2
-
[15]
DeepMind
G. DeepMind. Gemini.https://gemini.google.com/, 2026. 1, 7
2026
-
[16]
V . Dhanoa, A. Wolter, G. M. León, H.-J. Schulz, and N. Elmqvist. Agentic visualization: Extracting agent-based design patterns from visualization systems.IEEE Computer Graphics and Applications, 45(6):89–100, 2025. doi: 10.1109/MCG.2025.3607741 1, 9
-
[17]
V . Dibia. LIDA: A tool for automatic generation of grammar-agnostic visualizations and infographics using large language models. InProceed- ings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pp. 113–126, 2023. doi: 10.18653/v1/2023.acl-demo.11 1
-
[18]
Digital education council AI literacy frame- work
Digital Education Council. Digital education council AI literacy frame- work. Online, 2025. 9
2025
-
[19]
L. Dong and A. Crisan. Probing the visualization literacy of vision lan- guage models: the good, the bad, and the ugly. In2025 IEEE Visualization and Visual Analytics (VIS), pp. 6–10, 2025. doi: 10.48550/arXiv.2504. 05445 1, 2, 8
-
[20]
K. Gu, S. Palani, and V . Setlur. "I need to find that one chart": How data workers navigate, make sense of, and communicate analytical conversa- tions. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems (CHI ’26). ACM, 2026. doi: 10.48550/arXiv.2603. 00485 1, 2
-
[21]
K. Gu, R. Shang, T. Althoff, C. Wang, and S. M. Drucker. How do analysts understand and verify AI-assisted data analyses? InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24), art. no. 748, 22 pages, 2024. doi: 10.1145/3613904.3642497 1, 2
-
[22]
J. Hong, C. Seto, A. Fan, and R. Maciejewski. Do LLMs have visualization literacy? an evaluation on modified visualizations to test generalization in data interpretation.IEEE Transactions on Visualization and Computer Graphics, 31(10):7004–7018, 2025. doi: 10.1109/TVCG.2025.3536358 1, 2, 8
-
[23]
E. Horvitz. Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’99), pp. 159–166, 1999. doi: 10.1145/302979.303030 3
-
[24]
Huff.How to lie with statistics
D. Huff.How to lie with statistics. Penguin UK, 2023. 6, 8
2023
-
[25]
J. D. Hunter. Matplotlib: A 2D graphics environment.Computing in Science & Engineering, 9(3):90–95, 2007. doi: 10.1109/MCSE.2007.55 1
-
[26]
S. S. Y . Kim, Q. V . Liao, M. V orvoreanu, S. Ballard, and J. W. Vaughan. "I’m not sure, but...": Examining the impact of large language models’ uncertainty expression on user reliance and trust. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’24), pp. 822–835, 2024. doi: 10.1145/3630106.3658941 2, 5
-
[27]
S. S. Y . Kim, J. W. Vaughan, Q. V . Liao, T. Lombrozo, and O. Russakovsky. Fostering appropriate reliance on large language models: The role of explanations, sources, and inconsistencies. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25), art. no. 420, 19 pages, 2025. doi: 10.1145/3706598.3714020 2, 8
-
[29]
C. Knoll, T. Möller, K. Gregory, and L. Koesten. The gulf of interpretation: From chart to message and back again. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25), art. no. 695, 17 pages, 2025. doi: 10.1145/3706598.3713413 1
-
[31]
H.-P. H. Lee, A. Sarkar, L. Tankelevitch, I. Drosos, S. Rintel, R. Banks et al. The impact of generative AI on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25), CHI ’25, art. no. 1121, 22 pages,...
-
[32]
H. Li, Y . Wang, and H. Qu. Where are we so far? understanding data storytelling tools from the perspective of human-AI collaboration. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24), art. no. 845, 19 pages, 2024. doi: 10.1145/3613904. 3642726 9
-
[33]
Q. V . Liao, D. Gruen, and S. Miller. Questioning the AI: Informing design practices for explainable AI user experiences. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI ’20), CHI ’20, pp. 1–15, 2020. doi: 10.1145/3313831.3376590 8
-
[34]
C. Liu, C. Da, X. Long, Y . Yang, Y . Zhang, and Y . Wang. SimVecVis: A dataset for enhancing MLLMs in visualization understanding. In2025 IEEE Visualization and Visual Analytics (VIS), pp. 26–30, 2025. doi: 10. 1109/VIS60296.2025.00010 1
arXiv 2025
-
[35]
L. Y .-H. Lo, A. Gupta, K. Shigyo, A. Wu, E. Bertini, and H. Qu. Misin- formed by visualization: What do we learn from misinformative visualiza- tions?Computer Graphics Forum, 41(3):515–525, 2022. doi: 10.1111/cgf .14559 3, 4, 8
work page doi:10.1111/cgf 2022
-
[36]
R. Lou, K. Zhang, and W. Yin. Large language model instruction follow- ing: A survey of progresses and challenges.Computational Linguistics, 50(3):1053–1095, Sept. 2024. doi: 10.1162/coli_a_00523 3
-
[37]
Lundgard and A
A. Lundgard and A. Satyanarayan. Accessible visualization via natural language descriptions: A four-level model of semantic content.IEEE Transactions on Visualization and Computer Graphics, 28(1):1073–1083,
-
[38]
doi: 10.1109/TVCG.2021.3114770 3, 5
-
[39]
P. Maddigan and T. Susnjak. Chat2VIS: Generating data visualizations via natural language using chatgpt, codex and gpt-3 large language mod- els.IEEE Access, 11:45181–45193, 2023. doi: 10.1109/ACCESS.2023. 3274199 1
-
[40]
R. Mahbub, M. S. Islam, M. T. R. Laskar, M. Rahman, M. T. Nayeem, and E. Hoque. The perils of chart deception: How misleading visualizations affect Vision-Language models. In2025 IEEE Visualization and Visual Analytics (VIS), pp. 6–10, 2025. doi: 10.1109/VIS60296.2025.00006 1, 2, 8
-
[41]
A. Masry, M. S. Islam, M. Ahmed, A. Bajaj, F. Kabir, A. Kartha et al. ChartQAPro: A more diverse and challenging benchmark for chart question answering, 2025. doi: 10.48550/arXiv.2504.05506 1
-
[42]
Microsoft Power BI desktop
Microsoft Corporation. Microsoft Power BI desktop. https://powerbi. microsoft.com, 2026. 1
2026
-
[43]
K. Mukherjee, D. Ren, D. Moritz, and Y . Assogba. EncQA: Benchmarking vision-language models on visual encodings for charts.IEEE Transactions on Visualization and Computer Graphics, pp. 1–11, 2025. doi: 10.1109/ TVCG.2025.3634249 1
arXiv 2025
-
[44]
Chatgpt.https://chat.openai.com/, 2026
OpenAI. Chatgpt.https://chat.openai.com/, 2026. 1, 2
2026
-
[45]
S. Palani and V . Setlur. Lexara: A user-centered toolkit for evaluating large language models for conversational visual analytics. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems (CHI ’26). ACM, 2026. doi: 10.48550/arXiv.2603.05832 9
-
[46]
S. Passi. Agentic AI has a human oversight problem, Sept. 2025. Available at SSRN. doi: 10.2139/ssrn.5529058 9
-
[47]
Passi, S
S. Passi, S. Dhanorkar, and M. V orvoreanu.Addressing Overreliance on AI, pp. 1–34. Springer Nature Singapore, Singapore, 2025. doi: 10. 1007/978-981-97-8440-0_98-1 1, 2, 8, 9
2025
-
[48]
M. Radensky, J. A. Séguin, J. S. Lim, K. Olson, and R. Geiger. “I think you might like this”: Exploring effects of confidence signal patterns on trust in and reliance on conversational recommender systems. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’23), pp. 792–804, 2023. doi: 10.1145/3593013.3594043 2
-
[49]
S. Sah, R. Mitra, A. Narechania, A. Endert, J. Stasko, and W. Dou. Generat- ing Analytic Specifications for Data Visualization from Natural Language Queries using Large Language Models. Presented at the NLVIZ Workshop, IEEE VIS 2024, 2024. 1, 2
2024
-
[50]
A. Satyanarayan, D. Moritz, K. Wongsuphasawat, and J. Heer. Vega-Lite: A grammar of interactive graphics.IEEE Transactions on Visualization and Computer Graphics, 23(1):341–350, 2017. doi: 10.1109/TVCG.2016. 2599030 1
-
[51]
S. Shin, S. Hong, and N. Elmqvist. Visualizationary: Automating design feedback for visualization designers using large language models.IEEE Transactions on Visualization and Computer Graphics, 31(10):8796–8813,
-
[52]
doi: 10.1109/TVCG.2025.3579700 2
-
[53]
S. Shin, I. Na, and N. Elmqvist. Drillboards: Adaptive visualization dashboards for dynamic personalization of visualization experiences.IEEE Transactions on Visualization and Computer Graphics, 31(10):7196–7210,
-
[54]
doi: 10.1109/TVCG.2025.3542606 9
-
[55]
A. Simkute, L. Tankelevitch, V . Kewenig, A. E. Scott, A. Sellen, and S. Rintel. Ironies of generative AI: Understanding and mitigating productivity loss in human-AI interaction.International Journal of Human–Computer Interaction, 41(5):2898–2919, 2025. doi: 10.1080/ 10447318.2024.2405782 9
arXiv 2025
-
[56]
A. Srinivasan, N. Nyapathy, B. Lee, S. M. Drucker, and J. Stasko. Col- lecting and characterizing natural language utterances for specifying data visualizations. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI ’21), art. no. 464, 10 pages, 2021. doi: 10.1145/3411764.3445400 2
-
[57]
Tableau desktop
Tableau Software, LLC. Tableau desktop. https://www.tableau.com,
-
[58]
L. Tankelevitch, V . Kewenig, A. Simkute, A. E. Scott, A. Sarkar, A. Sellen et al. The metacognitive demands and opportunities of generative AI. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, art. no. 680, 24 pages, 2024. doi: 10.1145/3613904.3642902 2
-
[59]
Y . Tian, W. Cui, D. Deng, X. Yi, Y . Yang, H. Zhang et al. ChartGPT: Leveraging LLMs to generate charts from abstract natural language.IEEE Transactions on Visualization and Computer Graphics, 31(3):1731–1745,
-
[60]
doi: 10.1109/TVCG.2024.3368621 1, 2
-
[61]
P. Vaithilingam, E. L. Glassman, J. P. Inala, and C. Wang. Dynavis: Dy- namically synthesized ui widgets for visualization editing. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24), art. no. 985, 17 pages, 2024. doi: 10.1145/3613904.3642639 9
-
[62]
C. Wang, J. Thompson, and B. Lee. Data Formulator: AI-powered concept- driven visualization authoring.IEEE Transactions on Visualization and Computer Graphics, 30(1):1128–1138, 2024. doi: 10.1109/TVCG.2023. 3326585 7
-
[63]
H. W. Wang, J. Hoffswell, S. M. Thazin Thane, V . S. Bursztyn, and C. X. Bearfield. How aligned are human chart takeaways and LLM predictions? a case study on bar charts with varying layouts.IEEE Transactions on Visualization and Computer Graphics, 31(1):536–546, 2025. doi: 10. 1109/TVCG.2024.3456378 8
arXiv 2025
-
[64]
J. Zamfirescu-Pereira, R. Y . Wong, B. Hartmann, and Q. Yang. Why johnny can’t prompt: How non-AI experts try (and fail) to design LLM prompts. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23), art. no. 437, 21 pages, 2023. doi: 10. 1145/3544548.3581388 2
arXiv 2023
-
[65]
Y . Zhao, X. Shu, L. Fan, L. Gao, Y . Zhang, and S. Chen. ProactiveV A: Proactive visual analytics with llm-based ui agent.IEEE Transactions on Visualization and Computer Graphics, 32(1):451–461, 2026. doi: 10. 1109/TVCG.2025.3642628 3, 9
arXiv 2026
-
[66]
Y . Zhao, J. Wang, L. Xiang, X. Zhang, Z. Guo, C. Turkay et al. LightV A: Lightweight visual analytics with LLM agent-based task planning and execution.IEEE Transactions on Visualization and Computer Graphics, 31(9):6162–6177, 2025. doi: 10.1109/TVCG.2024.3496112 1, 9
-
[67]
J. Zhou, R. Li, J. Tang, T. Tang, H. Li, W. Cui et al. Understanding nonlin- ear collaboration between human and AI agents: A co-design framework for creative design. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24), art. no. 170, 16 pages, 2024. doi: 10.1145/3613904.3642812 9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.