Accuracy and Satisfaction in Multi-Turn LLM Dialogues for NFR Assessment
Pith reviewed 2026-06-25 23:10 UTC · model grok-4.3
The pith
Developers tend to agree with LLM assessments of non-functional requirements, yet these assessments show low accuracy compared to expert ground truth, and user satisfaction decreases with longer responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
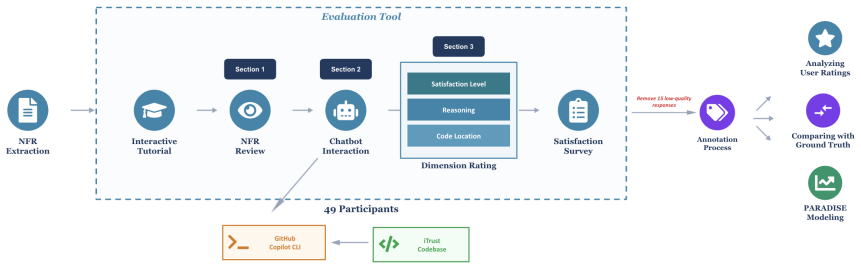
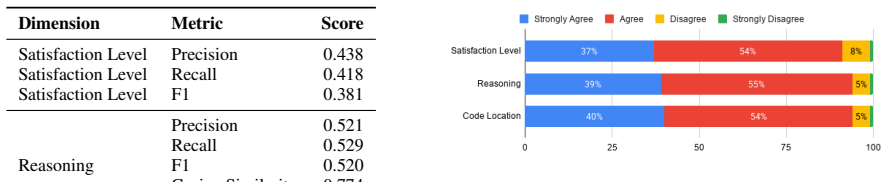
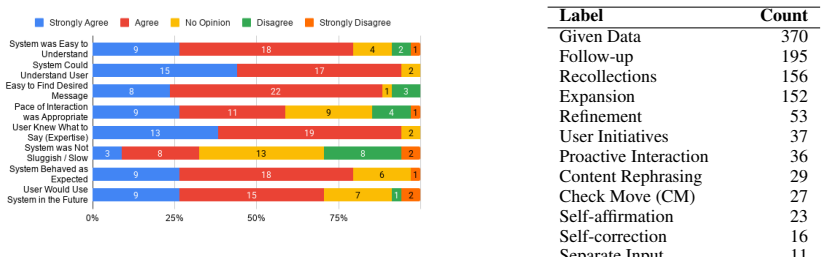
Through experiments with 49 programmers engaging in multi-turn dialogues with an LLM agent on 148 NFRs derived from HIPAA regulations in the iTrust system, the authors establish that developer agreement with LLM outputs is high across three assessment dimensions, but accuracy relative to expert ground truth is low. They further model satisfaction and determine that longer system responses and more information-providing turns reduce satisfaction while proactive interactions enhance it.
What carries the argument
The multi-turn dialogue process for NFR assessment, involving requirement satisfaction level, reasoning, and code localization, with a statistical model of user satisfaction based on response characteristics.
If this is right
- LLM-based systems for NFR assessment require enhancements to achieve higher accuracy against expert standards.
- Dialogue design should prioritize shorter responses and proactive interactions to improve user satisfaction.
- Evaluation of LLM tools should incorporate multi-turn interaction quality in addition to functional correctness.
- Benchmarks for NFR handling need to account for context-dependence and vagueness in requirements like regulatory compliance.
Where Pith is reading between the lines
- If the low accuracy persists, it may indicate a need for LLMs to incorporate more domain-specific knowledge or code analysis capabilities for NFRs.
- These satisfaction patterns could be tested in other requirement domains such as security or performance to see if they generalize.
- The study setup suggests potential for hybrid human-LLM workflows where experts validate initial assessments.
Load-bearing premise
The ground truth provided by experts for the 148 NFRs serves as an accurate and objective standard, and the 49 programmers' interactions represent typical developer use of LLM tools for such assessments.
What would settle it
Re-evaluation of the assessments by a different set of experts showing high agreement with the LLM outputs instead of low accuracy, or a satisfaction study where response length does not negatively correlate with user ratings.
Figures

read the original abstract
LLM-based dialogue assistants have become mainstream tools for software developers, yet current evaluation benchmarks focus exclusively on functional correctness. This leaves a critical gap in assessing the quality and accuracy of these conversations when handling Non-Functional Requirements (NFRs), which are inherently vague, context-dependent, and involve many parts of a program. Evaluating how well these systems support collaborative reasoning about NFRs requires methods that go beyond single-turn accuracy to capture both the correctness of the system's outputs and the quality of the multi-turn interaction. In this paper, we investigate the accuracy and quality of multi-turn conversations between developers and an LLM-based agent in the domain of Health Insurance Portability and Accountability Act (HIPAA) regulatory compliance. We hired 49 programmers to interact with GitHub Copilot to assess 148 HIPAA-derived NFRs against the iTrust codebase, a system designed to comply with HIPAA regulations, across three dimensions: requirement satisfaction level, reasoning, and code localization. We find that developers tend to agree with LLM assessments, but accuracy against expert ground truth is low. We model user satisfaction and find that longer system responses and more information-providing turns negatively affect user satisfaction, whereas proactive interactions positively affect it. Our findings provide insights for designing LLM-based dialogue systems that support NFR assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an empirical user study in which 49 hired programmers interacted with GitHub Copilot across 148 HIPAA-derived NFRs in the iTrust codebase. Dialogues were scored on three dimensions (requirement satisfaction level, reasoning, and code localization) against expert ground truth; the authors claim developers tend to agree with LLM assessments yet accuracy versus that ground truth is low. A separate model of user satisfaction finds negative effects from longer system responses and information-providing turns and positive effects from proactive interactions.
Significance. If the expert ground truth proves reliable and the participant sample representative, the work would supply concrete, actionable evidence on the limitations of current LLM dialogue tools for vague, multi-component NFR assessment and would directly inform design choices (response length, proactivity) that improve developer satisfaction.
major comments (3)
- [Abstract / Methods] Abstract and Methods (study design): the construction of the expert ground truth for the 148 NFRs is not described—no expert count, qualifications, annotation protocol, or inter-rater reliability statistics are supplied for the three scored dimensions. Because NFRs are explicitly characterized as “inherently vague, context-dependent,” the headline claim of “low accuracy against expert ground truth” cannot be evaluated without this information; modest expert agreement would render the reported developer-LLM mismatch indistinguishable from GT noise.
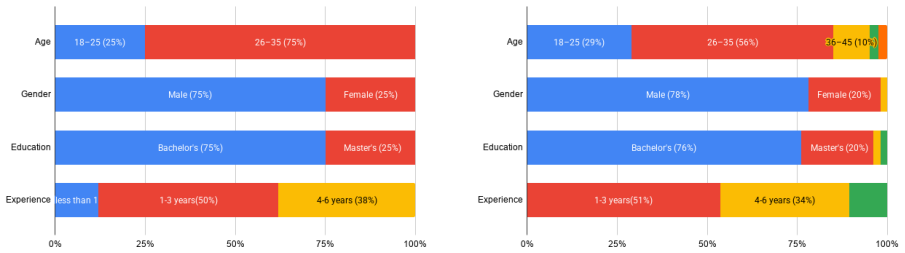
- [Abstract / Methods] Abstract and Methods: no exclusion criteria, bias controls, or demographic details are given for the 49 hired programmers, nor is any argument offered that their recorded multi-turn traces are representative of typical developer-LLM NFR-assessment dialogues. This directly affects the generalizability of both the accuracy and satisfaction findings.
- [Satisfaction Modeling] Satisfaction modeling section: the statistical approach used to model user satisfaction (regression type, variable definitions, handling of repeated measures, model fit statistics) is not reported, preventing assessment of the claimed negative effects of response length and information-providing turns or the positive effect of proactive interactions.
minor comments (1)
- [Abstract] The abstract states three scored dimensions but does not clarify whether the same three dimensions were used for both the developer-LLM agreement analysis and the expert-ground-truth accuracy analysis.
Simulated Author's Rebuttal
Thank you for the detailed review. We appreciate the opportunity to clarify and strengthen the manuscript. We address each of the major comments below, and will make revisions to incorporate additional details as requested.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods (study design): the construction of the expert ground truth for the 148 NFRs is not described—no expert count, qualifications, annotation protocol, or inter-rater reliability statistics are supplied for the three scored dimensions. Because NFRs are explicitly characterized as “inherently vague, context-dependent,” the headline claim of “low accuracy against expert ground truth” cannot be evaluated without this information; modest expert agreement would render the reported developer-LLM mismatch indistinguishable from GT noise.
Authors: We agree that the details of how the expert ground truth was constructed are essential for interpreting the accuracy results, particularly given the acknowledged vagueness of NFRs. In the original submission, these details were omitted to keep the manuscript concise, but we will add a new subsection in the Methods section titled 'Expert Ground Truth Construction' that specifies: three experts with backgrounds in software engineering and regulatory compliance were recruited; they independently scored each NFR on the three dimensions using a standardized rubric; disagreements were resolved through discussion; and inter-rater reliability was calculated using Cohen's kappa (values will be reported, e.g., >0.7 for all dimensions). This will allow readers to evaluate the reliability of the ground truth. revision: yes
-
Referee: [Abstract / Methods] Abstract and Methods: no exclusion criteria, bias controls, or demographic details are given for the 49 hired programmers, nor is any argument offered that their recorded multi-turn traces are representative of typical developer-LLM NFR-assessment dialogues. This directly affects the generalizability of both the accuracy and satisfaction findings.
Authors: We will revise the Methods section to include participant demographics (collected via pre-study survey: average years of programming experience, age range, gender distribution), exclusion criteria (participants were required to have at least basic programming knowledge and familiarity with web applications; no other exclusions), and bias controls (random assignment of NFRs to participants, use of standardized interface). Additionally, we will add a paragraph discussing limitations and representativeness, noting that while the sample was recruited via an online platform, the range of experience levels (from 2 to 15+ years) provides some diversity, though we acknowledge it may not fully represent all developer populations. revision: yes
-
Referee: [Satisfaction Modeling] Satisfaction modeling section: the statistical approach used to model user satisfaction (regression type, variable definitions, handling of repeated measures, model fit statistics) is not reported, preventing assessment of the claimed negative effects of response length and information-providing turns or the positive effect of proactive interactions.
Authors: We will expand the 'Satisfaction Modeling' section to provide full details on the statistical methods. Specifically, we used a linear mixed-effects regression model to account for repeated measures within participants (random intercepts for each developer). Variables were defined as follows: response length (number of tokens in system response), information-providing turns (binary indicator for turns that provide new information), proactive interactions (binary for turns where the system initiates without user prompt). We will report model coefficients, standard errors, p-values, and fit statistics including marginal and conditional R-squared, as well as AIC/BIC for model comparison. This will substantiate the reported effects. revision: yes
Circularity Check
Empirical user study with no derivation chain or self-referential reductions
full rationale
The paper describes an empirical study: 49 programmers interact with GitHub Copilot on 148 NFRs, outcomes are compared to expert ground truth, and satisfaction is modeled from recorded interaction features. No equations, fitted parameters renamed as predictions, uniqueness theorems, or ansatzes appear in the provided text. Results rest on participant data and external expert labels rather than any closed derivation that reduces outputs to inputs by construction. Self-citations, if present, are not load-bearing for the central claims.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert ground truth provides an objective and accurate measure of NFR satisfaction level, reasoning quality, and code localization.
- domain assumption The 49 programmers and their multi-turn interactions are representative of real developer use of LLMs for NFR assessment tasks.
Reference graph
Works this paper leans on
-
[1]
2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE) , pages=
Large language models for software engineering: Survey and open problems , author=. 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE) , pages=. 2023 , organization=
2023
-
[2]
IEEE Software , volume=
Application of large language models to software engineering tasks: Opportunities, risks, and implications , author=. IEEE Software , volume=. 2023 , publisher=
2023
-
[3]
arXiv preprint arXiv:2312.15223 , year=
A survey on large language models for software engineering , author=. arXiv preprint arXiv:2312.15223 , year=
-
[4]
arXiv preprint arXiv:2006.06143 , year=
Emora stdm: A versatile framework for innovative dialogue system development , author=. arXiv preprint arXiv:2006.06143 , year=
arXiv 2006
-
[5]
Constant, constant, multi-tasking craziness
" Constant, constant, multi-tasking craziness" managing multiple working spheres , author=. Proceedings of the SIGCHI conference on Human factors in computing systems , pages=
-
[6]
Proceedings of the 28th international conference on Software engineering , pages=
Maintaining mental models: a study of developer work habits , author=. Proceedings of the 28th international conference on Software engineering , pages=
-
[7]
Journal of Organizational Behavior: The International Journal of Industrial, Occupational and Organizational Psychology and Behavior , volume=
Who's helping whom? Layers of culture and workplace behavior , author=. Journal of Organizational Behavior: The International Journal of Industrial, Occupational and Organizational Psychology and Behavior , volume=. 2002 , publisher=
2002
-
[8]
2012 34th International Conference on Software Engineering (ICSE) , pages=
How do professional developers comprehend software? , author=. 2012 34th International Conference on Software Engineering (ICSE) , pages=. 2012 , organization=
2012
-
[9]
IEEE Transactions on Software Engineering , volume=
Asking and answering questions during a programming change task , author=. IEEE Transactions on Software Engineering , volume=. 2008 , publisher=
2008
-
[10]
arXiv e-prints , pages=
Sharp Tools: How Developers Wield Agentic AI in Real Software Engineering Tasks , author=. arXiv e-prints , pages=
-
[11]
arXiv preprint arXiv:2409.02977 , year=
Large language model-based agents for software engineering: A survey , author=. arXiv preprint arXiv:2409.02977 , year=
-
[12]
2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=
Large language models are few-shot testers: Exploring llm-based general bug reproduction , author=. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=. 2023 , organization=
2023
-
[13]
arXiv preprint arXiv:2411.10213 , year=
An empirical study on llm-based agents for automated bug fixing , author=. arXiv preprint arXiv:2411.10213 , year=
-
[14]
2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP) , pages=
How is google using ai for internal code migrations? , author=. 2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP) , pages=. 2025 , organization=
2025
-
[15]
arXiv preprint arXiv:2501.07531 , year=
Evaluating agent-based program repair at google , author=. arXiv preprint arXiv:2501.07531 , year=
-
[16]
arXiv preprint arXiv:2310.06770 , year=
Swe-bench: Can language models resolve real-world github issues? , author=. arXiv preprint arXiv:2310.06770 , year=
-
[17]
arXiv preprint arXiv:2403.07974 , year=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. arXiv preprint arXiv:2403.07974 , year=
-
[18]
2024 , month =
o1 tops aider's new polyglot leaderboard , howpublished =. 2024 , month =
2024
-
[19]
Rethinking the notion of non-functional requirements , author=. Proc. Third World Congress for Software Quality , volume=
-
[20]
Proceedings of the 2010 ACM symposium on applied computing , pages=
An investigation into the notion of non-functional requirements , author=. Proceedings of the 2010 ACM symposium on applied computing , pages=
2010
-
[21]
Generative AI for Effective Software Development , pages=
Advancing requirements engineering through generative ai: Assessing the role of llms , author=. Generative AI for Effective Software Development , pages=. 2024 , publisher=
2024
-
[22]
2024 IEEE International Systems Conference (SysCon) , pages=
Success Factors in the Specification of Operational Scenarios-An Industrial Perspective , author=. 2024 IEEE International Systems Conference (SysCon) , pages=. 2024 , organization=
2024
-
[23]
Computational Linguistics , volume=
The PARADISE evaluation framework: Issues and findings , author=. Computational Linguistics , volume=. 2006 , publisher=
2006
-
[24]
arXiv preprint arXiv:2503.13657 , year=
Why do multi-agent llm systems fail? , author=. arXiv preprint arXiv:2503.13657 , year=
-
[25]
arXiv preprint arXiv:1306.4134 , year=
Dialogue system: A brief review , author=. arXiv preprint arXiv:1306.4134 , year=
-
[26]
Artificial Intelligence Review , volume=
Survey on evaluation methods for dialogue systems , author=. Artificial Intelligence Review , volume=. 2021 , publisher=
2021
-
[27]
Natural Language Engineering , volume=
Towards developing general models of usability with PARADISE , author=. Natural Language Engineering , volume=. 2000 , publisher=
2000
-
[28]
35th Annual Meeting of the Association for Computational Linguistics and 8th Conference of the European Chapter of the Association for Computational Linguistics , pages=
PARADISE: A framework for evaluating spoken dialogue agents , author=. 35th Annual Meeting of the Association for Computational Linguistics and 8th Conference of the European Chapter of the Association for Computational Linguistics , pages=
-
[29]
, author=
DARPA communicator evaluation: progress from 2000 to 2001. , author=. Interspeech , pages=
2000
-
[30]
Journal of biomedical informatics , volume=
Health dialog systems for patients and consumers , author=. Journal of biomedical informatics , volume=. 2006 , publisher=
2006
-
[31]
Proceedings of the Human Language Technology Conference of the NAACL, Main Conference , pages=
Modelling user satisfaction and student learning in a spoken dialogue tutoring system with generic, tutoring, and user affect parameters , author=. Proceedings of the Human Language Technology Conference of the NAACL, Main Conference , pages=
-
[32]
arXiv preprint arXiv:2503.22458 , year=
Evaluating llm-based agents for multi-turn conversations: A survey , author=. arXiv preprint arXiv:2503.22458 , year=
-
[33]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[34]
Proceedings of the third conference on machine translation: Research papers , pages=
A call for clarity in reporting BLEU scores , author=. Proceedings of the third conference on machine translation: Research papers , pages=
-
[35]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[36]
Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments , author=. Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
-
[37]
Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
How not to evaluate your dialogue system: An empirical study of unsupervised evaluation metrics for dialogue response generation , author=. Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
2016
-
[38]
arXiv preprint arXiv:1904.09675 , year=
Bertscore: Evaluating text generation with bert , author=. arXiv preprint arXiv:1904.09675 , year=
Pith/arXiv arXiv 1904
-
[39]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Dialogue response ranking training with large-scale human feedback data , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[40]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Deconstruct to reconstruct a configurable evaluation metric for open-domain dialogue systems , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[41]
arXiv preprint arXiv:2308.04624 , year=
Benchmarking LLM powered chatbots: methods and metrics , author=. arXiv preprint arXiv:2308.04624 , year=
-
[42]
Proceedings of the AAAI conference on artificial intelligence , volume=
Ubar: Towards fully end-to-end task-oriented dialog system with gpt-2 , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[43]
arXiv preprint arXiv:2410.00526 , year=
Benchmarking large language models for conversational question answering in multi-instructional documents , author=. arXiv preprint arXiv:2410.00526 , year=
-
[44]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Can large language models be an alternative to human evaluations? , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[45]
Findings of the association for computational linguistics: EMNLP 2023 , pages=
A closer look into using large language models for automatic evaluation , author=. Findings of the association for computational linguistics: EMNLP 2023 , pages=
2023
-
[46]
Proceedings of the 2022 conference of the North American Chapter of the Association for Computational Linguistics: human language technologies , pages=
Reference-free summarization evaluation via semantic correlation and compression ratio , author=. Proceedings of the 2022 conference of the North American Chapter of the Association for Computational Linguistics: human language technologies , pages=
2022
-
[47]
Proceedings of the 4th Workshop on NLP for Conversational AI , pages=
Human evaluation of conversations is an open problem: comparing the sensitivity of various methods for evaluating dialogue agents , author=. Proceedings of the 4th Workshop on NLP for Conversational AI , pages=
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A comprehensive analysis of the effectiveness of large language models as automatic dialogue evaluators , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[49]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Sedareval: Automated evaluation using self-adaptive rubrics , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[50]
Proceedings of the 5th Workshop on NLP for Conversational AI (NLP4ConvAI 2023) , pages=
Llm-eval: Unified multi-dimensional automatic evaluation for open-domain conversations with large language models , author=. Proceedings of the 5th Workshop on NLP for Conversational AI (NLP4ConvAI 2023) , pages=
2023
-
[51]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
MEEP: Is this engaging? prompting large language models for dialogue evaluation in multilingual settings , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[52]
Asian Conference on Intelligent Information and Database Systems , pages=
An Evaluation of the Conversation Agent System , author=. Asian Conference on Intelligent Information and Database Systems , pages=. 2016 , organization=
2016
-
[53]
Knowledge , volume=
Do you ever get off track in a conversation? the conversational system’s anatomy and evaluation metrics , author=. Knowledge , volume=. 2022 , publisher=
2022
-
[54]
Journal of Physics: Conference Series , volume=
Multi-turn response selection in retrieval based chatbots with hierarchical residual matching network , author=. Journal of Physics: Conference Series , volume=. 2021 , organization=
2021
-
[55]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Fb-bench: A fine-grained multi-task benchmark for evaluating llms’ responsiveness to human feedback , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[56]
The annals of statistics , volume=
MM algorithms for generalized Bradley-Terry models , author=. The annals of statistics , volume=. 2004 , publisher=
2004
-
[57]
arXiv preprint arXiv:2308.07201 , year=
Chateval: Towards better llm-based evaluators through multi-agent debate , author=. arXiv preprint arXiv:2308.07201 , year=
-
[58]
arXiv preprint arXiv:2410.10934 , year=
Agent-as-a-judge: Evaluate agents with agents , author=. arXiv preprint arXiv:2410.10934 , year=
-
[59]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
Codebert: A pre-trained model for programming and natural languages , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
2020
-
[60]
Proceedings of the 28th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering , pages=
Intellicode compose: Code generation using transformer , author=. Proceedings of the 28th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering , pages=
-
[61]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[62]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[63]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[64]
Science , volume=
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
2022
-
[65]
arXiv preprint arXiv:2203.13474 , year=
Codegen: An open large language model for code with multi-turn program synthesis , author=. arXiv preprint arXiv:2203.13474 , year=
-
[66]
5-coder technical report , author=
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
-
[67]
2025 , note =
GitHub Copilot Statistics , author =. 2025 , note =
2025
-
[68]
GitHub Copilot Surpasses 20 Million All-Time Users, Accelerates Enterprise Adoption , howpublished =
-
[69]
arXiv preprint arXiv:2105.09938 , year=
Measuring coding challenge competence with apps , author=. arXiv preprint arXiv:2105.09938 , year=
-
[70]
Proceedings of the 15th international conference on mining software repositories , pages=
Learning to mine aligned code and natural language pairs from stack overflow , author=. Proceedings of the 15th international conference on mining software repositories , pages=
-
[71]
2023 IEEE International Conference on Software Maintenance and Evolution (ICSME) , pages=
Benchmarking causal study to interpret large language models for source code , author=. 2023 IEEE International Conference on Software Maintenance and Evolution (ICSME) , pages=. 2023 , organization=
2023
-
[72]
arXiv preprint arXiv:2108.07732 , year=
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[73]
Proceedings
The education of a software engineer , author=. Proceedings. 19th International Conference on Automated Software Engineering, 2004. , pages=. 2004 , organization=
2004
-
[74]
Information and Software Technology , volume=
Communication and co-ordination practices in software engineering projects , author=. Information and Software Technology , volume=. 2004 , publisher=
2004
-
[75]
Collaborative software engineering , pages=
Collaborative software engineering: challenges and prospects , author=. Collaborative software engineering , pages=. 2010 , publisher=
2010
-
[76]
2005 , publisher=
Software engineering: a practitioner's approach , author=. 2005 , publisher=
2005
-
[77]
Future of Software Engineering (FOSE'07) , pages=
Collaboration in software engineering: A roadmap , author=. Future of Software Engineering (FOSE'07) , pages=. 2007 , organization=
2007
-
[78]
ACM Transactions on Software Engineering and Methodology , volume=
Humanevalcomm: Benchmarking the communication competence of code generation for llms and llm agents , author=. ACM Transactions on Software Engineering and Methodology , volume=. 2025 , publisher=
2025
-
[79]
arXiv preprint arXiv:2208.06213 , year=
What is it like to program with artificial intelligence? , author=. arXiv preprint arXiv:2208.06213 , year=
-
[80]
ACM Transactions on Software Engineering and Methodology , volume=
Refining chatgpt-generated code: Characterizing and mitigating code quality issues , author=. ACM Transactions on Software Engineering and Methodology , volume=. 2024 , publisher=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.