Symmetry-Aware Convex Shrinkage for High-Dimensional Covariance Estimation
Pith reviewed 2026-05-20 14:50 UTC · model grok-4.3
The pith
Selecting a symmetry group from held-out data and projecting the sample covariance onto it produces a shrinkage target that dominates Ledoit-Wolf under a sufficient-match condition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a two-tier procedure selecting a finite symmetry group from a candidate library via held-out negative log-likelihood, then forming a convex combination of the sample covariance with its Reynolds projection under that group, satisfies a quantitative sufficient-match condition under which the estimator dominates Ledoit-Wolf shrinkage in Frobenius mean-squared error, while also admitting a finite-sample regret bound for the held-out calibration of the convex weight and an oracle inequality for the data-driven group selection.
What carries the argument
The Reynolds projection of the sample covariance onto the matrices invariant under a data-selected finite symmetry group, serving as the structured target in an adaptively weighted convex shrinkage estimator.
Load-bearing premise
The held-out data used for group selection and weight calibration is independent of the training sample and representative of the same distribution so that negative log-likelihood reliably identifies a sufficiently matching symmetry group.
What would settle it
A synthetic covariance matrix with no symmetry match where the held-out procedure still selects a group yet the resulting estimator shows higher Frobenius mean-squared error than Ledoit-Wolf shrinkage.
Figures





























read the original abstract
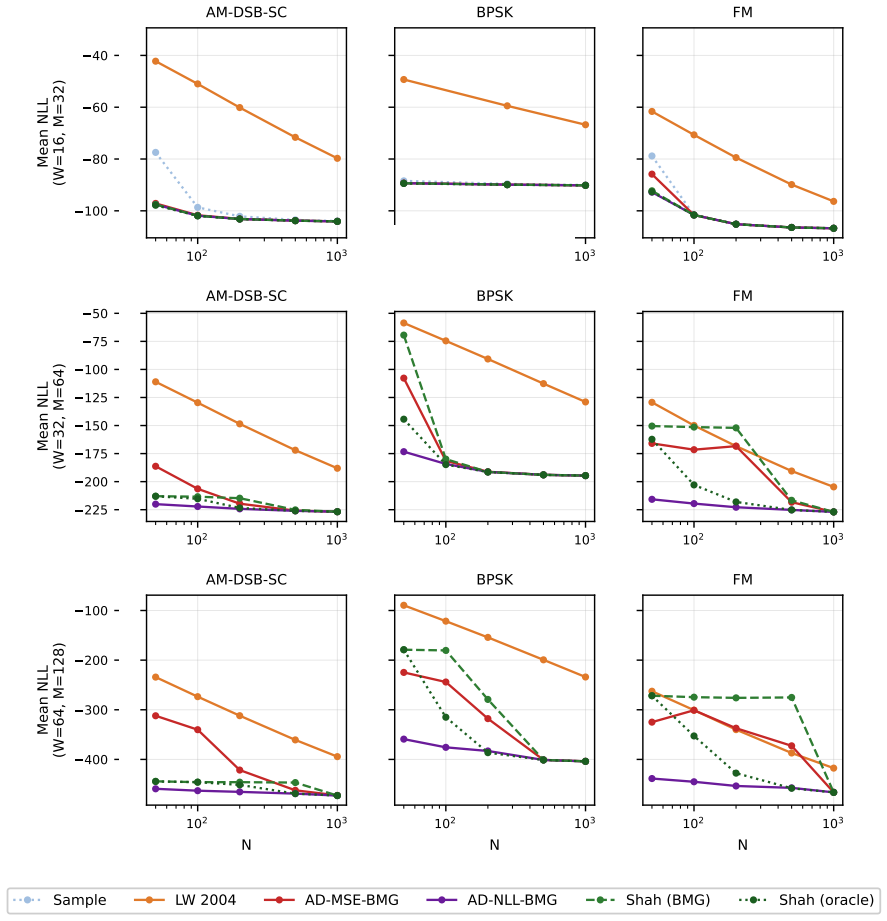
We develop a class of data-adaptive shrinkage estimators for high-dimensional covariance estimation in which the shrinkage target is a Reynolds projection of the sample covariance under a finite symmetry group selected from a candidate library by held-out predictive performance. The class generalizes the convex shrinkage estimator of Ledoit and Wolf by replacing the scalar-identity target with a structured target derived from a symmetry group when one is available, and generalizes the group-symmetric maximum-likelihood estimator of Shah and Chandrasekaran by combining structural targeting with adaptive convex shrinkage and by selecting the group from data rather than treating it as prespecified. A two-tier procedure performs the group selection: a universal per-candidate evaluation based on held-out negative log-likelihood, optionally preceded by a domain-specific step that constructs the candidate library from structural priors. We establish a finite-sample regret bound for the held-out calibration of the convex combination weight, an oracle inequality for the data-driven group selection, and a quantitative sufficient-match condition under which the proposed estimator dominates Ledoit-Wolf shrinkage in Frobenius mean-squared error. The procedure is illustrated on six real-data problems spanning finance (S&P~500 daily returns), climate (NOAA OISST sea-surface temperature anomalies), genomics (TCGA-BRCA gene expression), radio signal processing (RadioML 2018.A), astronomical imaging (Galaxy10 DECaLS), and natural image patches (CIFAR-10 with a CIFAR-10.1 distribution-shift companion). An empirical comparison is also made against the Bayesian permutation-symmetry estimator of Chojecki and colleagues. Outside the few-shot regime, where structural priors carry the most information per observation, Ledoit-Wolf shrinkage remains the appropriate baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops symmetry-aware convex shrinkage estimators for high-dimensional covariance estimation. It selects a symmetry group from a candidate library using held-out negative log-likelihood (optionally guided by domain priors), then forms a convex combination of the sample covariance and the Reynolds projection under the selected group. The approach generalizes Ledoit-Wolf shrinkage and prespecified group-symmetric MLE. It establishes a finite-sample regret bound for calibration of the convex weight, an oracle inequality for the data-driven group selection, and a quantitative sufficient-match condition under which the estimator dominates Ledoit-Wolf in Frobenius mean-squared error. The procedure is illustrated on six real datasets spanning finance, climate, genomics, radio signals, astronomy, and natural images, with comparisons to Ledoit-Wolf and a Bayesian permutation-symmetry estimator.
Significance. If the derivations hold, the finite-sample regret bound for the shrinkage weight and the oracle inequality for group selection constitute clear strengths, providing non-asymptotic guarantees that go beyond typical asymptotic analyses in high-dimensional covariance estimation. The sufficient-match condition offers a concrete route to dominance over Ledoit-Wolf when structural symmetry is present. The real-data illustrations across diverse domains demonstrate practical utility, though the strength of the dominance claim depends on how well the theory transfers to the non-Gaussian settings in the examples.
major comments (2)
- [the section deriving the sufficient-match condition] The section deriving the sufficient-match condition for Frobenius MSE dominance over Ledoit-Wolf: the condition is stated quantitatively, yet the group selection step minimizes held-out Gaussian negative log-likelihood. In the six real-data examples (daily returns, sea-surface temperatures, gene expression, radio signals, astronomical images, natural patches), the distributions are plausibly non-Gaussian, so the selected group need not satisfy the sufficient-match condition; this directly affects whether the dominance guarantee applies to the reported empirical comparisons.
- [the section stating the oracle inequality for group selection] The oracle inequality for data-driven group selection: it is presented as holding when the held-out NLL identifies a sufficiently matching group, but the paper does not provide a quantitative bound on the probability that NLL selection fails to recover a group satisfying the sufficient-match condition under non-Gaussianity or mild distribution shift (as in the CIFAR-10.1 companion). This is load-bearing for extending the theoretical claims to the real-data regime outside the few-shot setting.
minor comments (2)
- [notation and preliminaries] The definition of the Reynolds projection and its relation to the symmetry group should be stated explicitly with a short example in the notation section to aid readers without prior exposure to group-theoretic covariance models.
- [empirical illustrations] In the empirical section, the tables or figures comparing estimators should report the specific symmetry group selected for each dataset alongside the performance metrics to allow direct assessment of whether the sufficient-match condition is plausibly met.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We appreciate the positive assessment of the finite-sample regret bound, oracle inequality, and sufficient-match condition. We address each major comment below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: The section deriving the sufficient-match condition for Frobenius MSE dominance over Ledoit-Wolf: the condition is stated quantitatively, yet the group selection step minimizes held-out Gaussian negative log-likelihood. In the six real-data examples (daily returns, sea-surface temperatures, gene expression, radio signals, astronomical images, natural patches), the distributions are plausibly non-Gaussian, so the selected group need not satisfy the sufficient-match condition; this directly affects whether the dominance guarantee applies to the reported empirical comparisons.
Authors: We agree that the sufficient-match condition and associated dominance result are derived under modeling assumptions (including that the held-out NLL serves as a suitable surrogate for Frobenius risk) that are most directly justified in Gaussian or sub-Gaussian regimes. The real-data examples are presented as empirical illustrations rather than as formal verification of the dominance theorem. In the revision we will add an explicit caveat in the theoretical section and in the discussion of the experiments clarifying the scope of the guarantee. We will also insert a short controlled simulation study under non-Gaussian noise to illustrate when the selected group continues to yield improvement even if the quantitative sufficient-match condition is only approximately satisfied. revision: partial
-
Referee: The oracle inequality for data-driven group selection: it is presented as holding when the held-out NLL identifies a sufficiently matching group, but the paper does not provide a quantitative bound on the probability that NLL selection fails to recover a group satisfying the sufficient-match condition under non-Gaussianity or mild distribution shift (as in the CIFAR-10.1 companion). This is load-bearing for extending the theoretical claims to the real-data regime outside the few-shot setting.
Authors: The oracle inequality already bounds the excess risk of the data-driven selector relative to the oracle group without requiring that the selected group satisfy the sufficient-match condition with high probability. Introducing a separate high-probability bound on the event that NLL fails to recover a matching group would necessitate stronger assumptions on the degree of non-Gaussianity or distribution shift; such assumptions would limit rather than broaden the result. We therefore view the current oracle inequality as the appropriate non-asymptotic statement and will add a short clarifying remark distinguishing the roles of the oracle inequality and the sufficient-match condition. The real-data comparisons remain empirical demonstrations of practical utility. revision: no
Circularity Check
No significant circularity; derivation relies on independent held-out evaluation and mathematical bounds
full rationale
The paper's central results consist of a finite-sample regret bound on held-out calibration of the convex weight, an oracle inequality for data-driven group selection via held-out negative log-likelihood, and a quantitative sufficient-match condition for Frobenius dominance over Ledoit-Wolf. These are derived as mathematical statements that bound the procedure's risk relative to an oracle or under an explicit condition; they do not reduce by construction to the fitted values or selection criterion. The held-out NLL serves as an independent performance measure separate from the training sample, and the dominance claim is conditional rather than unconditional. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- convex shrinkage weight
axioms (1)
- domain assumption A finite symmetry group from the candidate library adequately represents the data structure.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the shrinkage target is a Reynolds projection of the sample covariance under a finite symmetry group selected from a candidate library by held-out predictive performance
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
quantitative sufficient-match condition under which the proposed estimator dominates Ledoit-Wolf shrinkage in Frobenius mean-squared error
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Peter J. Bickel and Elizaveta Levina. Covariance regularization by thresholding.Annals of Statistics, 36(6):2577–2604, 2008a. doi: 10.1214/08-AOS600. Peter J. Bickel and Elizaveta Levina. Regularized estimation of large covariance matrices.Annals of Statistics, 36(1):199–227, 2008b. doi: 10.1214/009053607000000758. Tony Cai and Weidong Liu. Adaptive thres...
-
[2]
doi: 10.1198/jasa.2011.tm10560. 96 Tony T. Cai and Harrison H. Zhou. Optimal rates of convergence for sparse covariance matrix estimation.Annals of Statistics, 40(5):2389–2420,
-
[3]
Center for Research in Security Prices
doi: 10.1214/12-AOS998. Center for Research in Security Prices. CRSP US Stock Database. Center for Research in Security Prices, Booth School of Business, The University of Chicago. Distributed via Wharton Research Data Services (WRDS),https://wrds-www.wharton.upenn.edu/.,
-
[4]
Adam Chojecki, Pawe l Morgen, and Bartosz Ko lodziejek
doi: 10.1109/TSP.2010.2053029. Adam Chojecki, Pawe l Morgen, and Bartosz Ko lodziejek. Learning permutation symmetry of a Gaussian vector with gips in R.Journal of Statistical Software, 112(7):1–38,
-
[5]
doi: 10.18637/jss.v112.i07. A. P. Dempster. Covariance selection.Biometrics, 28(1):157–175,
-
[6]
doi: 10.1038/s41587-020-0546-8. Gene H. Golub and Charles F. Van Loan.Matrix Computations. Johns Hopkins University Press, 4th edition,
-
[7]
doi: 10.1214/22-AOS2174. L. R. Haff. Empirical Bayes estimation of the multivariate normal covariance matrix.The Annals of Statistics, 8(3):586–597,
-
[8]
doi: 10.1111/j.1467-9868.2008.00666.x. Roger A. Horn and Charles R. Johnson.Matrix Analysis. Cambridge University Press, 2nd edition,
-
[9]
doi: 10.1175/JCLI-D-20-0166.1. Gordon James and Adalbert Kerber.The Representation Theory of the Symmetric Group, volume 16 ofEncyclopedia of Mathematics and Its Applications. Addison-Wesley,
-
[10]
Olivier Ledoit and Michael Wolf
doi: 10.1016/S0047-259X(03) 00096-4. Olivier Ledoit and Michael Wolf. Nonlinear shrinkage estimation of large-dimensional covariance matrices.Annals of Statistics, 40(2):1024–1060,
-
[11]
Olivier Ledoit and Michael Wolf
doi: 10.1214/12-AOS989. Olivier Ledoit and Michael Wolf. Analytical nonlinear shrinkage of large-dimensional covariance matrices.Annals of Statistics, 48(5):3043–3065,
-
[12]
doi: 10.1016/j.cels.2015.12.004. Karim Lounici. High-dimensional covariance matrix estimation with missing observations.Bernoulli, 20(3):1029–1058,
-
[13]
doi: 10.1070/SM1967v001n04ABEH001994. Timothy J. O’Shea, Tamoghna Roy, and T. Charles Clancy. Over-the-air deep learning based radio signal classification.IEEE Journal of Selected Topics in Signal Processing, 12(1):168–179,
-
[14]
Mohsen Pourahmadi.High-Dimensional Covariance Estimation: With High-Dimensional Data
doi: 10.1109/JSTSP.2018.2797022. Mohsen Pourahmadi.High-Dimensional Covariance Estimation: With High-Dimensional Data. Wiley,
-
[15]
98 Juliane Sch¨ afer and Korbinian Strimmer
doi: 10.1175/2007JCLI1824.1. 98 Juliane Sch¨ afer and Korbinian Strimmer. A shrinkage approach to large-scale covariance matrix estimation and implications for functional genomics.Statistical Applications in Genetics and Molecular Biology, 4(1),
-
[16]
Ilya Soloveychik, Dmitry Trushin, and Ami Wiesel
doi: 10.1214/12-EJS723. Ilya Soloveychik, Dmitry Trushin, and Ami Wiesel. Group symmetric robust covariance estimation. IEEE Transactions on Signal Processing, 64(1):244–257,
-
[17]
doi: 10.1109/TSP.2015.2486739. Charles Stein. Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. InProceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, volume 1, pages 197–206. University of California Press,
-
[18]
doi: 10.1007/BF01085007. Charles M. Stein. Estimation of the mean of a multivariate normal distribution.The Annals of Statistics, 9(6):1135–1151,
-
[19]
doi: 10.1038/nature11412. Mitchell A. Thornton. Algebraic diversity for high-dimensional covariance estimation, 2026a. Mitchell A. Thornton. Algebraic diversity for spectral estimation, 2026b. Roman Vershynin.High-Dimensional Probability: An Introduction with Applications in Data Science, volume 47 ofCambridge Series in Statistical and Probabilistic Mathe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.