WaveDetect: Robust Framework for Machine-Generated Text Detection via Wavelet Transform
Pith reviewed 2026-06-26 08:11 UTC · model grok-4.3
The pith
Modeling token probability sequences as signals and applying continuous wavelet transforms extracts spectral fingerprints that detect machine-generated text more accurately and robustly than prior approaches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WaveDetect treats the output of a language model as a probability signal, applies a differentiable Continuous Wavelet Transform to obtain multi-scale spectral features, and trains a classifier on those features; the resulting detector reports state-of-the-art accuracy on RAID, EvoBench, and Domain-Shift while remaining effective against adversarial perturbations, out-of-distribution topics, and LLMs that were not seen during training.
What carries the argument
The differentiable Continuous Wavelet Transform applied to the sequence of token probabilities, which produces scale-specific spectral coefficients that serve as the input features for classification.
If this is right
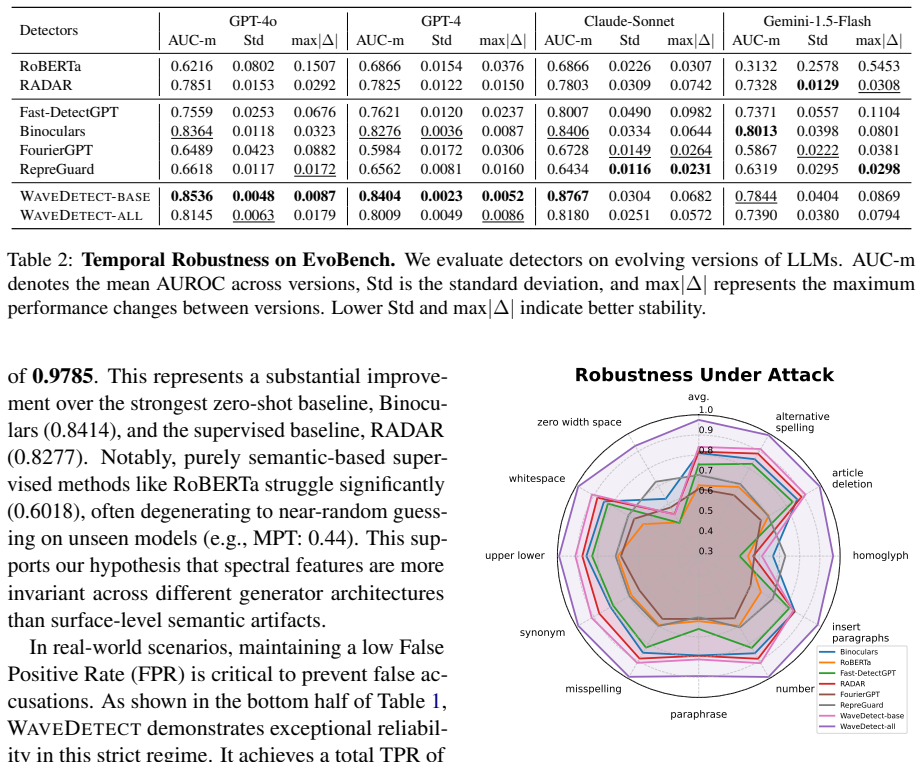
- Detection performance improves on three separate evaluation collections covering attacks, domain shifts, and temporal model evolution.
- The same spectral features remain discriminative when the underlying generator is replaced by an unseen model.
- End-to-end differentiability of the wavelet step allows the spectral extractor and classifier to be trained jointly.
- The approach does not rely on static token-level statistics that can be directly edited by an adversary.
Where Pith is reading between the lines
- The same signal-processing view could be tested on probability sequences from non-text generators such as image or audio models.
- A detector trained this way might still need periodic fine-tuning when entirely new architectures appear, but the required updates could be less frequent than for purely semantic detectors.
- Combining the wavelet features with existing semantic or watermark-based signals could be explored as a next step without changing the core spectral extraction step.
Load-bearing premise
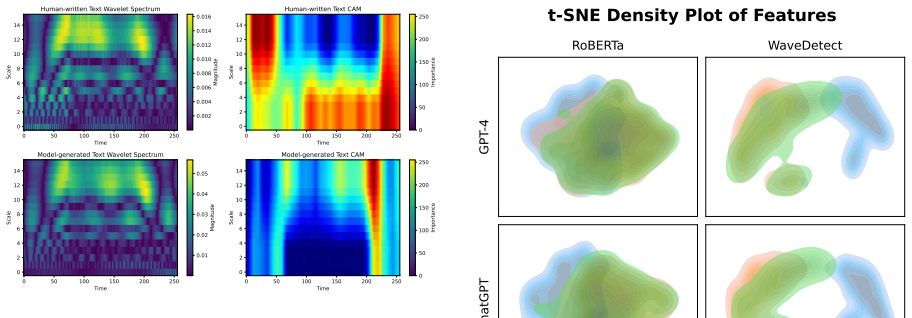
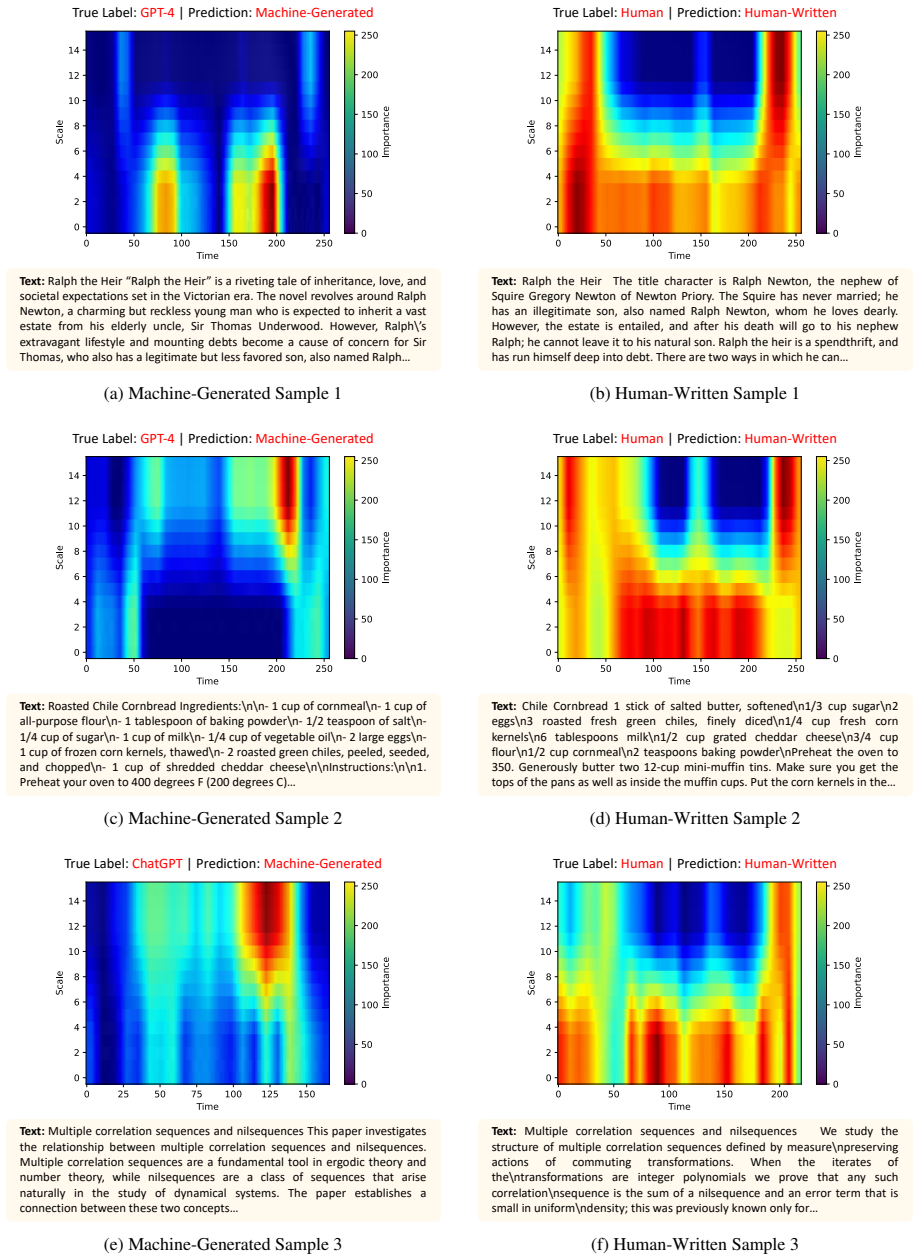
Machine-generated probability sequences contain frequency-domain patterns that differ systematically from human sequences and survive changes in wording, topic, and model version.
What would settle it
An experiment in which an adversary generates text whose wavelet coefficients on the probability signal are statistically indistinguishable from those of human text, or in which accuracy collapses on a new LLM released after the training cutoff.
Figures
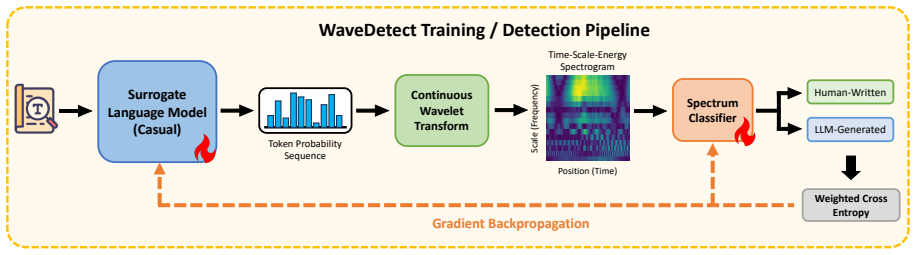
read the original abstract
As Large Language Models asymptotically approach human-level fluency in natural language generation, solely relying on surface-level semantic artifacts for detecting LLM-generated texts has become increasingly precarious. Existing detectors often falter when facing three critical challenges: adversarial perturbations, cross-domain shifts, and the rapid temporal evolution of the foundation model. To address these issues, we propose \wavedetect, a novel framework that reformulates text detection as a signal processing task within the time-frequency domain. Unlike previous methods that analyze static token probability distributions, \wavedetect models the generated output as a probability signal, upon which a differentiable Continuous Wavelet Transform is applied to convert them into learnable spectral representations. This process reveals the intrinsic ``spectral fingerprints'' in machine-generated texts--patterns that remain invisible in time domain. Comprehensive evaluations on three well-curated datasets (RAID, EvoBench, and Domain-Shift) show that our method achieves a new state-of-the-art. It not only achieves superior accuracy but also exhibits remarkable robustness against sophisticated attacks, generalization across out-of-distribution topics and unseen evolving LLMs. Our results validate the efficacy of spectral analysis as a promising paradigm for LLM-generated texts detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WaveDetect, a framework that reformulates machine-generated text detection as a signal-processing task: token-probability sequences are treated as signals, a differentiable Continuous Wavelet Transform is applied to produce learnable spectral representations, and these are used for classification. It reports new state-of-the-art accuracy together with robustness to adversarial perturbations, cross-domain shifts, and unseen evolving LLMs, evaluated on the RAID, EvoBench, and Domain-Shift datasets.
Significance. If the central empirical claims hold after proper controls, the work would demonstrate that time-frequency analysis can extract stable generation artifacts that survive domain shift and model evolution, offering a concrete alternative to purely semantic or statistical detectors. The differentiable CWT formulation is a potentially reusable technical contribution for other sequence-classification tasks.
major comments (3)
- [§3] §3 (Method): the probability signal construction is described only at a high level; it is not stated which surrogate model (or fixed set of models) supplies the logits for all test texts, nor whether that surrogate appears in the training distribution of the detector. This detail is load-bearing for the claim that the extracted wavelet coefficients capture intrinsic rather than model-specific artifacts.
- [§5.2–5.3] §5.2–5.3 (Experiments on EvoBench and unseen LLMs): no explicit statement is given that the detector was trained without exposure to the base models used in the “unseen evolving LLMs” test split, nor how attack strength was calibrated on RAID. Without these controls the generalization and robustness numbers cannot be interpreted as evidence for the spectral-fingerprint hypothesis.
- [Table 2] Table 2 (main results): the reported accuracy and robustness margins are presented without an ablation that replaces the wavelet front-end with a standard transformer classifier trained on the identical probability-signal input; the contribution of the CWT itself therefore remains unisolated.
minor comments (2)
- [Abstract] The abstract contains no numerical results or baseline names, which is inconsistent with the level of detail expected for a methods paper claiming SOTA.
- [§3.1] Notation for the CWT (scale, translation, mother wavelet) is introduced without an equation reference; readers must infer the exact differentiable implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, agreeing where clarifications or additions are needed, and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3] §3 (Method): the probability signal construction is described only at a high level; it is not stated which surrogate model (or fixed set of models) supplies the logits for all test texts, nor whether that surrogate appears in the training distribution of the detector. This detail is load-bearing for the claim that the extracted wavelet coefficients capture intrinsic rather than model-specific artifacts.
Authors: We agree that explicit details on the surrogate are necessary to support the claim of intrinsic spectral fingerprints. The current manuscript describes the process at a high level but omits the specific surrogate and its relationship to training data. In the revised version we will expand §3 with a new paragraph that names the surrogate model, states that it is fixed across all experiments, and confirms it is excluded from the detector's training distribution. This addition will directly address the concern and allow readers to evaluate whether the wavelet coefficients reflect model-agnostic artifacts. revision: yes
-
Referee: [§5.2–5.3] §5.2–5.3 (Experiments on EvoBench and unseen LLMs): no explicit statement is given that the detector was trained without exposure to the base models used in the “unseen evolving LLMs” test split, nor how attack strength was calibrated on RAID. Without these controls the generalization and robustness numbers cannot be interpreted as evidence for the spectral-fingerprint hypothesis.
Authors: We acknowledge the need for these explicit controls. The manuscript reports the generalization results but does not include the requested statements. We will revise §5.2 and §5.3 to add clear declarations that training data excluded all base models appearing in the unseen-LLM splits, together with a description of how attack strength was calibrated on RAID (including the specific perturbation parameters and validation procedure). These additions will enable proper interpretation of the numbers as evidence for the spectral-fingerprint hypothesis. revision: yes
-
Referee: [Table 2] Table 2 (main results): the reported accuracy and robustness margins are presented without an ablation that replaces the wavelet front-end with a standard transformer classifier trained on the identical probability-signal input; the contribution of the CWT itself therefore remains unisolated.
Authors: The referee correctly identifies that an internal ablation isolating the CWT is missing. While the paper compares against external baselines, it does not directly test the wavelet front-end against a transformer on the same probability-signal input. To address this, we will perform the suggested ablation and include the results in a revised Table 2 (or a new supplementary table) in the next version. This will quantify the incremental benefit of the differentiable CWT and strengthen the technical contribution. revision: yes
Circularity Check
No significant circularity; empirical method proposal without self-referential derivations
full rationale
The paper introduces WaveDetect as a signal-processing reformulation that applies a differentiable Continuous Wavelet Transform to token-probability sequences to extract spectral fingerprints. No equations, parameter-fitting steps, self-citations, or uniqueness theorems appear in the abstract or described content that would reduce any claimed prediction or result to its own inputs by construction. The central claims rest on empirical evaluations against external datasets (RAID, EvoBench, Domain-Shift) rather than internal mathematical reductions, making the derivation chain self-contained as a methodological proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ICLR 2026 Program Chairs , year=
2026
-
[2]
RAID : A Shared Benchmark for Robust Evaluation of Machine-Generated Text Detectors
Dugan, Liam and Hwang, Alyssa and Trhl \'i k, Filip and Zhu, Andrew and Ludan, Josh Magnus and Xu, Hainiu and Ippolito, Daphne and Callison-Burch, Chris. RAID : A Shared Benchmark for Robust Evaluation of Machine-Generated Text Detectors. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024....
-
[3]
La Cava, Lucio and Tagarelli, Andrea. O pen T uring B ench: An Open-Model-based Benchmark and Framework for Machine-Generated Text Detection and Attribution. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1354
-
[4]
2024 , eprint=
Stumbling Blocks: Stress Testing the Robustness of Machine-Generated Text Detectors Under Attacks , author=. 2024 , eprint=
2024
-
[5]
Yu, Xiao and Yu, Yi and Liu, Dongrui and Chen, Kejiang and Zhang, Weiming and Yu, Nenghai and Shao, Jing. E vo B ench: Towards Real-world LLM -Generated Text Detection Benchmarking for Evolving Large Language Models. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.754
-
[6]
2025 , eprint=
DivScore: Zero-Shot Detection of LLM-Generated Text in Specialized Domains , author=. 2025 , eprint=
2025
-
[7]
A Survey on Detection of LLM s-Generated Content
Yang, Xianjun and Pan, Liangming and Zhao, Xuandong and Chen, Haifeng and Petzold, Linda Ruth and Wang, William Yang and Cheng, Wei. A Survey on Detection of LLM s-Generated Content. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.572
-
[8]
Detecting Subtle Differences between Human and Model Languages Using Spectrum of Relative Likelihood
Xu, Yang and Wang, Yu and An, Hao and Liu, Zhichen and Li, Yongyuan. Detecting Subtle Differences between Human and Model Languages Using Spectrum of Relative Likelihood. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.564
-
[9]
2025 , eprint=
AI-Generated Text is Non-Stationary: Detection via Temporal Tomography , author=. 2025 , eprint=
2025
-
[10]
2019 , eprint=
Release Strategies and the Social Impacts of Language Models , author=. 2019 , eprint=
2019
-
[11]
LLM - D etect AI ve: a Tool for Fine-Grained Machine-Generated Text Detection
Abassy, Mervat and Elozeiri, Kareem and Aziz, Alexander and Ta, Minh Ngoc and Tomar, Raj Vardhan and Adhikari, Bimarsha and Ahmed, Saad El Dine and Wang, Yuxia and Mohammed Afzal, Osama and Xie, Zhuohan and Mansurov, Jonibek and Artemova, Ekaterina and others. LLM - D etect AI ve: a Tool for Fine-Grained Machine-Generated Text Detection. Proceedings of th...
-
[12]
DeTeCtive: Detecting AI-generated Text via Multi-Level Contrastive Learning , url =
Guo, Xun and Zhang, Shan and He, Yongxin and Zhang, Ting and Feng, Wanquan and Huang, Haibin and Ma, Chongyang , booktitle =. DeTeCtive: Detecting AI-generated Text via Multi-Level Contrastive Learning , url =. doi:10.52202/079017-2802 , editor =
-
[13]
2023 , eprint=
RADAR: Robust AI-Text Detection via Adversarial Learning , author=. 2023 , eprint=
2023
-
[14]
2023 , eprint=
DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature , author=. 2023 , eprint=
2023
-
[15]
2024 , eprint=
Fast-DetectGPT: Efficient Zero-Shot Detection of Machine-Generated Text via Conditional Probability Curvature , author=. 2024 , eprint=
2024
-
[16]
2024 , eprint=
Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text , author=. 2024 , eprint=
2024
-
[17]
2025 , eprint=
RepreGuard: Detecting LLM-Generated Text by Revealing Hidden Representation Patterns , author=. 2025 , eprint=
2025
-
[18]
2023 , eprint=
FACE: Evaluating Natural Language Generation with Fourier Analysis of Cross-Entropy , author=. 2023 , eprint=
2023
-
[19]
Evaluating Text Generation Quality Using Spectral Distances of Surprisal
Liu, Zhichen and Li, Yongyuan and Xu, Yang and Wang, Yu and Yuan, Yingfang and Yang, Zuhao. Evaluating Text Generation Quality Using Spectral Distances of Surprisal. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.132
-
[20]
GLTR : Statistical Detection and Visualization of Generated Text
Gehrmann, Sebastian and Strobelt, Hendrik and Rush, Alexander. GLTR : Statistical Detection and Visualization of Generated Text. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. 2019. doi:10.18653/v1/P19-3019
-
[21]
Machine-Generated Text: A Comprehensive Survey of Threat Models and Detection Methods , volume =
Crothers, Evan and Japkowicz, Nathalie and Viktor, Herna , year =. Machine-Generated Text: A Comprehensive Survey of Threat Models and Detection Methods , volume =. IEEE Access , doi =
-
[22]
2020 , eprint=
The Curious Case of Neural Text Degeneration , author=. 2020 , eprint=
2020
-
[23]
, journal=
Mallat, S.G. , journal=. A theory for multiresolution signal decomposition: the wavelet representation , year=
-
[24]
Siam Journal on Mathematical Analysis , year=
DECOMPOSITION OF HARDY FUNCTIONS INTO SQUARE INTEGRABLE WAVELETS OF CONSTANT SHAPE , author=. Siam Journal on Mathematical Analysis , year=
-
[25]
2019 , eprint=
PubMedQA: A Dataset for Biomedical Research Question Answering , author=. 2019 , eprint=
2019
-
[26]
Johnson, Alistair E. W. and Bulgarelli, Lucas and Shen, Lu and Gayles, Alvin and Shammout, Ayad and Horng, Steven and Pollard, Tom J. and Hao, Sicheng and Moody, Benjamin and Gow, Brian and Lehman, Li-wei H. and Celi, Leo A. and Mark, Roger G. , title =. Scientific Data , year =. doi:10.1038/s41597-022-01899-x , url =
-
[27]
doi:10.57967/hf/4792 , publisher =
Moslem, Yasmin , title =. doi:10.57967/hf/4792 , publisher =
-
[28]
Open Australian Legal QA , publisher =
Butler, Umar , year =. Open Australian Legal QA , publisher =. doi:10.57967/hf/1479 , url =
-
[29]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[30]
2015 , eprint=
Deep Residual Learning for Image Recognition , author=. 2015 , eprint=
2015
-
[31]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[32]
2023 , url=
MPT-30B: Raising the bar for open-source foundation models , author=. 2023 , url=
2023
-
[33]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[34]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[35]
2024 , url=
Cohere , author=. 2024 , url=
2024
-
[36]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[37]
2021 , howpublished =
arXiv Paper Abstracts , author =. 2021 , howpublished =
2021
-
[38]
Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing , year =
New Alignment Methods for Discriminative Book Summarization , author =. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing , year =
2013
-
[39]
SIGPLAN Notices , volume =
Probabilistic Model for Code with Decision Trees , author =. SIGPLAN Notices , volume =. 2016 , url=
2016
-
[40]
Proceedings of the 23rd International Conference on Machine Learning (ICML) , pages =
Practical Solutions to the Problem of Diagonal Dominance in Kernel Document Clustering , author =. Proceedings of the 23rd International Conference on Machine Learning (ICML) , pages =. 2006 , publisher =
2006
-
[41]
2020 , howpublished =
Poems Dataset (NLP) , author =. 2020 , howpublished =
2020
-
[42]
Proceedings of the 13th International Conference on Natural Language Generation , pages =
RecipeNLG: A Cooking Recipes Dataset for Semi-Structured Text Generation , author =. Proceedings of the 13th International Conference on Natural Language Generation , pages =. 2020 , address =
2020
-
[43]
Proceedings of the Workshop on New Frontiers in Summarization , pages =
TL;DR: Mining Reddit to Learn Automatic Summarization , author =. Proceedings of the Workshop on New Frontiers in Summarization , pages =. 2017 , address =
2017
-
[44]
Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages =
Learning Word Vectors for Sentiment Analysis , author =. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages =. 2011 , address =
2011
-
[45]
2023 , note =
GPT-Wiki-Intro , author =. 2023 , note =
2023
-
[46]
2022 , url =
Fine-Grained Czech News Article Dataset: An Interdisciplinary Approach to Trustworthiness Analysis , author =. 2022 , url =
2022
-
[47]
Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =
One Million Posts: A Data Set of German Online Discussions , author =. Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2017 , publisher =
2017
-
[48]
International Journal of Computer Vision , author =
Selvaraju, Ramprasaath R. and Cogswell, Michael and Das, Abhishek and Vedantam, Ramakrishna and Parikh, Devi and Batra, Dhruv , year=. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization , volume=. International Journal of Computer Vision , publisher=. doi:10.1007/s11263-019-01228-7 , number=
-
[49]
ArXiv , year=
Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization , author=. ArXiv , year=
-
[50]
Fan, Angela and Lewis, Mike and Dauphin, Yann. Hierarchical Neural Story Generation. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1082
-
[51]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[52]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.