Test Case Selection for Deep Neural Networks: A Replication Study on LLMs for Code
Pith reviewed 2026-06-29 00:45 UTC · model grok-4.3
The pith
Only a subset of test case selection findings from vision DNNs generalize to LLMs for code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
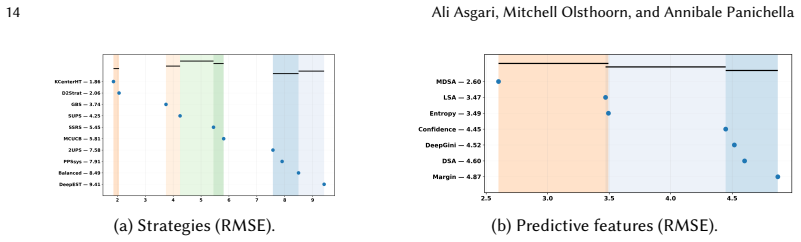
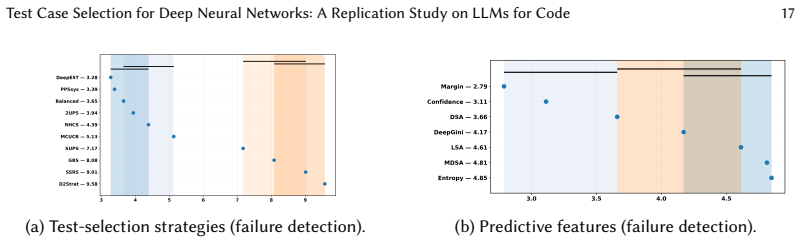
The central claim is that only a subset of findings reported for vision-based DNNs generalize when TCS is applied to LLMs for code. In particular, uncertainty-based features are effective for early failure discovery, while representation-based features are more robust for accuracy estimation. At the same time, performance varies substantially across tasks and models, indicating that TCS effectiveness is context-dependent.
What carries the argument
The comparison of uncertainty-based versus representation-based predictive features within thirteen selection strategies evaluated for both accuracy estimation and early failure discovery on code classification tasks.
If this is right
- Uncertainty-based features can be prioritized when the operational goal is rapid discovery of failures under limited labeling budgets.
- Representation-based features should be preferred when the goal is reliable estimation of overall model accuracy.
- Selection strategies must be adapted to the specific task and model because effectiveness is strongly context-dependent.
- Simple random sampling remains a viable baseline but is outperformed by informed strategies in targeted use cases.
- Operational evaluation of LLMs for code benefits from task-specific choice of TCS rather than direct reuse of vision DNN defaults.
Where Pith is reading between the lines
- The observed split between feature types suggests that hybrid selection strategies combining uncertainty and representation signals could improve both goals simultaneously.
- The context dependence implies that organizations maintaining multiple code LLMs will need per-task calibration of their testing pipelines.
- Extending the same replication design to generation tasks or larger foundation models would test whether the partial-transfer pattern holds more broadly.
- These results point to the value of maintaining separate test-case pools for failure hunting versus accuracy auditing in LLM development workflows.
Load-bearing premise
The three chosen code classification tasks and the seventeen fine-tuned model instances are sufficiently representative of LLM code models in general.
What would settle it
Finding the reverse pattern—representation features outperforming uncertainty features for early failure discovery and uncertainty features outperforming representation features for accuracy estimation—on additional code tasks or model families would falsify the reported generalization limits.
Figures
read the original abstract
Recently, test case selection (TCS) techniques have been explored to support the operational evaluation of deep neural networks (DNNs) under limited testing budgets, where labeling cost is a primary concern and uncovering model failures early is a key objective. Although prior studies report promising results, existing empirical evaluations focus almost exclusively on vision-based DNNs and datasets, leaving it unclear whether prior findings generalize to LLM code models. This paper presents a large-scale replication study of TCS techniques in the context of LLM code models. We re-examine established TCS strategies originally proposed for DNNs and complement them with statistical sampling strategies not previously evaluated for TCS. We assess their effectiveness on three code-related classification tasks: clone detection, vulnerability detection, and technical debt prediction. The study spans 17 task-specific fine-tuned model instances, 7 predictive features, and 13 selection strategies, including 12 feature-aware strategies and simple random sampling (SRS) as a feature-agnostic baseline. We evaluate performance along two dimensions: accuracy estimation and early failure discovery. The results indicate that only a subset of findings reported for vision-based DNNs generalize when TCS is applied to LLMs for code. In particular, uncertainty-based features are effective for early failure discovery, while representation-based features are more robust for accuracy estimation. At the same time, performance varies substantially across tasks and models, indicating that TCS effectiveness is context-dependent. Overall, this study provides empirical evidence on the replicability of TCS techniques beyond vision-based deep learning and offers insights into their use for the operational evaluation of LLMs for code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a replication study of test case selection (TCS) techniques originally developed for vision-based DNNs, now applied to LLMs for code. It evaluates 13 strategies (12 feature-aware plus random sampling) using 7 predictive features across 17 fine-tuned model instances on three classification tasks (clone detection, vulnerability detection, technical debt prediction). Effectiveness is measured on two axes: accuracy estimation and early failure discovery. The central claim is that only a subset of prior vision-DNN findings generalize, with uncertainty-based features effective for early failure discovery and representation-based features more robust for accuracy estimation, while overall performance is highly context-dependent across tasks and models.
Significance. If the results hold under rigorous statistical controls, the work supplies empirical evidence on the replicability of TCS methods outside vision domains and supplies concrete guidance for budgeted operational evaluation of code LLMs. The explicit comparison of uncertainty versus representation features and the documentation of task/model variance are useful contributions.
major comments (2)
- [Abstract] Abstract: the generalization statement that 'only a subset of findings reported for vision-based DNNs generalize when TCS is applied to LLMs for code' is grounded exclusively in three classification tasks. The manuscript does not examine generative tasks (completion, repair, summarization) that dominate many LLM-for-code applications; this scope limitation directly affects whether the reported feature rankings can be treated as informative for the broader class of models and tasks.
- [Abstract] Abstract (and implied Methods): the study reports differential effectiveness across 17 models, 7 features and 13 strategies yet supplies no information on data splits, cross-validation procedure, statistical significance tests, or error bars. Without these elements it is impossible to rule out post-hoc selection or to quantify the reliability of the claimed context-dependence.
minor comments (1)
- The abstract lists 'simple random sampling (SRS) as a feature-agnostic baseline' but does not state whether SRS performance is reported with the same evaluation protocol as the feature-aware strategies; adding an explicit comparison table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our replication study. We address each major comment below and indicate where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the generalization statement that 'only a subset of findings reported for vision-based DNNs generalize when TCS is applied to LLMs for code' is grounded exclusively in three classification tasks. The manuscript does not examine generative tasks (completion, repair, summarization) that dominate many LLM-for-code applications; this scope limitation directly affects whether the reported feature rankings can be treated as informative for the broader class of models and tasks.
Authors: We agree the study is limited to three classification tasks and does not cover generative tasks. Prior vision-DNN TCS work also focused on classification, so our replication preserves that scope. We will revise the abstract to explicitly state the scope (classification tasks only) and note that extension to generative tasks is left for future work, preventing overgeneralization of the feature rankings. revision: yes
-
Referee: [Abstract] Abstract (and implied Methods): the study reports differential effectiveness across 17 models, 7 features and 13 strategies yet supplies no information on data splits, cross-validation procedure, statistical significance tests, or error bars. Without these elements it is impossible to rule out post-hoc selection or to quantify the reliability of the claimed context-dependence.
Authors: The Methods section details dataset construction and model fine-tuning, including train/test splits. To strengthen the manuscript, we will add explicit reporting of any cross-validation used, apply and report statistical significance tests (e.g., paired Wilcoxon tests with p-values) for strategy comparisons, and include error bars or confidence intervals in figures/tables. This directly addresses concerns about reliability and post-hoc selection. revision: yes
Circularity Check
Empirical replication study with no derivation chain or self-referential definitions
full rationale
The paper is a purely empirical replication study evaluating existing TCS techniques on three code classification tasks using 17 fine-tuned models. It reports observed performance differences for accuracy estimation and early failure discovery without any equations, fitted parameters, predictions derived from inputs, or self-citations that serve as load-bearing premises. All claims rest on direct experimental results rather than quantities defined in terms of the study's own outputs. No patterns of self-definitional, fitted-input-as-prediction, or ansatz-smuggling circularity apply.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amin Abbasishahkoo, Mahboubeh Dadkhah, Lionel Briand, and Dayi Lin. 2025. Metasel: A test selection approach for fine-tuned dnn models.IEEE Transactions on Software Engineering(2025)
2025
-
[2]
Zohreh Aghababaeyan, Manel Abdellatif, Mahboubeh Dadkhah, and Lionel Briand. 2024. Deepgd: A multi-objective black-box test selection approach for deep neural networks.ACM Transactions on Software Engineering and Methodology 33, 6 (2024), 1–29
2024
-
[3]
Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. 2021. Unified pre-training for program understanding and generation. InProceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies. 2655–2668
2021
-
[4]
Miltiadis Allamanis, Earl T Barr, Premkumar Devanbu, and Charles Sutton. 2018. A survey of machine learning for big code and naturalness.ACM Computing Surveys (CSUR)51, 4 (2018), 1–37
2018
-
[5]
2006.k-means++: The advantages of careful seeding
David Arthur and Sergei Vassilvitskii. 2006.k-means++: The advantages of careful seeding. Technical Report. Stanford
2006
-
[6]
David Arthur and Sergei Vassilvitskii. 2007. Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. InSociety for Industrial and Applied Mathematics
2007
-
[7]
Ali Asgari, Milan de Koning, Pouria Derakhshanfar, and Annibale Panichella. [n. d.]. Metamorphic Testing of Deep Code Models: A Systematic Literature Review.ACM Transactions on Software Engineering and Methodology([n. d.])
-
[8]
Ali Asgari, Antonio Guerriero, Roberto Pietrantuono, Stefano Russo, et al. 2025. Adaptive Probabilistic Operational Testing for Large Language Models Evaluation. InThe 6th ACM/IEEE International Conference on Automation of Software Test
2025
-
[9]
Merve Astekin, Arda Goknil, Sagar Sen, Simeon Tverdal, and Phu Nguyen. 2025. Detecting Technical Debt in Source Code Changes Using Large Language Models. InInternational Conference on Product-Focused Software Process Improvement. Springer, 334–352
2025
-
[10]
Earl T Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo. 2014. The oracle problem in software testing: A survey.IEEE transactions on software engineering41, 5 (2014), 507–525
2014
-
[11]
Giovanni Capobianco, Andrea De Lucia, Rocco Oliveto, Annibale Panichella, and Sebastiano Panichella. 2013. Improving IR-based traceability recovery via noun-based indexing of software artifacts.Journal of Software: Evolution and Process 25, 7 (2013), 743–762
2013
-
[12]
Alexandra Carpentier and Rémi Munos. 2012. Adaptive stratified sampling for Monte-Carlo integration of differentiable functions.Advances in neural information processing systems25 (2012)
2012
-
[13]
Yizheng Chen, Zhoujie Ding, Lamya Alowain, Xinyun Chen, and David Wagner. 2023. Diversevul: A new vulnerable source code dataset for deep learning based vulnerability detection. InProceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses. 654–668
2023
-
[14]
Jean-Claude Deville and Yves Tille. 1998. Unequal probability sampling without replacement through a splitting method.Biometrika85, 1 (1998), 89–101
1998
-
[15]
Jean-Claude Deville and Yves Tillé. 1998. Unequal probability sampling without replacement.Survey Methodology24, 2 (1998), 157–168
1998
-
[16]
Xavier Devroey, Alessio Gambi, Juan Pablo Galeotti, René Just, Fitsum Kifetew, Annibale Panichella, and Sebastiano Panichella. 2023. JUGE: An infrastructure for benchmarking Java unit test generators.Software Testing, Verification and Reliability33, 3 (2023), e1838
2023
-
[17]
Melanie Ducoffe and Frederic Precioso. 2018. Adversarial active learning for deep networks: a margin based approach. arXiv preprint arXiv:1802.09841(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M Zhang. 2023. Large language models for software engineering: Survey and open problems. In2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). IEEE, 31–53
2023
-
[19]
Yang Feng, Qingkai Shi, Xinyu Gao, Jun Wan, Chunrong Fang, and Zhenyu Chen. 2020. Deepgini: prioritizing massive tests to enhance the robustness of deep neural networks. InProceedings of the 29th ACM SIGSOFT international symposium on software testing and analysis. 177–188
2020
-
[20]
Z Feng. 2020. Codebert: A pre-trained model for program-ming and natural languages.arXiv preprint arXiv:2002.08155 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[21]
Xinyu Gao, Yang Feng, Yining Yin, Zixi Liu, Zhenyu Chen, and Baowen Xu. 2022. Adaptive test selection for deep neural networks. InProceedings of the 44th international conference on software engineering. 73–85. 22 Ali Asgari, Mitchell Olsthoorn, and Annibale Panichella
2022
-
[22]
Salvador García, Daniel Molina, Manuel Lozano, and Francisco Herrera. 2009. A Study on the Use of Non-parametric Tests for Analyzing the Evolutionary Algorithms’ Behaviour: A Case Study on the CEC’2005 Special Session on Real Parameter Optimization.Journal of Heuristics15, 6 (Dec. 2009), 617–644
2009
-
[23]
Teofilo F Gonzalez. 1985. Clustering to minimize the maximum intercluster distance.Theoretical computer science38 (1985), 293–306
1985
-
[24]
Antonio Guerriero, Roberto Pietrantuono, and Stefano Russo. 2021. Operation is the hardest teacher: estimating DNN accuracy looking for mispredictions. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 348–358
2021
-
[25]
Antonio Guerriero, Roberto Pietrantuono, and Stefano Russo. 2024. DeepSample: DNN sampling-based testing for operational accuracy assessment. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE). ACM, 1–12
2024
-
[26]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. Unixcoder: Unified cross-modal pre-training for code representation.arXiv preprint arXiv:2203.03850(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, et al. 2020. Graphcodebert: Pre-training code representations with data flow.arXiv preprint arXiv:2009.08366 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[28]
Lianghong Guo, Yanlin Wang, Ensheng Shi, Wanjun Zhong, Hongyu Zhang, Jiachi Chen, Ruikai Zhang, Yuchi Ma, and Zibin Zheng. 2024. When to stop? towards efficient code generation in llms with excess token prevention. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1073–1085
2024
-
[29]
Morris H Hansen and William N Hurwitz. 1943. On the theory of sampling from finite populations.The Annals of Mathematical Statistics14, 4 (1943), 333–362
1943
-
[30]
Horvitz and Donovan J
Daniel G. Horvitz and Donovan J. Thompson. 1952. A generalization of sampling without replacement from a finite universe.Journal of the American statistical Association47, 260 (1952), 663–685
1952
-
[31]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang
- [32]
-
[33]
Qiang Hu, Yuejun Guo, Xiaofei Xie, Maxime Cordy, Lei Ma, Mike Papadakis, and Yves Le Traon. 2024. Test optimization in dnn testing: a survey.ACM Transactions on Software Engineering and Methodology33, 4 (2024), 1–42
2024
-
[34]
Qiang Hu, Yuejun Guo, Xiaofei Xie, Maxime Cordy, Wei Ma, Mike Papadakis, Lei Ma, and Yves Le Traon. 2025. Assessing the Robustness of Test Selection Methods for Deep Neural Networks.ACM Transactions on Software Engineering and Methodology(2025)
2025
-
[35]
An essay on the logical foundations of survey sampling, Part One
Jaroslav Hájek. 1971. Comment on “An essay on the logical foundations of survey sampling, Part One”. InFoundations of Statistical Inference. Holt, Rinehart and Winston
1971
-
[36]
Japkowicz and M
N. Japkowicz and M. Shah. 2011.Evaluating Learning Algorithms: A Classification Perspective. Cambridge University Press. https://books.google.com/books?id=VoWIIOKVzR4C
2011
-
[37]
Mojan Javaheripi, Sébastien Bubeck, Marah Abdin, Jyoti Aneja, Sebastien Bubeck, Caio César Teodoro Mendes, Weizhu Chen, Allie Del Giorno, Ronen Eldan, Sivakanth Gopi, et al . 2023. Phi-2: The surprising power of small language models.Microsoft Research Blog1, 3 (2023), 3
2023
-
[38]
Yiding Jiang, Dilip Krishnan, Hossein Mobahi, and Samy Bengio. 2018. Predicting the generalization gap in deep networks with margin distributions.arXiv preprint arXiv:1810.00113(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Mohamad Khajezade, Jie JW Wu, Fatemeh Hendijani Fard, Gema Rodríguez-Pérez, and Mohamed Sami Shehata. 2024. Investigating the Efficacy of Large Language Models for Code Clone Detection. InProceedings of the 32nd IEEE/ACM International Conference on Program Comprehension. 161–165
2024
-
[40]
Jinhan Kim, Robert Feldt, and Shin Yoo. 2019. Guiding deep learning system testing using surprise adequacy. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 1039–1049
2019
-
[41]
Jinhan Kim, Robert Feldt, and Shin Yoo. 2023. Evaluating surprise adequacy for deep learning system testing.ACM Transactions on Software Engineering and Methodology32, 2 (2023), 1–29
2023
-
[42]
Roham Koohestani, Philippe de Bekker, Begüm Koç, and Maliheh Izadi. 2025. Benchmarking AI Models in Software Engineering: A Review, Search Tool, and Unified Approach for Elevating Benchmark Quality.IEEE Transactions on Software Engineering(2025)
2025
-
[43]
Nam Hai Le and collaborators. 2024. Tesoro Code Dataset. https://huggingface.co/datasets/NamCyan/tesoro-code. Accessed: 2026-01-22
2024
-
[44]
Nam Le Hai, Dung Manh Nguyen, and Nghi DQ Bui. 2025. On the impacts of contexts on repository-level code generation. InFindings of the Association for Computational Linguistics: NAACL 2025. 1496–1524
2025
-
[45]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. Starcoder: may the source be with you!arXiv preprint arXiv:2305.06161 (2023). Test Case Selection for Deep Neural Networks: A Replication Study on LLMs for Code 23
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Zenan Li, Xiaoxing Ma, Chang Xu, Chun Cao, Jingwei Xu, and Jian Lü. 2019. Boosting operational DNN testing efficiency through conditioning. InProceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). ACM, 499–509
2019
-
[47]
Pietro Liguori, Cristina Improta, Roberto Natella, Bojan Cukic, and Domenico Cotroneo. 2023. Who evaluates the evaluators? On automatic metrics for assessing AI-based offensive code generators.Expert Systems with Applications 225 (2023), 120073
2023
-
[48]
Sharon L. Lohr. 2021.Sampling: design and analysis. Chapman and Hall/CRC, New York
2021
-
[49]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. 2024. Starcoder 2 and the stack v2: The next generation.arXiv preprint arXiv:2402.19173(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Junpeng Lv, Bei-Bei Yin, and Kai-Yuan Cai. 2014. On the asymptotic behavior of adaptive testing strategy for software reliability assessment.IEEE transactions on Software Engineering40, 4 (2014), 396–412
2014
-
[51]
Wei Ma, Mike Papadakis, Anestis Tsakmalis, Maxime Cordy, and Yves Le Traon. 2021. Test selection for deep learning systems.ACM Transactions on Software Engineering and Methodology (TOSEM)30, 2 (2021), 1–22
2021
-
[52]
William G Madow. 1949. On the theory of systematic sampling, II.The Annals of Mathematical Statistics20, 3 (1949), 333–354
1949
-
[53]
Debajyoti Mondal, Hadi Hemmati, and Stephane Durocher. 2015. Exploring test suite diversification and code coverage in multi-objective test case selection. In2015 IEEE 8th International Conference on Software Testing, Verification and Validation (ICST). IEEE, 1–10
2015
-
[54]
Chao Ni, Xin Yin, Liyu Shen, and Shaohua Wang. 2026. Learning-based models for vulnerability detection: An extensive study.Empirical Software Engineering31, 1 (2026), 18
2026
-
[55]
Tanzeem Bin Noor and Hadi Hemmati. 2015. A similarity-based approach for test case prioritization using historical failure data. In2015 IEEE 26th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 58–68
2015
-
[56]
Annibale Panichella. 2021. A systematic comparison of search-based approaches for LDA hyperparameter tuning. Information and Software Technology130 (2021), 106411
2021
-
[57]
Roberto Pietrantuono and Stefano Russo. 2016. On adaptive sampling-based testing for software reliability assessment. In2016 IEEE 27th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 1–11
2016
-
[58]
J NoK Rao, HO Hartley, and WG Cochran. 1962. On a simple procedure of unequal probability sampling without replacement.Journal of the Royal Statistical Society Series B: Statistical Methodology24, 2 (1962), 482–491
1962
-
[59]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
Tim Sonnekalb, Bernd Gruner, Clemens-Alexander Brust, and Patrick Mäder. 2022. Generalizability of code clone detection on codebert. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–3
2022
-
[61]
Weifeng Sun, Meng Yan, Zhongxin Liu, and David Lo. 2023. Robust test selection for deep neural networks.IEEE Transactions on Software Engineering49, 12 (2023), 5250–5278
2023
-
[62]
Zhensu Sun, Xiaoning Du, Zhou Yang, Li Li, and David Lo. 2024. Ai coders are among us: Rethinking programming language grammar towards efficient code generation. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1124–1136
2024
-
[63]
Jeffrey Svajlenko and Chanchal K Roy. 2021. Bigclonebench. InCode Clone Analysis: Research, Tools, and Practices. Springer, 93–105
2021
-
[64]
2006.Sampling Algorithms
Yves Tillé. 2006.Sampling Algorithms. Springer
2006
-
[65]
Keze Wang, Dongyu Zhang, Ya Li, Ruimao Zhang, and Liang Lin. 2016. Cost-effective active learning for deep image classification.IEEE Transactions on Circuits and Systems for Video Technology27, 12 (2016), 2591–2600
2016
-
[66]
Yue Wang, Hung Le, Akhilesh Gotmare, Nghi Bui, Junnan Li, and Steven Hoi. 2023. Codet5+: Open code large language models for code understanding and generation. InProceedings of the 2023 conference on empirical methods in natural language processing. 1069–1088
2023
-
[67]
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, et al. 2025. Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference. InProceedings of the 63rd Annual Meeting of the Ass...
2025
- [68]
- [69]
-
[70]
Shin Yoo and Mark Harman. 2012. Regression testing minimization, selection and prioritization: a survey.Software testing, verification and reliability22, 2 (2012), 67–120
2012
-
[71]
Daoguang Zan, Bei Chen, Fengji Zhang, Dianjie Lu, Bingchao Wu, Bei Guan, Wang Yongji, and Jian-Guang Lou. 2023. Large language models meet NL2Code: A survey. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7443–7464
2023
-
[72]
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. 2024. Tinyllama: An open-source small language model. arXiv preprint arXiv:2401.02385(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Quanjun Zhang, Chunrong Fang, Yang Xie, Yaxin Zhang, Yun Yang, Weisong Sun, Shengcheng Yu, and Zhenyu Chen
- [74]
- [75]
-
[76]
Xin Zhou, Ting Zhang, and David Lo. 2024. Large language model for vulnerability detection: Emerging results and future directions. InProceedings of the 2024 ACM/IEEE 44th International Conference on Software Engineering: New Ideas and Emerging Results. 47–51
2024
-
[77]
Yaqin Zhou, Shangqing Liu, Jingkai Siow, Xiaoning Du, and Yang Liu. 2019. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks.Advances in neural information processing systems32 (2019)
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.