Spatially Localized Image Degradation Embeddings for Image Quality Assessment
Pith reviewed 2026-06-30 07:57 UTC · model grok-4.3
The pith
SLIDE-IQA pretrains Vision Transformers on synthetic localized degradations to increase sensitivity to spatially bounded distortions in no-reference image quality assessment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
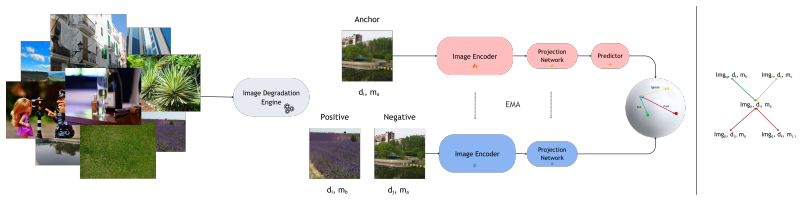
SLIDE-IQA employs a dual-branch Vision Transformer framework that injects spatially bounded degradations into a contrastive pretraining objective. To handle the spatial complexity of these degradations, a Threshold-Bounded Exclusion Mechanism resolves structural conflicts arising from spatially localized distortions to ensure the latent space respects both degradation type and spatial scale. Synthetic-only pretraining with this design significantly improves sensitivity to localized distortions while achieving competitive performance on NR-IQA benchmarks against existing SSL NR-IQA models.
What carries the argument
Dual-branch Vision Transformer with Threshold-Bounded Exclusion Mechanism that injects spatially bounded degradations into contrastive pretraining to encode both degradation type and spatial scale.
If this is right
- Greater sensitivity to localized and co-occurring degradations that appear in real-world images.
- Competitive accuracy on existing no-reference image quality benchmarks despite using only synthetic pretraining data.
- Latent representations that separately track degradation identity and its spatial location.
Where Pith is reading between the lines
- The same localized-degradation injection could be tested on video frames to see whether temporal consistency improves.
- Downstream tasks such as automated video compression tuning might benefit from the added spatial awareness.
- Removing the exclusion mechanism would be a direct test of whether it is required for the reported sensitivity gain.
Load-bearing premise
The Threshold-Bounded Exclusion Mechanism can resolve structural conflicts so the latent space respects both degradation type and spatial scale.
What would settle it
A direct comparison on a test set of images with spatially bounded degradations showing that SLIDE-IQA does not detect those localized distortions more accurately than standard uniform-distortion self-supervised models.
Figures

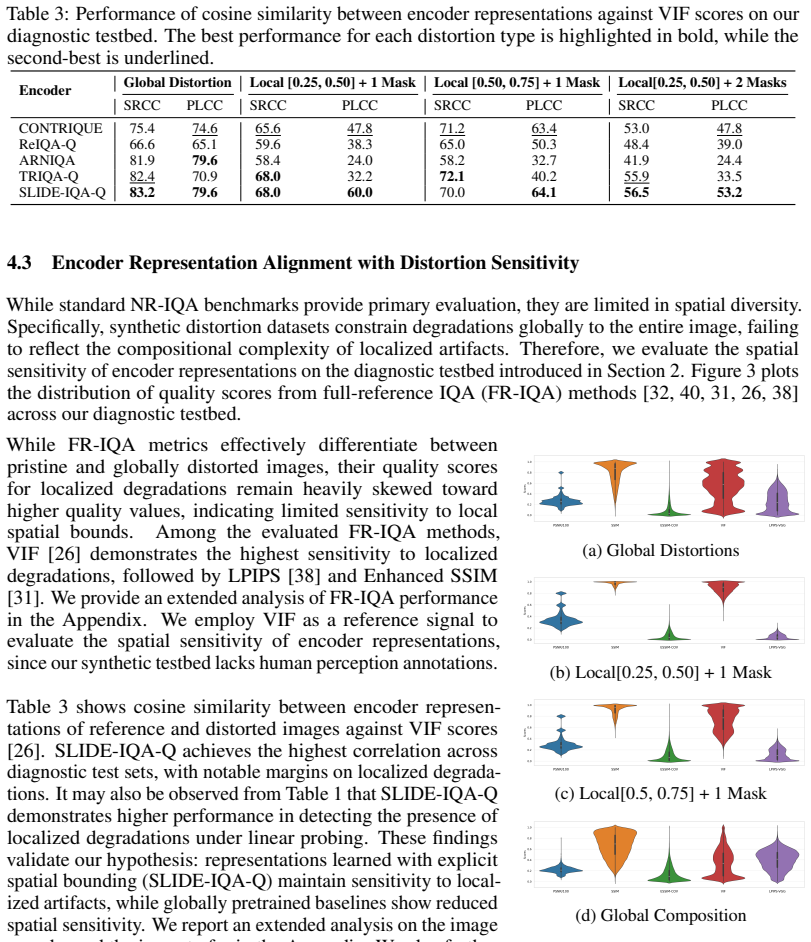


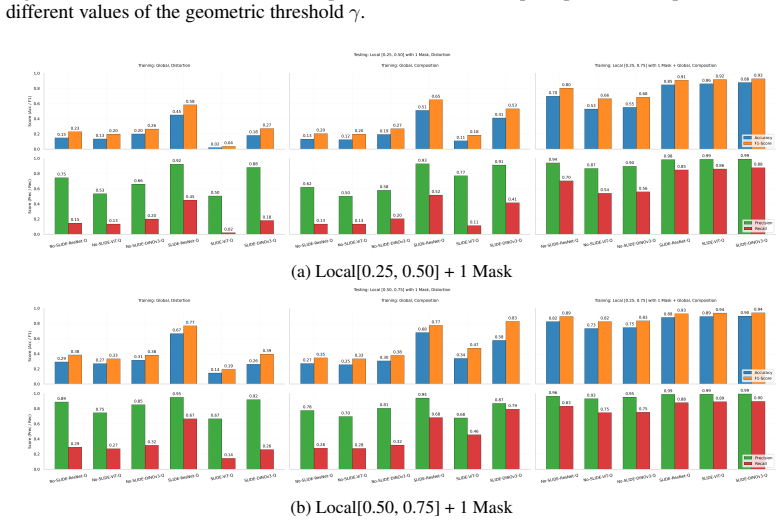
read the original abstract
Self-supervised learning (SSL) currently drives state-of-the-art performance in no-reference image quality assessment (NR-IQA). However, standard SSL pipelines uniformly apply synthetic distortions across the entire image field, which can limit their sensitivity to spatially localized and co-occurring degradations encountered in real-world content. In this work, we empirically expose this representational blind spot across existing state-of-the-art encoders, demonstrating their reduced sensitivity to spatially bounded image degradations. To bridge this gap, we introduce Spatial Localized Image Degradation Embeddings for Image Quality Assessment (SLIDE-IQA). SLIDE-IQA employs a dual-branch Vision Transformer framework that injects spatially bounded degradations into a contrastive pretraining objective. To handle the spatial complexity of these degradations, we introduce a Threshold-Bounded Exclusion Mechanism, a representational design choice that resolves structural conflicts arising from spatially localized distortions to ensure the latent space respects both degradation type and spatial scale. Finally, we show that SLIDE-IQA's synthetic-only pretraining significantly improves sensitivity to localized distortions, while achieving competitive performance on NR-IQA benchmarks against existing SSL NR-IQA models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing SSL methods for NR-IQA suffer from reduced sensitivity to spatially localized degradations due to uniform application of synthetic distortions across the image. To address this, SLIDE-IQA is proposed as a dual-branch Vision Transformer framework that incorporates spatially bounded degradations into a contrastive pretraining objective. A Threshold-Bounded Exclusion Mechanism is introduced to resolve structural conflicts in the latent space arising from these localized distortions, ensuring the latent space respects both degradation type and spatial scale. The authors empirically demonstrate that this synthetic-only pretraining significantly improves sensitivity to localized distortions while achieving competitive performance on standard NR-IQA benchmarks compared to existing SSL NR-IQA models.
Significance. If the empirical claims are substantiated, this work would be significant in the field of image quality assessment by identifying and mitigating a blind spot in current self-supervised learning approaches for NR-IQA. The focus on spatially localized degradations aligns with real-world challenges, and the synthetic-only pretraining strategy is a strength as it potentially offers a scalable way to improve model sensitivity without requiring additional real-world data.
major comments (1)
- [Abstract] Abstract: The abstract asserts empirical exposure of the blind spot and performance gains, but provides no experimental details, datasets, or quantitative results to evaluate the claims. This makes it difficult to assess the soundness of the central empirical claim regarding improved sensitivity to localized distortions and competitive benchmark performance.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for greater specificity in the abstract. We address the comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts empirical exposure of the blind spot and performance gains, but provides no experimental details, datasets, or quantitative results to evaluate the claims. This makes it difficult to assess the soundness of the central empirical claim regarding improved sensitivity to localized distortions and competitive benchmark performance.
Authors: We acknowledge that the abstract is written at a high level and omits specific datasets, quantitative metrics, and experimental details, which is standard for length constraints but can reduce immediate evaluability. The full manuscript substantiates the claims in the Experiments section with results on standard NR-IQA benchmarks (e.g., LIVE, CSIQ, TID2013) and custom localized degradation tests, reporting competitive SRCC/PLCC scores against SSL baselines plus gains in localized sensitivity. To address the concern directly, we will revise the abstract to incorporate one or two key quantitative highlights and dataset references while preserving brevity. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces a new dual-branch ViT contrastive framework and Threshold-Bounded Exclusion Mechanism for handling spatially localized degradations in SSL pretraining for NR-IQA. No equations, derivations, or self-citation chains are present in the provided text that reduce any claimed result to fitted inputs or prior author work by construction. The central claims rest on empirical sensitivity improvements from the synthetic-only pretraining setup, which is presented as an independent methodological contribution rather than a renaming or self-referential fit. The derivation chain is self-contained as a design proposal without load-bearing reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard SSL pipelines uniformly apply synthetic distortions across the entire image field.
- ad hoc to paper Spatially bounded degradations create structural conflicts in latent space that require a special exclusion mechanism.
invented entities (1)
-
Threshold-Bounded Exclusion Mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Arniqa: Learning distortion manifold for image quality assessment
Agnolucci, Lorenzo and Galteri, Leonardo and Bertini, Marco and Del Bimbo, Alberto. Arniqa: Learning distortion manifold for image quality assessment. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 189–198, 2024
2024
-
[2]
An empirical study of training self-supervised vision transformers
Chen, Xinlei and Xie, Saining and He, Kaiming. An empirical study of training self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9640–9649, 2021
2021
-
[3]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009
2009
-
[4]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
Perceptual quality assessment of smartphone photography
Fang, Yuming and Zhu, Hanwei and Zeng, Yan and Ma, Kede and Wang, Zhou. Perceptual quality assessment of smartphone photography. InProc. IEEE Conf. Comput. Vision Pattern Recognit., pages 3677–3686, 2020
2020
-
[6]
Massive online crowdsourced study of subjective and objective picture quality.IEEE Trans
Ghadiyaram, Deepti and Bovik, Alan C. Massive online crowdsourced study of subjective and objective picture quality.IEEE Trans. Image Process., 25(1):372–387, 2015
2015
-
[7]
No-reference image quality assessment via transformers, relative ranking, and self-consistency
S Alireza Golestaneh, Saba Dadsetan, and Kris M Kitani. No-reference image quality assessment via transformers, relative ranking, and self-consistency. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1220–1230, 2022
2022
-
[8]
A Statistical Evaluation of Recent Full Reference Image Quality Assessment Algorithms.IEEE Trans
Hamid R Sheikh and Muhammad F Sabir and Alan C Bovik. A Statistical Evaluation of Recent Full Reference Image Quality Assessment Algorithms.IEEE Trans. Image Process., 15(11):3440–3451, Nov 2006
2006
-
[9]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[10]
KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment.IEEE Trans
Hosu, Vlad and Lin, Hanhe and Sziranyi, Tamas and Saupe, Dietmar. KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment.IEEE Trans. Image Process., 29:4041–4056, 2020
2020
-
[11]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization, 2019. URL https://arxiv. org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[12]
MUSIQ: Multi-scale Image Quality Transformer.CoRR, abs/2108.05997, 2021
Junjie Ke and Qifei Wang and Yilin Wang and Peyman Milanfar and Feng Yang. MUSIQ: Multi-scale Image Quality Transformer.CoRR, abs/2108.05997, 2021. URLhttps://arxiv.org/abs/2108.05997
-
[13]
Most apparent distortion: Full-reference image quality assessment and the role of strategy.J
Larson, Eric Cooper and Chandler, Damon Michael. Most apparent distortion: Full-reference image quality assessment and the role of strategy.J. Electron. Imag, 19(1):011006, 2010
2010
-
[14]
Distilling spatially-heterogeneous distortion perception for blind image quality assessment
Li, Xudong and Nie, Wenjie and Zhang, Yan and Hu, Runze and Li, Ke and Zheng, Xiawu and Cao, Liujuan. Distilling spatially-heterogeneous distortion perception for blind image quality assessment. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 2344–2354, 2025
2025
-
[15]
KADID-10k: A large-scale artificially distorted IQA database
Lin, Hanhe and Hosu, Vlad and Saupe, Dietmar. KADID-10k: A large-scale artificially distorted IQA database. InIEEE Int’l Conf. on Quality of Multimedia Experience, pages 1–3, 2019
2019
-
[16]
DeepFL-IQA: Weak supervision for deep IQA feature learning.arXiv preprint arXiv:2001.08113, 2020
Lin, Hanhe and Hosu, Vlad and Saupe, Dietmar. DeepFL-IQA: Weak supervision for deep IQA feature learning.arXiv preprint arXiv:2001.08113, 2020. 16
-
[17]
Rankiqa: Learning from rankings for no- reference image quality assessment
Xialei Liu, Joost Van De Weijer, and Andrew D Bagdanov. Rankiqa: Learning from rankings for no- reference image quality assessment. InProceedings of the IEEE international conference on computer vision, pages 1040–1049, 2017
2017
-
[18]
A convnet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986, 2022
2022
-
[19]
and Birkbeck, Neil and Wang, Yilin and Adsumilli, Balu and Bovik, Alan C
Madhusudana, Pavan C. and Birkbeck, Neil and Wang, Yilin and Adsumilli, Balu and Bovik, Alan C. Image Quality Assessment Using Contrastive Learning.IEEE Transactions on Image Processing, 31: 4149–4161, 2022. ISSN 1941-0042. URLhttp://dx.doi.org/10.1109/TIP.2022.3181496
-
[20]
No-reference image quality assessment in the spatial domain.IEEE Transactions on image processing, 21(12):4695–4708, 2012
Mittal, Anish and Moorthy, Anush Krishna and Bovik, Alan Conrad. No-reference image quality assessment in the spatial domain.IEEE Transactions on image processing, 21(12):4695–4708, 2012
2012
-
[21]
completely blind
Mittal, Anish and Soundararajan, Rajiv and Bovik, Alan C. Making a “completely blind” image quality analyzer.IEEE Signal processing letters, 20(3):209–212, 2012
2012
-
[22]
Blind image quality assessment: From natural scene statistics to perceptual quality.IEEE transactions on Image Processing, 20(12):3350–3364, 2011
Moorthy, Anush Krishna and Bovik, Alan Conrad. Blind image quality assessment: From natural scene statistics to perceptual quality.IEEE transactions on Image Processing, 20(12):3350–3364, 2011
2011
-
[23]
Image database TID2013: Peculiarities, results and perspectives.Signal Process.: Image Commun., 30: 57–77, 2015
Ponomarenko, Nikolay and Jin, Lina and Ieremeiev, Oleg and Lukin, Vladimir and Egiazarian, Karen and Astola, Jaakko and V ozel, Benoit and Chehdi, Kacem and Carli, Marco and Battisti, Federica and others. Image database TID2013: Peculiarities, results and perspectives.Signal Process.: Image Commun., 30: 57–77, 2015
2015
-
[24]
Blind image quality assessment: A natural scene statistics approach in the DCT domain.IEEE Transactions on Image Processing, 21(8):3339–3352, 2012
Saad, Michele A and Bovik, Alan C and Charrier, Christophe. Blind image quality assessment: A natural scene statistics approach in the DCT domain.IEEE Transactions on Image Processing, 21(8):3339–3352, 2012
2012
-
[25]
Re-iqa: Unsupervised learning for image quality assessment in the wild
Saha, Avinab and Mishra, Sandeep and Bovik, Alan C. Re-iqa: Unsupervised learning for image quality assessment in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5846–5855, 2023
2023
-
[26]
and Bovik, A.C
Sheikh, H.R. and Bovik, A.C. Image information and visual quality.IEEE Transactions on Image Processing, 15(2):430–444, 2006
2006
-
[27]
Siméoni, Oriane and V o, Huy V and Seitzer, Maximilian and Baldassarre, Federico and Oquab, Maxime and Jose, Cijo and Khalidov, Vasil and Szafraniec, Marc and Yi, Seungeun and Ramamonjisoa, Michaël and others. DINOv3.arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Learning generalizable perceptual representations for data-efficient no-reference image quality assessment
Srinath, Suhas and Mitra, Shankhanil and Rao, Shika and Soundararajan, Rajiv. Learning generalizable perceptual representations for data-efficient no-reference image quality assessment. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 22–31, 2024
2024
-
[29]
Blindly Assess Image Quality in the Wild Guided by a Self-Adaptive Hyper Network
Su, Shaolin and Yan, Qingsen and Zhu, Yu and Zhang, Cheng and Ge, Xin and Sun, Jinqiu and Zhang, Yanning. Blindly Assess Image Quality in the Wild Guided by a Self-Adaptive Hyper Network. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3664–3673, 2020
2020
-
[30]
Triqa: Image Quality Assessment by Contrastive Pretraining on Ordered Distortion Triplets
Sureddi, Rajesh and Zadtootaghaj, Saman and Barman, Nabajeet and Bovik, Alan C. Triqa: Image Quality Assessment by Contrastive Pretraining on Ordered Distortion Triplets. In2025 IEEE International Conference on Image Processing (ICIP), pages 1744–1749, 2025
2025
-
[31]
and Wu, Chengyang and Bovik, Alan C
Venkataramanan, Abhinau K. and Wu, Chengyang and Bovik, Alan C. and Katsavounidis, Ioannis and Shahid, Zafar. A Hitchhiker’s Guide to Structural Similarity.IEEE Access, 9:28872–28896, 2021
2021
-
[32]
Zhou Wang and Alan C. Bovik. Mean squared error: Love it or leave it? a new look at signal fidelity measures.IEEE Signal Processing Magazine, 26(1):98–117, 2009
2009
-
[33]
Qpt-v2: Masked image modeling advances visual scoring
Qizhi Xie, Kun Yuan, Yunpeng Qu, Mingda Wu, Ming Sun, Chao Zhou, and Jihong Zhu. Qpt-v2: Masked image modeling advances visual scoring. InProceedings of the 32nd ACM International Conference on Multimedia, pages 2709–2718, 2024
2024
-
[34]
Blind image quality assessment based on high order statistics aggregation.IEEE Transactions on Image Processing, 25(9): 4444–4457, 2016
Jingtao Xu, Peng Ye, Qiaohong Li, Haiqing Du, Yong Liu, and David Doermann. Blind image quality assessment based on high order statistics aggregation.IEEE Transactions on Image Processing, 25(9): 4444–4457, 2016
2016
-
[35]
Unsupervised feature learning framework for no-reference image quality assessment
Ye, Peng and Kumar, Jayant and Kang, Le and Doermann, David. Unsupervised feature learning framework for no-reference image quality assessment. In2012 IEEE conference on computer vision and pattern recognition, pages 1098–1105. IEEE, 2012. 17
2012
-
[36]
From patches to pictures (PaQ-2-PiQ): Mapping the perceptual space of picture quality
Ying, Zhenqiang and Niu, Haoran and Gupta, Praful and Mahajan, Dhruv and Ghadiyaram, Deepti and Bovik, Alan. From patches to pictures (PaQ-2-PiQ): Mapping the perceptual space of picture quality. In Proc. IEEE Conf. Comput. Vision Pattern Recognit., pages 3575–3585, 2020
2020
-
[37]
A Probabilistic Quality Representation Approach to Deep Blind Image Quality Prediction
Zeng, Hui and Zhang, Lei and Bovik, Alan C. A probabilistic quality representation approach to deep blind image quality prediction.arXiv preprint arXiv:1708.08190, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
The unreasonable effectiveness of deep features as a perceptual metric
Zhang, Richard and Isola, Phillip and Efros, Alexei A and Shechtman, Eli and Wang, Oliver. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[39]
Blind image quality assessment using a deep bilinear convolutional neural network.IEEE Transactions on Circuits and Systems for Video Technology, 30(1):36–47, 2018
Zhang, Weixia and Ma, Kede and Yan, Jia and Deng, Dexiang and Wang, Zhou. Blind image quality assessment using a deep bilinear convolutional neural network.IEEE Transactions on Circuits and Systems for Video Technology, 30(1):36–47, 2018
2018
-
[40]
and Sheikh, H.R
Zhou Wang and Bovik, A.C. and Sheikh, H.R. and Simoncelli, E.P. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004. 18
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.