Toward Parking Spot Occupancy Recognition: A Self-Supervised Approach
Pith reviewed 2026-06-26 17:56 UTC · model grok-4.3
The pith
A two-stage self-supervised protocol reaches 97.8 percent accuracy on parking occupancy using no labels from the target lot.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
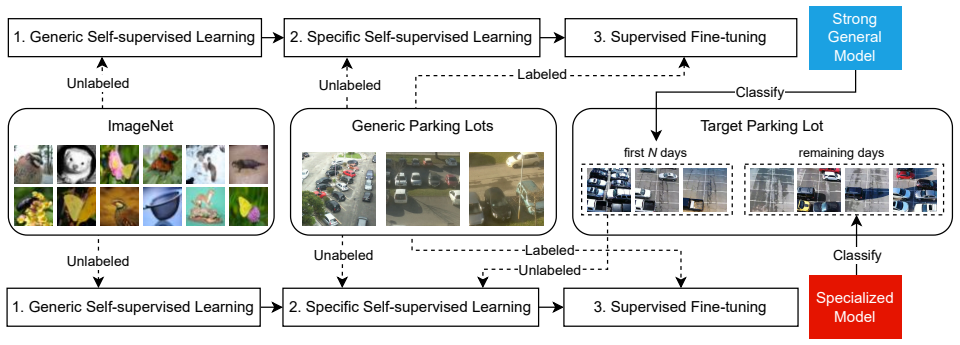
The paper claims that the two-stage self-supervised training strategy produces a Strong General Model that outperforms supervised and self-supervised baselines at 97.2 percent average accuracy across the three datasets and that adding a Specialized Model stage trained self-supervised on the first N days of target unlabeled images raises accuracy to 97.8 percent, thereby enabling effective parking spot monitoring without target labels.
What carries the argument
Two-stage self-supervised pretraining protocol that first learns from generic unlabeled data then adapts to target-specific unlabeled data before supervised fine-tuning on generic labels.
If this is right
- Parking occupancy can be monitored at high accuracy in new locations without collecting or labeling any local images.
- The two-stage deployment allows an initial general model to be installed immediately and then improved automatically from unlabeled data gathered in the first days of use.
- The approach generalizes across different parking environments as shown by the leave-one-out evaluation on three distinct datasets.
- Only generic labeled data is required for the final supervised step, reducing the annotation burden for each new deployment.
Where Pith is reading between the lines
- The same two-stage pattern could be tested on other fixed-camera tasks where environments change but labels remain scarce.
- Varying the number of days N used for the target stage would reveal how quickly adaptation saturates in practice.
- If the generic pretraining already encodes most useful features, the second stage may add diminishing returns once N exceeds a small threshold.
Load-bearing premise
The accuracy gains from the second self-supervised stage arise from learning features specific to the target lot rather than from the mere addition of extra training steps or from statistics already present in the generic pretraining.
What would settle it
Retraining the specialized model on the same generic data but replacing the first N days of target images with either random unrelated images or images from a different lot and measuring no accuracy improvement would falsify the benefit of the target adaptation stage.
Figures




read the original abstract
As urban areas expand, automatic monitoring of parking lots becomes essential for efficient and sustainable cities. This work proposes a self-supervised approach for parking spot occupancy recognition that requires no labeled samples from the target parking lot. Building upon a self-supervised transfer learning fine-tuning protocol, the proposed training strategy consists of two self-supervised stages: first on unlabeled generic data and then on unlabeled target-specific data, followed by supervised fine-tuning using only generic parking lot labels. We adopt SimCLR with a ResNet-50 encoder and evaluate the method under a leave-one-out cross-environment protocol on three public datasets: PKLot, CNRPark-EXT, and PLds. We also introduce a two-stage deployment strategy in which a Strong General Model is initially deployed, followed by a Specialized Model that incorporates unlabeled images collected during the first N days of deployment in a self-supervised manner. Experimental results show that the Strong General Model alone outperforms supervised and self-supervised baselines, achieving an average accuracy of 97.2%, which further improves to 97.8% with the proposed two-stage strategy. These results demonstrate that self-supervised learning enables a scalable and labelefficient solution for real-world parking occupancy monitoring. Our trained models and source code are publicly available at https://github.com/LoanMaikon/Parking-Spot-Occupancy-Recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a self-supervised approach for parking spot occupancy recognition that avoids the need for labeled data from the target parking lot. It employs SimCLR with a ResNet-50 backbone in two self-supervised pretraining stages—first on generic unlabeled data and then on target-specific unlabeled data—followed by supervised fine-tuning using only labels from generic parking lots. The method is evaluated under a leave-one-out cross-environment protocol on three public datasets (PKLot, CNRPark-EXT, PLds), with a proposed two-stage deployment where a Strong General Model is followed by a Specialized Model pretrained on the first N days of target images. The paper reports that the Strong General Model achieves 97.2% average accuracy, improving to 97.8% with the two-stage strategy.
Significance. If the reported gains hold under proper controls, this work offers a practical, label-efficient solution for adapting occupancy recognition models to new environments, which is valuable for real-world urban applications. The public availability of trained models and source code strengthens the contribution by enabling reproducibility.
major comments (3)
- [Abstract and experimental results] Abstract and results: The headline improvement from 97.2% to 97.8% with the two-stage strategy lacks an ablation study on the N-day window for target-specific pretraining. Without comparing against simply continuing generic pretraining for equivalent steps or analyzing the representativeness of the first N days, it is unclear whether the gains are attributable to the proposed method or to dataset-specific statistics captured in those initial days.
- [Experimental setup] Experimental setup: No error bars, standard deviations, or details on the number of runs are provided for the accuracy metrics, and baseline implementations lack sufficient detail for verification, making the outperformance claims difficult to assess rigorously.
- [Methods section on two-stage deployment] Methods on deployment strategy: The description of the Specialized Model does not include controls to isolate the effect of self-supervised pretraining on target data from potential confounds like the choice of N or atypical conditions in the initial deployment period.
minor comments (1)
- [Abstract] The term 'labelefficient' in the abstract should be hyphenated as 'label-efficient'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the experimental rigor and clarity of the work.
read point-by-point responses
-
Referee: [Abstract and experimental results] The headline improvement from 97.2% to 97.8% with the two-stage strategy lacks an ablation study on the N-day window for target-specific pretraining. Without comparing against simply continuing generic pretraining for equivalent steps or analyzing the representativeness of the first N days, it is unclear whether the gains are attributable to the proposed method or to dataset-specific statistics captured in those initial days.
Authors: We agree that an ablation study on the N-day window would strengthen the claims. In the revised manuscript, we will add experiments varying N and comparing the two-stage target pretraining against extending generic pretraining for an equivalent number of steps. This will help confirm that the observed gains stem from target-domain adaptation rather than additional training or initial-period statistics. revision: yes
-
Referee: [Experimental setup] No error bars, standard deviations, or details on the number of runs are provided for the accuracy metrics, and baseline implementations lack sufficient detail for verification, making the outperformance claims difficult to assess rigorously.
Authors: We acknowledge this limitation in the current presentation. We will rerun all experiments over multiple random seeds (reporting mean and standard deviation) and expand the methods and supplementary material with full baseline implementation details, including hyperparameters and training protocols, to enable rigorous verification. revision: yes
-
Referee: [Methods section on two-stage deployment] The description of the Specialized Model does not include controls to isolate the effect of self-supervised pretraining on target data from potential confounds like the choice of N or atypical conditions in the initial deployment period.
Authors: This is a valid concern regarding potential confounds. We will revise the methods section to explicitly address these issues and include additional controlled experiments, such as testing alternative periods or random subsets for the target pretraining stage, to better isolate the contribution of self-supervised adaptation on target data. revision: yes
Circularity Check
No circularity: empirical results on independent public datasets under leave-one-out protocol
full rationale
The paper reports measured accuracies (97.2% to 97.8%) from SimCLR pretraining + supervised fine-tuning on three public datasets (PKLot, CNRPark-EXT, PLds) using leave-one-out cross-environment evaluation. No equations, parameters, or derivations are present that reduce any reported quantity to a fitted input or self-citation by construction. The two-stage strategy is an empirical protocol whose gains are externally falsifiable on held-out data; the code and models are released for reproduction. This is a standard self-contained empirical ML evaluation with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Representations learned by SimCLR on unlabeled generic images remain useful after a second self-supervised stage on target unlabeled images
Reference graph
Works this paper leans on
-
[1]
Smart parking sensors, technologies and applications for open parking lots: a review,
V . Paidi, H. Fleyeh, J. H ˚akansson, and R. G. Nyberg, “Smart parking sensors, technologies and applications for open parking lots: a review,” IET Intelligent Transport Systems, vol. 12, no. 8, pp. 735–741, 2018
2018
-
[2]
Pklot – a robust dataset for parking lot classification,
P. R. de Almeida, L. S. Oliveira, A. S. Britto, E. J. Silva, and A. L. Koerich, “Pklot – a robust dataset for parking lot classification,”Expert Systems with Applications, vol. 42, no. 11, pp. 4937–4949, 2015
2015
-
[3]
Deep learning for decentralized parking lot occupancy detection,
G. Amato, F. Carrara, F. Falchi, C. Gennaro, C. Meghini, and C. Vairo, “Deep learning for decentralized parking lot occupancy detection,” Expert Systems with Applications, vol. 72, pp. 327–334, 2017
2017
-
[4]
Automatic vacant parking places management system using multicamera vehicle detection,
R. Mart ´ın Nieto, ´A. Garc ´ıa-Mart´ın, A. G. Hauptmann, and J. M. Mart´ınez, “Automatic vacant parking places management system using multicamera vehicle detection,”IEEE Transactions on Intelligent Trans- portation Systems, vol. 20, no. 3, pp. 1069–1080, 2019
2019
-
[5]
A systematic review on computer vision-based parking lot management applied on public datasets,
P. R. L. De Almeida, J. H. Alves, R. S. Parpinelli, and J. P. Barddal, “A systematic review on computer vision-based parking lot management applied on public datasets,”ESWA, vol. 198, p. 116731, 2022
2022
-
[6]
Deep single models vs. ensembles: Insights for a fast deployment of parking monitoring systems,
A. G. Hochuli, J. Barddal, G. Palhano, L. Mendes, and P. L. de Almeida, “Deep single models vs. ensembles: Insights for a fast deployment of parking monitoring systems,” inICMLA, 2023, pp. 1379–1384
2023
-
[7]
Evaluation of different annotation strategies for deployment of parking spaces classification systems,
A. G. Hochuli, A. S. Britto, P. R. de Almeida, W. B. Alves, and F. M. Cagni, “Evaluation of different annotation strategies for deployment of parking spaces classification systems,” inIJCNN. IEEE, 2022, pp. 1–8
2022
-
[8]
Optimizing parking space classification: Distilling ensembles into lightweight classifiers,
P. L. Alves, A. Hochuli, L. E. de Oliveira, and P. L. de Almeida, “Optimizing parking space classification: Distilling ensembles into lightweight classifiers,” inICMLA, 2024, pp. 1016–1020
2024
-
[9]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inInternational Conference on Machine Learning (ICML), 2020, pp. 1597–1607
2020
-
[10]
Big self-supervised models advance medical image classification,
S. Aziziet al., “Big self-supervised models advance medical image classification,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 3478–3488
2021
-
[11]
ImageNet Large Scale Visual Recognition Challenge,
O. Russakovskyet al., “ImageNet Large Scale Visual Recognition Challenge,”IJCV, vol. 115, no. 3, pp. 211–252, 2015
2015
-
[12]
Momentum contrast for unsupervised visual representation learning,
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9729–9738
2020
-
[13]
Unsupervised learning of visual features by contrasting cluster assign- ments,
M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, and A. Joulin, “Unsupervised learning of visual features by contrasting cluster assign- ments,”Advances in Neural Information Processing Systems, vol. 33, pp. 9912–9924, 2020
2020
-
[14]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inIEEE/CVF ICCV, 2021, pp. 9650–9660
2021
-
[15]
Self-supervised learning from images with a joint-embedding predictive architecture,
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y . LeCun, and N. Ballas, “Self-supervised learning from images with a joint-embedding predictive architecture,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 15 619–15 629
2023
-
[16]
Learning classification with unlabeled data,
V . de Sa, “Learning classification with unlabeled data,” inAdvances in Neural Information Processing Systems, vol. 6, 1993
1993
-
[17]
Unsupervised visual represen- tation learning by context prediction,
C. Doersch, A. Gupta, and A. A. Efros, “Unsupervised visual represen- tation learning by context prediction,” inIEEE International Conference on Computer Vision (ICCV), 2015, pp. 1422–1430
2015
-
[18]
Unsupervised learning of visual represen- tations by solving jigsaw puzzles,
M. Noroozi and P. Favaro, “Unsupervised learning of visual represen- tations by solving jigsaw puzzles,” inECCV, 2016, pp. 69–84
2016
-
[19]
Context encoders: Feature learning by inpainting,
D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros, “Context encoders: Feature learning by inpainting,” inIEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2536–2544
2016
-
[20]
A cookbook of self-supervised learning,
R. Balestriero, M. Ibrahim, V . Sobal, A. Morcos, S. Shekhar, T. Gold- stein, F. Bordes, A. Bardes, G. Mialon, Y . Tianet al., “A cookbook of self-supervised learning,”arXiv preprint arXiv:2304.12210, 2023
-
[21]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.