Towards Real-World Ultrasound Understanding: Large Vision-Language Models from Multi-Image Examinations with Long-Form Reports
Pith reviewed 2026-07-03 15:57 UTC · model grok-4.3
The pith
Scaling to 1.5 million real ultrasound exams with report alignment lets a standard vision-language model outperform complex prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
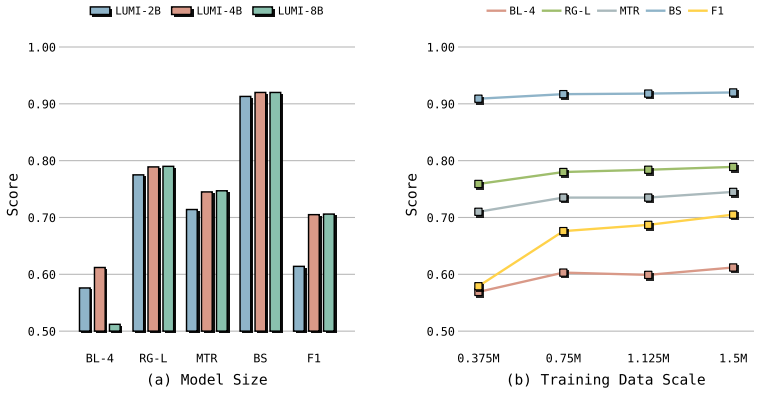
The central claim is that data scale together with examination-level alignment of multiple images to uncurated long-form reports is sufficient; fine-tuning a standard large vision-language model with low-rank adaptation on 1.5 million such examinations yields strong performance on diverse ultrasound understanding tasks and surpasses prior methods that rely on more complex pipelines.
What carries the argument
Examination-level organization that pairs multiple ultrasound images from one clinical exam with its corresponding long-form report to supply clinically faithful supervision.
If this is right
- The approach works across diverse ultrasound understanding tasks without task-specific modifications to the model.
- Model and data scaling analyses reveal how performance changes with increased volume of examinations.
- The method mirrors real clinical workflows because multiple images are aligned to one report.
- No elaborate architectures or training strategies are required to reach competitive results.
Where Pith is reading between the lines
- The same scale-plus-alignment recipe may transfer to other imaging modalities that generate long clinical reports.
- Further gains could appear if the dataset size grows beyond 1.5 million examinations while keeping the same alignment structure.
- Models trained this way might reduce reliance on manual expert annotation for new ultrasound applications.
- The results raise the question of whether report quality thresholds exist beyond which additional curation stops helping.
Load-bearing premise
Uncurated clinical reports contain sufficient and accurate information to provide effective supervision signals for model training without additional filtering or processing.
What would settle it
A head-to-head evaluation on the same ultrasound tasks where the model trained on the 1.5 million examinations does not exceed the accuracy of earlier specialized methods that use curated data or custom architectures.
Figures
read the original abstract
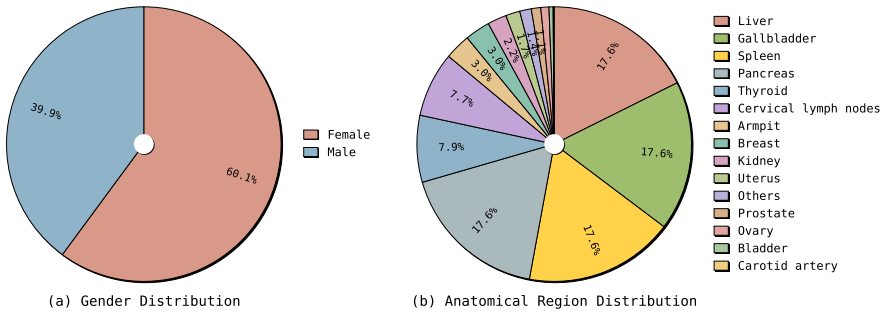
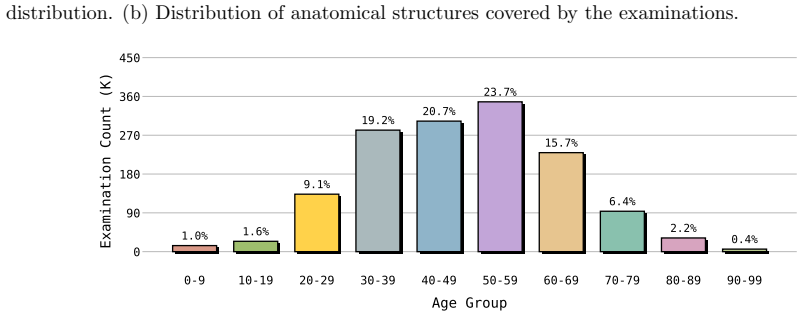
Large vision-language models (LVLMs) have achieved strong performance across many medical imaging tasks, yet their application to ultrasound remains limited due to its inherent complexity and variability. In this work, we revisit what is truly needed to enable real-world ultrasound understanding. Instead of introducing complex architectures or elaborate training strategies, we show that data scale and clinically faithful data alignment are the key factors. We construct a large-scale dataset of 1.5M real-world ultrasound examinations, containing 17.7M images, multi-organ coverage, and paired uncurated clinical reports. Crucially, we organize the data at the examination level, aligning multiple images with their corresponding reports to reflect real clinical workflows. We then fine-tune a standard LVLM using low-rank adaptation (LoRA) on this dataset without task-specific modifications. Surprisingly, this simple recipe already leads to strong performance across diverse ultrasound understanding tasks, outperforming prior methods designed with more complex pipelines. Beyond these results, we present model and data scaling analyses that provide insights into the role of scale in ultrasound LVLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs a dataset of 1.5M real-world ultrasound examinations (17.7M images) paired with uncurated clinical reports at the examination level. It fine-tunes a standard LVLM via LoRA on this data without task-specific changes and claims that data scale plus clinically faithful alignment suffice to achieve strong performance on diverse ultrasound understanding tasks, outperforming prior methods that use more complex pipelines. Scaling analyses are also presented.
Significance. If the empirical results hold under rigorous evaluation, the work would be significant for showing that examination-level alignment with real clinical reports can be more impactful than architectural or training innovations in medical LVLMs. The large-scale, multi-organ dataset construction itself is a concrete contribution that could support future reproducible research.
major comments (2)
- [Abstract] Abstract: the central claim that uncurated reports already supply effective supervision (leading to outperformance over complex pipelines) is load-bearing but unsupported by any reported ablation, report-quality analysis, or comparison isolating alignment from raw volume; without this, gains could be explained by data scale alone.
- [Abstract] Abstract: no quantitative results, baselines, metrics, or evaluation protocols are described, preventing assessment of the 'strong performance' and 'outperforming' assertions; this is required to substantiate the empirical claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We will revise it to include quantitative results and to more precisely describe the contributions of examination-level alignment with uncurated reports versus data volume alone.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that uncurated reports already supply effective supervision (leading to outperformance over complex pipelines) is load-bearing but unsupported by any reported ablation, report-quality analysis, or comparison isolating alignment from raw volume; without this, gains could be explained by data scale alone.
Authors: The manuscript presents scaling analyses that vary data volume while keeping the examination-level alignment fixed, and shows outperformance relative to prior methods that employ different data organizations. We acknowledge, however, that the current version does not contain an explicit ablation that isolates report curation quality or alignment from raw volume. We will revise the abstract to qualify the central claim accordingly and to direct readers to the scaling experiments in the main text. revision: yes
-
Referee: [Abstract] Abstract: no quantitative results, baselines, metrics, or evaluation protocols are described, preventing assessment of the 'strong performance' and 'outperforming' assertions; this is required to substantiate the empirical claim.
Authors: We agree that the abstract would be improved by the inclusion of concrete numbers. In the revised version we will add the primary task metrics, the main baselines, and a concise statement of the evaluation protocol. revision: yes
Circularity Check
No circularity; purely empirical dataset construction and fine-tuning results
full rationale
The paper contains no equations, derivations, or load-bearing self-citations. Its central claim rests on constructing a new 1.5M-examination dataset and reporting LoRA fine-tuning outcomes on standard LVLM backbones. Performance is measured against external benchmarks and prior methods; nothing reduces by construction to fitted parameters or renamed inputs. The reader's assessment of score 1.0 is consistent with the absence of any self-definitional, fitted-prediction, or uniqueness-imported steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Uncurated clinical reports provide high-quality supervision for ultrasound image understanding
Reference graph
Works this paper leans on
-
[1]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, JingJing Xie, Zehao Li, Bowen Yang, Yuchen Duan, Xuehui Wang, Zhi Hou,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Qwen Team. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Kimi Team. Kimi-VL technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
LLaVA-OneVision: Easy visual task transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. LLaVA-OneVision: Easy visual task transfer. Transactions on Machine Learning Research, 2025
2025
-
[5]
HuatuoGPT-Vision: Towards injecting medical visual knowledge into multimodal LLMs at scale
Junying Chen, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Ruifei Zhang, Zhenyang Cai, Ke Ji, Guangjun Yu, Xiang Wan, and Benyou Wang. HuatuoGPT-Vision: Towards injecting medical visual knowledge into multimodal LLMs at scale. arXiv preprint arXiv:2406.19280, 2024
-
[6]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
LASA Team, Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, Yu Sun, Junao Shen, Chaojun Wang, Jie Tan, Deli Zhao, Tingyang Xu, Hao Zhang, and Yu Rong. Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Andrew Sellergren, Chufan Gao, Fereshteh Mahvar, Timo Kohlberger, Fayaz Jamil, Madeleine Traverse, Alberto Tono, Bashir Sadjad, Lin Yang, Charles Lau, Liron Yatziv, Tiffany L. Chen, Bram Sterling, Kenneth Philbrick, Richa Tiwari, Yun Liu, Madhuram Jajoo, Chandrashekar Sankarapu, Swapnil Vispute, Harshad Purandare, Abhishek Bijay Mishra, Samuel Schmidgall,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
R2GenGPT: Radiology report gener- ation with frozen LLMs.arXiv preprint arXiv:2309.09812, 2023
Zhanyu Wang, Lingqiao Liu, Lei Wang, and Luping Zhou. R2GenGPT: Radiology report gener- ation with frozen LLMs.arXiv preprint arXiv:2309.09812, 2023
-
[9]
LLaVA-Med: Training a large language-and-vision assistant for biomedicine in one day
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. LLaVA-Med: Training a large language-and-vision assistant for biomedicine in one day. InNeurIPS, 2023
2023
-
[10]
Med-Flamingo: A multimodal medical few-shot learner
Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Yash Dalmia, Jure Leskovec, Cyril Zakka, Eduardo Pontes Reis, and Pranav Rajpurkar. Med-Flamingo: A multimodal medical few-shot learner. InMachine Learning for Health Symposium, PMLR, 2023
2023
-
[11]
Chunlei Li, Jingyang Hou, Yilei Shi, Jingliang Hu, Xiao Xiang Zhu, and Lichao Mou. Multimodal large language models for medical report generation via customized prompt tuning.arXiv preprint arXiv:2506.15477, 2025
-
[12]
HealthGPT: A medical large vision-language model for unifying comprehension and generation via heterogeneous knowledge adaptation
Tianwei Lin, Wenqiao Zhang, Sijing Li, Yuqian Yuan, Binhe Yu, Haoyuan Li, Wanggui He, Hao Jiang, Mengze Li, Xiaohui Song, et al. HealthGPT: A medical large vision-language model for unifying comprehension and generation via heterogeneous knowledge adaptation. InICML, 2025
2025
-
[13]
USFM: A universal ultrasound foundation model generalized to tasks and organs towards label-efficient image analysis.Medical Image Analysis, 96:103202, 2024
Jing Jiao, Jin Zhou, Xiaokang Li, Menghua Xia, Yi Huang, Lihong Huang, Na Wang, Xiaofan Zhang, Shichong Zhou, Yuanyuan Wang, and Yi Guo. USFM: A universal ultrasound foundation model generalized to tasks and organs towards label-efficient image analysis.Medical Image Analysis, 96:103202, 2024
2024
-
[14]
Hongyuan Zhang, Yuheng Wu, Mingyang Zhao, Zhiwei Chen, Rebecca Li, Fei Zhu, Haohan Zhao, Xiaohua Yuan, Meng Yang, Chunli Qiu, Xiang Cong, Haiyan Chen, Lina Luan, Randolph H. L. Wong, Huai Liao, Colin A. Graham, Shi Chang, Guowei Tao, Dong Yi, Zhen Lei, Nassir Navab, S´ ebastien Ourselin, Jiebo Luo, Hongbin Liu, and Gaofeng Meng. A fully open and generaliz...
-
[15]
Vision-Language foun- dation model for echocardiogram interpretation.Nature Medicine, 30:1481–1488, 2024
Matthew Christensen, Miloˇ s Vukadinovic, Neal Yuan, and David Ouyang. Vision-Language foun- dation model for echocardiogram interpretation.Nature Medicine, 30:1481–1488, 2024. 8
2024
-
[16]
Comprehensive echocardiogram evaluation with view-primed vision-language AI.Nature, 650:970–977, 2025
Miloˇ s Vukadinovic, I-Min Chiu, Xiu Tang, Neal Yuan, Tien-Yu Chen, Paul Cheng, Debiao Li, Susan Cheng, Bryan He, and David Ouyang. Comprehensive echocardiogram evaluation with view-primed vision-language AI.Nature, 650:970–977, 2025
2025
-
[17]
Maani, Numan Saeed, Tausifa Jan Saleem, Zaid Farooq, Hussain Alasmawi, Werner Diehl, Ameera Mohammad, Gareth Waring, Saudabi Valappi, Leanne Bricker, and Mohammad Yaqub
Fadillah A. Maani, Numan Saeed, Tausifa Jan Saleem, Zaid Farooq, Hussain Alasmawi, Werner Diehl, Ameera Mohammad, Gareth Waring, Saudabi Valappi, Leanne Bricker, and Mohammad Yaqub. FetalCLIP: A visual-language foundation model for fetal ultrasound image analysis.npj Digital Medicine, 2025
2025
-
[18]
Papageorghiou, and J
Xiaoqing Guo, Mohammad Alsharid, He Zhao, Yipei Wang, Jayne Lander, Aris T. Papageorghiou, and J. Alison Noble. A visually grounded language model for fetal ultrasound understanding. Nature Biomedical Engineering, 2026
2026
-
[19]
Ultrasound-CLIP: Semantic-Aware contrastive pre-training for ultrasound image-text understanding
Jiayun Jin, Haolong Chai, Xueying Huang, Xiaoqing Guo, Zengwei Zheng, Zhan Zhou, Junmei Wang, Xinyu Wang, Jie Liu, and Binbin Zhou. Ultrasound-CLIP: Semantic-Aware contrastive pre-training for ultrasound image-text understanding. InCVPR, 2026
2026
-
[20]
Dolphin v1.0 technical report.arXiv preprint arXiv:2509.25748, 2025
Taohan Weng, Chi Zhang, Chaoran Yan, Siya Liu, Xiaoyang Liu, Yalun Wu, Boyang Wang, Boyan Wang, Jiren Ren, Kaiwen Yan, Jinze Yu, Kaibing Hu, Henan Liu, Haoyun Zheng, Zhenyu Liu, Duo Zhang, Xiaoqing Guo, Anjie Le, and Hongcheng Guo. Dolphin v1.0 technical report.arXiv preprint arXiv:2509.25748, 2025
-
[21]
LLAUS: A high-quality instruction-tuned large vision language assistant for ultrasound
Junhao Guo, Xuefeng Shan, Guoming Wang, Dong Chen, Rongxing Lu, and Siliang Tang. LLAUS: A high-quality instruction-tuned large vision language assistant for ultrasound. InICMR, 2025
2025
-
[22]
Shijie Wang, Yilun Zhang, Zeyu Lai, and Dexing Kong. HAIBU-ReMUD: Reasoning mul- timodal ultrasound dataset and model bridging to general specific domains.arXiv preprint arXiv:2506.07837, 2025
-
[23]
Dengbo Chen, Ziwei Zhao, Kexin Zhang, Shishuang Zhao, Junjie Hou, Yaqian Wang, Nianxi Liao, Anlan Sun, Fei Gao, Jia Ding, Yuhang Liu, and Dong Wang. UMind-VL: A generalist ultrasound vision-language model for unified grounded perception and comprehensive interpretation.arXiv preprint arXiv:2511.22256, 2025
-
[24]
EchoVLM: Dynamic Mixture-of-Experts Vision-Language Model for Universal Ultrasound Intelligence
Chaoyin She, Ruifang Lu, Lida Chen, Wei Wang, and Qinghua Huang. EchoVLM: Dynamic mixture-of-experts vision-language model for universal ultrasound intelligence.arXiv preprint arXiv:2509.14977, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Improved baselines with visual instruc- tion tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruc- tion tuning. InCVPR, 2024
2024
-
[26]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-Pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025. 9 Case 1: Thyroid Examination (with suspected Hashimoto thyroiditis and multinodular goiter) Human Report Ultrasound Findings Cerv...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Fatty liver. 2. Multiple hypoechoic hepatic lesions, likely benign, without significant interval change compared with prior examination. 3. Multiple hepatic cysts. 4. Multiple polypoid lesions of the gallbladder wall. LUMI Ultrasound Findings The liver is enlarged with a smooth surface and blunt edges. Multiple cystic lesions are observed within the liver...
-
[28]
Heterogeneous hypoechoic lesion in the right hepatic lobe; contrast-enhanced ultrasound examination is recommended. 2. Multiple hepatic cysts. 3. Fatty liver. 4. Multiple polypoid lesions of the gallbladder wall. Qwen3.5-27B Ultrasound Findings The liver is normal in size and morphology with a smooth capsule. The hepatic parenchyma demonstrates coarse ech...
-
[29]
Solid lesion in the right hepatic lobe, most likely hepatic hemangioma; regular follow-up is recommended. 2. Multiple hepatic cysts. 3. Gallbladder stone in the neck/cystic duct region. 4. Coarse hepatic echogenicity, suggestive of fatty liver or chronic liver injury. InternVL3.5-38B-Instruct Ultrasound Findings Multiple sections of the liver at different...
-
[30]
Multiple uterine fibroids with relatively abundant vascularity. 2. Bilateral ovarian cysts, the largest measuring approximately 2.0 × 1.5 cm in the right adnexal region. 3. Clinical follow-up is recommended. InternVL3.5-38B-Instruct Ultrasound Findings The uterus is normal in size and morphology without obvious abnormal intracavitary echogenicity. A mixed...
-
[31]
Benign prostatic hyperplasia with prostatic calcifications. 2. Multiple prostatic cysts. 3. Hypoechoic lesion in the left peripheral zone of the prostate; MRI examination is recommended, and ultrasound-guided biopsy may be considered if necessary. LUMI Ultrasound Findings Transrectal ultrasound examination was performed. The prostate measures approximatel...
-
[32]
Hypoechoic lesion in the right peripheral zone of the prostate; correlation with serum PSA and MRI examination is recommended. 2. Benign prostatic hyperplasia with prostatic calcifications. 3. Multiple prostatic cysts. Qwen3.5-27B Ultrasound Findings Transvaginal ultrasound examination demonstrates an anteverted uterus with enlarged size and full morpholo...
-
[33]
Multiple uterine fibroids. 2. Enlarged uterus. InternVL3.5-38B-Instruct Ultrasound Findings The uterus is normal in size and morphology with homogeneous endometrial thickness. A hypoechoic lesion is observed in the posterior uterine wall, measuring approximately 12.43 × 10.28 × 9.14 mm, with clear margins and heterogeneous internal echogenicity. CDFI demo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.