EquiSteer: Cross-Attention Steering Towards a Fairer Text-Guided Image Generation
Pith reviewed 2026-07-02 13:28 UTC · model grok-4.3
The pith
EquiSteer reduces demographic bias in text-to-image diffusion models by steering cross-attention activations at inference time using precomputed vectors and a prompt-aware gate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
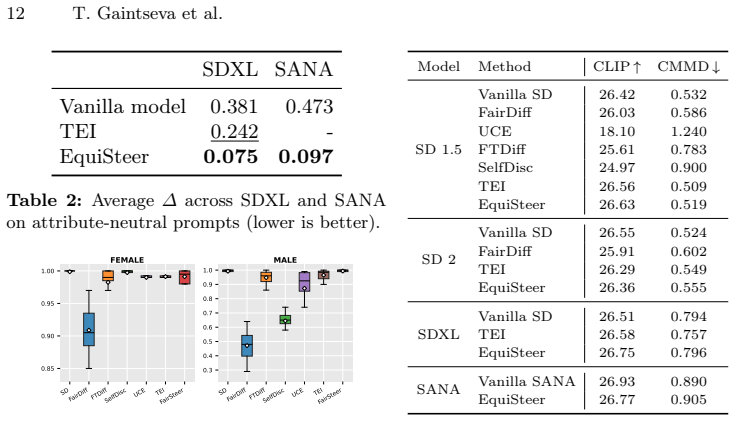
EquiSteer is a training-free method that works per sample by steering cross-attention activations at inference time. For each target attribute it precomputes steering vectors from contrastive prompts. At generation time a prompt-aware gate leaves attribute-specific prompts untouched while for neutral ones it clears existing attribute signals from the CA activations and injects a target attribute. Across SD-1.5, SD-2.1, SDXL, and SANA the method reduces the average parity gap by up to 87 percent with minimal effect on image quality and text-image alignment.
What carries the argument
The prompt-aware gate that selectively clears existing attribute signals from cross-attention activations and injects precomputed steering vectors derived from contrastive prompts.
If this is right
- The method applies without retraining to SD-1.5, SD-2.1, SDXL, and SANA.
- Average parity gap on common demographic attributes drops by as much as 87 percent.
- Image quality and text-image alignment remain essentially unchanged under the metrics used.
- No batch-level control or prompt-specific tuning is required at generation time.
Where Pith is reading between the lines
- The same cross-attention steering pattern could be tested on attributes beyond the gender and race pairs examined here.
- Because the gate operates per prompt, the technique might be combined with user-provided safety filters in deployed systems.
- If the steering vectors prove stable across prompt styles, they could be shared as lightweight bias-correction modules.
Load-bearing premise
Steering vectors derived from contrastive prompts can be selectively injected via a prompt-aware gate without introducing new unintended biases or degrading the generative distribution in ways not captured by the reported metrics.
What would settle it
A test set of neutral prompts where applying EquiSteer either widens the measured parity gap on the target attribute or lowers text-image alignment scores below the baseline model on the same prompts.
Figures


















read the original abstract
Text-to-image diffusion models power everyday creative tasks, but they still reproduce the demographic biases in their training data. On common prompts such as ``a photo of a nurse,'' ``a photo of a CEO'', they skew their outputs toward one gender, driven by the statistics of training data rather than anything in the text. Existing debiasing methods show promise in narrow settings but require retraining, batch-level control, or prompt-specific tuning, limiting their scalability. We propose \emph{EquiSteer}, a training-free method that works per sample by steering cross-attention (CA) activations at inference time. For each target attribute, EquiSteer precomputes steering vectors from contrastive prompts. Then at generation time, a prompt-aware gate leaves attribute-specific prompts untouched, while for neutral ones it clears existing attribute signals from the CA activations and injects a target attribute. Across SD-1.5, SD-2.1, SDXL, and SANA, EquiSteer reduces the average parity gap by up to $87\%$, with minimal effect on image quality and text-image alignment. Code is available at \href{https://github.com/Atmyre/EquiSteer}{https://github.com/Atmyre/EquiSteer}.%
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EquiSteer, a training-free inference-time method for mitigating demographic biases in text-to-image diffusion models. It precomputes steering vectors from contrastive prompts for target attributes and uses a prompt-aware gate to selectively clear and inject attribute signals in cross-attention activations during generation, leaving attribute-specific prompts untouched. Experiments across SD-1.5, SD-2.1, SDXL, and SANA report up to 87% reduction in average parity gap with minimal degradation in image quality and text-image alignment; code is released.
Significance. If the empirical results hold under rigorous validation, EquiSteer would represent a practical advance in scalable bias mitigation for generative models, avoiding retraining or batch-level constraints of prior work. The training-free design and public code release strengthen the contribution by enabling direct reproducibility and extension.
major comments (2)
- [Abstract and §4] Abstract and §4 (experimental protocol): the reported parity-gap reductions (up to 87%) and claims of minimal quality/alignment impact lack explicit definitions of the parity-gap metric, details on baseline implementations, statistical significance testing, or controls for post-hoc prompt/seed selection; without these, the central quantitative claim cannot be fully assessed from the provided information.
- [§3.2] §3.2 (prompt-aware gate): the assumption that selective injection of steering vectors via the gate avoids introducing new unintended biases or altering the generative distribution in unmeasured ways is load-bearing for the fairness claim, yet the manuscript provides no ablation isolating gate-induced side effects on non-target attributes.
minor comments (2)
- [§2-3] Notation for cross-attention activations and steering vectors should be defined once in §2 or §3 with consistent symbols across equations and text.
- [Figures] Figure captions for qualitative examples should explicitly state the prompt, model, and whether the image is before/after steering.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, recognition of the practical contribution, and recommendation for minor revision. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experimental protocol): the reported parity-gap reductions (up to 87%) and claims of minimal quality/alignment impact lack explicit definitions of the parity-gap metric, details on baseline implementations, statistical significance testing, or controls for post-hoc prompt/seed selection; without these, the central quantitative claim cannot be fully assessed from the provided information.
Authors: We agree that greater explicitness will improve clarity. The parity-gap metric is defined in §4 as the absolute difference between the empirical frequencies of each demographic category across generated images for a fixed prompt, then averaged over the prompt set and attribute pairs. Baseline methods are re-implemented from their original papers using the authors’ recommended hyperparameters and the same prompt/seed pool; we will state these settings verbatim in the revised §4. Statistical significance testing was omitted because of the prohibitive cost of repeated full-generation runs across four models, but we will report per-seed variance and add a limitations note. All quantitative results use a fixed set of 10 seeds and the complete prompt list with no post-hoc filtering or selection; we will add an explicit statement of this protocol in both the abstract and §4. revision: yes
-
Referee: [§3.2] §3.2 (prompt-aware gate): the assumption that selective injection of steering vectors via the gate avoids introducing new unintended biases or altering the generative distribution in unmeasured ways is load-bearing for the fairness claim, yet the manuscript provides no ablation isolating gate-induced side effects on non-target attributes.
Authors: We acknowledge that an explicit ablation isolating gate effects on non-target attributes is absent. The gate is intended to remain inactive for attribute-specific prompts, thereby preserving the original distribution for those cases. To directly address the concern, the revised manuscript will include a new ablation (added to §4) that measures parity gaps on unrelated attributes when steering is applied only to a target attribute (e.g., gender parity when steering for race). This will quantify any measurable side effects and will be reported alongside the existing results. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical, training-free inference-time steering method that constructs contrastive steering vectors from external prompts and applies them via a prompt-aware gate. No equations, derivations, or first-principles predictions are presented that reduce the reported parity-gap reductions to fitted parameters, self-definitions, or self-citation chains. The central claims are falsifiable empirical measurements across multiple diffusion models and are not equivalent to their inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.13496 (2025)
Chakraborty, R., Che, X., Xu, D., Faklaris, C., Niu, X., Yuan, S.: Biasmap: Lever- agingcross-attentionstodiscoverandmitigatehiddensocialbiasesintext-to-image generation. arXiv preprint arXiv:2509.13496 (2025)
-
[2]
ACM trans- actions on Graphics (TOG)42(4), 1–10 (2023)
Chefer, H., Alaluf, Y., Vinker, Y., Wolf, L., Cohen-Or, D.: Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. ACM trans- actions on Graphics (TOG)42(4), 1–10 (2023)
2023
-
[3]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Chen, M., Laina, I., Vedaldi, A.: Training-free layout control with cross-attention guidance. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 5343–5353 (2024)
2024
-
[4]
In: European Conference on Computer Vision
Chinchure, A., Shukla, P., Bhatt, G., Salij, K., Hosanagar, K., Sigal, L., Turk, M.: Tibet: Identifying and evaluating biases in text-to-image generative models. In: European Conference on Computer Vision. pp. 429–446. Springer (2024)
2024
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
D’Incà, M., Peruzzo, E., Mancini, M., Xu, D., Goel, V., Xu, X., Wang, Z., Shi, H., Sebe, N.: Openbias: Open-set bias detection in text-to-image generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12225–12235 (2024)
2024
-
[6]
Fair diffusion: instructing text-to- image generation models on fairness
Friedrich, F., Brack, M., Struppek, L., Hintersdorf, D., Schramowski, P., Luccioni, S., Kersting, K.: Fair diffusion: Instructing text-to-image generation models on fairness. arXiv preprint arXiv:2302.10893 (2023)
-
[7]
arXiv preprint arXiv:2510.21363 (2025)
Fu, Z., Brown, R., Shao, S., Rawal, K., Delaney, E., Russell, C.: Fairima- gen: Post-processing for bias mitigation in text-to-image models. arXiv preprint arXiv:2510.21363 (2025)
-
[8]
CASteer: Cross-Attention Steering for Controllable Concept Erasure
Gaintseva, T., Benning, M., Slabaugh, G., Elezi, I.: Casteer: Steering diffusion models for controllable generation. arXiv preprint arXiv:2503.09630 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Gandikota, R., Orgad, H., Belinkov, Y., Materzyńska, J., Bau, D.: Unified concept editing in diffusion models. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 5111–5120 (2024)
2024
-
[10]
arXiv preprint arXiv:2503.23398 (2025)
Girrbach, L., Alaniz, S., Smith, G., Akata, Z.: A large scale analysis of gender biases in text-to-image generative models. arXiv preprint arXiv:2503.23398 (2025)
-
[11]
arXiv preprint arXiv:2509.23639 (2025)
Han, B., Xu, Q., Bao, S., Yang, Z., Zi, K., Huang, Q.: Lightfair: Towards an efficient alternative for fair t2i diffusion via debiasing pre-trained text encoders. arXiv preprint arXiv:2509.23639 (2025)
-
[12]
In: Proceedings of the 1st ACM Multimedia Workshop on Multi-modal Misinformation Governance in the Era of Foundation Models
He, R., Xue, C., Tan, H., Zhang, W., Yu, Y., Bai, S., Qi, X.: Debiasing text-to- image diffusion models. In: Proceedings of the 1st ACM Multimedia Workshop on Multi-modal Misinformation Governance in the Era of Foundation Models. pp. 29–36 (2024)
2024
-
[13]
Prompt-to-Prompt Image Editing with Cross Attention Control
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 7514–7528 (2021)
2021
-
[15]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Jayasumana, S., Ramalingam, S., Veit, A., Glasner, D., Chakrabarti, A., Kumar, S.: Rethinking fid: Towards a better evaluation metric for image generation. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 9307–9315 (2024)
2024
-
[16]
In: EquiSteer: Cross-Attention Steering for Fairer T2I Generation 17 Proceedings of the Computer Vision and Pattern Recognition Conference
Kim, E., Kim, S., Park, M., Entezari, R., Yoon, S.: Rethinking training for de- biasing text-to-image generation: Unlocking the potential of stable diffusion. In: EquiSteer: Cross-Attention Steering for Fairer T2I Generation 17 Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13361–13370 (2025)
2025
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, H., Shen, C., Torr, P., Tresp, V., Gu, J.: Self-discovering interpretable diffusion latent directions for responsible text-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12006– 12016 (2024)
2024
-
[18]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, J., Hu, L., Zhang, J., Zheng, T., Zhang, H., Wang, D.: Fair text-to-image diffusion via fair mapping. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 26256–26264 (2025)
2025
-
[19]
Proceedings of Machine Learning Research, vol
Li, J., Li, D., Xiong, C., Hoi, S.C.H.: BLIP: bootstrapping language-image pre- trainingforunifiedvision-languageunderstandingandgeneration.In:International Conference on Machine Learning, ICML 2022, 17–23 July 2022, Baltimore, Mary- land, USA. Proceedings of Machine Learning Research, vol. 162, pp. 12888–12900. PMLR (2022)
2022
-
[20]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, B., Wang, C., Cao, T., Jia, K., Huang, J.: Towards understanding cross and self-attention in stable diffusion for text-guided image editing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7817– 7826 (2024)
2024
-
[22]
Stable Bias: Analyz- ing Societal Representations in Diffusion Models, 2023
Luccioni, A.S., Akiki, C., Mitchell, M., Jernite, Y.: Stable bias: Analyzing societal representations in diffusion models. arXiv preprint arXiv:2303.11408 (2023)
-
[23]
Yidong Ouyang, Liyan Xie, Hongyuan Zha, and Guang Cheng
Na, B., Park, M., Sim, G., Shin, D., Bae, H., Kang, M., Kwon, S.J., Kang, W., Moon, I.C.: Diffusion adaptive text embedding for text-to-image diffusion models. arXiv preprint arXiv:2510.23974 (2025)
-
[24]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Parihar, R., Bhat, A., Basu, A., Mallick, S., Kundu, J.N., Babu, R.V.: Balanc- ing act: distribution-guided debiasing in diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6668–6678 (2024)
2024
-
[25]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684– 10695 (June 2022)
2022
-
[28]
Scientific Reports15(1), 31401 (2025)
Schneider, M., Hagendorff, T.: Investigating toxicity and bias in stable diffusion text-to-image models. Scientific Reports15(1), 31401 (2025)
2025
-
[29]
In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Seshadri, P., Singh, S., Elazar, Y.: The bias amplification paradox in text-to-image generation. In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 6367–6384 (2024)
2024
-
[30]
Finetuning text-to-image diffusion models for fairness
Shen, X., Du, C., Pang, T., Lin, M., Wong, Y., Kankanhalli, M.: Finetuning text- to-image diffusion models for fairness. arXiv preprint arXiv:2311.07604 (2023)
-
[31]
Journal of Imaging11(2), 35 (2025) 18 T
Wu, Y., Nakashima, Y., Garcia, N.: Revealing gender bias from prompt to image in stable diffusion. Journal of Imaging11(2), 35 (2025) 18 T. Gaintseva et al
2025
-
[32]
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Xie, E., Chen, J., Chen, J., Cai, H., Tang, H., Lin, Y., Zhang, Z., Li, M., Zhu, L., Lu, Y., et al.: Sana: Efficient high-resolution image synthesis with linear diffusion transformers. arXiv preprint arXiv:2410.10629 (2024) Supplementary Material – Contents S1 Limitations ................................................... P1 S2 Future Work .................
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.