Boosting Neural Video Codec via Scale-Driven Online Flow Refinement
Pith reviewed 2026-06-26 09:17 UTC · model grok-4.3
The pith
A training-free plug-in fuses coarse and fine scale motion flows by warping accuracy to fix estimation errors in neural video codecs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
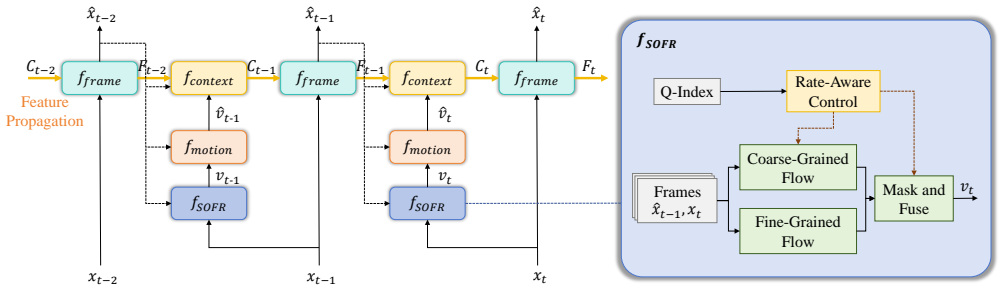
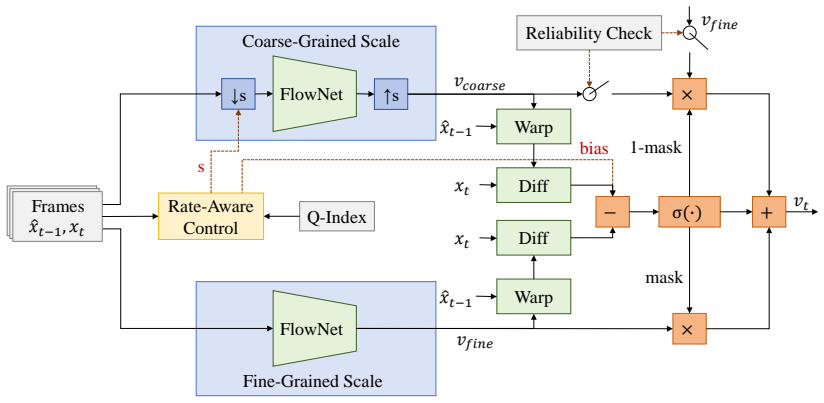
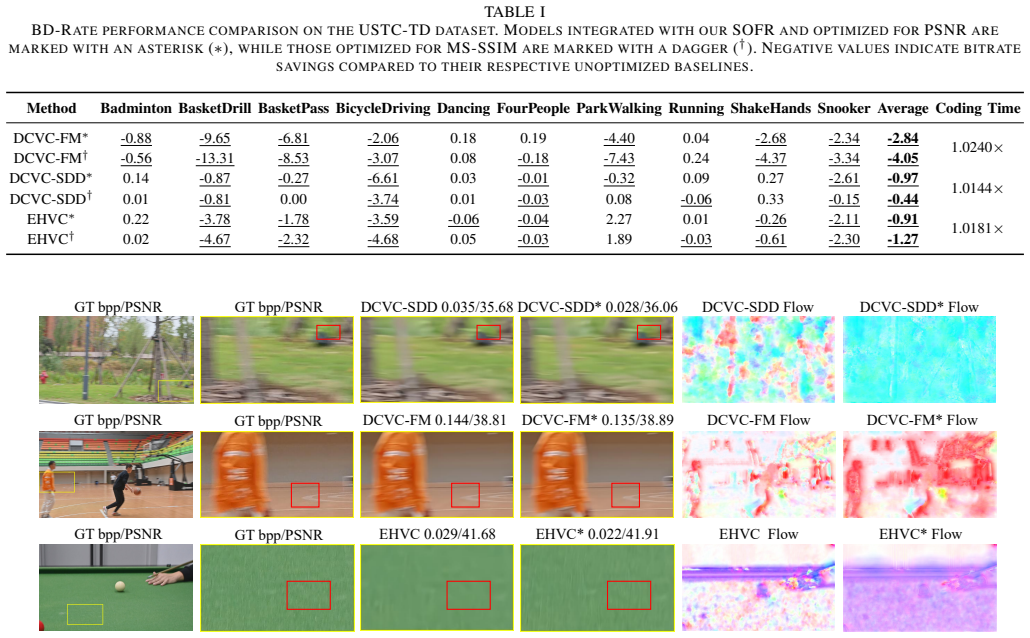
SOFR rectifies motion estimation errors in neural video codecs by integrating coarse- and fine-scale flow fields and fusing them on the fly according to per-pixel warping accuracy, using a rate-aware strategy and reliability check to remain robust; this training-free correction yields average bitrate savings of 2.84 percent under PSNR and 4.05 percent under MS-SSIM on the USTC-TD dataset when inserted into DCVC-FM, DCVC-SDD, and EHVC.
What carries the argument
SOFR module: dynamic fusion of multi-scale motion flows guided by warping accuracy, augmented by a rate-aware selector and warping-error reliability check.
If this is right
- Existing neural codecs can be upgraded at inference time without retraining or fine-tuning.
- Bitrate savings appear consistently across DCVC-SDD, DCVC-FM, and EHVC on the USTC-TD dataset.
- The added overhead remains negligible in coding time while the rate-aware path adapts fusion to different operating points.
- A warping-error reliability check prevents the module from harming performance on difficult frames.
Where Pith is reading between the lines
- The same scale-fusion logic could be tested on non-neural motion-compensated codecs that also rely on optical flow.
- If warping accuracy proves stable across datasets, training sets for future codecs could be smaller because online correction handles the tail of motion distributions.
- The approach suggests that explicit multi-scale fusion at inference may be cheaper than enlarging model capacity to cover every motion pattern.
Load-bearing premise
Warping accuracy will remain a reliable signal for choosing which scale of motion information to trust even on motion patterns never seen in training.
What would settle it
Measure whether inserting SOFR into a base codec on a new set of sequences with complex unseen motion increases total bitrate or lowers PSNR/MS-SSIM relative to the unmodified codec.
Figures
read the original abstract
Although state-of-the-art neural video codecs (NVCs) have achieved remarkable performance, they suffer from limited generalization when encountering complex motion patterns unseen during training. To bridge this domain gap without the expensive cost of online fine-tuning, we propose a Training-Free Scale-Driven Online Flow Refinement (SOFR) method. Serving as a plug-and-play module, SOFR integrates motion information from coarse and fine scales and dynamically fuses them according to warping accuracy, effectively rectifying motion estimation errors with negligible computational overhead. Furthermore, we design a rate-aware strategy that selects different dynamic fusion strategies according to bitrate modes, and employs a reliability check based on warping error to ensure robustness. Extensive experiments on the USTC-TD dataset verify the effectiveness and generalization of SOFR across various NVC frameworks, including DCVC-SDD, DCVC-FM, and EHVC. Notably, it brings an average of 2.84% and 4.05% bitrate savings in terms of PSNR and MS-SSIM, respectively, to DCVC-FM with negligible coding time increase. Our code is available at https://github.com/SunnyMass/SOFR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SOFR, a training-free plug-and-play module for neural video codecs that dynamically fuses coarse- and fine-scale motion information according to a warping-accuracy signal, augmented by a rate-aware fusion strategy and a warping-error reliability check. The central claim is that this online refinement corrects motion-estimation errors on complex patterns absent from the original training distribution, yielding average bitrate savings of 2.84% (PSNR) and 4.05% (MS-SSIM) on DCVC-FM (and gains on DCVC-SDD and EHVC) when evaluated on the USTC-TD dataset, all with negligible coding-time overhead. Code is released at https://github.com/SunnyMass/SOFR.
Significance. If the reported gains are robust, the work would be significant because it offers a low-overhead, training-free route to improving NVC generalization under distribution shift in motion, which is a practical bottleneck for deployment. The public code release is a clear strength that supports reproducibility.
major comments (2)
- [Method description (SOFR fusion and reliability check)] The load-bearing assumption is that the warping-accuracy signal reliably identifies the better scale (or their correct fusion weights) for motion patterns unseen during NVC training. The manuscript provides no analysis or controlled experiment demonstrating that this signal remains informative when both scales are simultaneously inaccurate under distribution shift; if the correlation weakens, the dynamic weights could reinforce rather than mitigate error, undermining the claimed savings.
- [Experiments and results] The 2.84 % / 4.05 % bitrate savings on USTC-TD are attributed entirely to SOFR, yet the experiments section supplies no ablation that isolates the contribution of the dynamic fusion, rate-aware strategy, and reliability check, nor any quantitative comparison of motion-error statistics between the original NVC training distribution and USTC-TD. Without these, attribution of the gains to the proposed mechanism remains unverified.
minor comments (1)
- [Abstract] The abstract states results for three frameworks but does not indicate whether the same hyper-parameters for the reliability threshold and rate-aware modes were used across all three; a short table or sentence clarifying this would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the method and experiments.
read point-by-point responses
-
Referee: [Method description (SOFR fusion and reliability check)] The load-bearing assumption is that the warping-accuracy signal reliably identifies the better scale (or their correct fusion weights) for motion patterns unseen during NVC training. The manuscript provides no analysis or controlled experiment demonstrating that this signal remains informative when both scales are simultaneously inaccurate under distribution shift; if the correlation weakens, the dynamic weights could reinforce rather than mitigate error, undermining the claimed savings.
Authors: We agree that the manuscript would benefit from explicit analysis of the warping-accuracy signal in cases where both scales may be inaccurate. The reliability check based on warping error is designed to detect unreliable signals and fall back to a conservative strategy, but we acknowledge the lack of a controlled experiment isolating this scenario under distribution shift. In the revision we will add such an analysis, including evaluation of signal correlation with ground-truth motion accuracy on held-out complex patterns. revision: yes
-
Referee: [Experiments and results] The 2.84 % / 4.05 % bitrate savings on USTC-TD are attributed entirely to SOFR, yet the experiments section supplies no ablation that isolates the contribution of the dynamic fusion, rate-aware strategy, and reliability check, nor any quantitative comparison of motion-error statistics between the original NVC training distribution and USTC-TD. Without these, attribution of the gains to the proposed mechanism remains unverified.
Authors: We agree that the current experiments lack component-wise ablations and direct quantification of the domain shift. In the revised manuscript we will include ablations that separately disable or vary the dynamic fusion, rate-aware strategy, and reliability check, reporting their individual contributions to the bitrate savings. We will also add quantitative motion-error statistics (e.g., warping-error histograms and mean statistics) comparing the NVC training distributions to USTC-TD to support the generalization claim. revision: yes
Circularity Check
No circularity; empirical training-free method with no self-referential derivations
full rationale
The paper describes a plug-and-play, training-free SOFR module that dynamically fuses coarse/fine-scale motion via warping accuracy and a rate-aware strategy. No equations, derivations, or parameter fits are presented that reduce the reported bitrate savings to inputs defined by the method itself. Claims rest on external empirical validation across NVC frameworks on USTC-TD, with no load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Motion estimation errors in neural video codecs can be corrected post hoc using multi-scale information without retraining the codec.
Reference graph
Works this paper leans on
-
[1]
Overview of the versatile video coding (vvc) standard and its applications,
Benjamin Bross, Ye-Kui Wang, Yan Ye, Shan Liu, Jianle Chen, Gary J Sullivan, and Jens-Rainer Ohm, “Overview of the versatile video coding (vvc) standard and its applications,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 10, pp. 3736–3764, 2021
2021
-
[2]
Image and video compression with neural net- works: A review,
Siwei Ma, Xinfeng Zhang, Chuanmin Jia, Zhenghui Zhao, Shiqi Wang, and Shanshe Wang, “Image and video compression with neural net- works: A review,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 30, no. 6, pp. 1683–1698, 2019
2019
-
[3]
Emerging advances in learned video com- pression: models, systems and beyond,
Chuanmin Jia, Feng Ye, Siwei Ma, Wen Gao, Huifang Sun, and Leonardo Chiariglione, “Emerging advances in learned video com- pression: models, systems and beyond,” inProceedings of the Thirty- Fourth International Joint Conference on Artificial Intelligence, 2025, pp. 10490–10498
2025
-
[4]
Multiple hypotheses based motion compensation for learned video compression,
Rongqun Lin, Meng Wang, Pingping Zhang, Shiqi Wang, and Sam Kwong, “Multiple hypotheses based motion compensation for learned video compression,”Neurocomputing, vol. 548, pp. 126396, 2023
2023
-
[5]
Video enhancement with task-oriented flow,
Tianfan Xue, Baian Chen, Jiajun Wu, Donglai Wei, and William T Freeman, “Video enhancement with task-oriented flow,”International Journal of Computer Vision, vol. 127, no. 8, pp. 1106–1125, 2019
2019
-
[6]
Integrating adaptive sampling for optimal learned video compression,
Wuyang Cong, Yuzhuo Kong, Ming Lu, Lizhong Wang, Weijing Shi, and Zhan Ma, “Integrating adaptive sampling for optimal learned video compression,” inIEEE International Conference on Acoustics, Speech and Signal Processing, 2025
2025
-
[7]
Offline and online optical flow enhancement for deep video compression,
Chuanbo Tang, Xihua Sheng, Zhuoyuan Li, Haotian Zhang, Li Li, and Dong Liu, “Offline and online optical flow enhancement for deep video compression,” inProceedings of the AAAI Conference on Artificial Intelligence, 2024, vol. 38, pp. 5118–5126
2024
-
[8]
Scale-space flow for end-to- end optimized video compression,
Eirikur Agustsson, David Minnen, Nick Johnston, Johannes Balle, Sung Jin Hwang, and George Toderici, “Scale-space flow for end-to- end optimized video compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 8503–8512
2020
-
[9]
Coarse-to-fine deep video coding with hyperprior-guided mode prediction,
Zhihao Hu, Guo Lu, Jinyang Guo, Shan Liu, Wei Jiang, and Dong Xu, “Coarse-to-fine deep video coding with hyperprior-guided mode prediction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5921–5930
2022
-
[10]
Group-aware parameter-efficient updating for content-adaptive neural video compres- sion,
Zhenghao Chen, Luping Zhou, Zhihao Hu, and Dong Xu, “Group-aware parameter-efficient updating for content-adaptive neural video compres- sion,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 11022–11031
2024
-
[11]
Parameter-efficient instance-adaptive neural video compression,
Seungjun Oh, Hyunmo Yang, and Eunbyung Park, “Parameter-efficient instance-adaptive neural video compression,” inProceedings of the Asian Conference on Computer Vision, 2024, pp. 250–267
2024
-
[12]
Neural video compression with domain transfer,
Tiange Zhang, Rongqun Lin, Xiandong Meng, Haofeng Wang, Xing Tian, Qi Zhang, and Siwei Ma, “Neural video compression with domain transfer,” inIEEE International Symposium on Circuits and Systems, 2026, pp. 1551–1555
2026
-
[13]
L-lbvc: Long-term motion estimation and prediction for learned bi- directional video compression,
Yongqi Zhai, Luyang Tang, Wei Jiang, Jiayu Yang, and Ronggang Wang, “L-lbvc: Long-term motion estimation and prediction for learned bi- directional video compression,” inIEEE Data Compression Conference, 2025, pp. 53–62
2025
-
[14]
Content-adaptive inference for state-of-the-art learned video compression,
Ahmet Bilican, M Akın Yılmaz, and A Murat Tekalp, “Content-adaptive inference for state-of-the-art learned video compression,”IEEE Open Journal of Signal Processing, 2025
2025
-
[15]
Motion-adaptive inference for flexible learned b-frame compression,
M Akin Yilmaz, O Ugur Ulas, Ahmet Bilican, and A Murat Tekalp, “Motion-adaptive inference for flexible learned b-frame compression,” inIEEE International Conference on Image Processing, 2024, pp. 1760– 1766
2024
-
[16]
Overview of the high efficiency video coding (hevc) standard,
Gary J Sullivan, Jens-Rainer Ohm, Woo-Jin Han, and Thomas Wiegand, “Overview of the high efficiency video coding (hevc) standard,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1649–1668, 2012
2012
-
[17]
Dvc: An end-to-end deep video compression framework,
Guo Lu, Wanli Ouyang, Dong Xu, Xiaoyun Zhang, Chunlei Cai, and Zhiyong Gao, “Dvc: An end-to-end deep video compression framework,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 11006–11015
2019
-
[18]
Deep contextual video compression,
Jiahao Li, Bin Li, and Yan Lu, “Deep contextual video compression,” Advances in Neural Information Processing Systems, vol. 34, pp. 18114– 18125, 2021
2021
-
[19]
Temporal context mining for learned video compression,
Xihua Sheng, Jiahao Li, Bin Li, Li Li, Dong Liu, and Yan Lu, “Temporal context mining for learned video compression,”IEEE Transactions on Multimedia, vol. 25, pp. 7311–7322, 2022
2022
-
[20]
Dmvc: Decomposed motion modeling for learned video compression,
Kai Lin, Chuanmin Jia, Xinfeng Zhang, Shanshe Wang, Siwei Ma, and Wen Gao, “Dmvc: Decomposed motion modeling for learned video compression,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 7, pp. 3502–3515, 2022
2022
-
[21]
Neural video compression with diverse contexts,
Jiahao Li, Bin Li, and Yan Lu, “Neural video compression with diverse contexts,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22616–22626
2023
-
[22]
Neural video compression with feature modulation,
Jiahao Li, Bin Li, and Yan Lu, “Neural video compression with feature modulation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26099–26108
2024
-
[23]
Deep video compression with scaled hierarchical bi-directional motion model,
Feng Ye, Li Zhang, and Chuanmin Jia, “Deep video compression with scaled hierarchical bi-directional motion model,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 11244– 11247
2024
-
[24]
Spatial decomposition and temporal fusion based inter prediction for learned video compres- sion,
Xihua Sheng, Li Li, Dong Liu, and Houqiang Li, “Spatial decomposition and temporal fusion based inter prediction for learned video compres- sion,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 7, pp. 6460–6473, 2024
2024
-
[25]
Towards practical real-time neural video compres- sion,
Zhaoyang Jia, Bin Li, Jiahao Li, Wenxuan Xie, Linfeng Qi, Houqiang Li, and Yan Lu, “Towards practical real-time neural video compres- sion,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12543–12552
2025
-
[26]
Bi-directional deep contextual video compression,
Xihua Sheng, Li Li, Dong Liu, and Shiqi Wang, “Bi-directional deep contextual video compression,”IEEE Transactions on Multimedia, 2025
2025
-
[27]
Content adaptive based motion alignment framework for learned video compression,
Tiange Zhang, Xiandong Meng, and Siwei Ma, “Content adaptive based motion alignment framework for learned video compression,” inIEEE Data Compression Conference, 2026, pp. 486–486
2026
-
[28]
L-stec: Learned video compression with long- term spatio-temporal enhanced context,
Tiange Zhang, Zhimeng Huang, Xiandong Meng, Kai Zhang, Zhipin Deng, and Siwei Ma, “L-stec: Learned video compression with long- term spatio-temporal enhanced context,” inIEEE Data Compression Conference, 2026, pp. 13–22
2026
-
[29]
Chnerv: Condition enhanced hybrid neural representation for videos,
Tiange Zhang, Haofeng Wang, Xiandong Meng, Kai Zhang, Xuan Deng, Zhimeng Huang, and Siwei Ma, “Chnerv: Condition enhanced hybrid neural representation for videos,” inIEEE International Conference on Acoustics, Speech and Signal Processing, 2026, pp. 8377–8381
2026
-
[30]
Generative coding: Promise and challenges,
Siwei Ma, Shenpeng Song, Bolin Chen, Qi Mao, Xiaohan Fang, Chuan- min Jia, and Shiqi Wang, “Generative coding: Promise and challenges,” APSIPA Transactions on Signal and Information Processing, vol. 14, 2025
2025
-
[31]
Ustc-td: A test dataset and benchmark for image and video coding in 2020s,
Zhuoyuan Li, Junqi Liao, Chuanbo Tang, Haotian Zhang, Yuqi Li, Yifan Bian, Xihua Sheng, Xinmin Feng, Yao Li, Changsheng Gao, et al., “Ustc-td: A test dataset and benchmark for image and video coding in 2020s,”IEEE Transactions on Multimedia, 2025
2025
-
[32]
Ehvc: Efficient hierarchical reference and quality structure for neural video coding,
Junqi Liao, Yaojun Wu, Chaoyi Lin, Zhipin Deng, Li Li, Dong Liu, and Xiaoyan Sun, “Ehvc: Efficient hierarchical reference and quality structure for neural video coding,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 12083–12091
2025
-
[33]
Calculation of average psnr differences between rd-curves,
Gisle Bjontegaard, “Calculation of average psnr differences between rd-curves,”ITU-T SG16, Doc. VCEG-M33, 2001
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.