ScaleErasure: Inference-Time Minimal Intervention for Precise Concept Erasure in Next-Scale Autoregressive Image Generation
Pith reviewed 2026-06-30 07:59 UTC · model grok-4.3
The pith
ScaleErasure erases unsafe concepts in next-scale autoregressive image generators by guiding selected logits at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
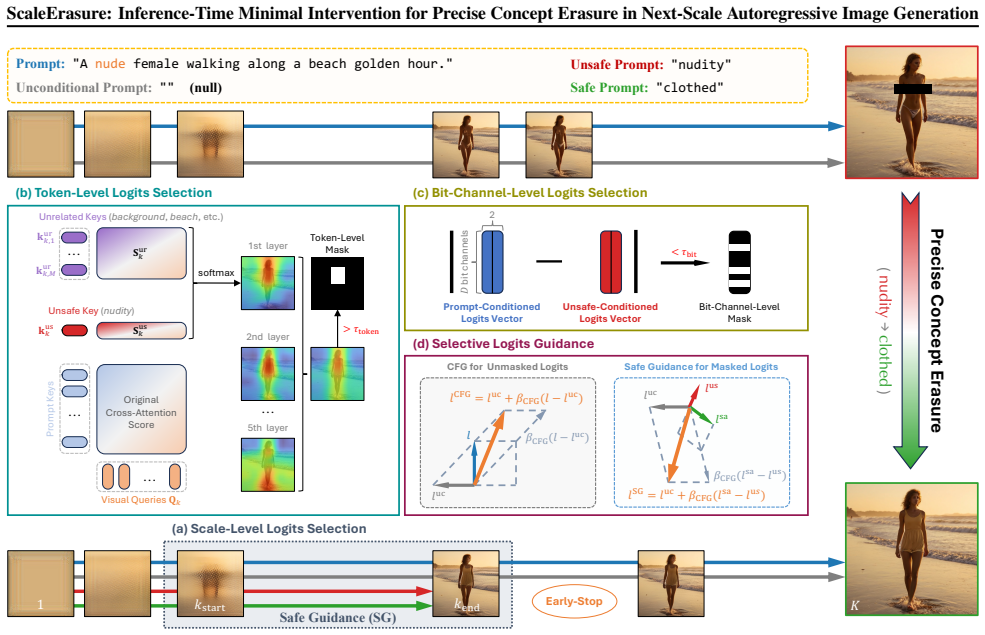
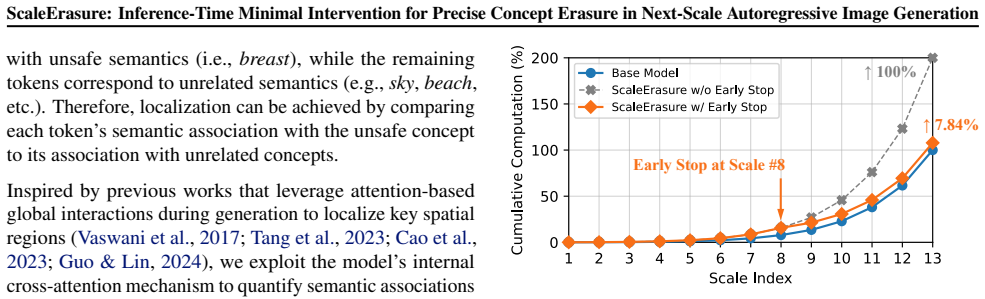
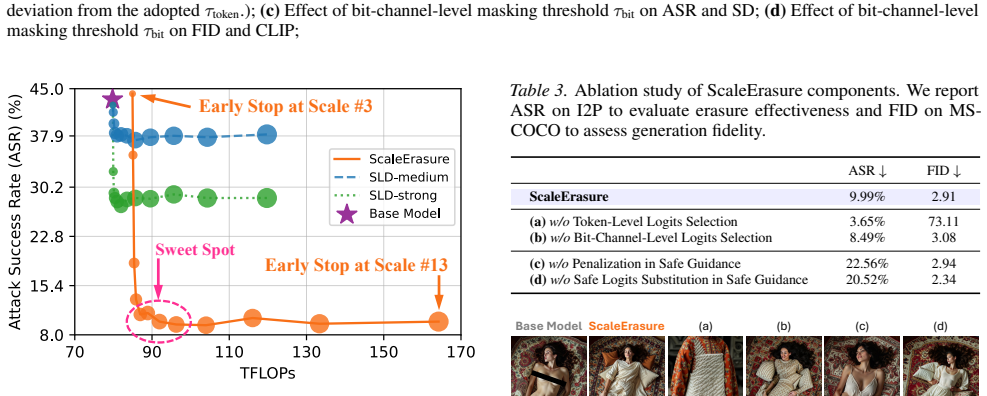
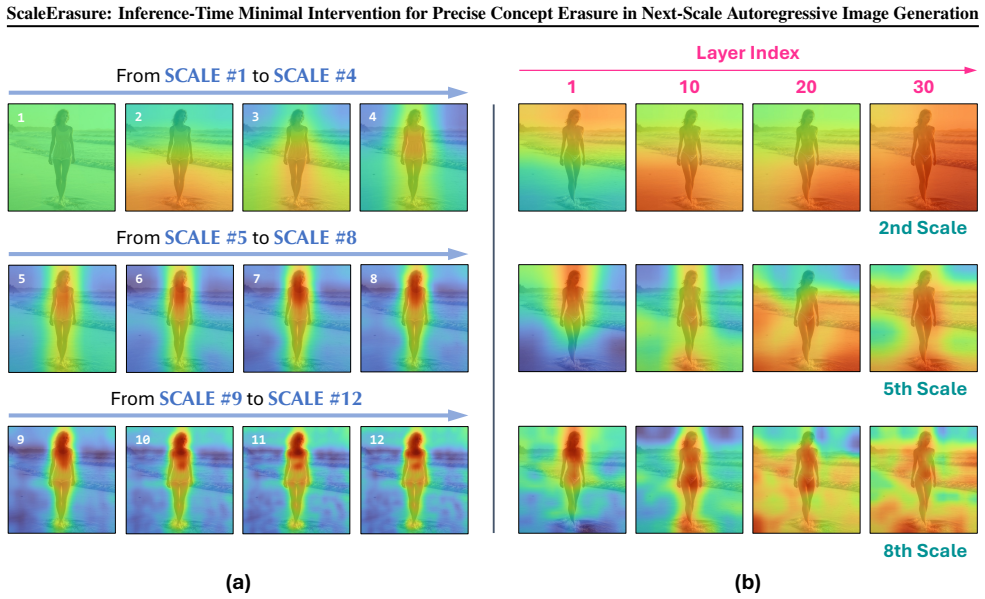
ScaleErasure is an inference-time concept erasure method for next-scale autoregressive image generation that performs minimal intervention by precisely selecting and guiding predicted logits most relevant to the unsafe concept. It achieves this through two additional forward passes conditioned on the unsafe concept and a corresponding safe concept, then leverages their outputs to guide target logits away from unsafe semantics toward safe ones. Logits selection and guidance are conducted across three dimensions—scales, tokens, and bit channels—to enable effective erasure under severe semantic entanglement while largely preserving general generative capability.
What carries the argument
Three-dimensional logit selection and guidance (scales, tokens, bit channels) driven by output differences from unsafe-conditioned and safe-conditioned forward passes.
If this is right
- Next-scale autoregressive models can receive concept-level safety controls directly at inference without retraining.
- Multi-dimensional guidance limits side effects on image content unrelated to the erased concept.
- The method outperforms simple adaptations of earlier erasure techniques when semantic entanglement is severe.
- Precise logit steering preserves the model's overall ability to generate diverse, high-quality images.
Where Pith is reading between the lines
- The same difference-based guidance pattern could be tested on other autoregressive generation tasks such as video or audio.
- Careful selection of the safe concept may be needed to avoid introducing new unintended biases in the outputs.
- Combining this inference-time step with light fine-tuning could further strengthen erasure on particularly entangled concepts.
Load-bearing premise
The differences between the two extra forward passes isolate exactly the logits tied to the unsafe concept without shifting unrelated content or introducing new artifacts.
What would settle it
Apply ScaleErasure to a next-scale model and observe that unsafe concepts still appear in a measurable fraction of outputs or that non-target regions show consistent quality degradation relative to the unmodified model.
Figures




read the original abstract
Concept erasure aims to prevent image generative models from producing unsafe content while preserving their general generative capability. Meanwhile, next-scale autoregressive (AR) image generation has recently emerged as a new generative paradigm characterized by next-scale prediction, for which concept erasure remains largely unexplored. In this paradigm, semantic information is highly compressed at early scales, leading to severe entanglement between unsafe and unrelated semantics. In this paper, we propose ScaleErasure, an inference-time concept erasure method that performs minimal intervention. ScaleErasure precisely selects and guides predicted logits that are most relevant to the unsafe concept, thereby enabling effective erasure under severe semantic entanglement. Specifically, ScaleErasure performs two additional forward passes conditioned on the unsafe concept and the corresponding safe concept, and leverages their outputs to guide the target logits away from unsafe concepts toward safe concepts. To enable precise and minimal intervention, logits selection and guidance are conducted across three dimensions: scales, tokens, and bit channels. Experiments demonstrate that ScaleErasure outperforms adapted baselines in the next-scale AR paradigm, achieving more precise concept erasure while largely preserving general generative capability. The code is available at https://github.com/coziiizz/ScaleErasure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ScaleErasure, an inference-time method for precise concept erasure in next-scale autoregressive image generation. It performs two additional forward passes (unsafe concept and safe concept) to compute logit differences, then selectively guides the target generation's logits across three dimensions—scales, tokens, and bit channels—to steer away from unsafe semantics while minimizing changes to unrelated content. The central claim is that this minimal intervention outperforms adapted baselines under severe semantic entanglement at early scales and largely preserves general generative capability, with code released.
Significance. If the isolation of unsafe logits holds, the work addresses an unexplored gap in safety techniques for the emerging next-scale AR paradigm, where early-scale compression creates high entanglement. The inference-time, parameter-free nature and open code are practical strengths that could enable safer deployment without retraining.
major comments (2)
- [§3] §3 (Method): The procedure defines logit guidance directly from the difference of the two conditioned forward passes, but provides no derivation or bound showing that the selected dimensions (after scale/token/bit-channel masking) are orthogonal to non-target semantics. Under the entanglement described in the introduction, this risks collateral shifts; a concrete test (e.g., measuring change in unrelated concept scores before/after guidance) is needed to support the 'precise' and 'minimal' claims.
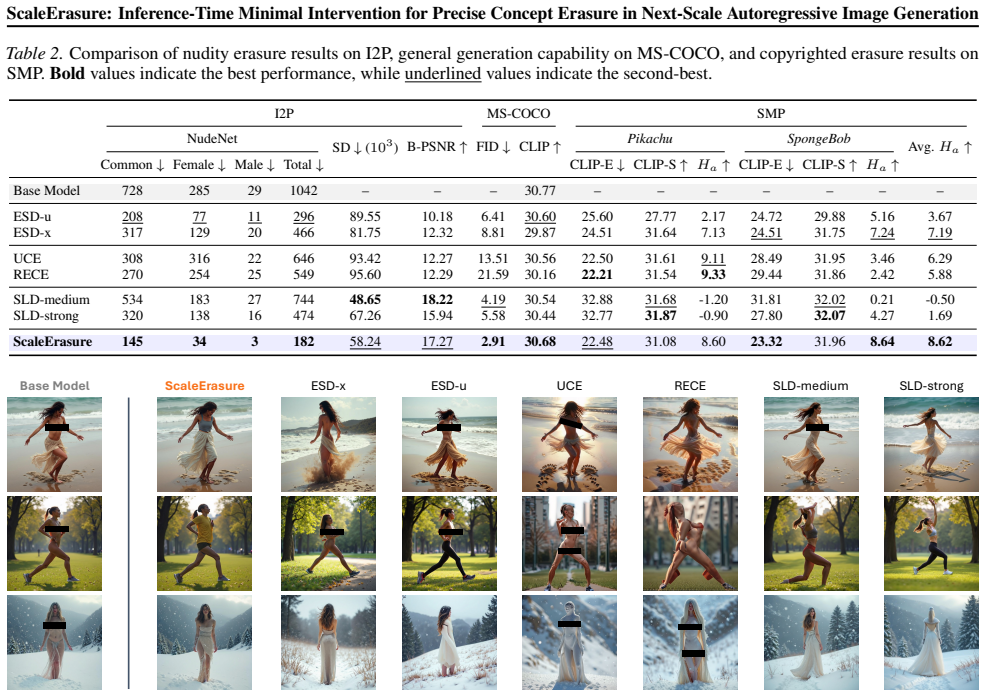
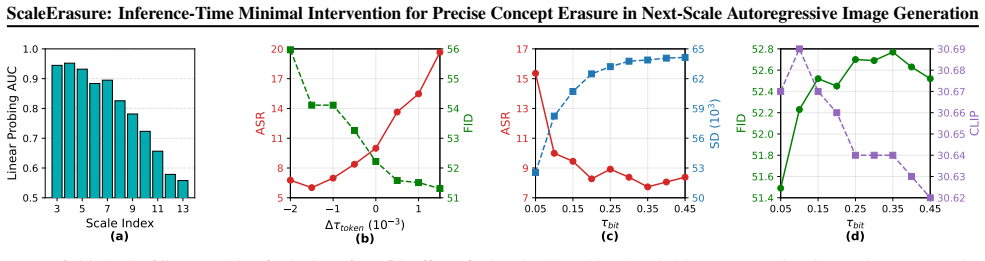
- [§4] §4 (Experiments): The abstract asserts outperformance and capability preservation, yet the soundness assessment notes absence of quantitative metrics, ablations on the three selection dimensions, or error analysis in the provided text. Without tables reporting, e.g., unsafe-concept success rate vs. FID or CLIP similarity on safe concepts, the central claim that the method 'enables effective erasure' cannot be verified as load-bearing.
minor comments (1)
- [§3.2] Notation for the three-dimensional selection mask is introduced without an explicit equation; adding a compact definition (e.g., Eq. (X)) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for strengthening the theoretical justification and empirical validation of ScaleErasure. We address each point below and will incorporate revisions to improve the paper.
read point-by-point responses
-
Referee: [§3] §3 (Method): The procedure defines logit guidance directly from the difference of the two conditioned forward passes, but provides no derivation or bound showing that the selected dimensions (after scale/token/bit-channel masking) are orthogonal to non-target semantics. Under the entanglement described in the introduction, this risks collateral shifts; a concrete test (e.g., measuring change in unrelated concept scores before/after guidance) is needed to support the 'precise' and 'minimal' claims.
Authors: We acknowledge that a formal derivation or bound demonstrating orthogonality after masking would provide stronger theoretical support. Deriving such a bound is non-trivial due to the severe semantic entanglement at early scales in next-scale AR models, which is the core challenge highlighted in the introduction. The logit selection is motivated by empirical differences between unsafe and safe conditioned passes. To directly address the request for a concrete test, we will add an empirical evaluation in the revised §3 measuring changes in unrelated concept scores (via CLIP-based probes on safe concepts) before and after guidance. This will quantify collateral shifts and better support the 'precise' and 'minimal' claims. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract asserts outperformance and capability preservation, yet the soundness assessment notes absence of quantitative metrics, ablations on the three selection dimensions, or error analysis in the provided text. Without tables reporting, e.g., unsafe-concept success rate vs. FID or CLIP similarity on safe concepts, the central claim that the method 'enables effective erasure' cannot be verified as load-bearing.
Authors: We agree that the current presentation would benefit from more explicit quantitative reporting to make the claims load-bearing. While the manuscript includes comparative experiments and qualitative results, we accept the assessment that dedicated tables, ablations on the scale/token/bit-channel dimensions, and error analysis are missing from the provided text. In the revision, we will expand §4 with tables reporting unsafe-concept success rates alongside FID and CLIP similarity on safe concepts, plus ablations isolating each selection dimension and error analysis (e.g., failure cases). This will allow direct verification of outperformance and capability preservation. revision: yes
Circularity Check
No circularity; method is a direct procedural definition using model forward passes
full rationale
The paper describes ScaleErasure via two additional conditioned forward passes whose logit differences are used for selection and guidance across scales/tokens/bit-channels. No equations, fitted parameters, or self-citations are presented that reduce any claimed result to its own inputs by construction. The central procedure is defined in terms of the model's existing inference behavior rather than any self-definitional loop or renamed empirical pattern. This is the common case of a self-contained inference-time algorithm with no load-bearing reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conditioning forward passes on unsafe and safe concepts isolates the logits most relevant to the unsafe semantics.
Reference graph
Works this paper leans on
-
[1]
Gandikota, Rohit and Materzynska, Joanna and Fiotto-Kaufman, Jaden and Bau, David , booktitle=
-
[2]
Kumari, Nupur and Zhang, Bingliang and Wang, Sheng-Yu and Shechtman, Eli and Zhang, Richard and Zhu, Jun-Yan , booktitle=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Schramowski, Patrick and Brack, Manuel and Deiseroth, Bj. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[4]
Cao, Mingdeng and Wang, Xintao and Qi, Zhongang and Shan, Ying and Qie, Xiaohu and Zheng, Yinqiang , booktitle=
-
[5]
Sohl-Dickstein, Jascha and Weiss, Eric and Maheswaranathan, Niru and Ganguli, Surya , booktitle=
-
[6]
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , journal=
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[8]
Ni, Minheng and Wu, Chenfei and Wang, Xiaodong and Yin, Shengming and Wang, Lijuan and Liu, Zicheng and Duan, Nan , booktitle=
-
[9]
Yang, Yijun and Gao, Ruiyuan and Yang, Xiao and Zhong, Jianyuan and Xu, Qiang , journal=
-
[10]
Heng, Alvin and Soh, Harold , journal=
-
[11]
Zhang, Yimeng and Chen, Xin and Jia, Jinghan and Zhang, Yihua and Fan, Chongyu and Liu, Jiancheng and Hong, Mingyi and Ding, Ke and Liu, Sijia , journal=
-
[12]
Kim, Changhoon and Min, Kyle and Yang, Yezhou , booktitle=
-
[13]
Gao, Daiheng and Lu, Shilin and Zhou, Wenbo and Chu, Jiaming and Zhang, Jie and Jia, Mengxi and Zhang, Bang and Fan, Zhaoxin and Zhang, Weiming , booktitle=
-
[14]
Yu, Qihang and He, Ju and Deng, Xueqing and Shen, Xiaohui and Chen, Liang-Chieh , booktitle=
-
[15]
Gong, Chao and Chen, Kai and Wei, Zhipeng and Chen, Jingjing and Jiang, Yu-Gang , booktitle=
-
[16]
Han, Jian and Liu, Jinlai and Jiang, Yi and Yan, Bin and Zhang, Yuqi and Yuan, Zehuan and Peng, Bingyue and Liu, Xiaobing , booktitle=
-
[17]
Guo, Qin and Lin, Tianwei , booktitle=
-
[18]
Li, Leyang and Lu, Shilin and Ren, Yan and Kong, Adams Wai-Kin , booktitle=
-
[19]
Gray, Robert , journal=
-
[20]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Gandikota, Rohit and Orgad, Hadas and Belinkov, Yonatan and Materzy. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[21]
Fan, Chenghao and Lu, Zhenyi and Wei, Wei and Tian, Jie and Qu, Xiaoye and Chen, Dangyang and Cheng, Yu , journal=
-
[22]
Tian, Keyu and Jiang, Yi and Yuan, Zehuan and Peng, Bingyue and Wang, Liwei , journal=
-
[23]
Advances in Neural Information Processing Systems , volume=
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser,. Advances in Neural Information Processing Systems , volume=
-
[24]
Zhang, Han and Koh, Jing Yu and Baldridge, Jason and Lee, Honglak and Yang, Yinfei , booktitle=
-
[25]
Labs, Black Forest and Batifol, Stephen and Blattmann, Andreas and Boesel, Frederic and Consul, Saksham and Diagne, Cyril and Dockhorn, Tim and English, Jack and English, Zion and Esser, Patrick and others , journal=
-
[26]
International Conference on Machine Learning , year=
Esser, Patrick and Kulal, Sumith and Blattmann, Andreas and Entezari, Rahim and M. International Conference on Machine Learning , year=
-
[27]
Li, Tianhong and Tian, Yonglong and Li, He and Deng, Mingyang and He, Kaiming , journal=
-
[28]
Parmar, Gaurav and Zhang, Richard and Zhu, Jun-Yan , booktitle=
-
[29]
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and others , booktitle=
-
[30]
Lu, Shilin and Wang, Zilan and Li, Leyang and Liu, Yanzhu and Kong, Adams Wai-Kin , booktitle=
-
[31]
Goodfellow, Ian J and Pouget-Abadie, Jean and Mirza, Mehdi and Xu, Bing and Warde-Farley, David and Ozair, Sherjil and Courville, Aaron and Bengio, Yoshua , journal=
-
[32]
Ji, Jiabao and Liu, Yujian and Zhang, Yang and Liu, Gaowen and Kompella, Ramana R and Liu, Sijia and Chang, Shiyu , journal=
-
[33]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Caron, Mathilde and Touvron, Hugo and Misra, Ishan and J. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[34]
Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Yunxuan and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and others , journal=
-
[35]
Tao, Ming and Tang, Hao and Wu, Fei and Jing, Xiao-Yuan and Bao, Bing-Kun and Xu, Changsheng , booktitle=
-
[36]
European Conference on Computer Vision , pages=
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll. European Conference on Computer Vision , pages=
-
[37]
Lyu, Mengyao and Yang, Yuhong and Hong, Haiwen and Chen, Hui and Jin, Xuan and He, Yuan and Xue, Hui and Han, Jungong and Ding, Guiguang , booktitle=
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Splicing ViT Features for Semantic Appearance Transfer , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[39]
Gafni, Oran and Polyak, Adam and Ashual, Oron and Sheynin, Shelly and Parikh, Devi and Taigman, Yaniv , booktitle=
-
[40]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Tang, Raphael and Liu, Linqing and Pandey, Akshat and Jiang, Zhiying and Yang, Gefei and Kumar, Karun and Stenetorp, Pontus and Lin, Jimmy and T. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[41]
Sun, Peize and Jiang, Yi and Chen, Shoufa and Zhang, Shilong and Peng, Bingyue and Luo, Ping and Yuan, Zehuan , journal=
-
[42]
Ho, Jonathan and Salimans, Tim , journal=
-
[43]
International Conference on Learning Representations , pages=
Zhao, Yue and Xiong, Yuanjun and Kr. International Conference on Learning Representations , pages=
-
[44]
Smith , booktitle=
Alisa Liu and Xiaochuang Han and Yizhong Wang and Yulia Tsvetkov and Yejin Choi and Noah A. Smith , booktitle=
-
[45]
Wang, Yufei and Guo, Lanqing and Li, Zhihao and Huang, Jiaxing and Wang, Pichao and Wen, Bihan and Wang, Jian , booktitle=
-
[46]
Tsai, Yu-Lin and Hsu, Chia-Yi and Xie, Chulin and Lin, Chih-Hsun and Chen, Jia You and Li, Bo and Chen, Pin-Yu and Yu, Chia-Mu and Huang, Chun-Ying , booktitle=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.