SSAFE: Simple and Strong AI-Generated Image Detection via Frozen Vision Encoders
Pith reviewed 2026-06-27 18:44 UTC · model grok-4.3
The pith
Frozen multimodal encoders already separate real images from AI-generated ones in embedding space, so a linear classifier detects deepfakes without fine-tuning the encoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
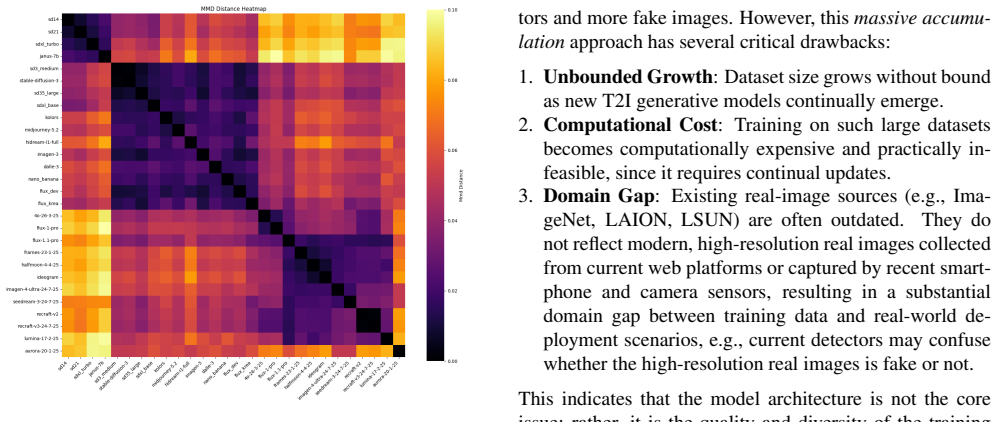
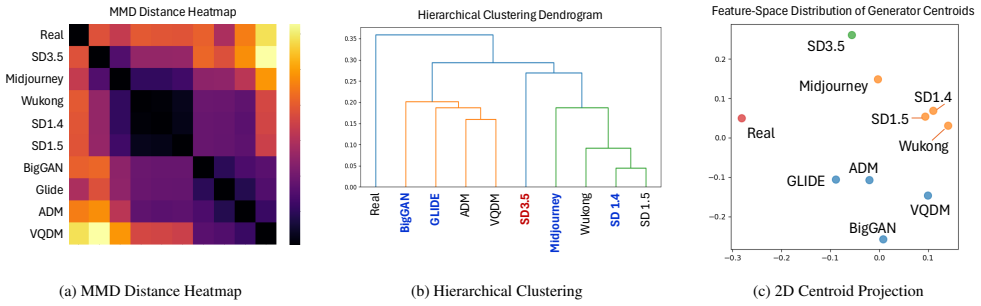
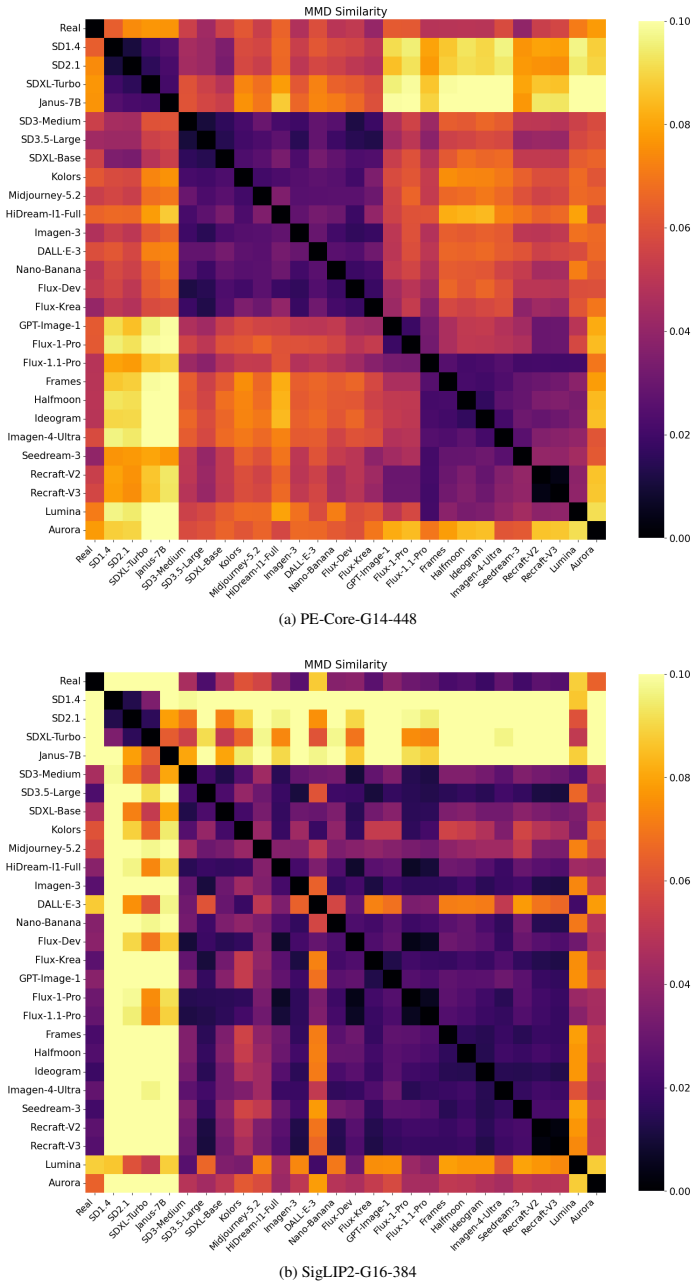
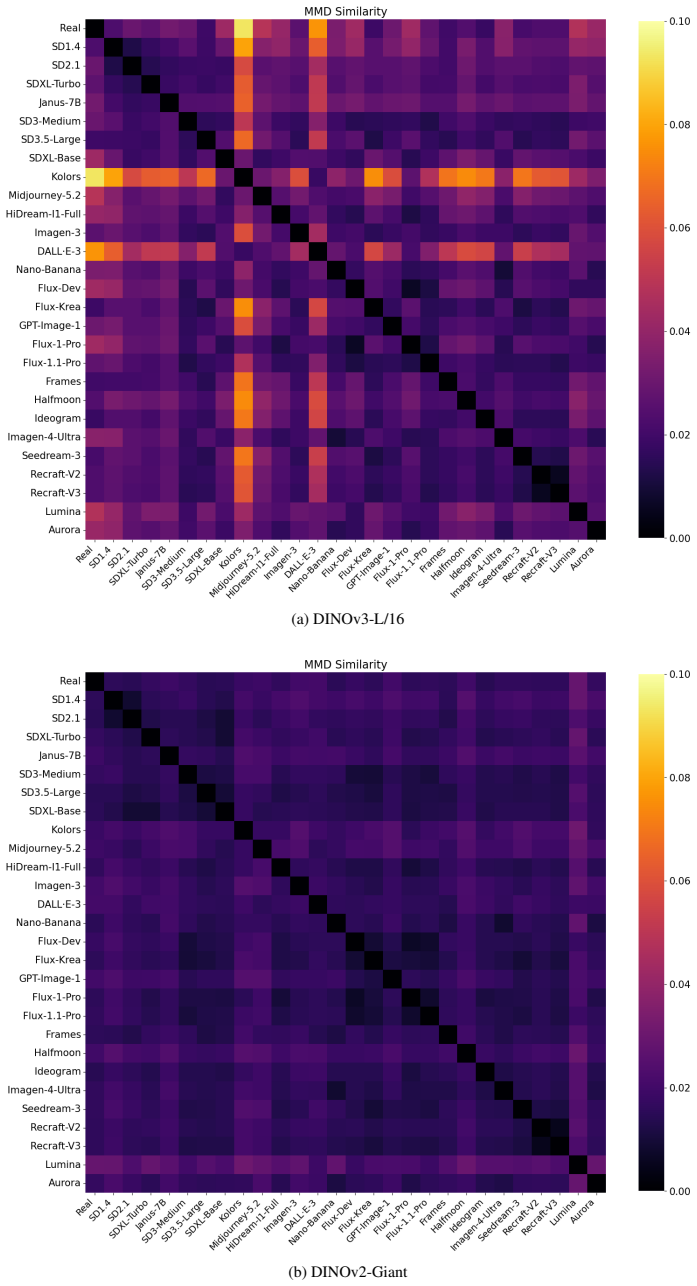
Frozen multimodal encoders naturally separate real and synthetic images in their embedding space, enabling a simple linear classifier to achieve strong performance without task-specific fine-tuning. A representation-aware curation strategy selects a compact set of 10K images from representative generators; the resulting detector improves robustness to unseen generators and distribution shifts compared with models trained on 288K or 4M images.
What carries the argument
Embedding-space separation produced by frozen multimodal vision encoders, together with representation-aware data curation that selects generators for training.
If this is right
- A linear probe on frozen multimodal features suffices for competitive detection accuracy.
- Training data volume can be reduced from millions to 10K images while increasing robustness to new generators.
- The same frozen encoder plus curated set performs well on a new benchmark of camera photos, stock images, and recent commercial outputs.
- Distribution shifts between training and test generators become less harmful when the training generators are chosen by representation similarity.
Where Pith is reading between the lines
- If the separation holds for encoders trained on different multimodal objectives, authenticity cues may be an emergent property of large-scale image-text pretraining.
- The curation method could be applied to other detection tasks such as video or audio generation if comparable frozen encoders exist.
- Detection pipelines might shift from periodic full retraining to periodic re-curation of a small generator set.
Load-bearing premise
The observed separation in embedding space is driven by image authenticity rather than by correlated low-level statistics or generator-specific artifacts.
What would settle it
Measure accuracy of the linear classifier on images produced by a generator architecture absent from the curation set; a substantial drop below reported performance would falsify the claim of generalization.
Figures






read the original abstract
The rapid advancement of generative models has blurred the boundary between synthetic and real imagery, creating an urgent need for reliable deepfake detection. Yet most existing approaches rely on massive real--fake datasets, which are increasingly difficult to maintain as new generators continue to emerge. In this work, we investigate how much information about image authenticity is already encoded in modern multimodal vision representations. We find that frozen multimodal encoders naturally separate real and synthetic images in their embedding space, enabling a simple linear classifier to achieve strong performance without task-specific fine-tuning. Motivated by this observation, we develop a representation-aware data curation strategy that selects a compact set of representative generators for training. The resulting training set contains only 10K images, compared to 288K in AIGIBench and 4M in OpenFake, while improving robustness to unseen generators and distribution shifts. We additionally introduce RealWorldBench, a benchmark consisting of modern camera photographs, contemporary stock images, and outputs from recent commercial generators. Experiments across multiple benchmarks show that combining frozen multimodal representations with carefully curated training data provides a simple and effective approach to AI-generated image detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that frozen multimodal vision encoders naturally separate real and synthetic images in embedding space, allowing a simple linear classifier (trained on a representation-aware curated set of only 10K images) to achieve strong AI-generated image detection performance and robustness to unseen generators/distribution shifts without task-specific fine-tuning. It introduces RealWorldBench (modern camera photos, stock images, recent commercial generators) and reports superior results versus methods trained on AIGIBench (288K) or OpenFake (4M).
Significance. If the central empirical claim holds and the separation is shown to reflect authenticity rather than generator artifacts, the result would be significant: it demonstrates that existing multimodal representations already encode useful authenticity signals, enabling a parameter-light, data-efficient detector that generalizes better than large-scale supervised approaches. The small curated training set and new benchmark are practical contributions.
major comments (3)
- [§4, §3.2] §4 (Experiments) and §3.2 (representation-aware curation): the central claim that embeddings separate images 'because of authenticity' rather than correlated low-level statistics (frequency spectra, compression, upsampling) is load-bearing but unsupported by any ablation that controls for these factors (e.g., no tests on real images with synthetic-like artifacts or vice versa). Without such controls, performance on RealWorldBench and unseen generators could be explained by generator-specific cues rather than the claimed natural separation.
- [Table 1, §4.3] Table 1 / §4.3 (comparison to AIGIBench/OpenFake): the reported robustness gains are presented without error bars, multiple random seeds, or statistical tests; given that the linear probe has free parameters, it is unclear whether the 10K-set advantage is reliable or could be matched by larger sets with proper regularization.
- [§3.3] §3.3 (generator selection): the curation procedure that yields the 10K set is described at a high level; the manuscript must specify the exact similarity metric, clustering method, and how 'representative' is quantified so that the generalization claim can be reproduced or falsified.
minor comments (2)
- [Abstract, §1] Abstract and §1: several quantitative claims ('strong performance', 'improving robustness') appear before any numbers or tables; move at least one key metric (e.g., AUC on RealWorldBench) into the abstract for immediate verifiability.
- Notation: the linear classifier is referred to interchangeably as 'probe' and 'classifier'; standardize terminology and explicitly state its input dimensionality and training objective (e.g., logistic regression or SVM).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, acknowledging where the manuscript can be strengthened through revisions while defending the core empirical claims on the basis of the presented evidence.
read point-by-point responses
-
Referee: [§4, §3.2] the central claim that embeddings separate images 'because of authenticity' rather than correlated low-level statistics (frequency spectra, compression, upsampling) is load-bearing but unsupported by any ablation that controls for these factors. Without such controls, performance could be explained by generator-specific cues rather than natural separation.
Authors: We agree that explicit controls isolating authenticity signals from low-level artifacts would strengthen the interpretation. The manuscript relies on the fact that the encoders are frozen multimodal models trained on broad real-world data, and the representation-aware curation operates in embedding space rather than pixel space. However, we acknowledge the absence of targeted ablations (e.g., artifact injection on real images). In revision we will add a controlled experiment applying frequency and compression perturbations to real images and measuring classifier degradation to test whether performance tracks authenticity or low-level cues. revision: yes
-
Referee: [Table 1, §4.3] the reported robustness gains are presented without error bars, multiple random seeds, or statistical tests; it is unclear whether the 10K-set advantage is reliable or could be matched by larger sets with proper regularization.
Authors: We accept that variance estimates are needed for rigorous comparison. The linear probe training protocol was deterministic in the reported runs, but we will re-execute all Table 1 experiments across five random seeds, report mean and standard deviation, and add a brief statistical comparison (paired t-test) between the 10K curated set and the larger baselines. This will clarify whether the observed gains are stable. revision: yes
-
Referee: [§3.3] the curation procedure that yields the 10K set is described at a high level; the manuscript must specify the exact similarity metric, clustering method, and how 'representative' is quantified so that the generalization claim can be reproduced or falsified.
Authors: We agree the description is insufficiently precise. In the revised §3.3 we will state: cosine similarity on the frozen encoder embeddings, k-means clustering with k equal to the number of generator families, and selection of the sample nearest each cluster centroid as the representative. These details will be accompanied by pseudocode to enable exact reproduction. revision: yes
Circularity Check
No circularity: empirical observation of embedding separation followed by linear probe training
full rationale
The paper presents an empirical finding that frozen multimodal encoders separate real and synthetic images, followed by training a linear classifier on a curated 10K-image set. No equations, derivations, or first-principles claims are present in the abstract or described approach. The central claim rests on observed performance across benchmarks rather than any self-definitional mapping, fitted parameter renamed as prediction, or load-bearing self-citation chain. The representation-aware curation and RealWorldBench are presented as practical choices, not reductions to prior fitted results. This is a standard empirical pipeline with no load-bearing step that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- linear classifier parameters
axioms (1)
- domain assumption Frozen multimodal encoders encode information about image authenticity in their embedding space
Reference graph
Works this paper leans on
-
[1]
Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond, 2023
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond, 2023. 2
2023
-
[2]
FLUX.1-dev.https : / / huggingface
Black Forest Labs. FLUX.1-dev.https : / / huggingface . co / black - forest - labs / FLUX . 1-dev, 2024. Accessed: 2024-12-01. 1, 2
2024
-
[3]
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Rasheed, et al. Perception encoder: The best visual embeddings are not at the output of the net- work.arXiv preprint arXiv:2504.13181, 2025. 2, 1
Pith/arXiv arXiv 2025
-
[4]
Large scale gan training for high fidelity natural image synthesis
Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018. 1, 2
Pith/arXiv arXiv 2018
-
[5]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 9650–9660, 2021. 2
2021
-
[6]
Real-time deepfake detection in the real-world.arXiv preprint arXiv:2406.09398, 2024
Bar Cavia, Eliahu Horwitz, Tal Reiss, and Yedid Hoshen. Real-time deepfake detection in the real-world.arXiv preprint arXiv:2406.09398, 2024. 5
arXiv 2024
-
[7]
Drct: Diffusion reconstruction contrastive training towards universal detection of diffusion generated images
Baoying Chen, Jishen Zeng, Jianquan Yang, and Rui Yang. Drct: Diffusion reconstruction contrastive training towards universal detection of diffusion generated images. InForty- first International Conference on Machine Learning, 2024. 1
2024
-
[8]
Gemini 2.5 flash-image.https:// aistudio.google.com/models/gemini- 2- 5- flash-image, 2025
Google DeepMind. Gemini 2.5 flash-image.https:// aistudio.google.com/models/gemini- 2- 5- flash-image, 2025. Accessed: 2025-11-14. 1
2025
-
[9]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 1
2009
-
[10]
Diffusion models beat gans on image synthesis.Advances in neural informa- tion processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural informa- tion processing systems, 34:8780–8794, 2021. 2
2021
-
[11]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[12]
Humanrefiner: Benchmarking abnormal human generation and refining with coarse-to-fine pose-reversible guidance
Guian Fang, Wenbiao Yan, Yuanfan Guo, Jianhua Han, Zu- tao Jiang, Hang Xu, Shengcai Liao, and Xiaodan Liang. Humanrefiner: Benchmarking abnormal human generation and refining with coarse-to-fine pose-reversible guidance. In European Conference on Computer Vision, pages 201–217. Springer, 2024. 2
2024
-
[13]
Imagen 3.https://deepmind
Google DeepMind. Imagen 3.https://deepmind. google/technologies/imagen-3, 2024. Accessed: 2024-12-01. 1
2024
-
[14]
Vec- tor quantized diffusion model for text-to-image synthesis
Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vec- tor quantized diffusion model for text-to-image synthesis. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 10696–10706, 2022. 2
2022
-
[15]
Progressive growing of GANs for improved quality, stabil- ity, and variation
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of GANs for improved quality, stabil- ity, and variation. InInternational Conference on Learning Representations, 2018. 1, 2
2018
-
[16]
Improving synthetic image detection to- wards generalization: An image transformation perspective
Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, and Fuli Feng. Improving synthetic image detection to- wards generalization: An image transformation perspective. arXiv preprint arXiv:2408.06741, 2024. 1, 5
arXiv 2024
-
[17]
Photomaker: Customizing re- alistic human photos via stacked id embedding
Zhen Li, Mingdeng Cao, Xintao Wang, Zhongang Qi, Ming- Ming Cheng, and Ying Shan. Photomaker: Customizing re- alistic human photos via stacked id embedding. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8640–8650, 2024. 1
2024
-
[18]
Ziqiang Li, Jiazhen Yan, Ziwen He, Kai Zeng, Weiwei Jiang, Lizhi Xiong, and Zhangjie Fu. Is artificial intelligence gen- erated image detection a solved problem?arXiv preprint arXiv:2505.12335, 2025. 1, 2, 4
arXiv 2025
-
[19]
Shuqiao Liang, Jian Liu, Renzhang Chen, and Quanlong Guan. Ferretnet: Efficient synthetic image detection via local pixel dependencies.arXiv preprint arXiv:2509.20890, 2025. 1, 5
arXiv 2025
-
[20]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 1
2014
-
[21]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 2
2023
-
[22]
Global tex- ture enhancement for fake face detection in the wild
Zhengzhe Liu, Xiaojuan Qi, and Philip HS Torr. Global tex- ture enhancement for fake face detection in the wild. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8060–8069, 2020. 5
2020
-
[23]
Victor Livernoche, Akshatha Arodi, Andreea Musulan, Zachary Yang, Adam Salvail, Ga´etan Marceau Caron, Jean- Franc ¸ois Godbout, and Reihaneh Rabbany. Openfake: An open dataset and platform toward real-world deepfake detec- tion.arXiv preprint arXiv:2509.09495, 2025. 1, 2, 4, 6
arXiv 2025
-
[24]
Seeing is not always believing: Benchmarking human and model perception of ai-generated images.Advances in neural information processing systems, 36:25435–25447, 2023
Zeyu Lu, Di Huang, Lei Bai, Jingjing Qu, Chengyue Wu, Xi- hui Liu, and Wanli Ouyang. Seeing is not always believing: Benchmarking human and model perception of ai-generated images.Advances in neural information processing systems, 36:25435–25447, 2023. 1
2023
-
[25]
Lcm-lora: A universal stable-diffusion ac- celeration module.arXiv preprint arXiv:2311.05556, 2023
Simian Luo, Yiqin Tan, Suraj Patil, Daniel Gu, Patrick V on Platen, Apolin˜AArio Passos, Longbo Huang, Jian Li, and Hang Zhao. Lcm-lora: A universal stable-diffusion ac- celeration module.arXiv preprint arXiv:2311.05556, 2023. 2
arXiv 2023
-
[26]
Midjourney V6.1.https://www
Midjourney Team. Midjourney V6.1.https://www. midjourney.com/, 2024. Accessed: 2024-12-01. 1
2024
-
[27]
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models.arXiv preprint arXiv:2112.10741, 2021. 1, 2
Pith/arXiv arXiv 2021
-
[28]
Towards uni- versal fake image detectors that generalize across genera- tive models
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. Towards uni- versal fake image detectors that generalize across genera- tive models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24480– 24489, 2023. 1, 2, 5
2023
-
[29]
Dall–e 3.https://dalle3.ai/, 2024
OpenAI Team. Dall–e 3.https://dalle3.ai/, 2024. Accessed: 2024-12-01. 1
2024
-
[30]
Dinov2: Learning robust visual features without supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2
Pith/arXiv arXiv 2023
-
[31]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 2
Pith/arXiv arXiv 2023
-
[32]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
2021
-
[33]
Recraft-v3-24-7-25 text-to-image human pref- erence dataset.https : / / huggingface
Rapidata. Recraft-v3-24-7-25 text-to-image human pref- erence dataset.https : / / huggingface . co / datasets / Rapidata / Recraft - v3 - 24 - 7 - 25 _ t2i_human_preference, 2025. 3, 4
2025
-
[34]
Anton Razzhigaev, Arseniy Shakhmatov, Anastasia Malt- seva, Vladimir Arkhipkin, Igor Pavlov, Ilya Ryabov, An- gelina Kuts, Alexander Panchenko, Andrey Kuznetsov, and Denis Dimitrov. Kandinsky: an improved text-to-image syn- thesis with image prior and latent diffusion.arXiv preprint arXiv:2310.03502, 2023. 2
arXiv 2023
-
[35]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 2
2022
-
[36]
Faceforen- sics++: Learning to detect manipulated facial images
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Chris- tian Riess, Justus Thies, and Matthias Nießner. Faceforen- sics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF international conference on computer vision, pages 1–11, 2019. 1
2019
-
[37]
Dinov3.arXiv preprint arXiv:2508.10104, 2025
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 2, 1
Pith/arXiv arXiv 2025
-
[38]
Learning on gradients: Generalized arti- facts representation for gan-generated images detection
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, and Yunchao Wei. Learning on gradients: Generalized arti- facts representation for gan-generated images detection. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 12105–12114, 2023. 2, 5
2023
-
[39]
Frequency-aware deepfake de- tection: Improving generalizability through frequency space domain learning
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. Frequency-aware deepfake de- tection: Improving generalizability through frequency space domain learning. InProceedings of the AAAI Conference on Artificial Intelligence, pages 5052–5060, 2024. 2, 5
2024
-
[40]
Rethinking the up-sampling op- erations in cnn-based generative network for generalizable deepfake detection
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. Rethinking the up-sampling op- erations in cnn-based generative network for generalizable deepfake detection. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 28130–28139, 2024. 5
2024
-
[41]
C2p-clip: Inject- ing category common prompt in clip to enhance generaliza- tion in deepfake detection
Chuangchuang Tan, Renshuai Tao, Huan Liu, Guanghua Gu, Baoyuan Wu, Yao Zhao, and Yunchao Wei. C2p-clip: Inject- ing category common prompt in clip to enhance generaliza- tion in deepfake detection. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 7184–7192, 2025. 1, 2, 5
2025
-
[42]
Renshuai Tao, Chuangchuang Tan, Huan Liu, Jiakai Wang, Haotong Qin, Yakun Chang, Wei Wang, Rongrong Ni, and Yao Zhao. Sagnet: Decoupling semantic-agnostic artifacts from limited training data for robust generalization in deep- fake detection.IEEE Transactions on Information Forensics and Security, 2025. 2
2025
-
[43]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 2, 1
Pith/arXiv arXiv 2025
-
[44]
Lota: Bit-planes guided ai-generated image de- tection
Hongsong Wang, Renxi Cheng, Yang Zhang, Chaolei Han, and Jie Gui. Lota: Bit-planes guided ai-generated image de- tection. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 17246–17255, 2025. 1, 5
2025
-
[45]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2
Pith/arXiv arXiv 2024
-
[46]
Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, Anthony Chen, Huaxia Li, Xu Tang, and Yao Hu. Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024. 1
Pith/arXiv arXiv 2024
-
[47]
Cnn-generated images are surprisingly easy to spot
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A Efros. Cnn-generated images are surprisingly easy to spot... for now. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8695–8704, 2020. 1, 2, 5
2020
-
[48]
Wukong — model zoo, mindspore xihe plat- form.https://xihe.mindspore.cn/modelzoo/ wukong, 2025
Wukong. Wukong — model zoo, mindspore xihe plat- form.https://xihe.mindspore.cn/modelzoo/ wukong, 2025. Accessed: 2025-11-10. 2
2025
-
[49]
Jiazhen Yan, Ziqiang Li, Ziwen He, and Zhangjie Fu. Gener- alizable deepfake detection via effective local-global feature extraction.arXiv preprint arXiv:2501.15253, 2025. 5
arXiv 2025
-
[50]
A sanity check for ai-generated image detection.arXiv preprint arXiv:2406.19435, 2024
Shilin Yan, Ouxiang Li, Jiayin Cai, Yanbin Hao, Xi- aolong Jiang, Yao Hu, and Weidi Xie. A sanity check for ai-generated image detection.arXiv preprint arXiv:2406.19435, 2024. 1, 2, 5, 6
arXiv 2024
-
[51]
Zhiyuan Yan, Jiangming Wang, Peng Jin, Ke-Yue Zhang, Chengchun Liu, Shen Chen, Taiping Yao, Shouhong Ding, Baoyuan Wu, and Li Yuan. Orthogonal subspace decompo- sition for generalizable ai-generated image detection.arXiv preprint arXiv:2411.15633, 2024. 1, 5
Pith/arXiv arXiv 2024
-
[52]
Dˆ 3: Scaling up deepfake detection by learning from discrepancy
Yongqi Yang, Zhihao Qian, Ye Zhu, Olga Russakovsky, and Yu Wu. Dˆ 3: Scaling up deepfake detection by learning from discrepancy. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23850–23859,
-
[53]
Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser, and Jianxiong Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop.arXiv preprint arXiv:1506.03365, 2015. 1
Pith/arXiv arXiv 2015
-
[54]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 2
2023
-
[55]
Towards universal ai-generated image detec- tion by variational information bottleneck network
Haifeng Zhang, Qinghui He, Xiuli Bi, Weisheng Li, Bo Liu, and Bin Xiao. Towards universal ai-generated image detec- tion by variational information bottleneck network. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 23828–23837, 2025. 5
2025
-
[56]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 2
2023
-
[57]
Ziyin Zhou, Yunpeng Luo, Yuanchen Wu, Ke Sun, Jiayi Ji, Ke Yan, Shouhong Ding, Xiaoshuai Sun, Yunsheng Wu, and Rongrong Ji. Aigi-holmes: Towards explainable and gener- alizable ai-generated image detection via multimodal large language models.arXiv preprint arXiv:2507.02664, 2025. 1, 2, 4, 5
arXiv 2025
-
[58]
A beige pastry sitting in a white bowl next to a spoon
Mingjian Zhu, Hanting Chen, Qiangyu Yan, Xudong Huang, Guanyu Lin, Wei Li, Zhijun Tu, Hailin Hu, Jie Hu, and Yunhe Wang. Genimage: A million-scale benchmark for de- tecting ai-generated image.Advances in Neural Information Processing Systems, 36:77771–77782, 2023. 1 SSAFE: Simple and Strong AI-Generated Image Detection via Frozen Vision Encoders Supplemen...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.