Introduction to stochastic gradient methods
Pith reviewed 2026-06-28 08:45 UTC · model grok-4.3
The pith
Stochastic gradient descent achieves classical convergence rates under smoothness and convexity assumptions on the objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the assumptions of smoothness and convexity, stochastic gradient descent converges to the optimum at a rate of O(1/sqrt(T)) after T steps in expectation, with almost sure convergence also holding for appropriate step-size sequences, and faster rates available under strong convexity or with variance reduction techniques.
What carries the argument
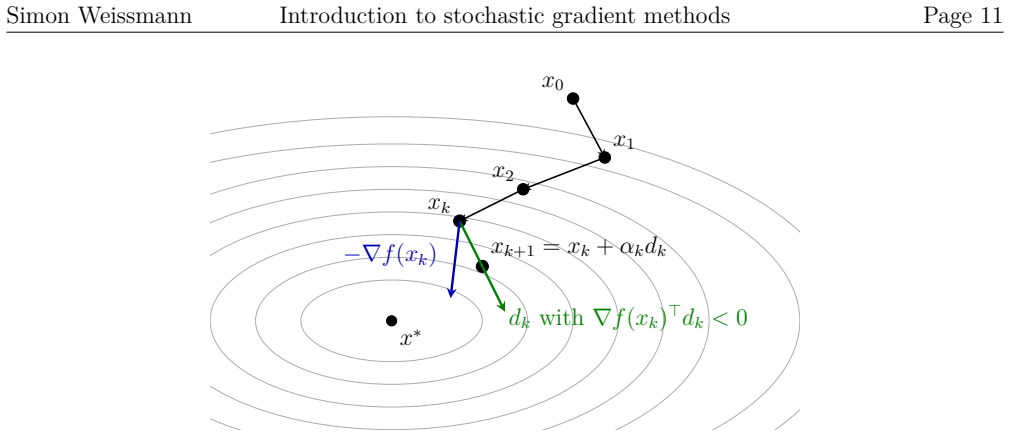
The stochastic gradient descent update rule analyzed using descent lemmas derived from smoothness and convexity to bound the progress per iteration.
If this is right
- Convergence rates apply directly to minimizing expected risk in machine learning models.
- Variance reduction methods improve upon basic SGD by reducing the variance of gradient estimates.
- Almost sure convergence guarantees that the iterates converge with probability one under suitable conditions.
- The Polyak-Lojasiewicz condition allows linear convergence without requiring strong convexity.
Where Pith is reading between the lines
- The derivations imply that step-size schedules must be chosen carefully based on the smoothness parameter to achieve the stated rates.
- These results connect stochastic approximation theory to practical machine learning optimization.
- Extensions to non-convex problems would require additional analysis beyond the paper's scope.
Load-bearing premise
The objective function must be smooth and satisfy convexity, strong convexity, or the Polyak-Lojasiewicz condition for the convergence proofs to hold.
What would settle it
A smooth convex function where running SGD with standard step sizes fails to achieve the O(1/sqrt(T)) rate in expectation.
Figures









read the original abstract
These lecture notes provide an introduction to first-order optimization methods with a particular emphasis on stochastic gradient methods. We begin with deterministic gradient based methods for unconstrained optimization and study their convergence under standard assumptions such as smoothness, convexity, strong convexity, and the Polyak-Lojasiewicz condition. We then turn to stochastic approximation and stochastic gradient descent, motivated by empirical and expected risk minimization in machine learning. The main focus is on convergence theory: we discuss almost sure convergence and convergence in expectation, derive classical convergence rates, and present selected advanced topics, including almost sure convergence rates and variance reduction methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript consists of lecture notes introducing first-order optimization methods, beginning with deterministic gradient descent and progressing to stochastic gradient descent. It derives classical convergence rates (in expectation and almost surely) for problems satisfying smoothness, convexity, strong convexity, and the Polyak-Łojasiewicz condition, motivated by empirical and expected risk minimization, and includes selected topics on almost sure rates and variance reduction.
Significance. The notes reproduce well-established results from the stochastic optimization literature without introducing new theorems, extensions, or parameter-free derivations. While a clear compilation of standard material may have pedagogical utility, the absence of novel contributions limits its significance for advancing research in mathematical optimization.
Simulated Author's Rebuttal
We thank the referee for their review of our lecture notes. The manuscript is explicitly positioned as an introductory compilation of established results rather than a research contribution with novel theorems.
read point-by-point responses
-
Referee: The notes reproduce well-established results from the stochastic optimization literature without introducing new theorems, extensions, or parameter-free derivations. While a clear compilation of standard material may have pedagogical utility, the absence of novel contributions limits its significance for advancing research in mathematical optimization.
Authors: We agree that the notes contain no new theorems and are a compilation of classical convergence results under standard assumptions (smoothness, convexity, strong convexity, PL condition). This is by design: the document is lecture notes whose purpose is to provide a self-contained, accessible derivation of these rates, motivated by empirical and expected risk minimization, for use in teaching or self-study. The referee acknowledges possible pedagogical utility; we believe this is the appropriate evaluation criterion for lecture notes rather than research novelty. revision: no
Circularity Check
No significant circularity
full rationale
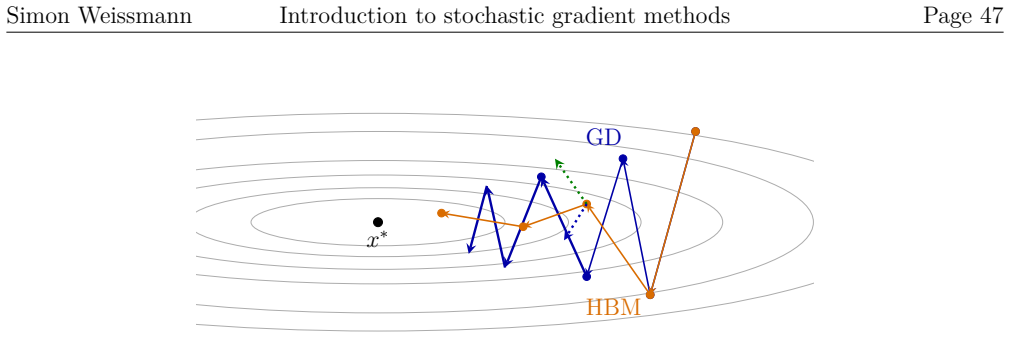
The manuscript consists of lecture notes reproducing classical convergence results for gradient descent and stochastic gradient descent under standard external assumptions (smoothness, convexity, strong convexity, Polyak-Łojasiewicz). All derivations follow from these assumptions via standard analysis techniques drawn from the broader literature; no parameters are fitted and then relabeled as predictions, no self-citations form load-bearing uniqueness arguments, and no ansatzes or renamings reduce the claimed results to the inputs by construction. The notes are therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Objective functions satisfy L-smoothness, convexity, strong convexity, or Polyak-Lojasiewicz condition.
Reference graph
Works this paper leans on
-
[1]
Bertsekas
Dimitri P. Bertsekas. Nonlinear programming. Athena Scientific, 2nd edition, September 2008
2008
-
[2]
Bertsekas and John N
Dimitri P. Bertsekas and John N. Tsitsiklis. Gradient convergence in gradient methods with errors. SIAM Journal on Optimization , 10(3):627–642, 2000
2000
-
[3]
Julius R. Blum. Approximation Methods which Converge with Probability one. The Annals of Mathematical Statistics , 25(2):382 – 386, 1954
1954
-
[4]
Curtis, and Jorge Nocedal
Léon Bottou, Frank E. Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning. SIAM Review, 60(2):223–311, 2018
2018
-
[5]
A Kurdyka-Lojasiewicz property for stochastic optimization algorithms in a non-convex setting
Emilie Chouzenoux, Jean-Baptiste Fest, and Audrey Repetti. A Kurdyka-Lojasiewicz property for stochastic optimization algorithms in a non-convex setting. arXiv Preprint , arXiv:2302.06447, 2023
-
[6]
Da Prato and J
G. Da Prato and J. Zabczyk. Stochastic Equations in Infinite Dimensions . Encyclopedia of Mathematics and its Applications. Cambridge University Press, 1992
1992
-
[7]
SAGA: A fast incremental gradient method with support for non-strongly convex composite objectives
Aaron Defazio, Francis Bach, and Simon Lacoste-Julien. SAGA: A fast incremental gradient method with support for non-strongly convex composite objectives. In Advances in Neural Information Processing Systems , volume 27. Curran Associates, Inc., 2014
2014
-
[8]
Convergence of stochastic gradient descent schemes for Łojasiewicz-landscapes
Steffen Dereich and Sebastian Kassing. Convergence of stochastic gradient descent schemes for Łojasiewicz-landscapes. Journal of Machine Learning , 3(3):245–281, 2024
2024
-
[9]
Adaptive subgradient methods for online learning and stochastic optimization
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research , 12(61):2121–2159, 2011
2011
-
[10]
Sharp analysis of stochastic optimization under global Kurdyka-Lojasiewicz inequality
Ilyas Fatkhullin, Jalal Etesami, Niao He, and Negar Kiyavash. Sharp analysis of stochastic optimization under global Kurdyka-Lojasiewicz inequality. In Advances in Neural Information Processing Systems, volume 35, pages 15836–15848. Curran Associates, Inc., 2022. 122 Simon Weissmann Introduction to stochastic gradient methods Page 123
2022
-
[11]
Convergence rates and approxi- mation results for sgd and its continuous-time counterpart
Xavier Fontaine, Valentin De Bortoli, and Alain Durmus. Convergence rates and approxi- mation results for sgd and its continuous-time counterpart. In Proceedings of Thirty Fourth Conference on Learning Theory , volume 134 of Proceedings of Machine Learning Research , pages 1965–2058. PMLR, 15–19 Aug 2021
1965
-
[12]
Stochastic heavy ball
Sébastien Gadat, Fabien Panloup, and Sofiane Saadane. Stochastic heavy ball. Electronic Journal of Statistics , 12(1):461 – 529, 2018
2018
-
[13]
Guillaume Garrigos and Robert M. Gower. Handbook of convergence theorems for (stochastic) gradient methods. arXiv-Preprint, 2023
2023
-
[14]
Exponential convergence rates for momentum stochas- tic gradient descent in the overparametrized setting
Benjamin Gess and Sebastian Kassing. Exponential convergence rates for momentum stochas- tic gradient descent in the overparametrized setting. Mathematical Programming, 2026
2026
-
[15]
Stochastic first- and zeroth-order methods for nonconvex stochastic programming
Saeed Ghadimi and Guanghui Lan. Stochastic first- and zeroth-order methods for nonconvex stochastic programming. SIAM Journal on Optimization , 23(4):2341–2368, 2013
2013
-
[16]
SGD for structured nonconvex func- tions: Learning rates, minibatching and interpolation
Robert Gower, Othmane Sebbouh, and Nicolas Loizou. SGD for structured nonconvex func- tions: Learning rates, minibatching and interpolation. In International Conference on Arti- ficial Intelligence and Statistics , pages 1315–1323. PMLR, 2021
2021
-
[17]
Hadamard
J. Hadamard. Sur les problèmes aux dérivées partielles et leur signification physique. Princeton University Bulletin , pages 49–52, 1902
1902
-
[18]
arXiv preprint arXiv:1905.00313 , title =
Elad Hazan and Sham Kakade. Revisiting the Polyak step size. arXiv Preprint , arXiv:1905.00313, 2022
-
[19]
Strong error analysis for stochastic gradient descent optimization algorithms
Arnulf Jentzen, Benno Kuckuck, Ariel Neufeld, and Philippe von Wurstemberger. Strong error analysis for stochastic gradient descent optimization algorithms. IMA Journal of Numerical Analysis, 41(1):455–492, 05 2020
2020
-
[20]
Lower error bounds for the stochastic gradient descent optimization algorithm: Sharp convergence rates for slowly and fast decaying learning rates
Arnulf Jentzen and Philippe von Wurstemberger. Lower error bounds for the stochastic gradient descent optimization algorithm: Sharp convergence rates for slowly and fast decaying learning rates. Journal of Complexity , 57:101438, 2020
2020
-
[21]
Accelerating stochastic gradient descent using predictive vari- ance reduction
Rie Johnson and Tong Zhang. Accelerating stochastic gradient descent using predictive vari- ance reduction. In Advances in Neural Information Processing Systems , volume 26. Curran Associates, Inc., 2013
2013
-
[22]
Linear convergence of gradient and proximal- gradient methods under the Polyak-Łojasiewicz condition
Hamed Karimi, Julie Nutini, and Mark Schmidt. Linear convergence of gradient and proximal- gradient methods under the Polyak-Łojasiewicz condition. In Machine Learning and Knowl- edge Discovery in Databases , pages 795–811, Cham, 2016. Springer International Publishing. Simon Weissmann Introduction to stochastic gradient methods Page 124
2016
-
[23]
Better theory for SGD in the nonconvex world
Ahmed Khaled and Peter Richtárik. Better theory for SGD in the nonconvex world. Trans- actions on Machine Learning Research , 2023
2023
-
[24]
H.K. Khalil. Nonlinear Systems. Pearson Education. Prentice Hall, 2002
2002
-
[25]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv Preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[26]
Wahrscheinlichkeitstheorie
Achim Klenke. Wahrscheinlichkeitstheorie. Springer, 2006
2006
-
[27]
First-order and Stochastic Optimization Methods for Machine Learning
Guanghui Lan. First-order and Stochastic Optimization Methods for Machine Learning . Springer Cham, 1st edition, 2021
2021
-
[28]
Lee, Ioannis Panageas, Georgios Piliouras, Max Simchowitz, Michael I
Jason D. Lee, Ioannis Panageas, Georgios Piliouras, Max Simchowitz, Michael I. Jordan, and Benjamin Recht. First-order methods almost always avoid strict saddle points. Mathematical Programming, 176(1):311–337, July 2019
2019
-
[29]
Analysis and design of optimization algorithms via integral quadratic constraints
Laurent Lessard, Benjamin Recht, and Andrew Packard. Analysis and design of optimization algorithms via integral quadratic constraints. SIAM J. on Optimization , 26(1):57–95, 2016
2016
-
[30]
On almost sure convergence rates of stochastic gradient methods
Jun Liu and Ye Yuan. On almost sure convergence rates of stochastic gradient methods. In Proceedings of Thirty Fifth Conference on Learning Theory , volume 178 of Proceedings of Machine Learning Research, pages 2963–2983. PMLR, 02–05 Jul 2022
2022
-
[31]
High prob- ability convergence of stochastic gradient methods
Zijian Liu, Ta Duy Nguyen, Thien Hang Nguyen, Alina Ene, and Huy Nguyen. High prob- ability convergence of stochastic gradient methods. In Proceedings of the 40th International Conference on Machine Learning , volume 202 of Proceedings of Machine Learning Research , pages 21884–21914. PMLR, 23–29 Jul 2023
2023
-
[32]
Convergence of a stochastic gradient method with mo- mentum for non-smooth non-convex optimization
Vien Mai and Mikael Johansson. Convergence of a stochastic gradient method with mo- mentum for non-smooth non-convex optimization. In Proceedings of the 37th International Conference on Machine Learning , volume 119 of Proceedings of Machine Learning Research , pages 6630–6639. PMLR, 13–18 Jul 2020
2020
-
[33]
On the almost sure convergence of stochastic gradient descent in non-convex problems
Panayotis Mertikopoulos, Nadav Hallak, Ali Kavis, and Volkan Cevher. On the almost sure convergence of stochastic gradient descent in non-convex problems. In Advances in Neural Information Processing Systems , volume 33, pages 1117–1128. Curran Associates, Inc., 2020
2020
-
[34]
Non-asymptotic analysis of stochastic approximation algo- rithms for machine learning
Eric Moulines and Francis Bach. Non-asymptotic analysis of stochastic approximation algo- rithms for machine learning. In Advances in Neural Information Processing Systems , vol- ume 24. Curran Associates, Inc., 2011
2011
-
[35]
Lectures on Convex Optimization
Yurii Nesterov. Lectures on Convex Optimization . Springer Cham, 2nd edition, 2018. Simon Weissmann Introduction to stochastic gradient methods Page 125
2018
-
[36]
Nguyen, Phuong Ha Nguyen, Peter Richtárik, Katya Scheinberg, Martin Takác, and Marten van Dijk
Lam M. Nguyen, Phuong Ha Nguyen, Peter Richtárik, Katya Scheinberg, Martin Takác, and Marten van Dijk. New convergence aspects of stochastic gradient algorithms. Journal of Machine Learning Research, 20:176:1–176:49, 2018
2018
-
[37]
Introduction to Optimization
Boris T Polyak. Introduction to Optimization . Translations series in mathematics and engi- neering. Optimization Software, Publications Division, 1987
1987
-
[38]
B.T. Polyak. Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics , 4(5):1–17, 1964
1964
-
[39]
On the momentum term in gradient descent learning algorithms
Ning Qian. On the momentum term in gradient descent learning algorithms. Neural Networks, 12(1):145–151, 1999
1999
-
[40]
Robbins and D
H. Robbins and D. Siegmund. A convergence theorem for non negative almost supermartin- gales and some applications. In Jagdish S. Rustagi, editor, Optimizing Methods in Statistics , pages 233–257. Academic Press, 1971
1971
-
[41]
A Stochastic Approximation Method
Herbert Robbins and Sutton Monro. A Stochastic Approximation Method. The Annals of Mathematical Statistics, 22(3):400 – 407, 1951
1951
-
[42]
An overview of gradient descent optimization algorithms
Sebastian Ruder. An overview of gradient descent optimization algorithms. arXiv Preprint , arXiv:1609.04747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Minimizing finite sums with the stochastic average gradient
Mark Schmidt, Nicolas Le Roux, and Francis Bach. Minimizing finite sums with the stochastic average gradient. Mathematical Programming, 162(1):83–112, 2017
2017
-
[44]
Almost sure convergence rates for stochastic gradient descent and stochastic heavy ball
Othmane Sebbouh, Robert M Gower, and Aaron Defazio. Almost sure convergence rates for stochastic gradient descent and stochastic heavy ball. In Proceedings of Thirty Fourth Conference on Learning Theory . PMLR, 2021
2021
-
[45]
Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude
Tijmen Tieleman and Geoffrey Hinton. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning , 4(2):26– 31, 2012
2012
-
[46]
Almost sure convergence of stochastic gradient methods under gradient domination
Simon Weissmann, Sara Klein, Waïss Azizian, and Leif Döring. Almost sure convergence of stochastic gradient methods under gradient domination. Transactions on Machine Learning Research, 2025
2025
-
[47]
Multilevel optimization for inverse prob- lems
Simon Weissmann, Ashia Wilson, and Jakob Zech. Multilevel optimization for inverse prob- lems. In Proceedings of Thirty Fifth Conference on Learning Theory, volume 178 of Proceedings of Machine Learning Research , pages 5489–5524. PMLR, 02–05 Jul 2022
2022
-
[48]
Wilson, Benjamin Recht, and Michael I
Ashia C. Wilson, Benjamin Recht, and Michael I. Jordan. A Lyapunov analysis of accelerated methods in Optimization. J. Mach. Learn. Res. , 22(1), jan 2021. Simon Weissmann Introduction to stochastic gradient methods Page 126
2021
-
[49]
Matthew D. Zeiler. Adadelta: An adaptive learning rate method. arXiv Preprint , arXiv:1212.5701, 2012. A Appendix A.1 Convex sets and functions We give a brief overview of convex functions and properties that are important for optimization. This appendix covers selected material from [ 1, Appendix B], adapted to the notation and scope of these notes. We s...
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[50]
Then \i∈ICi is a convex set
Let fCi, i 2 Ig be a family of convex sets. Then \i∈ICi is a convex set
-
[51]
127 Simon Weissmann Introduction to stochastic gradient methods Page 128
Let C1, C2 Rd be two convex sets, then the set C = fx 2 Rd j x = x1 + x2, x 1 2 C1, x2 2 C2g is a convex set. 127 Simon Weissmann Introduction to stochastic gradient methods Page 128
-
[52]
The image of a convex set under linear transformation is again a convex set
-
[53]
Then the level sets Aα = fx 2 C j f (x) αg and Bα = fx 2 C j f (x) < αg are convex sets for all α 2 R
Let C Rd be a convex set and let f : C ! R be a convex function. Then the level sets Aα = fx 2 C j f (x) αg and Bα = fx 2 C j f (x) < αg are convex sets for all α 2 R. Definition A.1.3. Let f : C ! R be a function and C Rd be a convex set. We define the epigraph of f as E(f ) := f(x, w) 2 C R j f (x) wg, the set of all points above the graph of f defined ...
-
[54]
Every linear function is convex
-
[55]
Every norm in Rd is convex
-
[56]
, fn be convex functions and c1,
Let f1, . . . , fn be convex functions and c1, . . . , cn 0. a) Then x 7!Pn i=1 fi(x) is a convex function. b) Then x 7! supi=1,...,n fi(x) is a convex function. Exercise A.1.2. Prove the properties presented in Example A.1.6. Proposition A.1.7. Let C Rd be a convex set and let f : C ! R be differentiable over C. Then the following holds true:
-
[57]
The function f is convex over C if and only if f (z) f (x) + (z x)⊤rf (x), for all x, z 2 C
-
[58]
If f (z) > f (x) + (z x)⊤rf (x), x 6= z, for all x, z 2 C, then f is strictly convex. Proof. We only prove the first assertion, the second one follows by similar argumentation. Firstly, assume that f is convex and let x, z 2 C. Since C is a convex set, x+a(z x) 2 C for all a 2 (0, 1). The convexity of f implies that f (x + a(z x)) af (z) + (1 a)f (x), Sim...
-
[59]
If r2f (x) is positive semi-definite for all x 2 C, then f is convex over C
-
[60]
If r2f (x) is positive definite for all x 2 C, then f is strictly convex over C
-
[61]
If C = Rd and f is convex, then r2f (x) is positive semi-definite for all x 2 C
-
[62]
Moreover, f is strictly convex if and only if Q is positive definite
The quadratic function x 7! f (x) = x⊤Qx is convex if and only if Q is positive semi- definite. Moreover, f is strictly convex if and only if Q is positive definite. Proof. 1. Let x, y 2 C, then by the mean-value theorem there exists α 2 [0, 1] such that f (y) = f (x) + (y x)⊤rf (x) + 1 2 (y x)⊤r2f (x + α(y x))(y x) f (x) + (y x)⊤f (x), Simon Weissmann In...
-
[63]
Follows similarly as the proof of the first claim
-
[64]
By assumption we have that x 7! r 2f (x) is continuous, such that for ¯α > 0 small enough it holds true that z⊤r2f (x)z < 0, for α 2 [0, ¯α)
Let f be convex and suppose that there exists x 2 Rd such that z⊤r2f (x)z < 0 for some z 2 Rd. By assumption we have that x 7! r 2f (x) is continuous, such that for ¯α > 0 small enough it holds true that z⊤r2f (x)z < 0, for α 2 [0, ¯α). For an arbitrary ˜α 2 [0, ¯α) we set ˜z = ˜αz. By the mean-value theorem there exists β 2 [0, 1] such that f (x + ˜z) = ...
-
[65]
The hessian of f is given by r2f (x) = 2 Q for all x 2 Rd. With 1. and 3. it follows that f is convex if and only if Q is positive semi-definite. If Q is positive definite, then convexity of f follows by the 3. assertion. It is left to prove that strict convexity of f implies that Q is positive definite. Assume that f is strictly convex, then by 3. we kno...
-
[66]
Exercise A.1.3
A function f : C ! R is µ-strongly convex if and only if its hessian r2f (x) is uniformly positive definite with z⊤r2f (x)z µkzk2 for all x 2 C and all z 2 Rd. Exercise A.1.3. Prove Proposition A.1.10. A.2 Optimality conditions We recall a few basic optimality conditions that are used throughout the notes. The selection and presentation are partly guided ...
-
[67]
r2f (x∗) (strictly) positive definite. Then x∗ is a strict local minimum of f and there exist γ > 0, ε > 0 such that f (x) f (x∗) + γ 2 kx x∗k2 Simon Weissmann Introduction to stochastic gradient methods Page 134 for all x 2 B ε(x∗). Before proving Theorem A.2.4, we will need to prove the following auxiliary result. Lemma A.2.5. Let A 2 Rd×d be a symmetri...
-
[68]
λ1kzk2 z⊤Az λdkzk2 for all z 2 Rd
-
[69]
The matrix A is (strict) positive definite if and only if all eigenvalues are (strictly) positive. Proof. We start with the first assertion. Let z 2 Rd and write z = dX i=1 ξivi with coefficients ξi 2 R. Then we can write z⊤Az = dX i=1 ξ2 i hvi, Av i|{z} =λivi i = dX i=1 λiξ2 i kvik2 8 < : λ1 Pd i=1 ξ2 i kvik2 = λikzk2, λd Pd i=1 ξ2 i kvik2 = λdkzk2., whic...
-
[70]
Every local minimum of f over S is also a global minimum over S
-
[71]
If f is even strictly convex, then there exists at most one global minimum
-
[72]
Then the condition rf (x∗) = 0 is a sufficient and necessary condition for x∗ 2 S to be a global minimum of f over S
Let S be an open set. Then the condition rf (x∗) = 0 is a sufficient and necessary condition for x∗ 2 S to be a global minimum of f over S. A.3 Lyapunov methods for optimization We will motivate the application of Lyapunov theory to optimization methods based on stability analysis of ordinary differential equations (ODEs). Lyapunov theory can be applied to...
-
[73]
stable, if for all ε > 0 there exists a δ = δ(ε) > 0 such that: kz(0)k < δ =) k z(t)k < ε for all t 0
-
[74]
unstable, if ¯z is not stable
-
[75]
locally asymptotically stable , if ¯z is stable and δ > 0 can be chosen such that: kz(0)k < δ =) lim t→∞ z(t) = 0
-
[76]
globally stable , if ¯z is stable and limε→∞ δ(ε) = 1
-
[77]
We consider a continuously differentiable function V : Rd ! R - in the following called candidate of a Lyapunov function - which will be used to be described along the trajectories
globally asymptotically stable , if limt→∞ z(t) = 0 for all z0 2 Rd. We consider a continuously differentiable function V : Rd ! R - in the following called candidate of a Lyapunov function - which will be used to be described along the trajectories. With the help of chain rule, we can describe the dynamical behavior of V along the trajectory of z(t): dV ...
-
[78]
V (¯z) = 0 and V (z) > 0 for all z 2 Rd n f¯zg,
-
[79]
V (z) ! 1 for kzk ! 1 ,
-
[80]
Simon Weissmann Introduction to stochastic gradient methods Page 137 If W (z) 0 for all z 2 Rd, then ¯z is globally stable
dV (z(t)) dt = hrzV (z(t)), g(z(t))i W (z(t)), for some continuous function W : Rd ! R. Simon Weissmann Introduction to stochastic gradient methods Page 137 If W (z) 0 for all z 2 Rd, then ¯z is globally stable. Moreover, if W (z) > 0 for all z 2 Rd nf ¯zg, then ¯z is even globally asymptotically stable. A function satisfying the above conditions is somet...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.