Efficient Financial Language Understanding via Distillation with Synthetic Data
Pith reviewed 2026-06-26 20:59 UTC · model grok-4.3
The pith
Clustering real examples to pick seeds lets compact models match or beat large teachers on financial sentiment tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
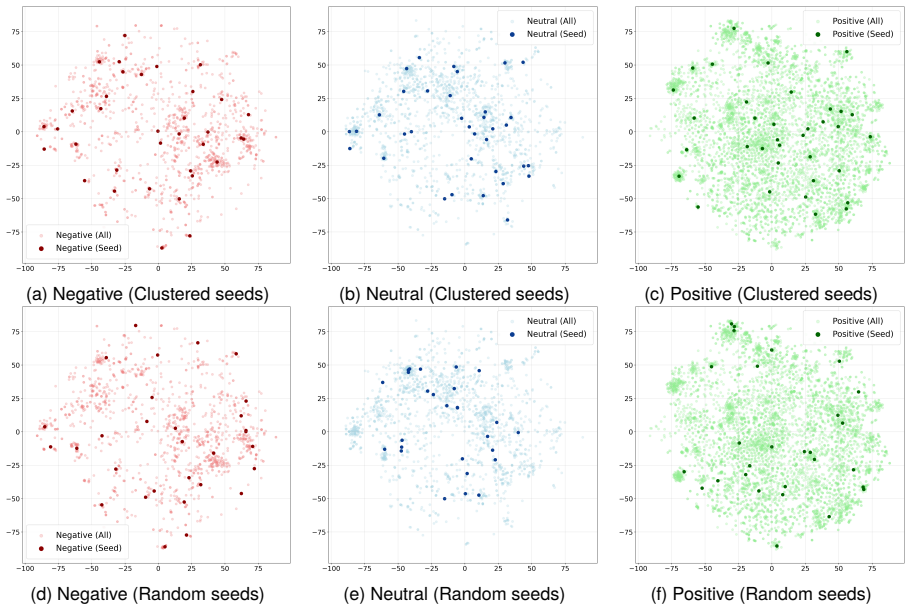
The framework clusters a small set of real labeled examples and selects seeds from those clusters to generate synthetic examples through structured few-shot prompting from a large instruction-tuned teacher. This clustering step produces more representative synthetic data than random sampling. Compact student models trained on the resulting synthetic-seed corpus reach strong performance with minimal supervision; on a complex noisy text domain the student even surpasses the teacher, while staying competitive on formal text.
What carries the argument
Clustering-based seed selection that identifies representative real examples to guide structured few-shot prompting and synthetic data generation for student training.
If this is right
- Compact models reach strong performance with only a small number of hand-labeled real examples.
- On noisy financial text domains the trained student can outperform the original teacher model.
- Performance remains competitive with the teacher on formal text domains.
- The overall method supplies a practical route to resource-efficient domain adaptation in financial NLP.
Where Pith is reading between the lines
- The same clustering-plus-synthetic pipeline could be tested on other low-resource, high-confidentiality text domains beyond finance.
- The observed outperformance on noisy data raises the question of whether synthetic data generated this way systematically reduces sensitivity to domain-specific noise.
- Replacing the clustering step with other diversity-aware selection methods might further improve seed quality and student results.
Load-bearing premise
The synthetic examples produced by structured few-shot prompting from the teacher model are sufficiently accurate in both content distribution and label quality to serve as effective training data for the student without introducing substantial noise or systematic bias that would degrade downstream performance.
What would settle it
A controlled comparison in which student models trained on the clustering-selected synthetic corpus perform no better than students trained on an equal-sized random-seed synthetic corpus, or worse than the teacher on held-out real financial texts, would falsify the central effectiveness claim.
Figures

read the original abstract
Large instruction-following models are powerful but costly to deploy, particularly in finance, where labelled data are limited by confidentiality and expert annotation cost. We present an efficient framework for financial sentiment analysis through distillation with synthetic data, transferring knowledge from a large instruction-tuned teacher to compact student models. The framework is designed for low-resource conditions, where a small set of real examples are collected and labelled by hand. The framework then clusters the examples and uses the clusters to select seeds for generating synthetic examples via structured few-shot prompting. Experiments show that clustering-based seed selection yields more representative synthetic data than random sampling, enabling compact models to achieve strong performance with minimal supervision. Notably, on a more complex and noisy text domain, the compact model trained on the complete synthetic-seed corpus even outperforms the teacher model, while remaining competitive on formal text. The framework provides a practical route toward resource-efficient domain adaptation in financial NLP with minimal human labelling effort.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an efficient framework for financial sentiment analysis via knowledge distillation from a large instruction-tuned teacher model to compact student models. A small set of hand-labeled real examples is clustered to select representative seeds, which are then used for structured few-shot prompting to generate synthetic training data. The central claims are that clustering-based seed selection produces more representative synthetic data than random sampling, enabling strong student performance with minimal supervision, and that the student can outperform the teacher on a complex noisy text domain while remaining competitive on formal text.
Significance. If the experimental results hold under detailed scrutiny, the work addresses a practical challenge in financial NLP where labeled data are scarce due to confidentiality and expert annotation costs. It demonstrates a low-supervision route to domain adaptation that could enable deployment of efficient models, and the observation that synthetic data can allow a compact model to exceed teacher performance in noisy domains is potentially impactful if reproducible.
major comments (1)
- [Abstract] Abstract: The abstract reports positive experimental outcomes for clustering versus random sampling and student outperforming teacher in one domain, but provides no metrics, baselines, dataset sizes, statistical tests, or error analysis, leaving the central claims difficult to verify from the given information.
minor comments (1)
- The description of how clusters are formed, how seeds are selected within clusters, and the exact structure of the few-shot prompts would benefit from additional detail to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports positive experimental outcomes for clustering versus random sampling and student outperforming teacher in one domain, but provides no metrics, baselines, dataset sizes, statistical tests, or error analysis, leaving the central claims difficult to verify from the given information.
Authors: We agree that the abstract is too high-level and omits quantitative details that would allow readers to assess the claims without consulting the full text. In the revised version we will expand the abstract to report the key accuracy/F1 deltas for clustering vs. random sampling, the student-vs-teacher comparison on the noisy domain, the number of real seed examples and synthetic examples generated, and a brief note on statistical significance testing. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical framework for knowledge distillation in financial sentiment analysis using synthetic data from a teacher model, with clustering for seed selection versus random sampling. No equations, derivations, or first-principles results are present that could reduce to fitted inputs or self-referential definitions by construction. All claims rest on experimental comparisons of data generation methods and downstream model performance, which are independent of any self-citation load-bearing steps or ansatz smuggling. The work is self-contained as standard ML practice with no circular reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of clusters
axioms (1)
- domain assumption Few-shot prompting from a large teacher model can generate synthetic labeled examples whose distribution and labels are useful for training a student model in the target domain.
Reference graph
Works this paper leans on
-
[1]
Introduction Financial sentiment analysis supports investment decision-making and market monitoring, yet an- notated data are often scarce due to confiden- tiality and expert labelling costs (Lopez-Lira and Tang, 2023; Yang et al., 2023; Kirtac and Germano, 2024). Large language models (LLMs) such as GPT-4o (OpenAI, 2024) offer a potential solution: they ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Related Work Distillation and Model CompressionLLMs such as GPT-4o (OpenAI, 2024) demonstrate strong instruction-following and reasoning capa- bilities across domains, yet they remain generalists that can lag behind fine-tuned, task-specific sys- tems on domain benchmarks (Koćon et al., 2023; Liang et al., 2023). Their substantial computa- tional requirem...
2024
-
[3]
This idea is related to coreset selection, which identifies samples that give good coverage of a larger train- ing set (Sener and Savarese, 2018)
to SBERT embeddings yields semantically diverse centroids, ensuring that generated data span the breadth of financial expressions rather than repeating frequent surface forms. This idea is related to coreset selection, which identifies samples that give good coverage of a larger train- ing set (Sener and Savarese, 2018). Prompt en- gineering also plays a ...
2018
-
[4]
provide predefined prompt formats that con- trol how instructions, examples, and outputs are composed. These templates leveragein-context learning(Brown et al., 2020), where a few labelled instances are embedded directly within the prompt to guide model behaviour without parameter up- dates. This structure enables scalable expansion of small human-labelle...
2020
-
[5]
Methodology We propose a lightweight and reproducible frame- work fordistillation with synthetic data gener- ation, transferring instruction-following behaviour from a large teacher model (GPT-4o) to compact encoder-based students forfinancial sentiment classification. As shown in Figure 1, the work- flow comprises three main stages: (1) embedding- based ...
2019
-
[6]
{$EX_POS}→Positive Now generate a new financial news sen- tence expressing: {$TARGET_LABEL} Template 2 — Single-seed paraphrase expan- sion.Generates paraphrases of a labelled seed withdiversewordingandstructurewhilepreserving sentiment. The following sentence has sentiment {$LABEL}: {$SEED_SENTENCE} Generate 3 new sentences that: - Express the same senti...
-
[7]
Design rationale.Template 1 establishes label semantics; Template 2 enhances lexical and syn- tactic diversity; Template 3 promotes intra-class generalisation
{$SEED_3} Generate 5 more realistic sentences with the same sentiment. Design rationale.Template 1 establishes label semantics; Template 2 enhances lexical and syn- tactic diversity; Template 3 promotes intra-class generalisation. Together, these templates aim to produce a compact yet expressive synthetic corpus aligned with financial tone and sentiment. ...
2019
-
[8]
ES” = early stopping; “Synth
Datasets and Experimental Setup DatasetsWe evaluate the proposed framework on two complementary English corpora: (i)Fi- nancial PhraseBank(Malo et al., 2014),(Malo et al., 2014), consisting of formal, expert-authored statements, and (ii)Twitter Financial News Senti- ment(on Huggingface, 2022), comprising informal, real-time investor discourse. Labels for ...
2014
-
[9]
sues”(negative),“moves
Results and Analysis Inthissection,wereporttheperformanceofthepro- posed synthetic data distillation framework across datasets and models, assess the contribution of each prompt template, compare clustering-based versus random seed selection, and analyse errors. 5.1. Overall Performance Table 2 summarises the results of compact student models across datas...
1947
-
[10]
Conclusion and Future Work This study presented a lightweight framework for distillation from synthetic data, enabling com- pact encoder models to inherit instruction-following behaviourfromlargeteachersusingaminimalnum- ber of domain-specific seeds. Through clustering- based seed selection and structured prompting, the framework generates semantically di...
-
[11]
Bearish: UPDATE 1–California sues e-cigarette maker Juul for selling nicotine products to youth
-
[12]
Neutral: Stocks making the biggest moves midday: TD Ameritrade, Tiffany, Uber, Hasbro & more
-
[13]
Bullish: $AMZN — Amazon: One Of The Best Long-Term Investments In The Tech Sector. Synth. e.g.:Wall Street opens flat as investors await key economic data releases later this week. Template 2 (P2 – For Bullish) Real Seed:Oil boosted by renewed hopes for global production cuthttps://t.co/4tAO1U31nz Synth. e.g.:Hopes of a coordinated decrease in global oil ...
-
[14]
$AMZN – Amazon: One Of The Best Long-Term Investments In The Tech Sector
-
[15]
STOCKS SURGE INTO THE CLOSE: Dow up 7.59%, Nasdaq up 7.35%, S&P up 6.95%
-
[16]
UnitedHealth stock price target raised to $335 from $310 at SunTrust RH. Synth. e.g.:Apple Inc. ($AAPL) hits a new all-time high as analysts increase price target to $225, citing strong iPhone sales and services growth. Table 3: Representative real and synthetic examples grouped by prompt template. Each template example is shown for one sentiment type: th...
2023
-
[17]
Limitations While effective, the proposed framework exhibits several limitations. First, performance can vary with prompt phrasing and the representativeness of selected seeds; domain shift may reduce gains if the seed distribution fails to capture emerging financial expressions. Second, reliance on a single teacher model restricts linguistic variety and ...
-
[18]
Bibliographical References Dogu Araci. 2019. FinBERT: financial sentiment analysiswithpre-trainedlanguagemodels.arXiv preprint arXiv:1908.10063. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sas- try, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, ...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[19]
InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2020, pages 4163–4174, Online
TinyBERT: Distilling BERT for natural lan- guage understanding. InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2020, pages 4163–4174, Online. Association for Computational Linguistics. KemalKirtacandGuidoGermano.2024.Sentiment trading with large language models.Finance Research Letters, 62:105227. Jan Koćon, Igor Cichecki, Olgierd Ka...
-
[20]
Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference.arXiv preprint arXiv:2412.13663. Sarah Wiegreffe and Ana Marasović. 2021. Teach me to explain: A review of datasets for explain- ablenaturallanguageprocessing. In35thconfer- ence on Neural Information Processing Systems (Ne...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Finbert: A pretrained language model for financial communications.arXiv preprint arXiv:2006.08097. Ranran Zhen, Juntao Li, Yixin Ji, Zhenlin Yang, Tong Liu, Qingrong Xia, Xinyu Duan, Zhefeng Wang,BaoxingHuai,andMinZhang.2025. Tam- ing the titans: A survey of efficient LLM infer- ence serving. InProceedings of the 18th Interna- tional Natural Language Gene...
-
[22]
2014.Financial PhraseBank
Language Resource References Malo, Pekka and Sinha, Ankur and Takala, Pekka and Korhonen, Pasi and Wallenius, Jyrki. 2014.Financial PhraseBank. PID https://huggingface.co/datasets/takala/financial_phrasebank. Sentiment annotations for financial text. Zeroshot on Huggingface. 2022.Twitter Financial News Sentiment Corpus. PID https://huggingface.co/datasets...
2014
-
[23]
Dataset Examples Examples illustrating the text data from Financial Phrasebank and Twitter Financial News Sentiment are shown in Table 5
Appendix 10.1. Dataset Examples Examples illustrating the text data from Financial Phrasebank and Twitter Financial News Sentiment are shown in Table 5. 10.2. Statistical and Reproducibility Analysis To assess the reliability and significance of the pro- posed framework, we combined statistical testing with empirical consistency analysis. Although each ex...
1947
-
[24]
Table6thereforereportsonlythehyperparame- ters that varied across model families and datasets (learning rate and the number of frozen encoder layers). 10.4. Layer Freezing and Stability Notes DistilBERT and ModernBERT, with deeper stacks (6–12 layers) and wider hidden sizes, achieved stable convergence with a learning rate of1× 10−4 andcouldsafelyfreezefo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.