FlowTrain: Flow-Based Decoupled Training for Industrial-Grade Vision-Language Models
Pith reviewed 2026-06-26 09:11 UTC · model grok-4.3
The pith
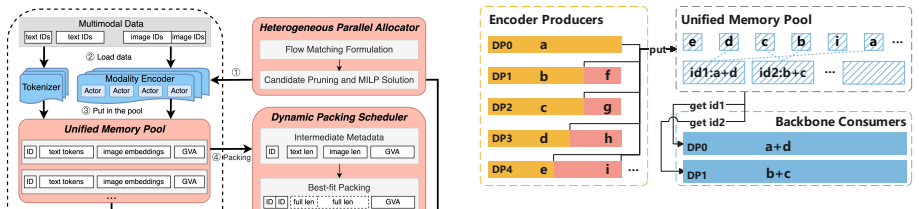
FlowTrain reformulates VLM training as a producer-consumer dataflow so that the vision encoder and language backbone can run independently over a shared memory pool.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
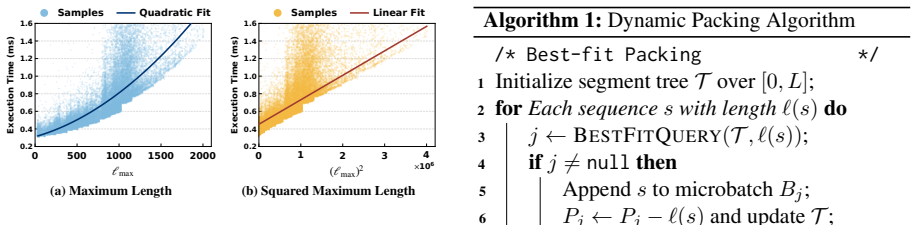
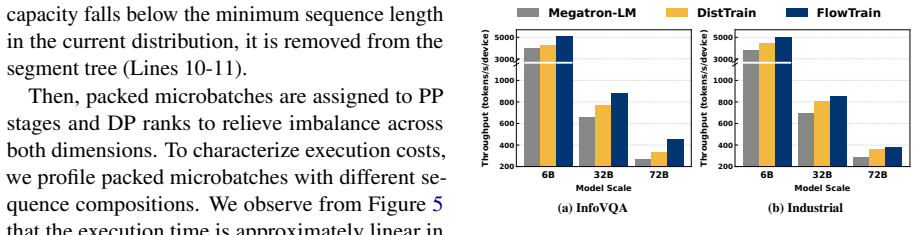
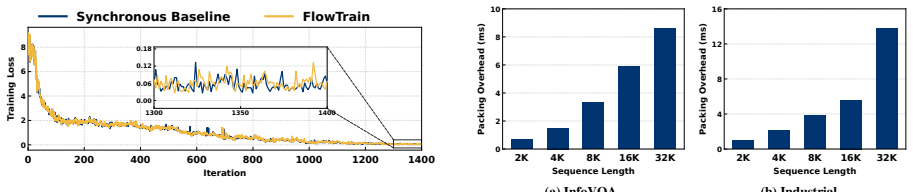
FlowTrain is a flow-based decoupled training framework that reformulates VLM training as a producer-consumer dataflow coordinated through a unified memory pool. The encoder and backbone progress independently over a global virtual address space. A heterogeneous parallel allocator assigns module-specific parallelism by solving a throughput matching problem, while a dynamic packing scheduler builds balanced microbatches at runtime according to actual LLM-side computation cost.
What carries the argument
producer-consumer dataflow coordinated through a unified memory pool that allows independent progress of encoder and backbone
If this is right
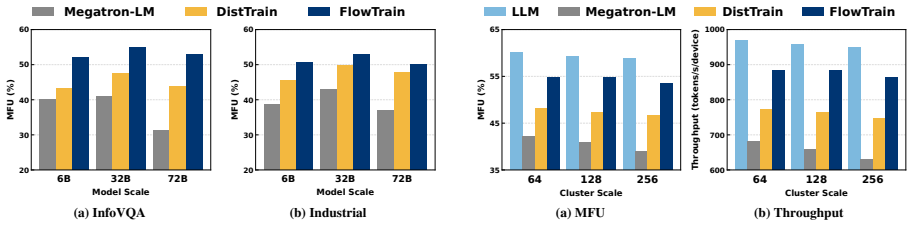
- FlowTrain reaches over 50 percent MFU on real workloads.
- Throughput improves by up to 1.7 times compared with prior VLM training methods.
- The efficiency gap between VLM training and LLM-only training narrows substantially.
- Module-specific parallelism strategies become feasible without batch synchronization.
Where Pith is reading between the lines
- Similar decoupling might improve training for other multimodal models that combine heterogeneous components.
- Runtime schedulers could adapt to varying hardware or workload changes beyond the tested cases.
- Memory pool management techniques may generalize to other producer-consumer patterns in distributed systems.
Load-bearing premise
That splitting the encoder and backbone into independent flows keeps the training correct and convergent while the allocator and scheduler run without adding new slowdowns.
What would settle it
A head-to-head comparison on the same VLM workload showing that FlowTrain either diverges, converges to worse loss, or delivers lower throughput than a standard monolithic trainer.
Figures


read the original abstract
Industrial-grade distributed training of vision-language models (VLMs) remains far less efficient than that of unimodal LLMs. Existing solutions either follow a monolithic design that assigns uniform parallelism to heterogeneous modules or adopt a disaggregated deployment that separates modules while executing them as a batch-synchronized pipeline. In this paper, we highlight that the above solutions are still not sufficient, and VLM training can be further decoupled. To this end, we present FlowTrain, a flow-based decoupled training framework that reformulates VLM training as a producer-consumer dataflow coordinated through a unified memory pool. The encoder and backbone can progress independently over a global virtual address space. Since this execution decoupling fundamentally changes the optimization objective of allocation and scheduling, FlowTrain further introduces a heterogeneous parallel allocator that assigns module-specific parallelism strategies by solving a throughput matching problem. The dynamic packing scheduler is used to construct balanced microbatches at runtime according to the actual LLM-side computation cost. Extensive experiments on real-world workloads show that FlowTrain achieves over 50% MFU and up to 1.7x throughput improvement, narrowing the efficiency gap to LLM-only training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlowTrain, a flow-based decoupled training framework for industrial-grade vision-language models. It reformulates VLM training as a producer-consumer dataflow over a unified memory pool, allowing the encoder and backbone to progress independently over a global virtual address space. A heterogeneous parallel allocator solves a throughput-matching problem to assign module-specific parallelism strategies, while a dynamic packing scheduler constructs balanced microbatches at runtime based on LLM-side computation cost. The abstract reports that extensive experiments on real-world workloads achieve over 50% MFU and up to 1.7x throughput improvement, narrowing the efficiency gap to LLM-only training.
Significance. If the decoupling preserves convergence properties and the reported efficiency gains hold under rigorous validation, the work could meaningfully advance practical VLM training by enabling higher utilization of heterogeneous hardware without monolithic parallelism constraints.
major comments (2)
- [Abstract] Abstract: the central throughput claim (1.7x improvement, >50% MFU) depends on the assertion that independent encoder/backbone progress yields equivalent optimization trajectories to monolithic training. The description provides no mechanism for bounding feature/gradient staleness, no mention of how back-propagation or optimizer steps are reconciled when producer and consumer rates differ, and no reference to any synchronization primitive or staleness analysis.
- [Abstract] Abstract: no experimental details are supplied (model scales, datasets, hardware, error bars, loss curves, or ablations of synchronous vs. decoupled execution). Without these, the throughput numbers cannot be separated from possible degradation in final model quality, rendering the efficiency claims unverifiable from the provided text.
minor comments (1)
- [Abstract] Abstract: 'MFU' appears without expansion; define Model FLOPs Utilization on first use.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable comments on our manuscript. We address each major comment point-by-point below and plan to incorporate revisions to enhance the clarity of our presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central throughput claim (1.7x improvement, >50% MFU) depends on the assertion that independent encoder/backbone progress yields equivalent optimization trajectories to monolithic training. The description provides no mechanism for bounding feature/gradient staleness, no mention of how back-propagation or optimizer steps are reconciled when producer and consumer rates differ, and no reference to any synchronization primitive or staleness analysis.
Authors: We recognize that the abstract does not provide explicit details on mechanisms for bounding feature or gradient staleness, nor does it describe how back-propagation and optimizer steps are handled under decoupled rates or reference synchronization primitives. The manuscript describes the flow-based coordination through a unified memory pool and the dynamic packing scheduler to balance computation. To fully address this concern, we will revise the abstract and add a new subsection in the methodology or analysis section providing a formal discussion of staleness bounds and the synchronization approach used. This revision will make the equivalence of optimization trajectories more rigorous. revision: yes
-
Referee: [Abstract] Abstract: no experimental details are supplied (model scales, datasets, hardware, error bars, loss curves, or ablations of synchronous vs. decoupled execution). Without these, the throughput numbers cannot be separated from possible degradation in final model quality, rendering the efficiency claims unverifiable from the provided text.
Authors: We agree that the abstract lacks specific experimental details such as model scales, datasets, hardware configurations, error bars, loss curves, and ablations. While these are present in the full Experiments section of the manuscript, the abstract's brevity makes the claims difficult to verify independently. We will update the abstract to include key details on the experimental setup and results, including a brief mention of the ablations comparing synchronous and decoupled execution, to ensure the efficiency claims are properly contextualized. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description contain no equations, fitted parameters, self-citations, or derivation steps that reduce to inputs by construction. The framework is presented as an engineering reformulation with runtime allocators and schedulers whose correctness is asserted via experimental throughput results rather than any self-referential math or uniqueness theorems. No load-bearing claims rely on prior author work or ansatzes smuggled through citation. The central performance claims rest on external benchmarks (MFU, throughput) that are independently measurable and not forced by the method's own definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[2]
International Conference on Learning Representations , volume=
Flashattention-2: Faster attention with better parallelism and work partitioning , author=. International Conference on Learning Representations , volume=
-
[3]
arXiv preprint arXiv:2404.10830 , year=
Fewer truncations improve language modeling , author=. arXiv preprint arXiv:2404.10830 , year=
-
[4]
Scalable Vision Language Model Training via High Quality Data Curation
Dong, Hongyuan and Kang, Zijian and Yin, Weijie and Liang, Xiao and Feng, Chao and Ran, Jiao. Scalable Vision Language Model Training via High Quality Data Curation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
2025
-
[5]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[6]
2025 USENIX Annual Technical Conference (USENIX ATC 25) , pages=
Optimus: Accelerating \ Large-Scale \ \ Multi-Modal \ \ LLM \ Training by Bubble Exploitation , author=. 2025 USENIX Annual Technical Conference (USENIX ATC 25) , pages=
2025
-
[7]
21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24) , pages=
\ DISTMM \ : Accelerating distributed multimodal model training , author=. 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24) , pages=
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Spacedrive: Infusing spatial awareness into vlm-based autonomous driving , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[9]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
A survey of state of the art large vision language models: Benchmark evaluations and challenges , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[10]
19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25) , pages=
Understanding stragglers in large model training using what-if analysis , author=. 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25) , pages=
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Is-bench: Evaluating interactive safety of vlm-driven embodied agents in daily household tasks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[12]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Infographicvqa , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[13]
arXiv preprint arXiv:2211.13878 , year=
Galvatron: Efficient transformer training over multiple gpus using automatic parallelism , author=. arXiv preprint arXiv:2211.13878 , year=
-
[14]
13th USENIX symposium on operating systems design and implementation (OSDI 18) , pages=
Ray: A distributed framework for emerging \ AI \ applications , author=. 13th USENIX symposium on operating systems design and implementation (OSDI 18) , pages=
-
[15]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[16]
Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , volume=
A Survey on Efficient Vision-Language Models , author=. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , volume=. 2025 , publisher=
2025
-
[17]
arXiv preprint arXiv:1909.08053 , year=
Megatron-lm: Training multi-billion parameter language models using model parallelism , author=. arXiv preprint arXiv:1909.08053 , year=
Pith/arXiv arXiv 1909
-
[18]
arXiv preprint arXiv:2511.00279 , year=
Longcat-flash-omni technical report , author=. arXiv preprint arXiv:2511.00279 , year=
-
[19]
2024 USENIX Annual Technical Conference (USENIX ATC 24) , pages=
Metis: Fast automatic distributed training on heterogeneous \ GPUs \ , author=. 2024 USENIX Annual Technical Conference (USENIX ATC 24) , pages=
2024
-
[20]
Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 , pages=
Spindle: Efficient distributed training of multi-task large models via wavefront scheduling , author=. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 , pages=
-
[21]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Marten: Visual question answering with mask generation for multi-modal document understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[22]
Proceedings of the 21st European Conference on Computer Systems , pages=
MegaScale-Omni: A Hyper-Scale, Workload-Resilient System for MultiModal LLM Training in Production , author=. Proceedings of the 21st European Conference on Computer Systems , pages=
-
[23]
arXiv preprint arXiv:2504.14145 , year=
PipeWeaver: Addressing Data Dynamicity in Large Multimodal Model Training with Dynamic Interleaved Pipeline , author=. arXiv preprint arXiv:2504.14145 , year=
-
[24]
Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 , pages=
DIP: Efficient Large Multimodal Model Training with Dynamic Interleaved Pipeline , author=. Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 , pages=
-
[25]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[26]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Mm-llms: Recent advances in multimodal large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[27]
Proceedings of the ACM SIGCOMM 2025 Conference , pages=
Disttrain: Addressing model and data heterogeneity with disaggregated training for multimodal large language models , author=. Proceedings of the ACM SIGCOMM 2025 Conference , pages=
2025
-
[28]
arXiv preprint arXiv:2304.11277 , year=
Pytorch fsdp: experiences on scaling fully sharded data parallel , author=. arXiv preprint arXiv:2304.11277 , year=
-
[29]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
PlanGPT-VL: Enhancing urban planning with domain-specific vision-language models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2025
-
[30]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
Deploying Tiny LVLM Judges for Real-World Evaluation of Chart Models: Lessons Learned and Best Practices , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2025
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Scaling pre-training to one hundred billion data for vision language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
2025 USENIX Annual Technical Conference (USENIX ATC 25) , pages=
Accelerating Model Training on Ascend Chips: An Industrial System for Profiling, Analysis and Optimization , author=. 2025 USENIX Annual Technical Conference (USENIX ATC 25) , pages=
2025
-
[33]
Proceedings of the 2020 ACM SIGMOD international conference on management of data , pages=
Prompt: Dynamic data-partitioning for distributed micro-batch stream processing systems , author=. Proceedings of the 2020 ACM SIGMOD international conference on management of data , pages=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.