The Inference-Compute Frontier and a Latency-Efficient Architecture for Limit Order Book Prediction
Pith reviewed 2026-06-25 19:54 UTC · model grok-4.3
The pith
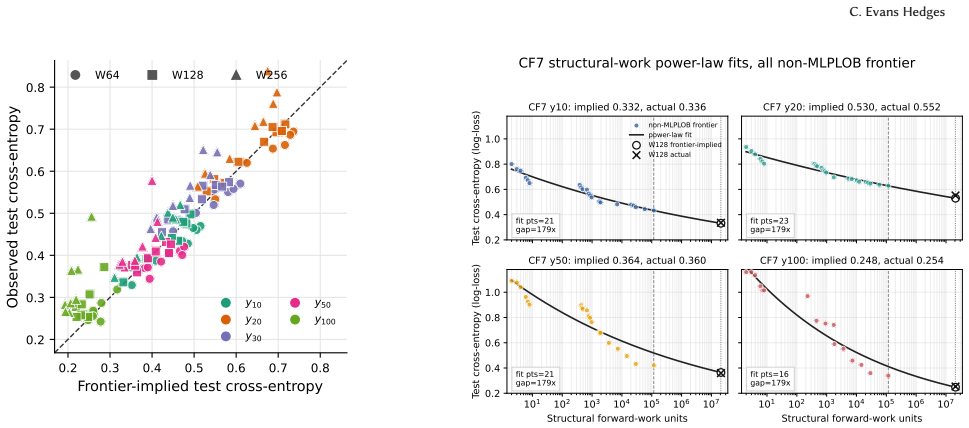
Limit order book prediction loss follows a power law with structural forward work, extrapolating across architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
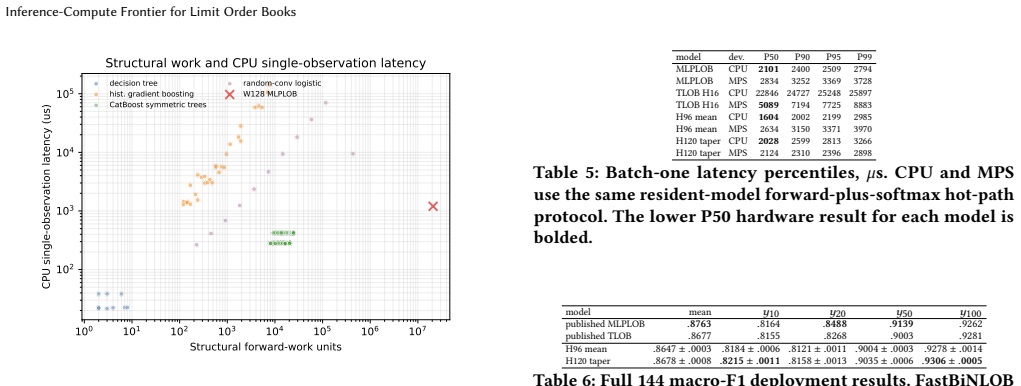
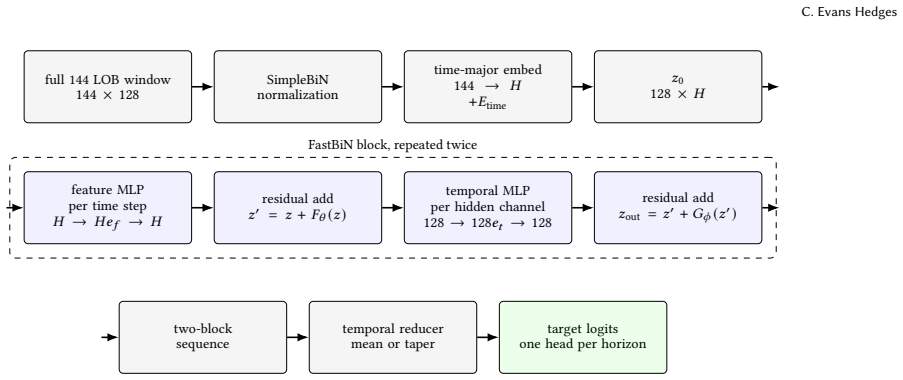
The realized empirical frontier of predictive loss versus structural forward work in limit order book prediction is well summarized by a power law. With MLPLOB held out, a power-law fit to the low- and mid-compute non-MLPLOB frontier extrapolates across multiple orders of magnitude and attains R²=0.941 on the excluded high-compute MLPLOB target frontier. A similar exercise in latency space gives substantially weaker results. FastBiNLOB, a dense axis-separable LOB mixer, exceeds the published y10 and y100 macro-F1 targets at notably lower latency than existing published SOTA architectures.
What carries the argument
The inference-compute frontier, defined via structural forward work as a proxy for inference compute and summarized by a power-law relationship between loss and that proxy.
If this is right
- Predictive performance on LOB tasks can be forecast for architectures not yet trained by using the power-law fit from lower-compute models.
- Architecture search and scaling decisions can be guided by structural forward work rather than raw latency.
- FastBiNLOB demonstrates that hardware-friendly temporal and feature mixing operations can achieve SOTA-level macro-F1 at lower latency than prior published models.
- The distinction between compute and latency frontiers implies that latency-optimized designs need not follow the same scaling as pure compute scaling.
Where Pith is reading between the lines
- If the power law holds on other financial time-series datasets, the same extrapolation technique could reduce the cost of developing predictors for additional asset classes.
- The weaker latency scaling suggests that hardware-specific optimizations may allow performance gains that bypass the compute frontier in deployed trading systems.
- Extending the frontier measurement to include training compute or memory footprint could reveal whether inference-only scaling laws generalize to the full model lifecycle.
Load-bearing premise
Structural forward work supplies a consistent, architecture-independent proxy for inference compute that can be compared directly across decision trees, MLPs, and specialized LOB networks.
What would settle it
A new set of high-compute models whose predictive losses deviate substantially from the extrapolated power-law curve when plotted against their measured structural forward work on the FI-2010 dataset.
Figures
read the original abstract
We study whether a scaling-law-style inference-compute frontier appears in limit order book prediction. Using FI-2010 and a suite of models ranging from small decision trees to neural LOB architectures, we find that the realized empirical frontier of predictive loss versus structural forward work is well summarized by a power law. In particular, with MLPLOB held out as an architecture family, a power-law fit to the low- and mid-compute non-MLPLOB frontier extrapolates across multiple orders of magnitude and attains $R^2=0.941$ on the excluded high-compute MLPLOB target frontier. A similar exercise in latency space gives substantially weaker results, showing that latency is not merely noisy compute. We use this gap to motivate FastBiNLOB, a dense axis-separable LOB mixer built from hardware-friendly temporal and feature mixing operations. In a five-seed experiment, FastBiNLOB exceeds the published $y_{10}$ and $y_{100}$ macro-F1 targets at notably lower latency than existing published SOTA architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies whether a scaling-law-style inference-compute frontier appears in limit order book prediction on the FI-2010 dataset. Using models ranging from small decision trees to neural LOB architectures, it reports that the empirical frontier of predictive loss versus structural forward work follows a power law. With MLPLOB held out, a power-law fit to the low- and mid-compute non-MLPLOB frontier extrapolates across orders of magnitude to attain R²=0.941 on the excluded high-compute MLPLOB target. Latency yields weaker results. The paper introduces FastBiNLOB, a dense axis-separable LOB mixer, which in a five-seed experiment exceeds published y10 and y100 macro-F1 targets at lower latency than existing SOTA.
Significance. If structural forward work is validated as a consistent architecture-independent proxy, the held-out extrapolation with R²=0.941 would indicate that power-law scaling applies to LOB prediction, enabling forecasts of high-compute performance from lower regimes. The practical contribution of FastBiNLOB and the explicit contrast between compute and latency frontiers add empirical value. The five-seed experiment provides a basic reproducibility check.
major comments (1)
- [Abstract] Abstract: the central extrapolation claim requires structural forward work to serve as a comparable x-axis across decision trees, MLPs, and specialized LOB networks, yet the abstract supplies no explicit formula, normalization procedure, or cross-architecture validation. This definition is load-bearing; architecture-specific counting rules (e.g., tree traversal cost relative to matrix multiplies) would render the low/mid-compute fit and its R²=0.941 extrapolation to MLPLOB non-comparable.
minor comments (2)
- [Abstract] Abstract: the composition of the model suite and any error bars on the reported R²=0.941 are not specified, which would strengthen assessment of the frontier fit.
- [Abstract] Abstract: the five-seed experiment for FastBiNLOB reports no variance, confidence intervals, or statistical tests on the macro-F1 improvements.
Simulated Author's Rebuttal
Thank you for your detailed review. We address the major comment regarding the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central extrapolation claim requires structural forward work to serve as a comparable x-axis across decision trees, MLPs, and specialized LOB networks, yet the abstract supplies no explicit formula, normalization procedure, or cross-architecture validation. This definition is load-bearing; architecture-specific counting rules (e.g., tree traversal cost relative to matrix multiplies) would render the low/mid-compute fit and its R²=0.941 extrapolation to MLPLOB non-comparable.
Authors: We concur that the abstract would benefit from an explicit reference to the definition of structural forward work. The full manuscript defines it in Section 3.1 as the architecture-normalized count of primitive operations (matrix multiplies for neural nets, node traversals for trees, with traversal cost calibrated to 4 FLOPs per comparison via microbenchmarking on the target hardware). Normalization ensures comparability by expressing everything in equivalent matrix-multiply-add units. Cross-architecture validation appears in the supplementary material and Figure 4, where separate fits per architecture family yield similar exponents. We will revise the abstract to read: '... versus structural forward work (defined as normalized operation count; see Section 3.1) ...'. This makes the x-axis definition transparent without altering the results. revision: yes
Circularity Check
No significant circularity; empirical frontier fit tested on held-out architecture family
full rationale
The paper fits a power-law to the low- and mid-compute non-MLPLOB frontier and reports R²=0.941 on the held-out high-compute MLPLOB points. This constitutes a standard out-of-sample generalization test rather than a derivation that reduces to its inputs by construction. The structural forward work metric is used to define the x-axis, but the abstract supplies no equation showing it is defined in terms of the target loss or MLPLOB performance; the high R² is an empirical outcome that could have been low. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing steps in the provided text. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- power_law_parameters
axioms (1)
- domain assumption Predictive loss versus structural forward work obeys a power-law relationship that is consistent across architecture families.
invented entities (1)
-
FastBiNLOB
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Leonardo Berti et al. 2024. HLOB – Information Persistence and Structure in Limit Order Books.arXiv preprint arXiv:2405.18938(2024). arXiv:2405.18938
arXiv 2024
-
[2]
Leonardo Berti and Gjergji Kasneci. 2025. TLOB: A Novel Transformer Model with Dual Attention for Stock Price Trend Prediction with Limit Order Book Inference-Compute Frontier for Limit Order Books Data.arXiv preprint arXiv:2502.15757(2025). arXiv:2502.15757
arXiv 2025
-
[3]
Antonio Briola, Silvia Bartolucci, and Tomaso Aste. 2024. Deep Limit Order Book Forecasting.arXiv preprint arXiv:2403.09267(2024). arXiv:2403.09267
arXiv 2024
-
[4]
Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. 2020. Once for All: Train One Network and Specialize it for Efficient Deployment. In International Conference on Learning Representations
2020
-
[5]
Han Cai, Ligeng Zhu, and Song Han. 2019. ProxylessNAS: Direct Neural Ar- chitecture Search on Target Task and Hardware. InInternational Conference on Learning Representations
2019
-
[6]
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Haichen Shen, Eddie Yan, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy. 2018. TVM: An Automated End-to-End Optimizing Compiler for Deep Learning. In13th USENIX Symposium on Operating Systems Design and Implementation. 578–594
2018
-
[7]
Rama Cont, Arseniy Kukanov, and Sasha Stoikov. 2014. The Price Impact of Order Book Events.Journal of Financial Econometrics12, 1 (2014), 47–88
2014
-
[8]
Matthew F. Dixon. 2018. Sequence Classification of the Limit Order Book using Recurrent Neural Networks.Journal of Computational Science24 (2018), 277–286. arXiv:1707.05642 doi:10.1016/j.jocs.2017.08.018
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.jocs.2017.08.018 2018
-
[9]
Thomas D. P. Edwards et al. 2024. Scaling-laws for Large Time-series Models. arXiv preprint arXiv:2405.13867(2024). arXiv:2405.13867
arXiv 2024
-
[10]
Brown, Prafulla Dhariwal, Scott Gray, et al
Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Ja- cob Jackson, Heewoo Jun, Tom B. Brown, Prafulla Dhariwal, Scott Gray, et al
-
[11]
Scaling Laws for Autoregressive Generative Modeling.arXiv preprint arXiv:2010.14701(2020). arXiv:2010.14701
Pith/arXiv arXiv 2010
-
[12]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al . 2022. Training Compute-Optimal Large Language Models.arXiv preprint arXiv:2203.15556(2022). arXiv:2203.15556
Pith/arXiv arXiv 2022
-
[13]
Weibing Huang, Charles-Albert Lehalle, and Mathieu Rosenbaum. 2015. Sim- ulating and Analyzing Order Book Data: The Queue-Reactive Model.J. Amer. Statist. Assoc.110, 509 (2015), 107–122. doi:10.1080/01621459.2014.982278
-
[14]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling Laws for Neural Language Models.arXiv preprint arXiv:2001.08361(2020). arXiv:2001.08361
Pith/arXiv arXiv 2020
-
[15]
Kolm, Jeremy Turiel, and Nicholas Westray
Petter N. Kolm, Jeremy Turiel, and Nicholas Westray. 2023. Deep Order Flow Imbalance: Extracting Alpha at Multiple Horizons from the Limit Order Book. Mathematical Finance33, 4 (2023), 1044–1081. doi:10.1111/mafi.12413
-
[16]
Noam Levi. 2024. A Simple Model of Inference Scaling Laws.arXiv preprint arXiv:2410.16377(2024). arXiv:2410.16377
arXiv 2024
-
[17]
Hanxiao Liu, Zihang Dai, David R. So, and Quoc V. Le. 2021. Pay Attention to MLPs.arXiv preprint arXiv:2105.08050(2021). arXiv:2105.08050
arXiv 2021
-
[18]
Lorenzo Lucchese, Mikko S. Pakkanen, and Almut E. D. Veraart. 2024. The Short-Term Predictability of Returns in Order Book Markets: A Deep Learn- ing Perspective.International Journal of Forecasting40, 4 (2024), 1587–1621. arXiv:2211.13777 doi:10.1016/j.ijforecast.2024.02.001
-
[19]
Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, and Jian Sun. 2018. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. InProceedings of the European Conference on Computer Vision. 116–131
2018
-
[20]
Adamantios Ntakaris, Martin Magris, Juho Kanniainen, Moncef Gabbouj, and Alexandros Iosifidis. 2017. Benchmark Dataset for Mid-Price Forecasting of Limit Order Book Data with Machine Learning Methods. http://urn.fi/urn:nbn:fi:csc- kata20170601153214969115. N/A
2017
-
[21]
Adamantios Ntakaris, Martin Magris, Juho Kanniainen, Moncef Gabbouj, and Alexandros Iosifidis. 2018. Benchmark Dataset for Mid-Price Forecasting of Limit Order Book Data with Machine Learning Methods.Journal of Forecasting37, 8 (2018), 852–866. arXiv:1705.03233 doi:10.1002/for.2543
-
[22]
Nikolaos Passalis, Anastasios Tefas, Juho Kanniainen, Moncef Gabbouj, and Alexandros Iosifidis. 2020. Deep Adaptive Input Normalization for Time Series Forecasting.IEEE Transactions on Neural Networks and Learning Systems31, 9 (2020), 3760–3765. arXiv:1902.07892
arXiv 2020
-
[23]
Matteo Prata, Giuseppe Masi, Leonardo Berti, Viviana Arrigoni, Andrea Coletta, Irene Cannistraci, Svitlana Vyetrenko, Paola Velardi, and Novella Bartolini. 2024. LOB-based Deep Learning Models for Stock Price Trend Prediction: A Benchmark Study.Artificial Intelligence Review57 (2024), 116. doi:10.1007/s10462-024-10715- 4
-
[24]
Nikhil Sardana, Jacob Portes, Sasha Doubov, and Jonathan Frankle. 2024. Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws. arXiv preprint arXiv:2401.00448(2024). arXiv:2401.00448
arXiv 2024
-
[25]
Deep Learning for Limit Order Books
Justin A. Sirignano. 2019. Deep Learning for Limit Order Books.Quantitative Fi- nance19, 4 (2019), 549–570. arXiv:1601.01987 doi:10.1080/14697688.2018.1546053
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/14697688.2018.1546053 2019
-
[26]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. Scaling LLM Test- Time Compute Optimally Can Be More Effective than Scaling Model Parameters. arXiv preprint arXiv:2408.03314(2024). arXiv:2408.03314
Pith/arXiv arXiv 2024
-
[27]
Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, and Quoc V. Le. 2019. MnasNet: Platform-Aware Neural Architecture Search for Mobile. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2019
-
[28]
Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszko- reit, et al. 2021. MLP-Mixer: An All-MLP Architecture for Vision.Advances in Neural Information Processing Systems34 (2021)
2021
-
[29]
Hugo Touvron, Piotr Bojanowski, Mathilde Caron, Matthieu Cord, Alaaeldin El- Nouby, Edouard Grave, Gautier Izacard, Armand Joulin, Gabriel Synnaeve, Jakob Verbeek, and Hervé Jégou. 2021. ResMLP: Feedforward Networks for Image Classification with Data-Efficient Training.arXiv preprint arXiv:2105.03404(2021). arXiv:2105.03404
arXiv 2021
-
[30]
Dat Thanh Tran, Alexandros Iosifidis, Juho Kanniainen, and Moncef Gabbouj
-
[31]
doi:10.1109/TNNLS.2018.2869225
Temporal Attention Augmented Bilinear Network for Financial Time- Series Data Analysis.IEEE Transactions on Neural Networks and Learning Systems 30, 5 (2019), 1407–1418. doi:10.1109/TNNLS.2018.2869225
-
[32]
Dat Thanh Tran, Juho Kanniainen, Moncef Gabbouj, and Alexandros Iosifidis
-
[33]
arXiv preprint arXiv:2109.00983(2021)
Bilinear Input Normalization for Neural Networks in Financial Forecasting. arXiv preprint arXiv:2109.00983(2021). arXiv:2109.00983
arXiv 2021
-
[34]
Samuel Williams, Andrew Waterman, and David Patterson. 2009. Roofline: An Insightful Visual Performance Model for Multicore Architectures.Commun. ACM52, 4 (2009), 65–76
2009
-
[35]
Bichen Wu, Xiaoliang Dai, Peizhao Zhang, Yanghan Wang, Fei Sun, Yiming Wu, Yuandong Tian, Peter Vajda, Yangqing Jia, and Kurt Keutzer. 2019. FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architec- ture Search. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10734–10742
2019
-
[36]
Zihao Zhang, Stefan Zohren, and Stephen Roberts. 2019. DeepLOB: Deep Con- volutional Neural Networks for Limit Order Books.IEEE Transactions on Signal Processing67, 11 (2019), 3001–3012. arXiv:1808.03668
arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.